基于XGBoost算法的手机用户真实性别识别
2022-03-24鲁涔
鲁 涔
中国电信股份有限公司江苏分公司
0 引言
用户性别可细分为自然性别和互联网使用行为性别两种。自然性别是指用户的实际性别,一般可通过入网实名制身份证获得。该标签只需要从相应的表中抽取数据即可,加工起来较为方便。用户互联网使用行为性别是指用户使用手机的性别取向。例如,一位身份证性别为男性的用户,可能经常使用美拍类APP、教育类APP,那么这位用户的互联网使用行为性别可能是女性。目前国内有基于用户APP类型、打开APP的频率,及网址关键词统计汇总后进行GBDT迭代决策树的预测性别模型,但数据多样性不足,缺乏运营商特有的多维度特征,如终端信息、套餐信息、上网行为信息等。
因此本研究通过对运营商多样性数据进行沉淀和梳理,利用智能手机用户使用APP数据对用户的性别进行预测,明晰移动网络背后用户的性别属性,助力企业精准营销、人口政策分析、景区人流特征、用户画像、客户关怀话术用语等工作。
1 数据抽取
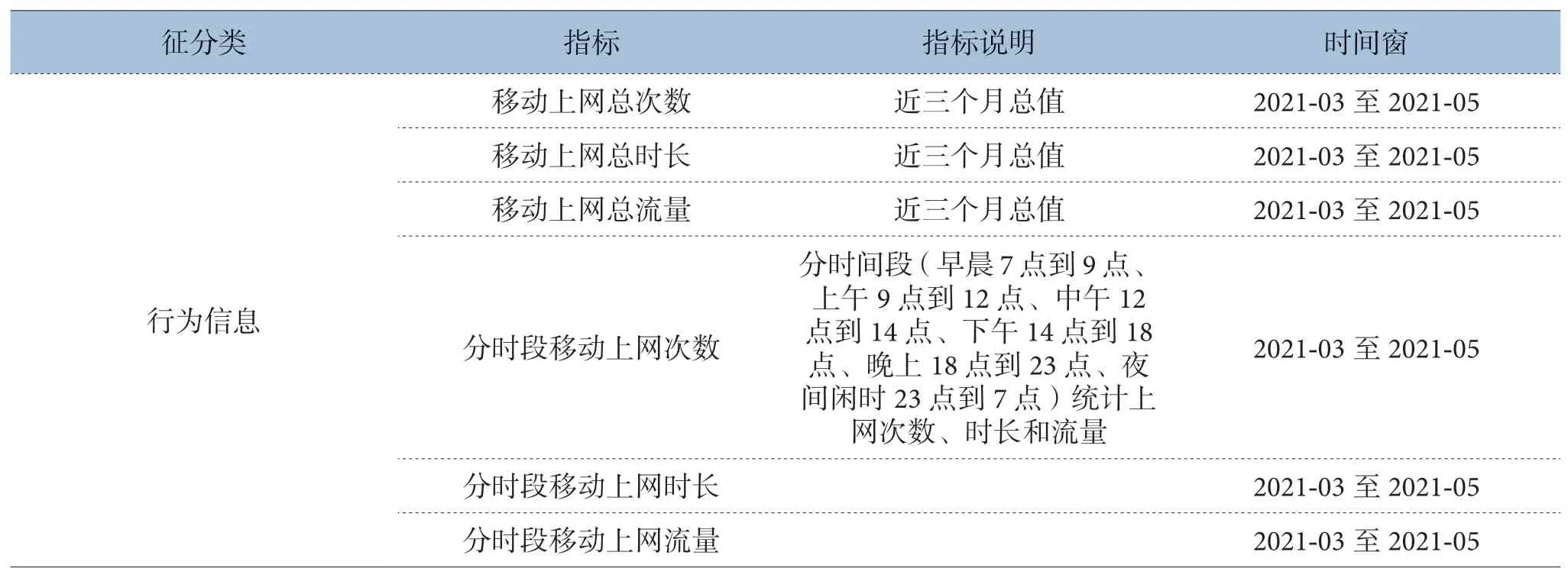
通过抽取整合单天翼用户的基本信息、终端信息、套餐信息、APP信息、微信公众号信息和行为信息,构造分析所需要的基础数据宽表。宽表数据字段如表1所示。
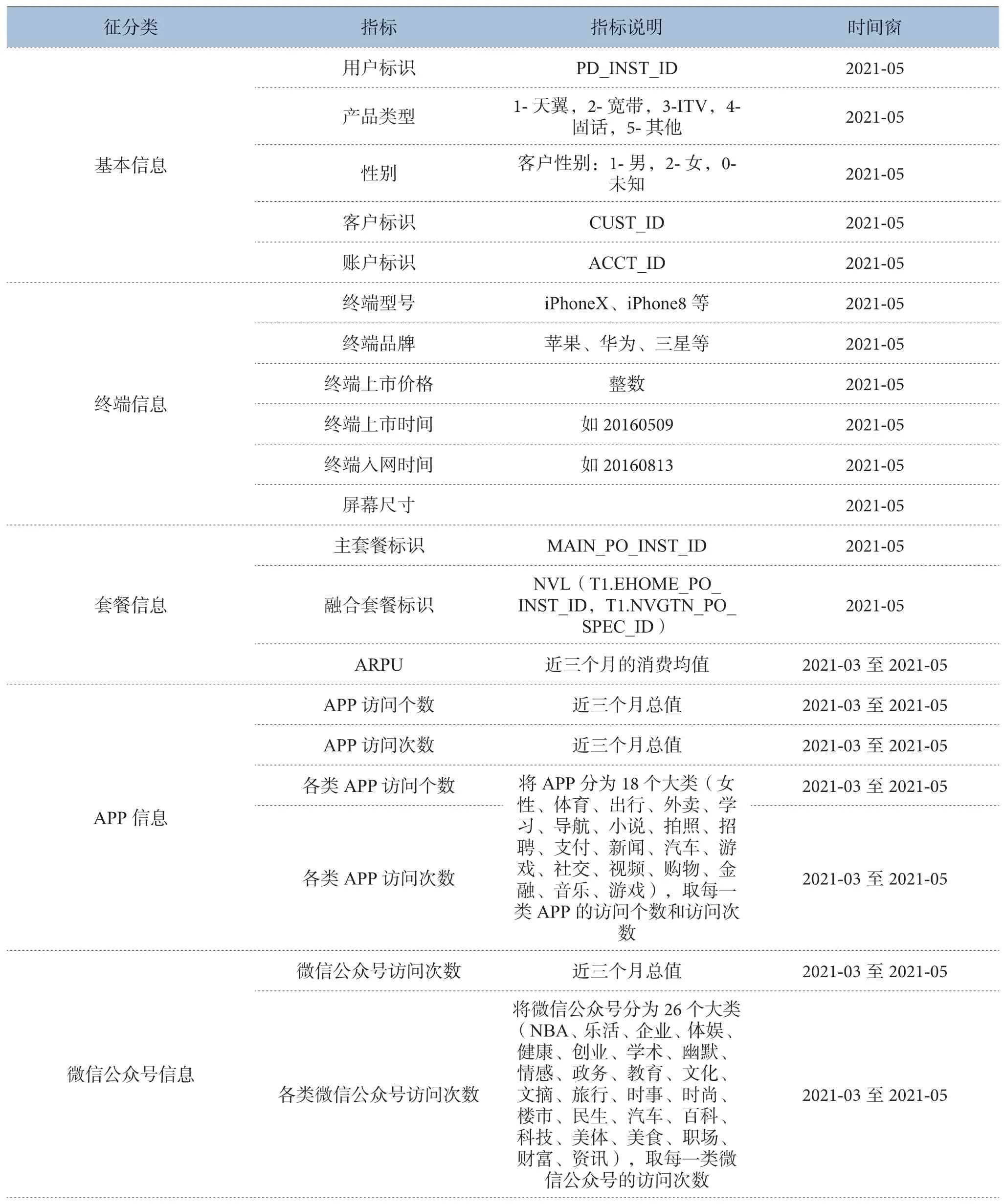
表1 单天翼用户特征分类表
2 数据探索
在最简单的情况下,采用专家经验if else 判断(一棵树)即可。但如果预测结果与众多因素有关,每一个特征的权重又不尽相同。如何把这些特征的权重合理的找出来?XGBoost正是这样一种算法,以分类回归树(CART树)进行组合,由多个相关联的树联合决策。这样集成学习方法是指将多个学习模型组合,以获得更好的效果,使组合后的模型具有更强的泛化能力。在模型训练中,参数的调整固然重要,但特征的辨识度更加重要,数据和特征决定了机器学习的上限,而模型和算法则是逼近上限而已。好的特征工程以及数据集才会影响模型本质的结果。
分析思路:单天翼客户名下有且仅有一个天翼用户,该天翼用户所属的客户性别可认为是其真实的性别,本次分析建立在单天翼用户的基础上。
目标用户:2021年5月某市在网单天翼用户(剔除客户性别为空的用户共527984户)
特征选择:通过初步的数据探索,发现以下三个因素对识别用户性别的效果比较好,男性和女性的区分度比较大。
(1)女性APP访问个数、次数。通过分析目标用户的访问的女性APP信息发现,女性用户三个月的访问量是男性的4倍(1015:266),且访问过女性APP的用户中,女性比例明显高于男性,如图1所示。(2)体育类APP访问个数、次数。(3)男性平均每户有2个体育类APP,三个月的访问量达到了872次,而女性平均每户只有0.8个,三个月的访问量也仅有86次,均远低于男性。说明男性相比女性偏好体育类APP。(4)拍照类APP访问个数、次数。与上面相反,女性平均每户有7.7个拍照类APP,三个月访问量达到263次,相比之下男性平均每户只有4.4个,三个月的访问次数仅有87次,不足女性的三分之一。说明女性比男性偏好拍照类APP。

图1 TOP10女性APP的用户性别比例
?
3 数据预处理
数据预处理方法可以大致分为四类:数据清理、数据集成、数据变换和数据规约。模型的输入一般对数据有要求,需要进行预处理,以下是本文构建的模型对字段进行的处理:
3.1 数据清洗
数据清理(data cleaning) 的主要思想是通过填补缺失值、光滑噪声数据,平滑或删除离群点,并解决数据的不一致性来“清理“数据。如果用户认为数据是脏乱的,他们不太会相信基于这些数据的挖掘结果,即输出的结果是不可靠的。如表2所示。
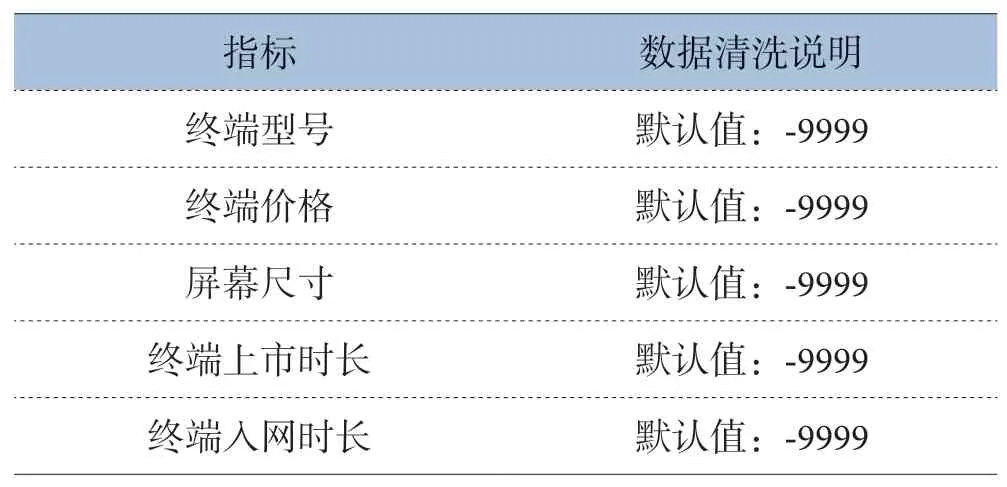
表2 数据清洗说明
3.2 数据规约
数据归约技术可以用得到数据集的归约表示,它小得多,但仍接近地保持原数据的完整性。这样,在归约后的数据集上挖掘将更有效,并产生相同(或几乎相同)的分析结果。如表3所示。

表3 数据约束说明
数据变换包括对数据进行规范化,离散化,稀疏化处理,达到适用于挖掘的目的。如表4所示。

表4 数据转换说明
4 模型构建
4.1 建模字段筛选
建模字段筛选如表5所示。

表5 建模字段筛选
4.2 Python建模—调用XGBoost模块
XGBoost是boosting算法的其中一种。Boosting算法的思想是将许多弱分类器集成在一起形成一个强分类器。因为XGBoost是一种提升树模型,所以它是将许多树模型集成在一起,形成一个很强的分类器。而所用到的树模型则是CART回归树模型。该算法思想就是不断地添加树,不断地进行特征分裂来生长一棵树,每次添加一个树,其实是学习一个新函数,去拟合上次预测的残差。当训练完成得到k棵树,要预测一个样本的分数,其实就是根据这个样本的特征,在每棵树中会落到对应的一个叶子节点,每个叶子节点就对应一个分数,最后只需要将每棵树对应的分数加起来就是该样本的预测值。
XGBoost使用了和CART回归树一样的想法,利用贪婪算法,遍历所有特征的所有特征划分点,不同的是使用上式目标函数值作为评价函数。具体做法就是分裂后的目标函数值比单子叶子节点的目标函数的增益,同时为了限制树生长过深,还加了个阈值,只有当增益大于该阈值才进行分裂。同时可以设置树的最大深度、当样本权重和小于设定阈值时停止生长去防止过拟合。
XGBoost是大规模并行boosted tree的工具,它是目前最快最好的开源boosted tree工具包,比常见的工具包快10倍以上。在数据科学方面,有大量kaggle选手选用它进行数据挖掘比赛。在工业界规模方面,xgboost的分布式版本有广泛的可移植性,支持在YARN, MPI, Sungrid Engine等各个平台上面运行,并且保留了单机并行版本的各种优化,使得它可以很好地解决于工业界规模的问题。
5 模型检验
目标用户共527984条数据,将其中的395988(四分之三)作为训练集,其他的131996作为测试集进行验证。
通过构建的模型对测试集进行性别预测,得到的模型效果如表6所示。

表6 检测样本的预测结果

表6 模型效果
准确率=预测正确的用户数/实际性别(男性或女性)用户数
召回率=预测正确的用户数/预测性别(男性或女性)用户数
6 结束语
该方案在江苏电信属首创,以公司客户服务及客户经营分析画像的需求和痛点为本,创新地构建了手机用户真实使用性别识别的新思路,解决用户画像男女数据不全、不准确的问题。通过数据挖掘完成这项工作,极大地解放人力,提升效率。在实际使用中,收到良好的反馈效果。运用互联网思维,借助机器学习技术,充分挖掘企业数据的价值和作用,开辟了一条数据探索新航道。
本文研究还有待提升的空间:此方案的正样本来自于单天翼样本量的男女性别情况,后期将着手于海量的语音文件分析,通过机器学习的方法对声音文件进行特征提取、分类建模训练,进行男女音频样本的识别,补充单天翼样本量的不足之处,增加更多正样本量进行训练,以此完善本方案。
