基于大数据和虚拟化技术的网元告警接收处理方法
2022-03-24邹雨佳郭旭芝耿书鹏
班 瑞 李 颖 邹雨佳 郭旭芝 耿书鹏
1.中讯邮电咨询设计院有限公司;2.北京航天航空大学
0 引言
网络管理是对硬件、软件和人力的综合使用,使得各个部分能够协调高效地对网络资源进行监视、测试、配置、分析、评价和控制,以保障网络系统稳定正常的运行。另外,网络运营中每天都会产生大量的网元告警。设备产生的告警信息数量庞大,种类繁多,且一次故障往往会在众多互连设备上产生大量的告警。因此,当网络出现故障时能及时对告警信息进行报告和处理,并协调、保持网络系统的高效运行,在网络管理中占据着至关重要的地位。
本文针对网元告警,提出一种基于5G虚拟化告警采集、大数据信息分类与存储、松耦合式数据处理与分析的告警接收处理方法,大幅提高告警信息的处理效率与存储能力,降低网络运营维护的成本,尽量避免因告警发现和处理的不及时导致的网络故障问题。
1 传统告警采集分析存在的问题
联通传统智能城域网采用SNMP trap来接收网元发送的告警。采集程序监听指端口的告警报文,默认端口为162端口,接收到告警以后通过解析分析将其存储到数据库中。告警分析需要具备告警设备资源数据识别、合并、过滤等,通常程序使用并发的方式处理告警。这种利用SNMP trap来接受网元发送的告警,在通常情况下能够满足常用的告警分析,但是存在以下几个缺点:
(1)采集规模不够。告警采集分析程序一般为单机程序,能够支撑的网元数在万级别以内,这个规模可以支撑一般的企业网和城域网,但是在面对运营商级集中式管理的模式下,网元数量通常在十万级,传统方式难以支撑。
(2)告警分析的时效性差。传统的实现方式中,为了提高采集性能,对分析的处理比较简单。一般深入分析都是采用事后的方式,分析时效难以满足日常的运维要求。告警采集数据以数据流的方式流入分析程序,分析的延时在10秒级。
(3)数据开放性不够。传统的数据方式原始告警采集分析完以后,一般直接入库,对于第三方原始告警数据是封闭的。数据采集和分析是紧耦合的,原始数据无法进行共享。
2 系统设计思路
随着5G时代的到来,快速发展的云网业务、垂直行业的创新应用等都对承载网络提出了新的要求,新型的网络需要面临数十万的设备管理以及大量的业务开通,因而网元告警数量规模更是以亿计量,传统的告警分析系统难以支撑大规模的告警采集与大量数据的实时分析。针对传统告警采集分析存在的不足,本文的网元告警采集分析系统从需求上要求技术架构需要满足以下几点:(1)大规模采集能力;(2)海量数据存储能力;(3)实时数据处理能力;(4)集群资源利用最大化;(5)多系统大数据分析能力;(6)灵活的对外业务支撑服务能力。
结合以上特点,系统设计的方案以云计算的架构思路出发,提升系统的计算能力。采集使用DOCKER化,存储使用分布式列式存储的技术,有效地解决了网元规模限制的问题。这样做不但可以实现采集的规模大幅度提高,而且还可以同时实现更多的告警数据储存。
另一方面,新的采集和分析系统采用分布式计算方法。分布式计算与传统的集中式计算相比,具有稀有资源可以共享、可以在多台计算机上平衡计算负载的特点,更适合处理需要大量算力的告警数据的分析与采集。分布式计算可以极大地提升计算的效率,同时也为提高实时性的分析奠定了基础。
系统将采集和分析分成两块独立程序,中间通过转发层进行数据链接,所以新告警的分析日志的数据是开放并支持第三方的。这样不但可以节约中间处理数据的时间,而且为对外业务其他接口处理数据提供了便利。
3 告警采集分析系统设计流程
本系统使用一种松耦合的方式完成告警的采集和分析。主要包括四个方面的内容,即告警采集、转发、分析、存储,整体架构如图1所示。
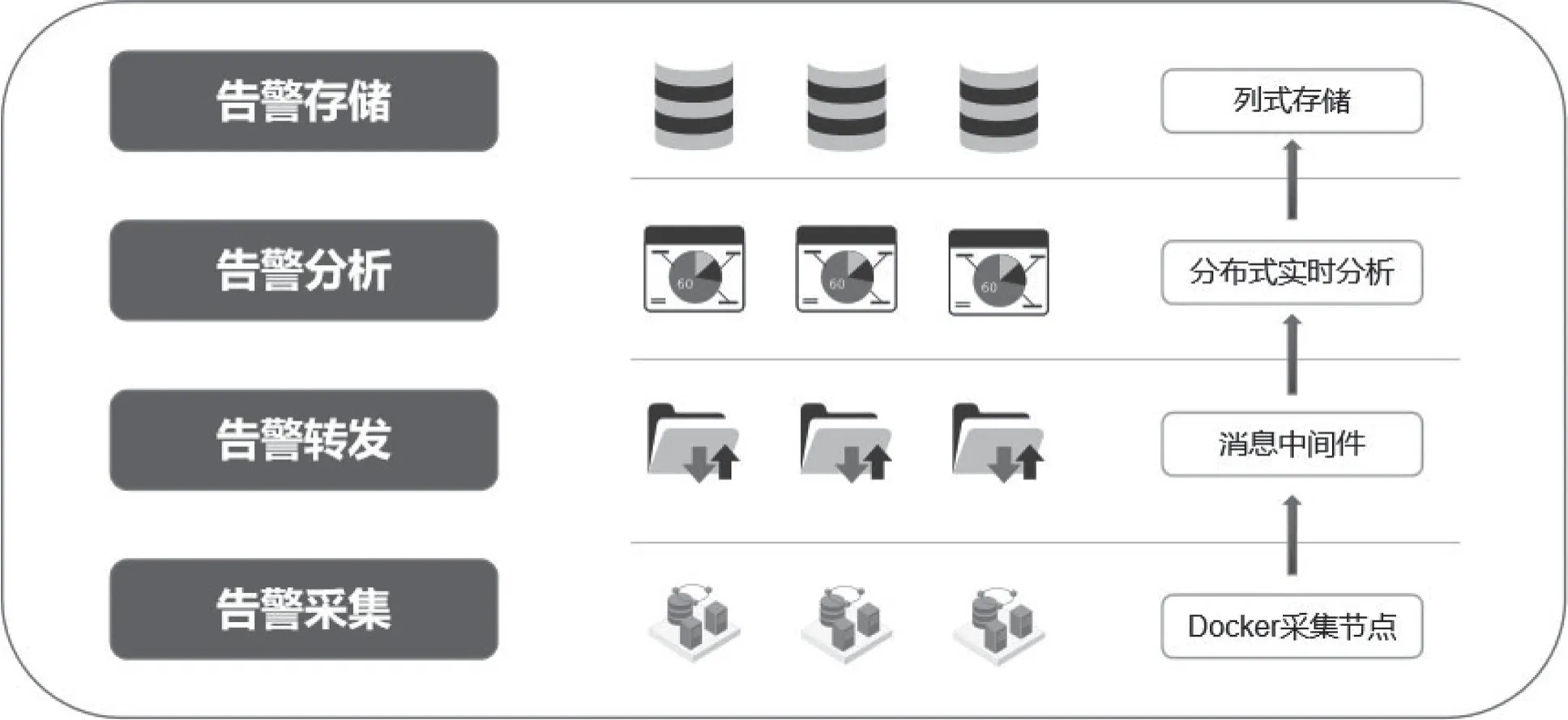
图1 总体技术架构
告警采集采用SNMP采集方式,并将告警采集的程序DOCKER化。DOCKER容器虚拟化技术可以实现应用程序的快捷部署,并且支持横向扩展,以便应对5G时代带来的更大规模的日志收集、存储和分析。基于该系统架构,系统各层之间通过网络传输方式进行交互,实现系统层级的独立解耦。
告警转发采用Kafka日志系统作为消息中间件,采用具有高吞吐率以及高可用性特点的消息中间件Kafka作为消息存储与消费的底层技术支持,并在Kafka定义的Topic基础上以逻辑Topic的概念作为消息发布订阅的基本单元。
告警分析采用Spark分布式计算框架,在基于Spark Streaming的实时日志分析与信息管理系统中,利用基于Kafka和Spark Streaming的实时流处理,对海量日志数据进行实时分析处理。
告警存储利用基于HDFS分布式系统框架的列式分布式数据库实现,在集群节点间实现负载均衡算法,在保证副本跨交换机存储的原则上,使新增节点之后数据存储重新达到基于字段均衡的状态,保证存储的可靠性与数据量。
3.1 告警采集
新型告警采集分析系统将传统的告警采集程序DOCKER化,这样原有的采集程序只需少量变更,即可完成虚拟化安装。DOCKER化后可以支持多节点部署快速部署采集程序,极大提升采集能力。
告警采集主要的工作为适配各个厂家的告警定义,以统一的形式发送到消息中间件中。转化后的告警格式如下:
告警ID(0)||告警时间(yyyy-MM-dd HH:mm:ss)(1)||告警设备IP(2)||告警原始时间戳(3)||厂家(4)||告警标题(5)||原始名称(6)||原始OID(7)||厂家告警级别(8)||统一告警级别(9)||告警解释(10)||MIB类型(11)||告警类别(12)||该事件对网元的影响(13)||该事件对业务的影响(14)||告警参数数量(15)||实际告警参数数量(16)||告警参数1序号(17)||告警参数1原始名称(18)||告警参数1原始OID(19)||告警参数1原始类型(20)||告警参数1标题(21)||告警参数1详细解释(22)||告警参数1值(23)||告警参数2...
3.2 告警转发
告警采集分析系统将传统的告警采集和分析分离,使用日志转发的方式将告警存储到消息中间件中。常见的数据集成需要使用Flume作为日志收集系统,本文系统的告警存储使用Kafka作为日志收集系统消息中间件,直接将消息写入HDFS中。消息中间件以Kafka集群的方式部署,利用Kafka作为分布式发布订阅消息系统的特性,对磁盘数据结构提供消息的持久化,长时间保持大量存储的告警数据的稳定性能,保障数据转发的可靠性与实时性。
将告警存储到消息中间件Kafka的另一目的是为了原始数据的开放性,Kafka具有解耦特点,可以在告警信息处理过程中插入一个隐含的、基于数据的接口层,第三方系统可以通过实现Kafka接口完成与告警系统的通信操作。这种松耦合式的数据缓存,不仅仅使得网管自身的分析程序可以使用该数据,其他第三方的系统也可以通过消息中间件获取告警原始数据进行分析加工。
3.3 告警分析
基于电信网络告警数据的特点,利用Spark分布式计算框架,实时分析技术消费消息中间件中的告警信息,通过算子、缓存等方式分析告警相关的网元信息、告警的过滤规则、合并规则等。实时计算模型采用Spark Streaming,可以把指定的时间片段的流数据积累为RDD,继而对每个RDD进行微批次处理,实现大吞吐量实时处理大规模的流式数据,使得系统可以支持每秒千万级的告警处理。同时Spark Streaming可以作为离线分析的计算模型,选用Spark Streaming进行实时分析可以只需要维护并监控Spark集群,降低系统的维护难度与成本。
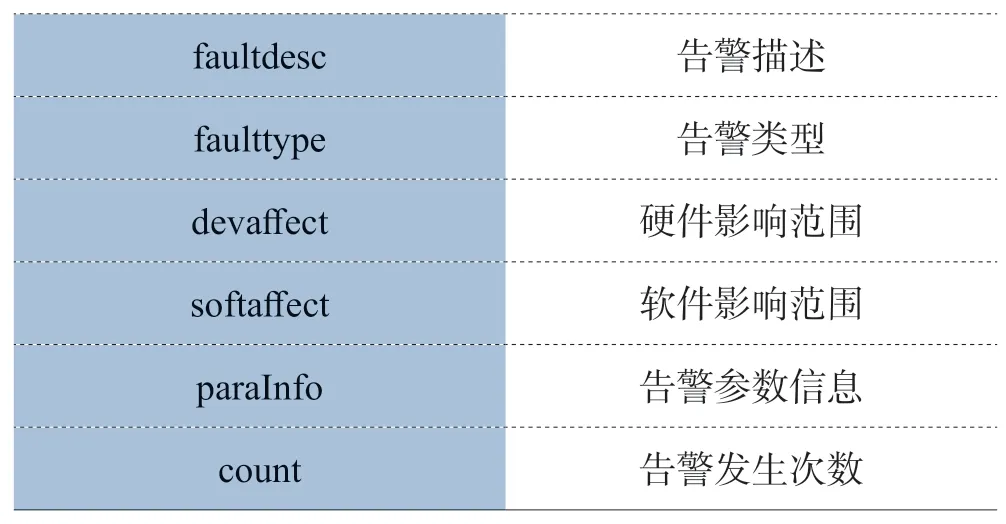
告警分析从消息中间件中获取数据后将数据转成流的形式将获取的告警日志信息转成通用的实体类,通过分布式计算进行分析产生最终分析结果。常用算子包括map、reduce、map partition、for each等。实体类的字段定义如表1所示。通过分布式计算的算子对数据进行转换分析最终产生分析结果。
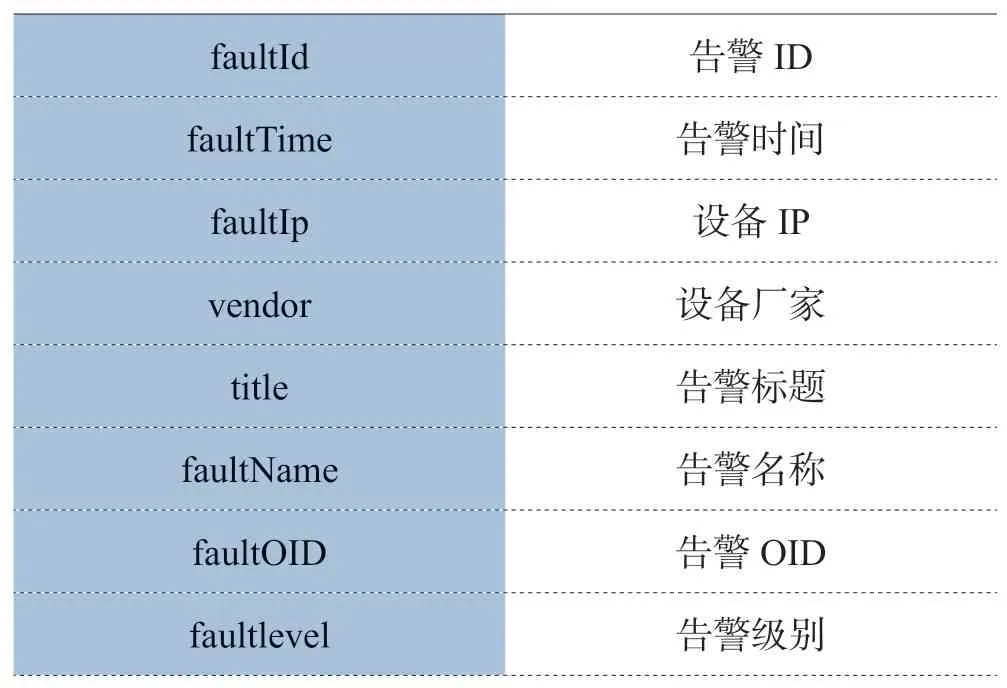
表1 告警字段定义表
?
3.4 告警存储
使用Kafka作为日志收集系统直接将消息写入HDFS中,将分析后的告警数据存储到分布式列式数据库中。HDFS还有相应处理并发访问的机制,通过这样的机制使得内存读取速度快的同时,还能够适应多个客户端同时访问的压力。
与传统数据库相比,分布式数据库具有可扩展性和高可靠性两个特点,分布式数据库弱化了数据处理过程中的一致性,保障最终结果数据的一致性,这样既可以扩展数据库的规模,也满足企业的应用需求。列式数据库可以有效降低系统I/O流,充分发挥字段内部压缩的优势,为告警数据的存储节省大量的空间。
本文的告警分析采集系统采用HDFS作为数据的存储,列式分布式数据库以集群的方式部署,支持存储半年以上的告警数据,并且支持即时查询。
4 告警采集分析系统应用情况
中国联通以5G建设及5G承载网络构建为契机,构建了一张融合承载的智能城域网,告警采集分析系统目前已通过设备厂家互通测试,逐步投入到智能城域网网管系统运营场景中。
应用效果具备以下特点:(1)告警采集采用虚拟化技术,可以快速部署多个采集节点,有效地解决了传统网管告警模块告警采集规模的问题;(2)利用分布式计算的技术,可以满足每秒千万级告警的分析,有效地解决了告警分析的时效性;(3)引入消息中间件,支持告警转发,有效地解决了数据开放性的问题;(4)利用分布式列式数据库存储大量告警信息,满足半年内告警的数据随查随用,有效地解决了告警数据量大而导致不得不定期清除数据的问题。
智能城域网系统目前已纳管全国超过3万5千台设备,在近一个月的网元告警采集分析实际运用中,网元平均每分钟通过SNMP Trap传送给网管的告警数量近5万条。系统将告警流统一存储在消息中间件Kafka中,并根据时间片段从Kafka读取告警流数据积累为RDD,进而利用Spark快速分析处理告警数据。处理完成后的告警将展示在智能城域网网管系统的实时告警板上,实时告警板支持用户自定义时间片段,最小粒度为10秒刷新一次告警数据展示。
系统所采取的告警采集分析方式,可以保障告警从网元发出至分析展示在系统页面上所需的处理时间维持在1秒以内,可以满足5G时代大规模的网元告警处理,具有良好的鲁棒性与稳定性。
目前智能城域网网管系统月均系统使用人数超过5000人次,月处理数据量达200亿。网管系统每日需处理千万级以上的告警数据,月告警数据已达到3亿以上,并实现每10秒近1万告警数据的实时分析与展示,同时系统将储存一年内的所有告警数据并保证数据的可靠性与完整性。网管系统已成功实现告警数据与数个第三方系统对接,实现大规模告警数据派单等功能,推动了网管系统中告警模块的创新与发展。
5 结束语
本文提出的告警采集分析系统,在保障数据的稳定性的同时将告警采集流程简化并虚拟化,利用分布式计算实现告警采集程序大规模快速部署,是未来提升网络管理稳定的关键手段,目前已在现网应用成功并取得良好的运作效果。本系统的设计能够更加可靠稳定、灵活快速满足运维人员的配置需求,及时采集并分析5G网元告警,便于运维人员及时且准确地定位问题,维护网络稳定,极大提升运维效率,减少人力成本。
