大数据技术在网络威胁情报系统的应用研究
2022-03-23黄必栋
◆黄必栋
大数据技术在网络威胁情报系统的应用研究
◆黄必栋
(南京铁道职业技术学院智能工程学院 江苏 210000)
本文结合威胁情报系统的设计、开发和运维经验,系统研究了流式数据处理、交互式数据分析、数据湖以及分布式数据处理等大数据技术在威胁情报系统中的应用。分析和总结了在威胁情报系统建设场景中,大数据技术的选择、大数据产品的选型以及大数据平台的设计,为基于大数据技术的应用系统的设计和开发提供参考。
威胁情报;流式数据处理;交互式数据分析;数据湖
在网络安全防护中使用威胁情报发现和阻止网络攻击,即通过分析已知网络攻击、恶意软件的行为,提取可用于识别网络威胁的关键特征,使用关键特征进行匹配,从而发现和阻止网络攻击行为。可用于识别网络威胁的关键特征即威胁情报,包括恶意文件的哈希值、C&C地址、攻击手法、攻击组织和攻击意图等[1]。威胁情报数据符合大数据特征:数据量大、数据来源和种类多样、数据增长快以及数据价值密度和可信度相对较低。因此大数据技术广泛并深入应用于威胁情报系统中,其中包括了大数据存储、大数据离线分析与挖掘、大数据实时处理、大数据在线查询统计等。由于大数据技术种类繁多、同一类技术存在多个开源系统以及开源系统存在不成熟和不稳定的问题,使得不同组织的威胁情报系统差异较大,没有统一的数据处理平台。本文结合威胁情报系统的设计、开发和运维经验,系统研究了大数据技术在威胁情报系统中的应用。分析和总结了在威胁情报系统建设场景中,大数据技术的选择、大数据产品的选型以及大数据平台的设计。
1 威胁情报系统介绍
威胁情报系统是安全防御的后台系统,提供威胁情报用于网络威胁检测。使用威胁情报的效果,取决于组织拥有情报的可靠性、完整性和及时性。而网络攻击持续发生,覆盖范围广,攻击形式和方法变化多端,恶意软件数量也持续增长,这些特征决定了组织应通过情报共享、安全大数据分析与挖掘、实时数据处理、情报生成自动化等方法来确保威胁情报的质量。情报共享使得组织在无法掌握所有攻击活动和恶意样本的情况下,尽可能掌握更多的攻击信息。安全数据分析与挖掘能够丰富与完善情报信息,通过安全数据的关联分析找出攻击特征与规律,进一步生成更多的威胁情报,提高情报的可靠性。实时数据处理确保了威胁情报的时效性,以及情报生成的高效性。情报自动化生成能够提高威胁情报生成的效率,确保威胁情报的按时生成。
威胁情报系统的架构如图1所示,虚线框中为威胁情报系统,收集各种情报相关数据进行处理,生成情报并分发至安全产品,整个过程以自动化的方式进行,使情报持续稳定的输出[2]。整个系统围绕安全数据的收集、处理、存储、分析和生成而进行,安全分析师和研究员使用系统对情报相关数据进行分析和评估,以及调整情报生成相关算法。流式数据处理技术确保了情报数据处理的及时性和高效性;交互式数据查询和分析技术使得安全分析人员能够高效、快速地查找和分析安全数据;数据湖技术使得大量安全数据能够安全可靠地存储,配合分布式数据处理引擎,能够进行高效的数据处理和分析,并支持运行复杂的情报生成算法。
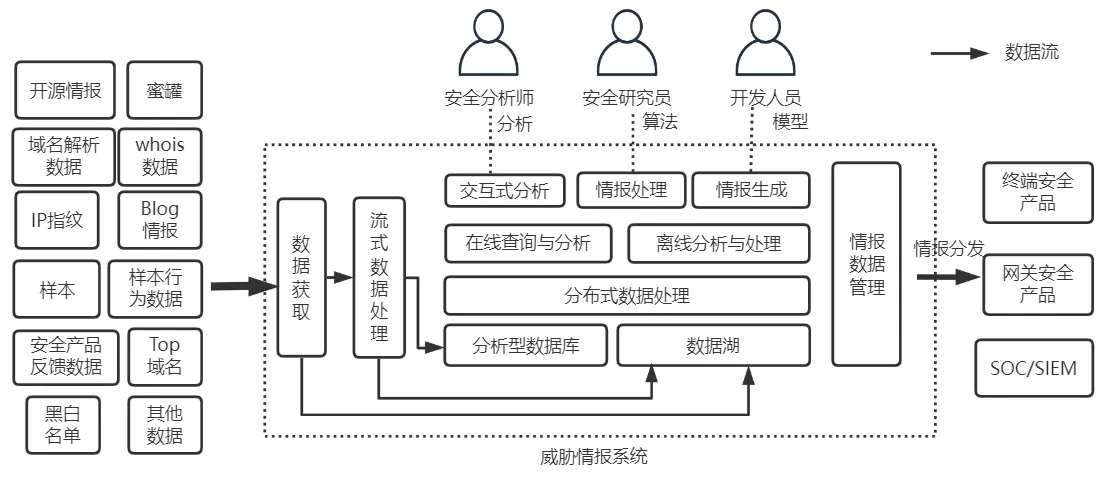
图1 威胁情报系统
2 流式数据处理技术的应用
2.1 数据处理需求
一些情报数据具有量大、价值密度低的特点,如蜜罐数据、样本行为数据等,须在落入数据仓库前进行数据处理,以确保数据处理的效率。此类数据处理要求复杂,除了常规的数据变换、筛选、去重等处理之外,还需进行定制化的复杂处理,例如对数据中的IP地址进行实时指纹查询,并依据查询结果打标签;实时解析域名的IP地址或者IP地址的反向查询等。流式数据处理技术能满足相应的要求,即能进行常规的数据处理,也能支持用户定制化的数据处理要求。
2.2 技术选型
满足数据处理要求的开源流式处理系统有:Spark Streaming[3]、Storm[4]和Flink[6],其技术对比如表1所示。Storm是较早推出的流式处理系统,具有较好的实时性,但是吞吐能力、状态管理以及窗口处理能力较弱。Spark Streaming是目前主流的流式处理系统,具有较好的吞吐能力、状态管理、编程语言支持,但由于micro batch的处理方式,实时性相对较弱,为近实时数据处理[5]。Flink是目前流行的流式处理系统,具有较好的实时性、吞吐能力、状态管理以及窗口处理能力,在流式处理方面功能支持完善,性能较好[6]。但是Flink的批处理和Python支持相对较弱,生态也不及Spark完善。
表1 Flink、Spark Streaming、Storm技术对比
FlinkSpark StreamingStorm 分布式处理是是是 支持UDF是是是 窗口处理能力强一般弱 处理吞吐能力强强一般 处理延时实时近实时实时 处理方式process at arrivemicro batchprocess at arrive 处理语义at-least-onceexactly-onceat-least-onceexactly-onceat-least-onceat-most-once 开发语言Java,PythonScala,Java,PythonJava SQL支持完整较完整部分 支持批处理是是否
综合分析得出Flink和Spark Streaming都能满足情报处理系统流式数据处理的要求。Flink虽然性能较优,但是批处理和Python支持较弱;Spark Streaming虽然是近实时数据处理,实时性不及Flink,但是在批处理和Python支持方面较强。考虑到系统中还需要数据分析批处理功能,并且Python是数据分析的主流语言,首选Spark Streaming作为情报系统的流式处理引擎。
2.3 系统设计

图2 数据处理架构
数据处理架构如图2所示,由数据缓冲、流式处理以及数据处理管道组成[2]。输入的数据首先写入Kafka缓冲并持久化,确保数据可靠落地。Spark Streaming程序读取Kafka相应的topic,执行完处理后再输出至Kafka特定的topic,输出的topic可以作为中间结果被其他的Spark Streaming程序读取,也可以通过数据处理管道分发至数据存储。Logstash提供数据处理管道功能,其功能完善稳定,拥有可扩展的插件生态系统,支持输出至多种数据存储,支持轻量的数据处理能力和数据丰富化功能,能实时的解析和转换数据[7]。
3 交互式数据查询和分析技术的应用
3.1 数据处理需求
为使安全分析人员能够高效、快速的查找和分析安全数据,系统须提供即席查询、数据仪表盘以及数据报表等功能。快速查询和分析的数据为系统的热数据,即近期落入系统的数据和常用的基础数据。查询时要求具有较好的人机交互功能,能快速响应用户的查询和统计分析。
3.2 技术选型
分析型数据库(OLAP数据库)能满足查询和统计分析的要求,目前主流的开源OLAP数据库有:ClickHouse[9]、Druid、ElasticSearch[8]、Kylin,其技术对比如表2所示。这几款数据库的实现原理各有不同,Druid和Kylin都采用了预聚合技术,但对明细数据的查询支持较弱;ElasticSearch采用了倒排索引,具有全文检索功能[8];ClickHouse是列式存储数据库,单机性能优秀[9]。Kylin的预聚合使用了数据立方体方法,聚合过程复杂且耗时,存在导入的数据在较长时间才能查到的问题,难以满足实时性要求。Druid的预聚合处理相对轻量,虽然满足实时性要求,但是在查询明细数据方面还存在不足,无法满足系统要求。ClickHouse和ElasticSearch基本上都满足系统的查询和统计要求,考虑到ElasticSearch可以配合开源的数据可视化和探索工具Kibana[10],能提供灵活易用的数据探索和分析功能,并且支持全文检索功能,而ClickHouse在数据可视化分析方面还不够成熟,ElasticSearch作为OLAP数据库的首选。
表2 OLAP数据库技术对比
ClickHouseDruidElasticSearchKylin 分布式集群支持支持支持支持 支持数据量大大中等大 实时性强强强弱 SQL支持中等弱弱标准 查询性能高高较高高 并发能力中高中高 预处理否是否是 全文检索不支持支持支持不支持 原始数据查询支持不支持支持不支持
3.3 系统设计
交互式数据查询与分析的系统架构如图3所示,ElasticSearch和Kibana为交互式数据分析的核心,ElasticSearch提供了数据存储、查询、统计分析的功能,Kibana提供了交互式分析的人机界面功能。导入ElasticSearch的有两类数据,一类数据来自流式数据处理,通过Logstash导入;另一类数据来自数据批处理,通过Spark程序导入。

图3 交互式数据查询与分析系统架构

图4 蜜罐最近1小时实时数据展示
流式数据中带有时间戳属性,导入ElasticSearch中可进行时间序列的统计分析,如数据的历史变化趋势、异常流量分析等。ElasticSearch数据库具有良好的实时性,导入的数据可以近实时地被查询到(亚秒-秒级),通过数据仪表盘可以近实时地展示系统的输入以及数据处理的运行情况。图4所示为蜜罐最近1小时的实时数据趋势,包括数据详细信息的展示。通过查询条件可以筛选过滤数据,查询条件使用灵活的ElasticSearch DSL语法,可以进行关键字匹配,也可以使用复杂的逻辑组合,数据查询功能完善。
Kibana提供了强大的数据可视化和探索功能,可以不用编程而直接使用界面配置出各种类型的图表,方便了安全分析人员进行数据分析。图5和图6为系统的部分统计分析图,图5展示了最近15天内每日情报数据的变化趋势和分布,清晰的展示出系统输出情报的概况;图6展示了最近一段时间蜜罐的流量分布,以及每个蜜罐的具体流量值。

图5 最近15天情报数据的趋势和分布

图6 蜜罐流量分析
4 数据湖和分布式数据处理技术的应用
4.1 系统存储和离线数据分析需求
存放在分析型数据库中的数据为系统的热数据,其数据量为GB~TB级别。而系统的全量数据的数据量为TB~PB级别,需要通过数据湖技术进行存储管理。数据湖能够支撑TB~PB级的存储,并提供类似传统数据库的表Schema管理、高效率的数据更新和删除以及ACID特性。考虑到系统的成本和数据安全性问题,数据湖须搭建在本地的多台通用服务器上,底层的数据存储使用Hadoop分布式文件存储系统HDFS。数据湖结合分布式查询引擎能进行高效的数据查询和分析,能支持交互式数据分析、离线分析以及应用复杂的数据处理算法进行数据挖掘。
4.2 技术选型对比
目前主流的开源数据湖有:Iceberg、Delta Lake和Hudi。Iceberg最初由Netflix公司开发,之后发展为Apache开源项目。Netflix最初为了替换Hive,解决Hive的缺陷而开发了Iceberg,设计抽象和通用性较好。Delta Lake由Databricks开发,有商业版本和开源版本,最初为了解决Lambda架构流批处理场景中所存在的问题,随后发展为功能完善的数据湖[11]。Hudi最初由Uber公司开发,之后发展为Apache开源项目。Hudi最初是为解决快速upsert存量数据问题和流式增量消费问题,后来发展为功能完善的数据湖。三种数据湖技术对比如表3所示,Iceberg在数据更新和删除、流式数据写入方面支持较弱;Delta Lake虽然和Spark计算引擎强绑定,但对Spark以及流批统一处理架构的支持较强;Hudi则在各方面技术较为均衡。
表3 数据湖技术对比
IcebergDelta LakeHudi upsert和delete数据片重写支持支持 表Schema管理支持支持支持 底层存储HDFS、S3HDFS、S3、Azure Data Lake Storage Hadoop、S3 ACID语义支持支持支持 Time travel支持支持支持 上层引擎Hive、Spark、PrestoSpark强绑定Hive、Spark、Presto 流式数据写入支持弱支持支持 小文件合并支持弱支持支持
支持上述三种数据湖技术的主流开源查询引擎有:Hive、Spark[5]和Presto。Hive是Hadoop生态中出现较早的结构化查询引擎,早期由于使用Map-Reduce作为计算引擎性能欠佳,但后期加入了Tez和Spark作为计算引擎,以及使用CBO和缓存技术,性能有所提升,目前还是一种主流的结构化分布式查询引擎。Spark是近年来发展较为迅速的计算平台,早期为非结构化的Spark RDD计算模型,后期发展为Spark SQL结构化查询引擎,在性能方面优化较大,并且生态完善。Presto是由Facebook开源的分布式SQL查询引擎,其设计目标是结束数据分析的两难选择:速度快但价格贵的商业方案和消耗大量硬件的慢速免费方案。这三个分布式查询引擎对比如表4所示。
表4 分布式查询引擎技术对比
Hive TezSpark SQLPresto SQL查询语言支持支持支持 交互式查询能力一般一般强 编程语言以SQL为主,其他语言支持较弱Python,Scala,R,Java以SQL为主,其他语言支持较弱 内存计算支持支持支持 ETL能力中等强弱
4.3 系统设计
由于系统需要具备较强的ETL批处理能力,并且除了支持SQL语言之外还需支持适合于数据分析的Python语言,Spark SQL是分布式查询引擎的首选。数据湖方面,Delta Lake与Spark SQL紧密集成,并且在数据湖其他特性上支持完善,Delta Lake为数据湖方案的首选。设计方案如图4.1所示,底层存储使用分布式文件系统Hadoop HDFS,分布式查询引擎运行于Hadoop Yarn之上,Delta Lake作为Spark插件与Spark紧密集成,用户可以使用SQL、Python和Scala等编程语言进行数据操作。Python是目前比较流行的数据分析语言,深受数据分析师和开发人员的喜爱,而PySpark支持在Spark平台上使用Python,并且提供了与数据分析库之间良好的转换接口,因此PySpark是数据批处理、数据探索分析、ETL以及数据建模的首选工具。

图7 数据湖和分布式查询引擎方案
5 结论
网络威胁情报系统是一个复杂的典型的大数据处理系统,涉及大数据技术领域的多个关键技术。在流式数据处理中,FLink和Spark Streaming都是成熟可靠的产品,历经多年的版本迭代和演化。在实时性和吞吐能力方面FLink有着明显的优势,这来自设计上的差异;Spark由于使用Micro Batching处理方法,实时性上稍微偏弱。而Spark生态完整、丰富,批处理方面做得更好,在实际应用中若流批需求共存,加上Python语言在数据分析中的流行,Spark方案通常为首选方案。在数据存储方面,以往的直接文件存储(基于分布式文件系统或对象存储系统)显露出越来越多的弊端,如文件修改不方便、并发写冲突、数据Schema难以维护等问题。数据湖技术是近几年来发展出的技术,目标是解决直接文件存储方法存在的问题,这些问题出现在各个公司的不同应用场景下,急待解决。本文使用的Delta Lake是Databricks公司的开源产品,支持的特性较为完善,是当前稳定可靠的一种数据湖方案。Iceberg和Hudi同样也是优秀的数据湖方案,他们的区别在于设计之初的目标和设计方案上的区别,目前都是活跃的项目,未来的发展可能在于目标的统一和多样化的发展。在数据可视化和探索领域,Elastic Stack是一款明星开源产品,来自商业公司,安装维护方面做得比较完善,易于使用。Elastic Stack项目比较活跃,版本更新较快,不断有新功能的加入,在OLAP数据库、数据可视化、数据探索需求共存的场景下,通常成为首选方案。由于研究时间和作者的水平有限,本研究可能存在不够全面、深度不足等问题,若有问题希望读者给予指正。
[1]360威胁情报中心. 威胁情报的上下文、标示及能够执行的建议[EB/OL]. http://www.secrss.com/articles/6062,2018.
[2]黄必栋. 网络威胁情报处理系统的设计与开发[J]. 网络安全技术与应用,2020(8):61-63.
[3]Structured Streaming Programming Guide[EB/OL]. http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html.
[4]Apache Storm [EB/OL]. https://storm.apache.org/.
[5]Michael Armbrust,Tathagata Das,Joseph Torres. Structured Streaming:A Declarative API for Real-Time Applications in Apache Spark[J]. SIGMOD,2018.
[6]Apache Flink[EB/OL]. https://flink.apache.org/.
[7]How Logstash Works[EB/OL]. https://www.elastic.co/guide/en/logstash/current/pipeline.html.
[8]Elasticsearch Reference[EB/OL]. https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html.
[9]ClickHouse[EB/OL]. https://clickhouse.tech/.
[10]Kibana Guide[EB/OL]. https://www.elastic.co/guide/en/kibana/current/index.html.
[11]Delta Lake[EB/OL]. https://docs.delta.io/latest/index.html.
