基于空间变换的属性可编辑的人体图像合成
2022-03-22魏程峰董洪伟徐小春
魏程峰,董洪伟,徐小春
江南大学 人工智能与计算机学院,江苏 无锡 214122
人体图像合成(PIS)具有广泛的潜在应用价值,例如电影制作、虚拟试衣和图像编辑等。尽管生成对抗网络(generative adversarial networks,GAN)在图像合成领域已经取得显著的成果,能够合成真实的图像,但是人体图像合成仍然是一个具有挑战性的问题,例如,当衣服上存在图案时,纯卷积结构的生成对抗网络就无法很好地生成它们,因为卷积神经网络对输入的数据具有平移不变性,这限制了其对数据进行空间重组的能力。对于人体图像合成的研究目前大多集中在人体姿态的编辑,但是人体属性并不是只有姿态,还有人体外观属性(如:人脸、头发、衣服和裤子等)针对这些属性的编辑所做的研究还相对较少,效果也不能令人满意。
为了解决上述问题,本文通过对输入的人体图像进行语义分割来实现人体外观属性的分离,通过替换其中的某些属性来实现外观属性的编辑,通过提出新的空间变换算法来对多个外观属性特征进行空间变换,并将它们融合为目标人体图像,有效保留了衣服上的纹理与图案。实验发现,本文提出的方法实现了同时编辑姿态、外观等属性的目的,并且得到的结果具有较好的视觉效果。
1 相关研究
1.1 图像空间变换
图像空间变换通过改变源图像中像素点的空间位置坐标来得到目标图像,但由于卷积神经网络对输入的数据具有平移不变性,这一特性限制了其空间变换的能力,因此有很多增强其空间变换能力的方法被提出。Jaderberg等人[1]提出了空间变换器网络(STN),其使用了可学习的空间变换模块,用于估计全局转换参数并且使用仿射变换在特征级别进行变换。Lin等人[2]在STN的基础上提出在网络中传送变换参数而不是变换后的特征,在所有的对准模块中使用相同的几何预测器以避免采样错误。Jiang等人[3]提出线性化多采样方法以解决双线采样在尺度变化较大的情况下表现较差的问题。全局空间变换方法由于对全局特征采用相同的变换参数,无法处理像人体等可以发生形变的目标,基于流场的方法能够对每一个特征点进行偏移,使用起来更为灵活。Zhou等人[4]提出Appearance flow用于预测源与目标之间的流场,通过对源图像进行变换来生成目标图像,但是该方法在像素级别对图像进行变换,而不是特征级别,使其难以捕捉较大的动作和生成新的内容。Wang等人[5]以监督的方式训练流场估计网络,并使用生成对抗网络来生成人体自遮挡部分的内容。Siarohin等人[6]提出将关键点定位在物体的刚性位置,通过输入稀疏的关键点来获得密集的流场。
1.2 姿态引导的人体图像合成
姿态引导的人体图像合成通过输入一幅源人体图像和一组目标姿态的关键点,得到一幅目标姿态的人体图像,同时具有源图像的外观。Ma等人[7]提出一个二阶段方法,在第一阶段合成一幅粗糙的人体图像,然后在第二阶段对该粗糙的人体图像进行完善,得到更为精细的结果。Esser等人[8]将变分自动编码器和条件U-Net相结合对人体进行建模,然而,U-Net中的跳连接会引起特征错位,影响生成结果。Siarohin等人[9]通过将U-Net中的跳连接改为可变形的跳连接后缓解了这一问题,但是可变形的跳连接需要预定义,使得这一方法的应用受到限制。Zhu等人[10]提出在生成器中使用级联的姿态注意力转换模块对源人体图像进行转换。Han等人[11]使用基于流的方法对输入的像素进行变换,但是在像素级别进行变换无法生成新的内容,因此也无法处理人体自遮挡的情况。为了解决了上述问题,本文提出了新的空间变换算法在特征级别进行空间变换,取得了较好的结果。
2 本文方法
本文提出的方法允许用户对各个人体属性进行控制(如姿态、衣服、裤子和头发等),并合成高质量的人体图像。通过使用预训练的语义分割方法,将不同的人体外观属性进行分离并将它们输入外观属性编码网络中,得到各个属性的特征,通过提出新的空间变换算法对这些属性特征进行变换与组合,从而达到控制合成结果的目的。生成器整体结构如图1所示。本文的方法主要由五个网络所组成,分别是流场估计网络、语义合成网络、外观属性编码网络、人体图像合成网络和判别器网络。流场估计网络用于估计源人体图像与目标人体图像中相同特征之间的空间位置的坐标偏移量以及自遮挡情况,并以流场和掩码的形式表示。语义合成网络用于合成目标人体的语义分割图,该语义分割图用于在人体图像合成阶段进行像素级别的特征选择,保证最终合成的人体图像的质量。外观属性编码网络对源人体图像中的各个外观属性进行编码,得到各个属性的特征,在后续阶段将对这些特征进行空间变换,以合成目标人体图像。人体图像合成网络是本文的主干网络,该网络接收其他网络的输出,用于合成高质量的目标人体图像。

图1 生成器整体网络结构Fig.1 Overall network structure of generator
2.1 流场估计网络
流场估计网络E用于估计源人体外观属性与目标人体外观属性中相同特征之间的空间位置偏移量,以及人体自遮挡情况,然后分别以流场和掩码的形式输出。该网络将源人体外观属性XS,源人体姿态PS和目标人体姿态PT作为输入,然后输出预测的流场W,遮挡掩码M和特征图F。网络的超参数配置如图2所示,不同的上角标代表不同的分辨率。
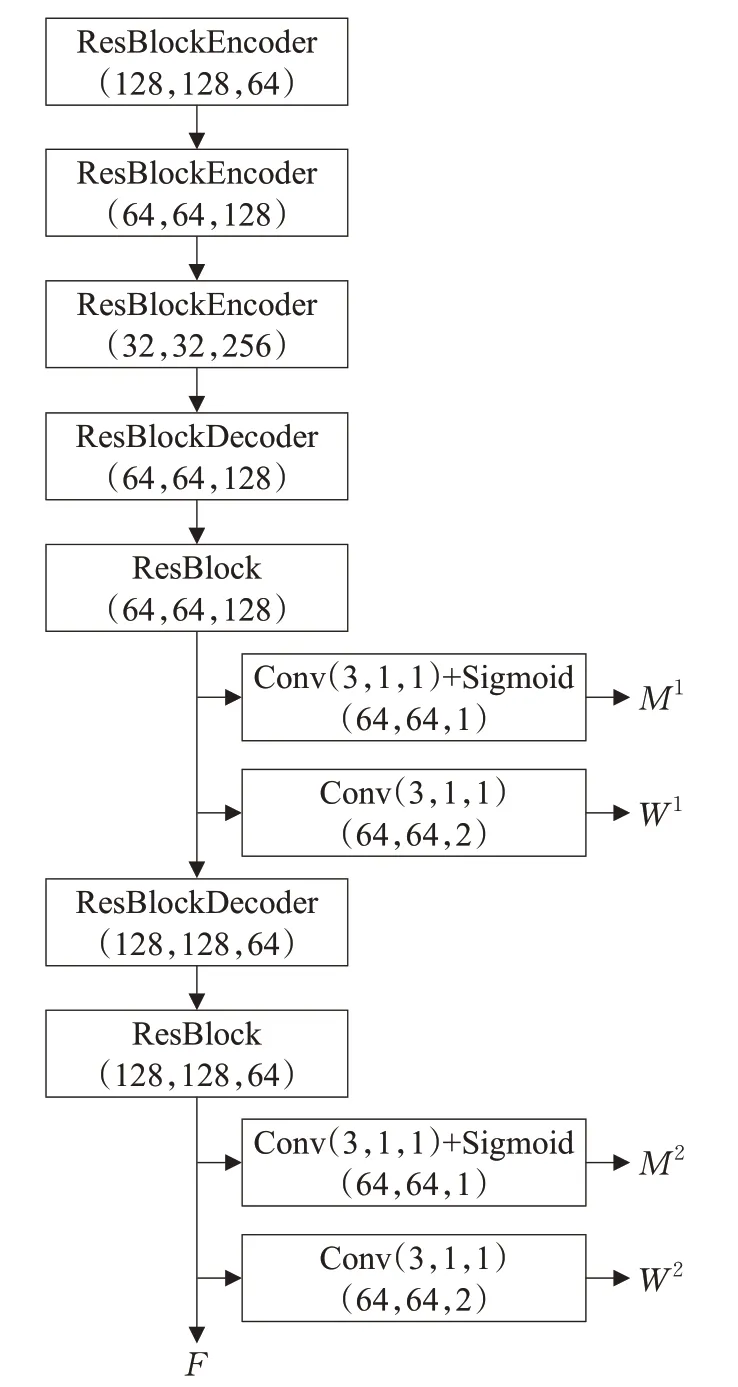
图2 流场估计网络超参数配置Fig.2 Flow field estimation network hyperparameter configuration

流场W中包含了目标属性中每一个特征的坐标对应于源属性特征坐标的偏移;掩码M用于表示目标属性中的内容是否被遮挡,如果没有被遮挡,则从源属性中得到特征,如果被遮挡,则从生成对抗网络中生成;特征图F将作为后续语义合成网络的输入。
本文的流场估计网络是在特征级别进行估计,而不是在像素级别,在特征级别进行估计可以降低估计的难度,并且模型可以生成新的内容。为了保证在特征级别采样的正确性,防止陷入局部最小,本文引入了采样正确性损失函数[12],该损失函数用于测量两个特征之间的相似性,即转换后的源属性特征和目标特征,源属性特征VS和目标特征VT是分别将XS和XT送入预训练的VGG网络后得到的。

采样正确性损失函数可以约束流场在源属性特征与目标特征的语义相似区域采样,但由于相邻的特征具有相似性以及空间关系,这就会导致局部区域的采样出现错误,因此,本文引入一个正则化项用于惩罚局部区域的采样问题,使得局部区域的变换符合仿射变换。使用CT表示目标特征的坐标矩阵,源特征的坐标矩阵CS可以表示为CS=CT+W。使用Nn(CT,l)表示在坐标矩阵CT中以l为中心提取n×n大小的矩阵块。该正则化项使得矩阵块Nn(CT,l)和Nn(CS,l)之间的变换符合仿射变换。

2.2 语义合成网络
本文提出的方法并不只是控制姿态这一个属性,还可以控制人体外观属性,这就意味着这些属性需要被分离,替换并单独输入网络,然后再重新组合在一起生成新的高质量人体图像。虽然流场可以将源属性变换到目标属性,但是当进行外观属性编辑时,这些源属性是由不同人体图像的外观属性组合而成,这就意味着转换后的各个属性之间很难完美的配合,可能会出现重叠之类的情况(例如长头发可能会与衣服发生重叠)会导致最终的结果变差。因此,本文在流场估计网络之后又增加了语义合成网络,语义分割可以很好地明确各个属性的边界使得属性之间可以完美配合,获得较好的最终结果。网络的超参数配置如图3所示。
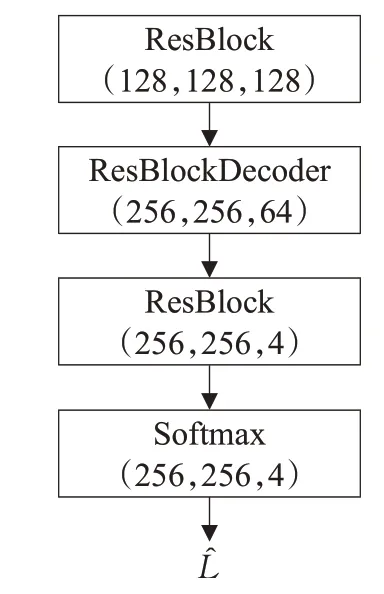
图3 语义合成网络超参数配置Fig.3 Semantic synthesis network hyperparameter configuration
语义合成网络H将流场估计网络对各个属性输出的特征图进行连接后作为输入,并输出目标人体图像的语义分割图。

2.3 外观属性编码网络
由于本文选择在特征级别进行空间变换,而不是在像素界别,因此需要对外观属性进行编码,外观属性编码网络C将外观属性XS作为输入,得到该外观属性的特征FS。这些特征在经过空间变换后用于目标人体图像的合成。网络的超参数配置如图4所示,不同的上角标代表不同的分辨率。

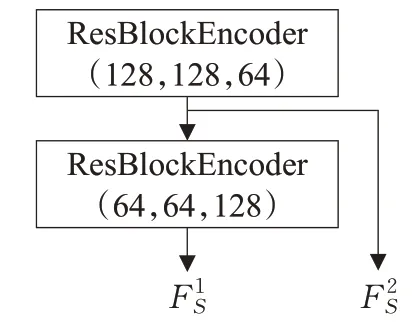
图4 外观属性编码网络Fig.4 Appearance attribute encode network
2.4 人体图像合成网络
人体图像合成网络G是本文的主干网络,用于生成高质量的人体图像。该网络由编码器和解码器组成,编码器对目标人体姿态PT进行编码,得到特征图FT。解码器根据语义分割图L^在源外观属性特征FS中进行选择,根据流场W和掩码M对该特征进行变换与融合,最后得到具有特定外观属性的目标人体图像。网络的超参数配置如图5所示。


图5 人体图像合成网络超参数配置Fig.5 Person image synthesis network hyperparameter configuration
由于基于纯卷积的生成对抗网络无法清晰地合成衣服上的图案与纹理,导致先前的方法对有图案的衣服进行转换时效果较差。受到文献[13]的启发,本文提出了新的特征空间变换算法,该算法根据输入的语义分割图L^从多个源外观属性特征FS中选择相对应的外观属性特征,根据对应的流场W对所选择的特征进行空间变换。使用本文提出的特征空间变换算法可以对被分离的各个源属性特征分别进行空间变换后再组合到一起,从而实现了外观属性编辑的目的。
本文使用CUDA在Nvidia GPU上实现该特征空间变换算法,以加快网络的训练和推理速度,基于该算法的特征空间变换模块如图6所示,其伪代码实现如算法1所示。

图6 特征空间变换模块Fig.6 Feature spatial transformation module
算法1特征空间变换算法


为了使合成的图像更加真实,本文加入了基于内容感知的局部注意力模块,该模块分别对变换后的特征图FS′和目标特征FT以空间坐标l为中心,提取3×3大小的特征块Nn(FS′,l)和Nn(FT,l),将两个特征块连接后输入局部注意力网络A得到注意力掩码Kl。
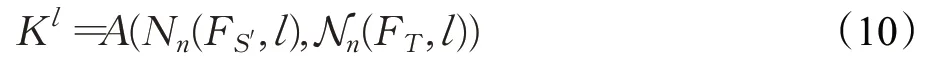
注意力掩码Kl需要与特征块Nn(FS′,l)进行逐元素相乘,最后进行平均池化得到局部注意力特征图在坐标l处的特征

其中,AP表示平均池化操作,⊗表示逐元素相乘操作。为了得到整个局部注意力特征图,需要遍历空间坐标得到每个坐标处的特征,最后组合成整个特征图FAttn。局部注意力模块如图7所示。

图7 局部注意力模块Fig.7 Local attention module
然而,人体很容易出现自遮挡的情况,对于没有被遮挡的部分可以从源属性特征中得到,对于被遮挡的部分则需要让网络合成。流场估计网络得到的遮挡掩码M用于指示当前坐标的内容是可以在源属性中找到的还是需要合成的。

目标人体图像特征的掩码Mfull并不能通过各个属性的掩码相加得到,而是需要先将语义分割图进行分离与处理,然后与各个属性的掩码进行逐元素相乘后再相加,以避免掩码之间的互相干扰。

最终的人体图像特征Fout可以通过掩码Mfull在特征图FT与特征图FAttn之间进行选择得到。得到了特征图Fout之后,需要将其送入上采样层以得到最终的人体的图像,为了避免在最终的结果中出现棋盘状伪影,本文采用最近邻插值与卷积而不是转置卷积。
人体图像合成网络在多个损失函数的共同约束下进行训练。

l1loss计算生成的目标人体图像与真实人体图像之间的l1距离误差。

Adversarial loss[14]以对抗的方式来学习真实数据的分布,使得生成的数据与真实数据的分布相接近。

Perceptual loss[15]用于计算目标图像的特征和生成图像的特征之间的l1距离,这两个特征图可以通过提取预训练VGG网络的特定激活层的输出得到。

3 实验结果与分析
3.1 实验细节
数据集:本文使用DeepFashion[16]作为数据集,该数据集包含了52 712幅各种姿态的人体图像,使用256×256分辨率进行训练,将不同姿态的人体图像进行配对后再随机划分101 966对作为训练集,8 750对作为测试集。
数据预处理:为了分离人体外观属性,本文使用人体语义分割算法[17]对人体图像进行分割,将人体图像分为头部、身体和腿部三个部分,同时也将表示姿态的关键点分为这三个部分。如图8和图9所示。

图8 人体语义分割Fig.8 Semantic segmentation of human body
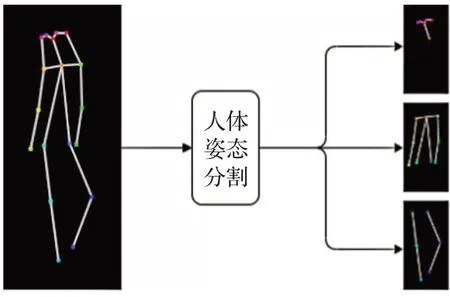
图9 人体姿态分割Fig.9 Human posture segmentation
网络参数设置:本文提出的方法除了包含流场估计网络、人体图像合成网络、外观属性编码网络和语义合成网络外,还包含了判别器网络,判别器网络的超参数设置如图10所示。
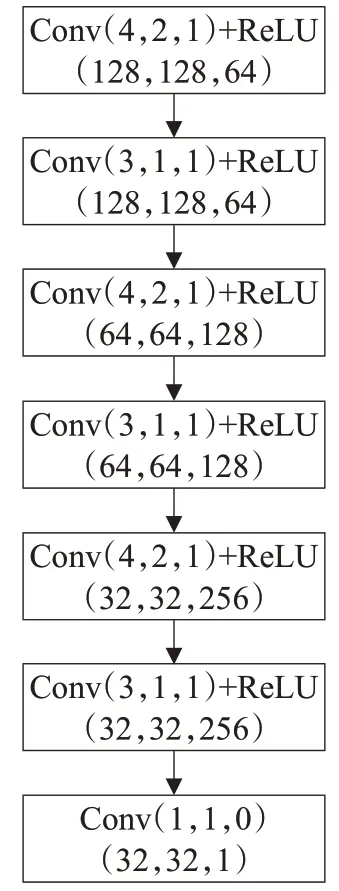
图10 判别器网络超参数配置Fig.10 Discriminator network hyperparameter configuration
训练方法:本文的实验在一块NVIDIA P100 16 GB显卡上进行,网络模型使用PyTorch框架进行编写,使用Adam作为优化器,β1和β2分别设置为0.0和0.999,生成器和判别器的学习率分别设置为0.000 1和0.000 01。为了加快整个网络的收敛速度,本文首先对流场估计网络和语义合成网络进行预训练,待这两个网络收敛之后再加入人体图像合成网络进行整体训练,整个网络迭代训练50个epochs后收敛。整个训练过程中batchsize设置为8,损失函数的权重设置为λC=5,λR=0.002 5,λl1=5,λadv=2,λprec=0.5,λstyle=500和λlayout=6。
3.2 实验结果
为了对本文提出的方法进行评估,本文选择目前人体图像合成领域较为先进的LiquidWarpingGAN[18]和ADGAN[19]进行对比。其中,能够针对人体图像的姿态与外观属性(如:头部、衣服和裤子等)同时进行编辑的情况目前仅有ADGAN可以做到。
图11~13展示了同时对人体图像中的姿态与外观属性进行编辑的情形,相比于ADGAN,本文的方法得到的结果有更清晰的纹理,在编辑某一个外观属性的时候也不会破坏其他的外观属性。

图11 头部属性变换Fig.11 Head attribute transform
图14展示了只对人体图像中的姿态属性进行编辑的情形,相比于其他两种方法本文提出的方法可以较好地保留衣服上的纹理以及衣服的样式,合成的整体效果较好,更具真实性。
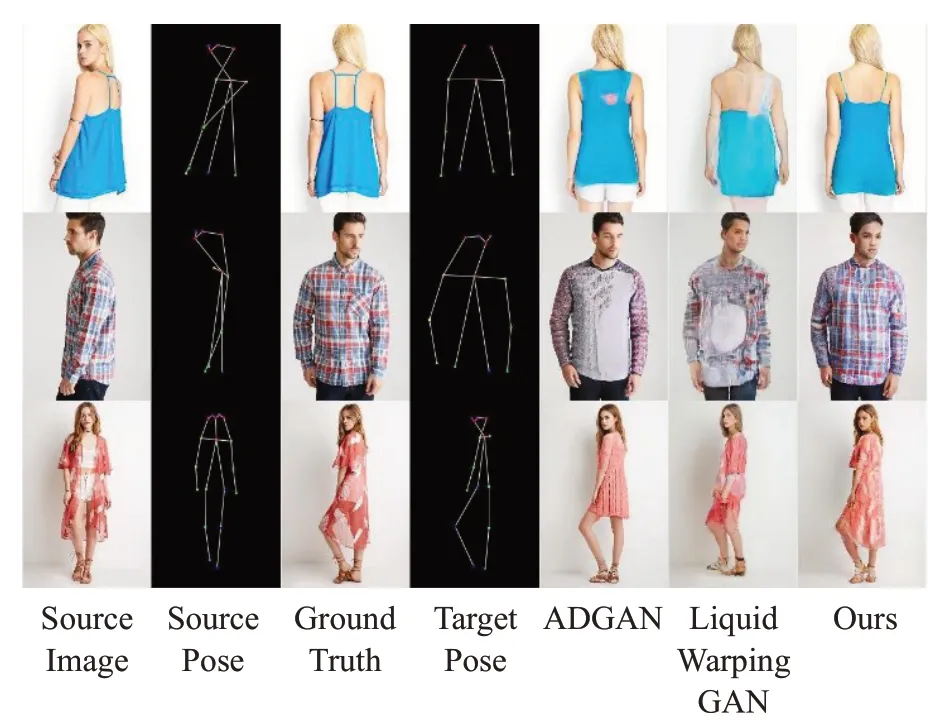
图14 人体姿态变换Fig.14 Human posture transform
本文通过加入语义合成网络实现了从人体关键点到人体语义分割图的转换,特征空间变换模块通过合成的语义分割图从特定的源属性中提取特征,因此,语义分割图合成的好坏程度就决定了特征选择的正确程度,也决定了最终人体图像的合成质量,人体语义分割图合成的效果如图15所示。

图15 语义生成网络的结果Fig.15 Result of semantic generating network

图12 上身属性变换Fig.12 Upper body attribute transform
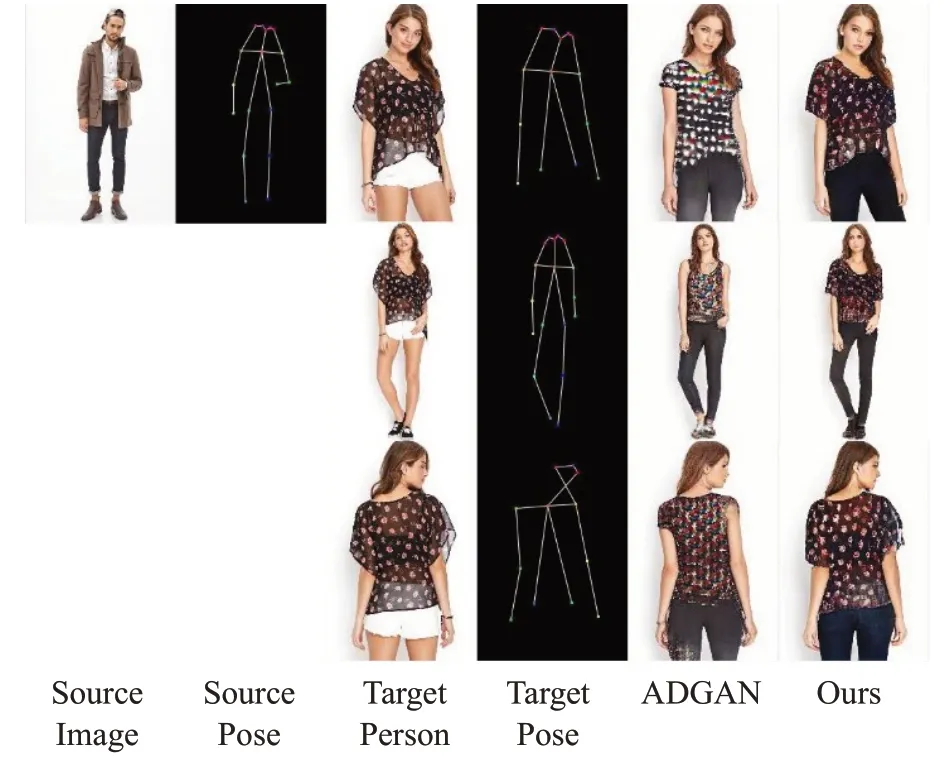
图13 下身属性变换Fig.13 Lower body attribute transform
在客观评价指标方面,本文选择FID和SSIM两个评价指标来对模型进行评估,由表1可知本文提出的方法在FID评价指标上超越了先前提出的方法,取得了较好的结果。

表1 评估结果比较Table 1 Comparison of evaluation results
3.3 消融研究
为了证明本文方法的有效性,进行了消融实验,用于对比的模型去掉了本文提出的语义合成网络,并将本文提出的特征空间变换算法替换为文献[13]中使用的算法。实验结果如图16所示,第一行表示将源图像中的衣服变换到目标人体图像上,第二行表示对源人体图像的姿态进行变换。从实验结果可以看出本文提出的方法只改变目标属性,不会破坏其他属性,证明了本文提出的方法是可行的。

图16 消融研究结果对比Fig.16 Comparison of ablation study results
此外,由算法1可知本文提出的算法只对人体图像所在的像素点进行空间变换,这样做不仅可以获得更好的变换效果,还可以提高推理和训练时的计算效率。两种算法运行的帧率如表2所示,证明了本文提出的方法更加高效。

表2 算法效率比较Table 2 Comparison of algorithm efficiency
4 结束语
针对现有人体图像合成方法无法灵活地编辑人体外观属性的问题,本文使用图像分割技术对人体外观属性进行分离,替换这些属性以实现外观属性编辑的目的,通过提出新的特征空间变换算法实现将多个外观属性特征合成为人体图像,并且可以保留各个属性的外观细节。实验结果表明本文提出的方法可以有效地编辑人体外观及姿态等属性,相比于其他方法本文的方法合成的人体图像能够保留衣服上的纹理和图案,合成的图像更加清晰,有更好的视觉效果。但由于人脸所占的像素比较少,导致脸部区域合成效果较为不佳,接下来将进一步增强人脸合成的效果。
