基于改进Efficientdet的自动驾驶场景目标检测
2022-03-22李彦辰张小俊张明路沈亮屹
李彦辰,张小俊,张明路,沈亮屹
河北工业大学 机械工程学院,天津 300401
近年来,深度学习被广泛应用于各个领域,计算机视觉[1]逐渐成为其中的佼佼者。驾驶场景实时检测已经成为计算机视觉领域中的研究热点问题。目标检测作为自动驾驶中最基本的环节,为车辆采集实时的环境信息,以确保安全和提供正确的规划决策[2]。基于深度学习的目标检测和语义分割算法在自动驾驶领域中已经表现出独有的优势,可以在使用较少计算资源的前提下获得较高的检测精度,因而成为自动驾驶系统中必不可少的方法[3]。
目前常用的目标检测框架分为两大类,一类是Girshick等人提出的R-CNN[4]、Fast R-CNN[5]和Faster R-CNN[6]等两阶段目标检测算法,另一类是Redmon等人提出的Yolo[7]、SSD[8]等单阶段目标检测算法。单阶段算法的检测速度基本可以满足驾驶场景下的实时性要求,但其检测精度低于两阶段检测器。近年来,许多模型效率较高的单阶段算法被应用于驾驶场景中,如Yolov3[9]、Centernet[10]、Retinanet[11]等。目标检测算法在自动驾驶应用的先决条件是处理速度要高于30 frame/s。虽然上述方法可以进行实时检测,但却以低分辨率输入作为代价,应用于自动驾驶中依然十分困难。这就是说,平衡检测算法的速度和精度仍旧是实际应用中一个最主要的问题。
此外,大部分之前的研究仅关注某个或某些特定的资源要求,而大量现实应用(从移动设备到数据中心)通常具备不同的资源限制。自动驾驶计算平台的计算资源和内存有限,又需要同时处理多个传感器和计算任务,如检测、跟踪与决策。因此,神经网络设计的最新趋势应是探索便携式和高效的网络架构,应用于车载平台的检测算法需要具有相对小的内存和计算资源占比。同时,大多数传统目标检测算法最关键的问题是无法有效地处理多尺度特征。通常大目标很容易被检测到,而小目标通常被忽略,这在自动驾驶的情况下非常危险。因为它会导致过度反应,从而降低驾驶的稳定性和效率,造成致命事故[12]。
针对上述问题,本文选取Efficientdet[13]网络作为基准模型,结合Ghost[14]模块重构了原主干网络Efficientnet[15]中的倒转残差瓶颈MBConv,在加权双向特征金字塔网络[13](bi-directional feature pyramid networks,Bi-FPN)前设计了多尺度注意力机制模块。相较于之前的目标检测算法,改进后的模型使用更少的参数实现了更先进的精度。不但可以在车载平台上轻松部署并实现快速推理,且进一步提高了对小目标检测精度。与此同时,作为一种模型效率高且支持复合缩放的目标检测算法,其在广泛的资源约束下始终比现有技术获得更好的效率,在自动驾驶检测领域中有着巨大的发展潜力。
1 Efficientdet网络概述
Efficientdet是2020年谷歌大脑(Google brain)团队提出的目标检测模型,是一系列可扩展高效的目标检测器的统称,其网络架构如图1所示。其中主干特征提取网络为Efficientnet,并沿用其复合缩放(compounding scaling)方法。Bi-FPN作为特征融合网络,引入了可学习的权重来学习不同输入特征的重要性。预测网络由分类预测网络和回归预测网络组成,两个网络共享特征网络的权重。
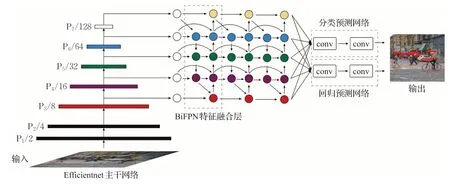
图1 Efficientdet-d0算法网络结构图Fig.1 Efficientdet-d0 algorithm network
Efficientdet最重要的贡献是将Efficientnet复合缩放的思路进行延伸,把架构决策明确化为可扩展的框架,并且为不同的应用场景提供了d0到d7共8种模型。使用者无需复杂调参,便能轻松应用于目标检测中的多种应用。针对自动驾驶车辆,Efficiendet系列的优势在于,可以根据真实环境中软硬件的性价比与对精度和效率的实际需求,来选择不同的检测框架,以设计出更高效的自动驾驶应用检测器。
然而,在Efficientdet系列d0~d7的8个模型中,随着网络的精确度逐代提高,计算量也会相应增大。一个典型的真实道路检测场景如图2所示,Efficientdet d0~d3的检测速度虽然满足实时性要求,但它们对于小目标的检测精度无法完全满足应用在自动驾驶场景的要求。从图2(a)中可以看出,当车辆处于远端视线,目标变小时,检测器精度随之下降。Efficientdet d4~d7的检测精度虽然逐代提高,但其计算资源占用量较大,不能满足自动驾驶车辆对检测算法小内存和低计算资源的需求。图2(b)中的小目标虽被很好地检测出来,但却以加大计算量和牺牲速度作为代价。

图2 真实道路场景目标检测Fig.2 Real road scene object detection
为了解决这一问题,可以在利用Efficientdet系列多样性的同时,对Efficientdet自身架构加以改进,设计出一种在自动驾驶应用中更有效的检测器。本文将以Efficientdet-d0作为基准,改进主干网络以降低网络复杂度,提出一个模型综合效率更高并且满足现实车载计算平台部署的Efficientdet系列。
2 Efficientdet-Gs网络模型
大多数单阶段目标检测算法通常包括主干网络、特征融合网络以及预测网络。本文对Efficientdet-d0的主干网络Efficientnet-b0进行了详细修改,引入了Efficientnet-Gs-b0作为原网络的改进版本。后在特征融合网络Bi-FPN前设计了多尺度注意力机制模块,并于训练过程中引入了Balanced L1 Loss[16],修改后的版本d0将在本文用作基准模型。改进后的目标检测算法称为Efficientdet-Gs系列,是一种多尺度、实时、可部署的自动驾驶道路场景下的检测器。
2.1 主干网络改进
Efficientdet的整体框架如图1所示。Efficientnet作为其主干网络,是一系列快速高精度的优秀框架(Efficientnet b0~b7)。复合缩放(compounding scaling)是整个Efficientnet系列的核心,通过定义尺度化参数φ,Efficientnet将深度d、宽度w、分辨率r均统一在参数φ的旗下,受φ统一控制,来达到对三者动态调整的目的。由于具备这一标准化的卷积神经网络扩展方法,Efficientnet系列既可以通过模型扩展实现较高的准确率,又可以通过模型压缩节省一定的算力资源。但考虑到目前自动驾驶场景的现实条件,仅利用复合缩放存在着软硬件性价比的问题。为了完成复杂交通环境下大部分的特征提取任务,Efficientnet自身网络结构的优化仍显得尤为关键。
Efficientnet-b0的网络架构如表1所示,Stage1是一个卷积核大小为3×3的普通卷积层,其中包含批量标准化(batch normalization,BN)和Swish激活函数。Stage2~Stage8都是在重复堆叠MBConv结构。Stage9由一个普通的1×1的卷积层,一个平均池化层和一个全连接层组成。如图3所示,MBConv[15]正是Efficientnet的核心部分,总体的设计思路是倒转残差结构(inverted residuals),在3×3或者5×5深度可分离卷积结构前利用1×1卷积升维,在深度可分离卷积后增加了SE net[17](squeeze-andexcitation networks),最后利用1×1卷积降维后增加一个残差边。

表1 Efficientnet-b0的网络架构Table 1 Efficientnet-b0 network architecture

图3 MBConv结构Fig.3 MBConv structure
自动驾驶场景中,神经网络的研究更趋向于移动设备上的应用,MBConv中大量的1×1卷积仍存在较高的计算量,SE net被证明在移动端设备上支持欠佳[13],以上均为Efficientnet应用于车载平台制造了阻碍。为了克服应用中的资源限制,使深度神经网络可以在车载计算平台上更好地完成部署,同时为模型扩展提供现实可行性,本文利用Ghost模块、ECA net[18](efficient channel attention networks)和通道混洗[19](channel shuffle)对MBConv进行重构,重构的MBConv如图4所示。
在重构的MBConv中,本文首先利用Ghost模块取代起到升降维作用的1×1普通卷积。普通卷积操作如公式(1),X∈Rc×h×w为输入数据,Y∈Rh′×w′×n为输出的n维特征图,f∈Rc×k×k×n为该层的卷积核,可得该层的计算量为n×h′×w′×c×k×k,这个数值通常会成千上万。公式(1)的参数量与输入和输出的特征图数息息相关,而一般卷积中的输出特征图又存在大量冗余,且存在相似的特征(Ghost),所以完全没必要使用大量的浮点运算次数(floating point operations,FLOPs)和参数生成这些冗余特征图。
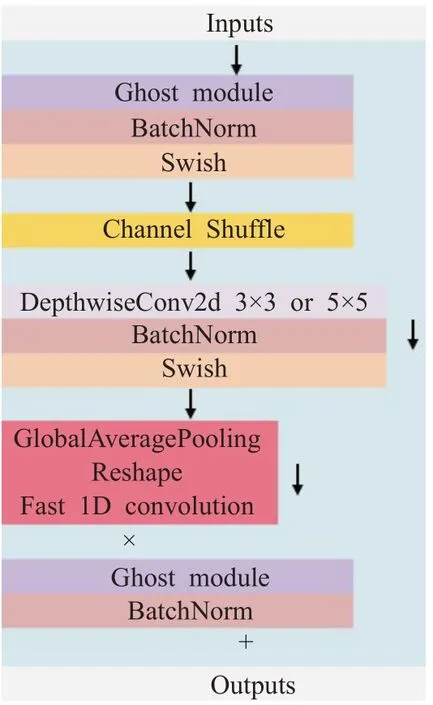
图4重构的MBConvFig.4 Reconstructed MBConv

Ghost模块的主要功能如下。首先,第一部分涉及普通卷积,假设原输出的特征为某些内在特征进行简单的变换得到Ghost,通常这些内在特征数量都很少,并且能通过原始卷积操作公式(2)获得,Y′∈Rh′×w′×m为原始卷积输出,f′∈Rc×k×k×m为使用的卷积核,由于m≤n,为简单起见,bias直接被简化。

同时,在第二部分中,为了获得原来的n维特征,对第一部分中Y′的内在特征分别使用一系列简单线性操作来产生s维Ghost特征。在公式(3)中,Φi,j为生成′的j-th Ghost特征图的线性变换函数,最后的Φi,s为保存内在特征的特殊映射(identity mapping),整体计算过程如图5所示。
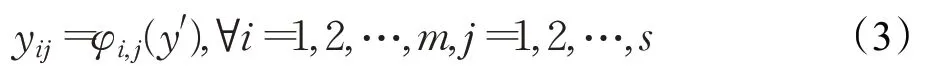
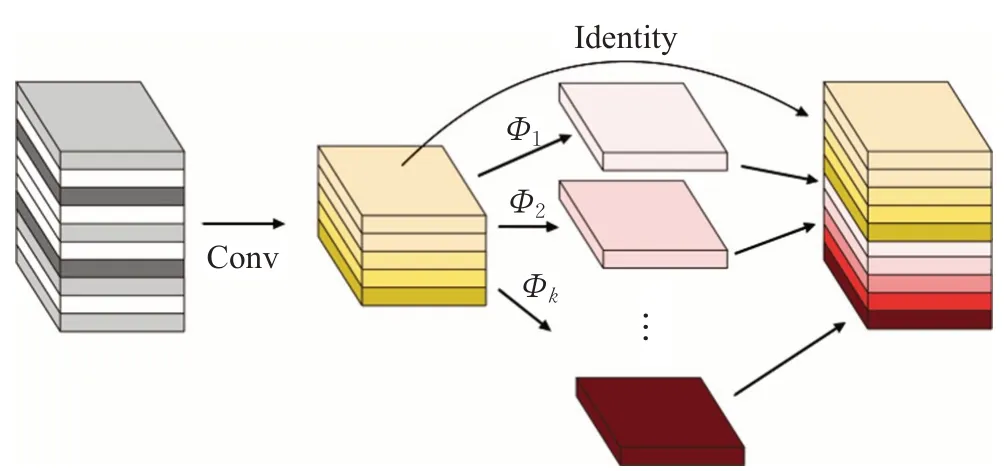
图5 Ghost模块Fig.5 Ghost module
与普通卷积神经网络相比,在不改变输出特征图大小的情况下,该Ghost模块中所需的参数总数和计算复杂度都有所降低。如表2所示,在与现有优秀轻量型网络MobileNetV2[20]、MobileNetV3[21]在MS COCO数据集的对比中,以Ghost模块为核心所组成的GhostNet计算成本显著降低,且保持着相似的目标检测精度。由此可知,Ghost模块能够在保持相似识别性能的同时降低通用卷积层的计算成本,为移动设备(例如智能手机和自动驾驶汽车)提供可接受的性能,满足在嵌入式设备上部署神经网络的需要。
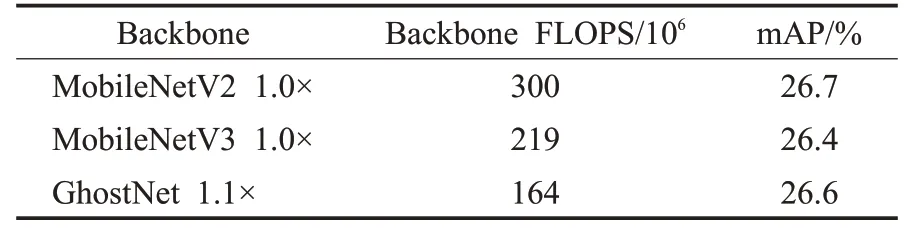
表2 MS COCO数据集结果对比Table 2 Comparison of MS COCO data set
此外,本文采用ECA net替代原MBConv中的注意力机制SE net。ECA net是一种适用于深度神经网络的高效通道注意力模块,相比于SE net,该模块避免了降维,并能有效捕捉跨通道交互。如图6所示,在没有降维的通道式全局平均池化之后,ECA net通过考虑每个通道的旁路来捕获本地跨通道交互。ECA net通过大小为k的快速1D卷积来有效地实现,其中内核大小k表示本地跨通道交互的覆盖范围。为了避免通过交叉验证手动调整k,其采用一种自适应确定k的方法,其中交互覆盖(即内核大小k)与通道维度成比例。ECA net引入了更少的附加参数和可忽略的计算,不但在移动端计算设备上支持更好,同时带来了显著的性能增益。
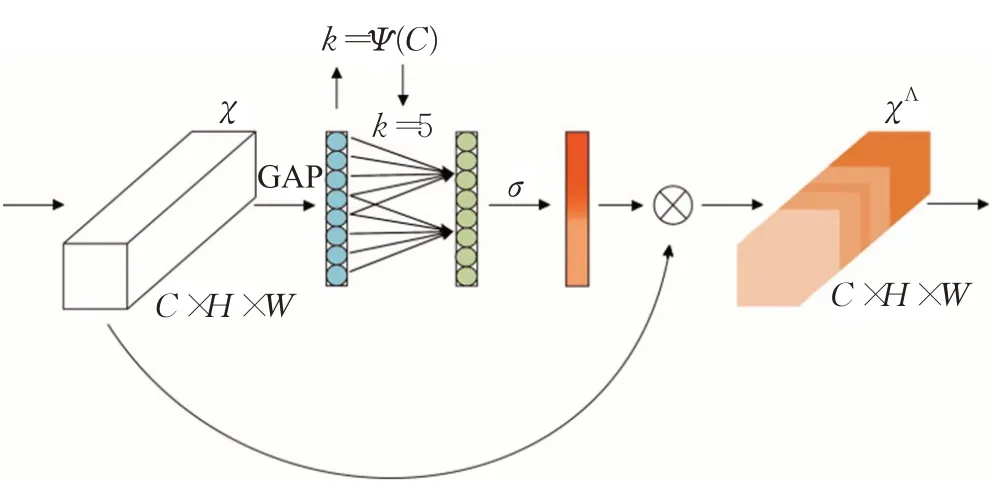
图6 ECA模块Fig.6 ECA module
综上所述,本文采用Ghost模块取代了原MBConv中占用大量内存和FLOPs的1×1卷积,以满足车载计算平台有限的内存及计算资源。随后,采用ECA net代替SE net,在带来精度提升的同时,进一步降低了模型的复杂性,以便于实现在移动端的部署。然而,Ghost模块可能会导致普通卷积与Ghost映射中的信息得不到交换,从而一定程度上削弱模型的性能。因此,为了克服其带来少量的副作用,本文在升维卷积后加入通道混洗(channel shuffle)来帮助信息在特征通道之间流动,如图4所示。最终,在图7中,这个改进后的主干网络称为Efficientnet-Gs系列,其旨在减少计算和存储成本的同时保持高效的特征提取能力及复合缩放特点,来实现自动驾驶场景下应用的目标。

图7 Efficientdet-Gs-d0算法结构图Fig.7 Efficientdet-Gs-d0 algorithm network
2.2 特征融合网络优化
特征金字塔融合网络[22](feature pyramid networks,FPN)是2017年提出的一种网络。FPN主要解决的是物体检测中的多尺度问题,通过简单的网络连接改变,在基本不增加原有模型计算量的情况下,大幅度提升了小物体检测的性能。Efficientdet中的Bi-FPN在PANet[23](path aggregation network)的基础上提出了跨尺度连接的优化方法,即高效的双向跨尺度连接和加权特征融合。Bi-FPN为每个输入增加一个权重,并让网络学习每个输入特性的重要性。
SRM[24](style-based recalibration module)作为一种基于风格的重新校准模块,通过利用中间特征图的风格来自适应地重新校准中间特征图。如图8所示,该方法首先通过风格池从特征映射的每个通道中提取风格信息,然后通过独立于通道的风格集成来估计每个通道的重新校准权重。通过将单个风格的相对重要性结合到特征地图中,SRM有效地增强了卷积神经网络的表示能力。该模块直接馈入现有深度神经网络架构,开销往往可以忽略不计。
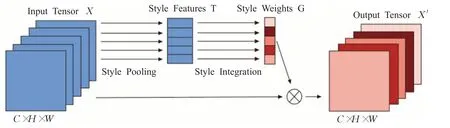
图8 SRM模块Fig.8 SRM module
鉴于自动驾驶环境中对小目标检测的重要性,以及Efficientdet d0~d3在此方面存在明显不足,结合现实应用情况,本文在Bi-FPN前引入了多尺度注意力机制模块以提高小目标检测精度。如图7所示,本文将SRM置于中间特征图P4、P5后,将前文提到的深层网络轻量级的通道关注度模块ECA net置于高层特征图P6、P7前,组成多尺度特征融合模块。虽然该模块会以损失微量的检测速度为代价,但会进一步提高Bi-FPN对小目标的检测性能。
2.3 预测网络及平衡训练过程
Efficientdet-Gs的预测网络十分简单,只需将经过Bi-FPN的5个有效的特征层传输过Class/Box net就可以获得预测结果。与模型架构相比,训练过程在目标检测中受到的关注相对较少,而训练过程也是检测器成功与否的关键。一般探测器在通常情况下需要完成分类和定位两项任务,如公式(4)所示,Lcls和Lloc分别对应着分类和定位的损失函数,p、u分别是Lcls的预测和目标,tu是对应u类的回归结果,v是回归目标。λ用于在多任务学习下调整损失权重。

损失函数是两个loss的相加,如果分类做得很好的话会得到很高的分数,但会忽略回归的重要性,导致整体的性能不佳。一个自然的想法就是调整λ的值,但直接增加回归损失的权重将会使模型对困难样本更加敏感。这些困难样本会产生巨大的梯度而不利于训练的过程,相对的简单样本只会产生相比困难样本大概0.3倍的梯度。Balanced L1 Loss由传统的Smooth L1 Loss推导而来,如公式(5)所示,其思想是促进关键的回归梯度,即来自简单样本的梯度,重新平衡所涉及的样本和任务,从而在分类、整体定位和准确定位方面实现更平衡的训练。

在驾驶场景下的网络训练过程中,正负样本极其不平衡,即存在对应真实框的先验框可能只有若干个,但是不存在对应真实框的负样本却有上万个,这就会导致负样本的loss值极大,因此仍采用原分类损失函数Focal Loss进行正负样本的平衡。同时本文引入Balanced L1 Loss来替代原回归损失函数Smooth L1 Loss,以改善分类和回归损失之间的不平衡性。
3 实验结果与分析
本文实验基于BDD100K数据集进行。BDD100K(A large-scale diverse driving video database)是伯克利大学AI实验室(BAIR)发布的目前最大规模、内容最具多样性的自动驾驶数据集。BDD100K数据集包含10万段高清视频,在每个视频的第10 s对关键帧进行采样,得到10万张图片,并进行标注。BDD100K数据集收集了6种天气情况,6种场景类型以及一天中3个不同时间的图像级注释。视频包含大部分极端天气条件,世界各地的各种不同场景,还包含大约相等数量的日间和夜间视频。这种多样性使其能够研究域转移,对于训练模型十分有效,因此它对新环境有更好的鲁棒性。BDD100K数据集由以下10类组成,包含Car(汽车)、Bus(公交车)、Person(行人)、Bike(自行车)、Truck(卡车)、Motor(摩托车)、Train(火车)、Rider(骑行的人)、Traffic sign(交通指示牌)及Traffic light(交通信号灯),每个图像平均有9.7辆汽车和1.2个人。由于该数据集具有许多不同的场景类型,且并非所有人都拥挤,因此与大多数其他数据集相比,每个图像的人数更少。构建多目标道路检测模型的目的是在自然驾驶场景中准确检测常见目标。因此,本文去掉Train,将Traffic sign及Traffic light合并为Traffic light类,将Bike、Motor、Rider合并为Bicycle类,最后的训练集标签分为6个类别,包含Car、Bus、Truck、Person、Traffic light和Bicycle。最终将数据集以7∶1∶2的比例分成训练集、验证集和测试集。本文实验在NVDIA GeForce RTX 3070上进行,辅助环境为CUDA 11.1和cuDNN 8.0.5。
3.1 Efficentdet-Gs的性能评价
图9为Efficientdet-Gs-d0在BDD100K训练集上的损失函数变化趋势图。训练集的批处理尺寸(Batch Size)设置为8,迭代次数(Iteration Number)设置为1 600 000。从图中可以看出,在网络训练的前5 000次迭代中,损失函数的数值快速下降,然后进入稳定收敛阶段。在BDD100K数据集的训练过程中,采用了基于训练过程中的某些测量值对学习率进行动态下降的方法,这使得网络从数据集中学习到更多的信息,并将训练过程中得到的最优权重作为最终权重文件。本文选取平均准确度均值(mean average precision,mAP)作为精度评价指标,每秒传输帧数(frames per second,FPS)、模型尺寸和FLOPs作为速度评价指标,其在以往的目标检测研究中被广泛应用。其中,模型尺寸是通过参数量和FLOPs来衡量,FPS是通过批处理尺寸大小为1(batch size 1)来测量。表3比较了Efficientdet-d0及其后续各版本的性能。

图9 Efficientdet-Gs训练损失Fig.9 Efficientdet-Gs training loss

表3 BDD100K数据集上的性能评价Table 3 Performance evaluation on BDD100K data set
从表3中可以看出,BDD100K测试集中Efficientdetd0的mAP值为0.594 2,而提出的Efficientdet-d0结合多尺度特征融合模块(SRM/ECA)的mAP值为0.623 5,该模块使其检测精度提高了2.9%。多尺度特征融合模块(SRM/ECA)对Car(汽车)、Person(行人)等可大可小对象的检测性能结果分别提高了2.5%和4.5%。对于具有较大边界框的对象,如Bus(公交车)、Truck(卡车),其检测精度略有提高。通过Efficientdet和Efficient-det+SRM/ECA对每个类的AP(平均精度值)变化的分析,可以得出合理的结论,该模块在不牺牲大目标的检测精度的情况下显著提高了小物体的检测精度。
最终,在结合重构后的MBConv后,如表3所示,在mAP基本无损失的条件下,Efficientdet-Gs-d0的模型尺寸仅为10.1 MB,相比原网络降低了36%,大量减少了设备的资源消耗,提高了模型的性价比。其BFLOPs(Billion FLOPs)为1.9,相比原网络计算量降低了25%。对于不同网络而言,处理每张图片所需的FLOPs是不同的,所以同一硬件处理相同图片所需的FLOPs越小,相同时间内,就能处理更多的图片,速度也就越快。总的来说,Efficientdet-Gs既保留了Efficientdet在自动驾驶应用中模型效率高及支持复合缩放的优点,同时又在车载计算平台部署和小目标检测两个方面取得了提升,是一种适合自动驾驶场景且可选择版本的目标检测算法。
精确召回率(precision recall,PR)曲线是用于评估目标检测算法的一个重要指标,BDD100K数据集中的两个典型对象Car(汽车)和Person(行人)的PR曲线如图10所示。一般认为,曲线靠近图右上角的算法具有更好的整体性能。从图10中可以看出,Efficientdet-Gs-d0的两个典型对象的PR曲线与原始Efficientdet-d0相比,都有了明显的提升,进一步验证了所提出的Efficientdet-Gs的检测能力。
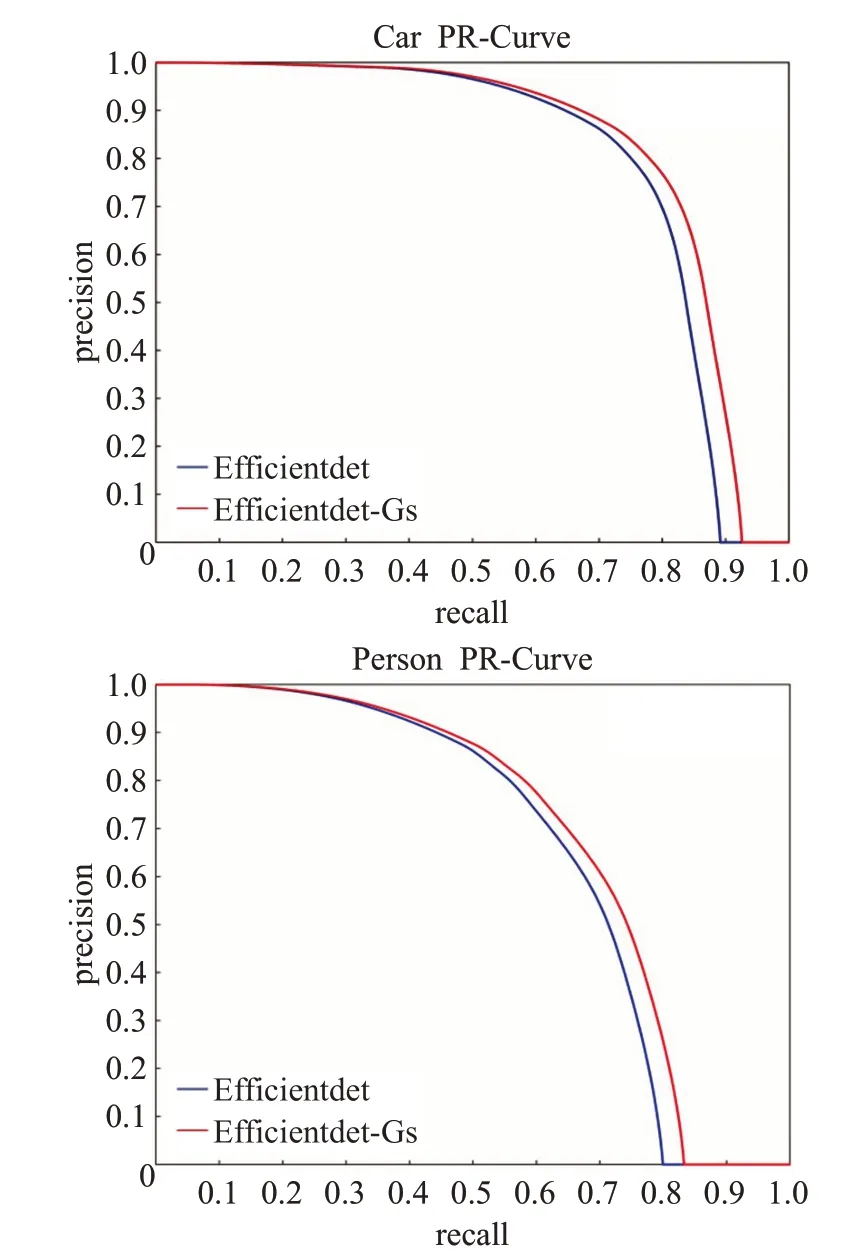
图10 PR曲线Fig.10 PR curve
3.2 Efficientdet-Gs系列与其他算法的性能比较
为了证明Efficientdet-Gs算法的优越性,本文将其性能与Faster R-CNN、Cascade R-CNN[25]、SSD、Retinanet、Yolov3、Yolov4、Efficientdet-d0、Efficientdet-d1等8种研究对象的检测精度和速度进行了比较。上述8种算法均使用各个算法官方发布的代码,并在BDD100K数据集中训练与评估。为了保证检测器比较的公平性,单阶段检测器输入分辨率均设置为512×512,两阶段检测器使用每个官方发布的代码默认分辨率,同时采用官方评价方法进行准确比较。表4比较了Efficientdet-Gs与其他算法在BDD100K测试集上的性能。
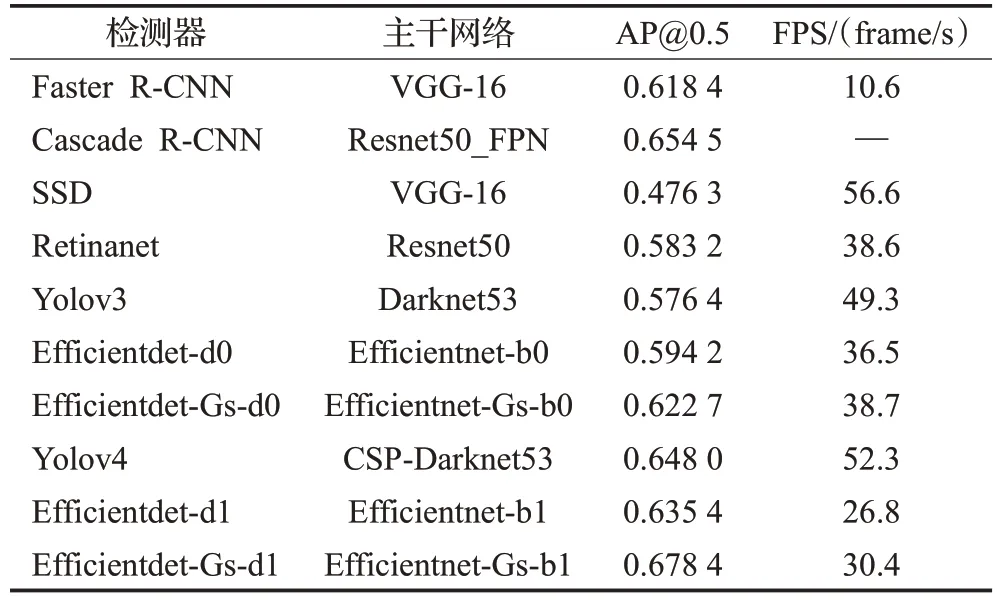
表4 BDD100K测试集的性能比较Table 4 Performance comparison of BDD100K test set
考虑到目前真实自动驾驶条件下软硬件的性价比,本文选取Efficientdet-Gs系列前2代举例说明。从表4中可以看出,本文提出的Efficientdet-Gs-d0比Efficientdetd0的mAP提高了4.8%,检测速度为38.7 frame/s,完全实现了实时检测。Efficientdet-Gs-d1比Efficientdet-d1的mAP提高了6.8%,检测速度同样达到实时检测需求。以Faster R-CNN为代表的两阶段检测算法在BDD100K测试数据集中具有较好的检测精度,但其检测速度只有10.6 frame/s,不能满足自动驾驶感知系统的实时性要求。SSD检测算法是单阶段目标检测算法的代表算法,其在BDD100K测试数据集上具有较好的速度性能,但检测精度性能较差。Yolo系列检测算法在速度和精度上都有较好的表现,其中最为出众的检测算法是以CSP-Darknet53为骨干的Yolov4,检测精度为0.648 0,检测速度达到52.3 frame/s。实验结果表明,Efficientdet-Gs-d0在38.7 frame/s下的mAP值为0.622 7,Efficientdet-Gs-d1在30.4 frame/s下的mAP值为0.678 4,其检测精度优于表4中列出的所有目标检测算法,虽然检测速度低于Yolov4,但一般认为在满足自动驾驶检测实时性要求的情况下,精度的提高和易于部署更为重要。而随着车载计算平台的逐步发展,自动驾驶车辆可根据自身软硬件的性价比来选择Efficientdet-Gs-d2至d7等后续模型,以满足更高的精度需求。综上所述,Efficientdet-Gs目标检测算法在BDD100K测试集上具有最好的性能结果,是一种适合自动驾驶检测场景的检测算法。
3.3 检测结果可视化
意力机制模块后,本文提出的Efficientdet-Gs系列在小目标检测能力方面明显优于Efficientdet,同时,对显著目标的检测能力没有明显降低。
图11为BDD100K测试集对Efficientdet-d0和Efficientdet-Gs-d0分别在白天、黄昏和傍晚的可视化检测结果。通过对比不难发现,随着光线的逐渐变暗,检测难度也随之提升。图中第2列结果表明,在同一光线条件下,Efficientdet-Gs能够检测到Efficientdet找不到的目标,拥有更高的检测精度,并表现出了优越的性能。图中第3列为Efficientdet-Gs-d0在嵌入式计算平台的检测结果。利用本文提出的轻量型主干Efficientnet-Gs,在小型化人工智能终端NVIDIA Jetson TX2上,Efficientdet-Gs-d0可以用0.027 2 s的时间正确检测目标。通过对MBConv进行重构,将Efficientdet-d0的推理速度提高了5.7%,模型大小仅有10.1 MB。

图11 BDD100K测试集上的可视化检测结果Fig.11 Visual inspection results on BDD100K test set
图12为Efficientdet-d0和Efficientdet-Gs-d0在KITTI数据集下的可视化结果。其中,第1列为Efficientdet-d0的检测结果。第2列为Efficientdet-Gs-d0的检测结果。通过对比不难发现,Efficientdet-Gs系列在不同的数据集上同样展现出了一定程度的提升,故该框架在自动驾驶常见目标检测中有着良好的普适性和泛化性。

图12 KITTI数据集上的可视化检测结果Fig.12 Visual inspection results on KITTI data set
另外,从检测结果可以看出,在自动驾驶检测场景中存在着大量的小目标,例如交通指示灯和远端的行人与车辆。这种小目标密集的检测场景是对算法检测性能的一个很好的测试。对比分析表明,在结合多尺度注
4 结束语
具有高模型效率且在资源限制下便于部署是目标检测算法在自动驾驶车辆中应用的关键。本文针对车载计算平台的计算资源有限而无法满足算法的实时性能的问题,利用Ghost模块、通道混洗和ECA net对主干网络进行优化,提高了其特征提取能力并大幅度降低了原网络的参数量;针对小目标检测精度的问题,在特征融合网络Bi-FPN前引入了多尺度注意力机制模块,以更好地融合具有丰富语义信息的低级特征和具有重要位置信息的高级特征;针对自动驾驶场景中多种目标的不平衡问题,在训练过程中引入Balanced L1 Loss,以得到更好的训练效果。与原Efficientdet-d0相比,提出的Efficientdet-Gs-d0在BDD100K数据集上的mAP提高了4.8%,推理速度提高了5.7%,而内存仅为10.1 MB。该算法能够以高于38.7 frame/s的速度进行实时检测,并且在速度相近的情况下比之前的方法具有更高的准确率和更小的内存占比。与此同时,提出的算法继承了Efficientdet复合缩放的优点,自动驾驶车辆可根据自身车载计算平台的条件来选择Efficientdet-Gs-d1至d7等后续模型,以追求检测精度的进一步提升。
实验结果表明,所提出的算法是适合于自动驾驶应用的。Efficientdet-Gs在与其他模型的对比中,不仅检测精度达到了最优,模型大小也是最小的,虽然测试速度并不完全占优,但依然满足实时性的要求。在之后的研究中将进一步对网络进行优化,并考虑将生成对抗网络(generative adversarial network,GAN)加入检测器当中,增强网络的鲁棒性能,并且进一步提高检测精度。
