光流与纹理特征融合的人脸活体检测算法
2022-03-22王宏飞赵祥模周经美
王宏飞,程 鑫,赵祥模,周经美
1.长安大学 信息工程学院,西安 710064
2.长安大学 电子与控制工程学院,西安 710064
随着人脸识别技术在支付、门禁等场景中的应用,如何有效检测人脸欺诈成为该技术面临的一大挑战。照片与视频重放[1]是最常见的欺诈手段之一,攻击者仅需播放包含用户人脸的照片或视频就可对系统发起攻击。为提高系统安全性,许多项目通常要求用户配合完成眨眼、摇头、朗读文字等组合动作,通过人脸关键点定位人脸追踪等技术确认当前图像中是否为真实人脸。为进一步提高人脸活体检测系统的使用体验,研究者提出静默式活体检测的概念,即不需用户配合,利用真实人脸与重放图像在表面纹理、三维结构、图像质量等方面的差异完成活体验证。
Boulkenafet等[2]分析了真实与虚假人脸图像的色度与亮度差异,基于颜色局部二值模式提取各阶图像频带的特征直方图作为人脸纹理表征,最后通过支持向量机实现分类,在Replay Attack数据集上测试取得了2.9%半错误率。Galbally等[3]证实了高斯滤波产生的图像质量损失值能够有效区分真实与欺诈人脸图像,设计了包含14个指标的质量评估向量,并结合LDA(linear discriminant analysis)提出了一种活体检测方法,在Replay Attack数据集上获得15.2%半错误率。然而,此类方法往往需要针对某种类别的攻击方式设计特定特征描述符,同时在不同光照条件、不同欺诈载体下方法鲁棒性较差[4]。施新岚等[5]利用色彩空间转换导致的信息丢失现象,通过Gabor滤波器对人脸图像纹理特征从多尺度、多方向进行增强,并使用SURF算子提取特征用于检测人脸欺诈,并在Replay-Attack数据集取得较好的结果。
一些研究者通过分析人脸运动模式,提出了基于动态特征的人脸活体检测算法,并在相关数据集表现出良好的性能[6]。Kim等[7]设计了一种用于光速估计的局部速度模型,并根据光在真实人脸与欺诈载体表面扩散速度的差异区分欺诈与真实人脸,在Replay Attack数据集上得到了12.50%半错误率。Bharadwaj等[8]通过欧拉运动放大算法对影像中0.2~0.5 Hz的眨眼信号进行放大,结合局部二值模式与方向光流直方图(LBP-HOOF)提取动态特征作为分类依据,在Replay Attack数据集上取得了1.25%半错误率,同时证明了影像放大算法对算法性能的积极作用。Freitas等[9]借鉴人脸表情检测方法,采用LBP-TOP算子从时空域正交平面中提取特征直方图并利用支持向量机进行分类,在Replay Attack数据集上得到了7.6%的半错误率。Ge等[10]基于相邻帧之间的动作信息,建立了一种CNN-LSTM网络模型,使用卷积神经网络提取人脸图像纹理特征,之后将其输入至长短期记忆结构中对人脸视频中的时域动作信息进行学习。
此外,部分研究者结合不同检测设备、系统模块对多模信息进行数据级、特征级融合,有效增加了活体检测准确率[11-12]。Zhang等[13]利用Intel RealSense SR300相机构造了包含RGB图像、深度图像(Depth)、红外图像(IR)的多模态人脸图像数据库,运用人脸三维重建网络PRNet[14]与掩膜运算准确定位人脸区域,随后基于ResNet 18分类[15]网络对RGB、Depth以及IR等混合多模态数据进行特征提取与融合。邓茜文等[16]基于近红外与可见光双目视觉技术提取人脸深度信息并进行三维点云重建,根据采样点的深度值方差和空间距离信息表征人脸活体信息,并使用支持向量机完成真伪分类。基于多模态信息的人脸欺诈检测方法虽然取得了较好效果,但是需要更多的设备开销。近来,一些研究者利用深度卷积神经网络从多帧二维图像生成人脸深度图像[17]或者通过远程光学体积描记术[18-19]获取人脸区域血流信息,提出了相关人脸真伪判别算法,虽然在许多数据集上取得了更好的性能,但相比其他方法更复杂,不适合需要快速决策、算力受限的使用场景,甚至由于受运动噪声和复杂光照影响在部分场景下失去有效性。
受上述文献启发,针对单目静默式人脸活体检测任务,论文基于图像纹理和帧间光流场变化,设计了双通道卷积神经网络与特征融合模块,提出了一种光流与纹理特征融合的人脸活体检测算法。
1 算法流程
算法流程如图1所示。输入一段采集的人脸视频,使用影像放大算法将其中0.04~0.4 Hz频段放大20倍,增强脸部动作,并选择任意相邻两帧作为算法输入;为消除背景对活体特征提取的干扰,基于人脸检测算法定位人脸框并截取对应区域;同时,计算光流场变化并生成光流场变化图,依据人脸位置得到人脸区域光流图;将人脸区域的光流图与纹理图输入至卷积神经网络,完成纹理特征提取、光流特征提取、特征融合,根据所得特征值实现人脸真伪分类。
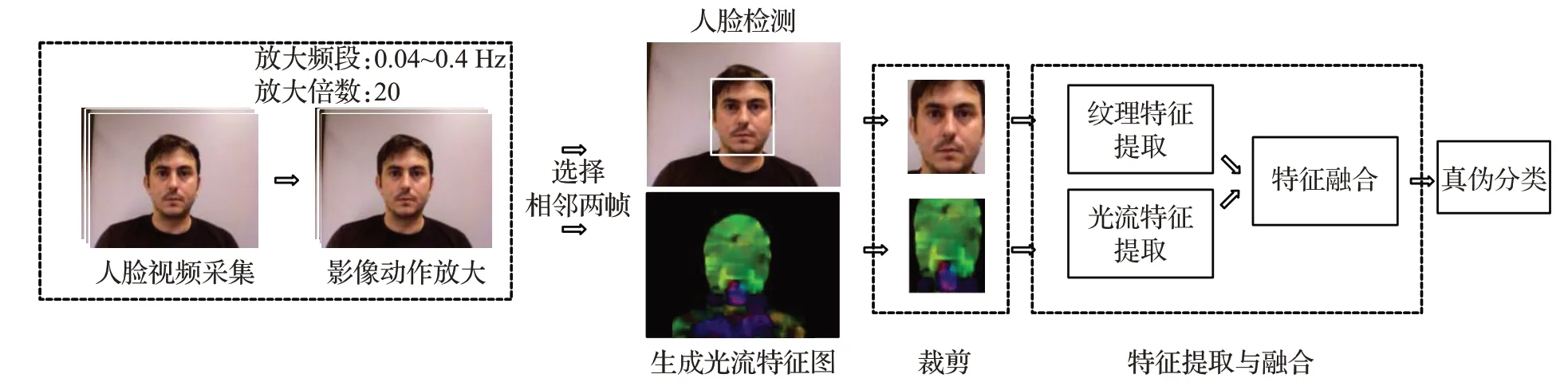
图1 算法流程Fig.1 Algorithm flowchart
1.1 影像动作放大
Wu等[20]基于欧拉视角,提出了欧拉影像动作放大算法。该算法将视频中的运动信息等价为时空域内的像素值变化,通过拉普拉斯金字塔多尺度分解视频帧序列,并使用时域带通滤波器提取其中的某一频段B;采用IIR滤波器将该频段的动作信号放大∂倍,之后从最低一级开始对处理后的图像金字塔进行复原,得到放大后的影像,放大原理如式(1)所示:
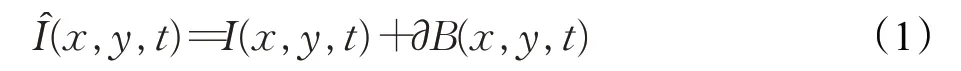
其中,I(x,y,t)及分别是原始与放大后视频在(x,y,t)处的像素值,B(x,y,t)为带通滤波器在原始视频中(x,y,t)处提取的动作信息,∂为信号放大倍数。然而,此算法在提取动作特征时无法有效区分频段中的噪声和动作信号,导致视频中的噪声也随动作信号放大,降低了视频图像质量。因此,本文采用了文献[21]提出的基于深度学习的影像放大方法,与欧拉算法相比,该算法基于残差网络设计了一个动作-视觉编码器Ge,表征视频中的动作信号M(t)和纹理信号V(t);其次,运用时域滤波器T在得到的动作表征上提取目标频段用于动作放大,这种做法有效避免了噪声随信号放大的问题;最后,利用解码器Gd对视觉及放大后的动作信号进行组合,得到动作增强视频,其放大过程如式(2)~(4)所示:

其中,I(t)为t时刻原始视频图像,V(t)和M(t)分别是t时刻的纹理与动作特征;∂为信号放大倍数,为t时刻放大后的动作特征;为t时刻放大后的视频图像。
为直观对比两种动作放大算法效果,本文分别使用上述两种算法将一段视频的同一频段放大20倍,视频帧图像与标线区域的时间切片如图2所示。分析原始及放大后视频切片可得,两种动作放大算法均能够对原始视频中的动作信号进行放大,其中与欧拉算法相比,基于深度学习的动作放大算法所产生的动作干扰与模糊均小于前者。由于图像模糊会对光流场变化计算过程带来影响,因此本文选取基于深度学习的动作放大算法对人脸信号进行增强,从而在保证图像纹理清晰的条件下实现动作放大。
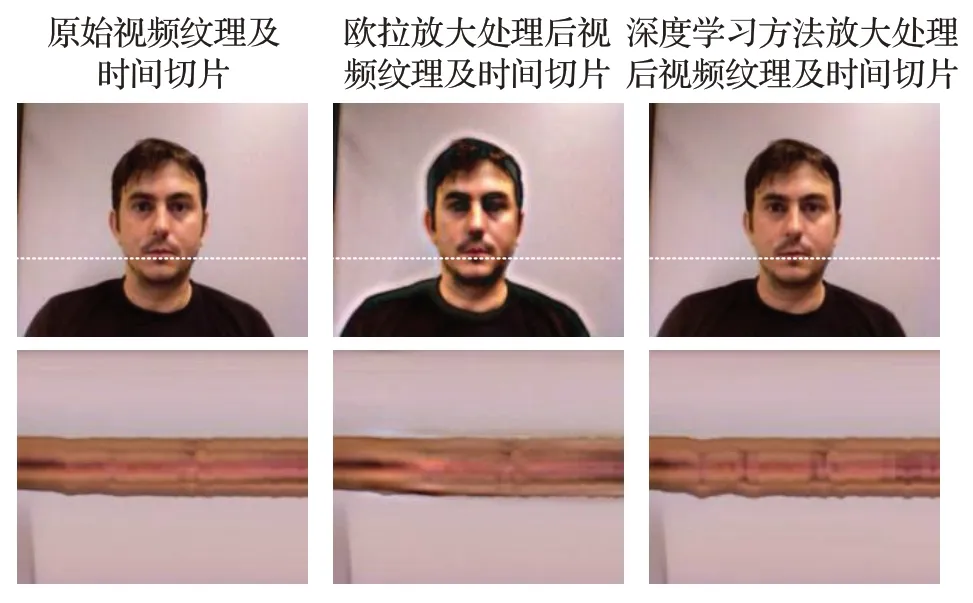
图2 动作放大算法效果对比Fig.2 Effect comparison between motion magnification methods
1.2 光流场变化
光流法是一种用于描述相邻帧物体运动信息的方法,其通过计算时间域上图像中x与y方向上运动位移反映帧间场变化。定义视频中点P在t时刻位于图像中(x,y)处,经过dt运动至(x+dx,y+dy)处,则当dt趋近于0时,两处像素值满足如下关系:

其中,v=(x,y)为t时刻点P的坐标,I(v)为t时刻(x,y)处的灰度值;d=(dx,dy)为dt时间内点P的位移;I(v+d)为t+dt时刻(x+dx,y+dy)处灰度值。
本文使用Farneback[22]提出的稠密光流法计算人脸视频帧间位移,该算法使用二项式近似表示t时刻(x,y)处灰度值,将其从2维空间映射到6维空间:

其中,(r1,r2,r3,r4,r5,r6)均为常量,可在(x,y)邻域内采用最小二乘法拟合得到。

式(6)可写为:

将位移d=(dx,dy)变换至极坐标系d=(ρ,θ)并映射至HSV颜色空间内,其中极角作为色相,极径作为明度,饱和度置1,随后进行颜色空间转换得到RGB图像。如图3所示,真实情况下人脸部区域光流场变化相比其他两种欺诈最为明显,且几乎不存在静态背景干扰;照片重放由于脸部不存在任何动作信息,其光流现象相比最为微弱,仅仅存在因照片抖动而产生的光流场变化;视频重放脸部光流信息较为丰富,但由于受到播放设备抖动、屏幕反光等影响,整体光流场变化杂乱,背景干扰较为严重。

图3 真实人脸、照片或视频攻击光流图对比Fig.3 Comparison of real face,photo or video attackoptical flow diagram
1.3 人脸区域检测
为消除背景对活体检测的影响,本文使用方向梯度直方图算法定位视频图像中的人脸区域,并截取该区域光流场变化图。
方向梯度直方图(histogram of oriented gradients,HOG)是一种用于描述图像局部纹理特征的方法,该算法图像等划分为小尺寸的细胞空间,计算细胞内各像素点的梯度,并根据梯度分布生成细胞HOG;然后,在较大尺寸的块空间上统计各细胞HOG分布,生成块空间HOG,描述局部纹理信息。像素点梯度计算如式(9)、(10)所示:

其中,Gx(x,y)和Gy(x,y)分别是图像(x,y)处的水平梯度与垂直梯度,I(x,y)是该处的灰度值。据此可计算该处梯度的幅度G(x,y)与方向∂(x,y),如式(11)、(12):

将梯度方向空间[0,2π]平均划分为如图4所示的9个维度,采用线性插值方式,依据梯度的方向将幅度值分配至不同维度。
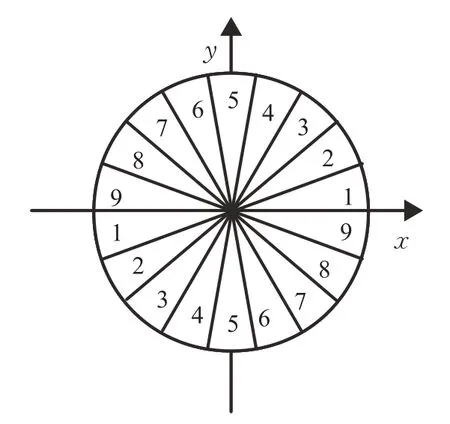
图4 梯度方向的9个划分通道Fig.4 Nine divided channels for gradient direction
遍历细胞空间内的所有像素点,生成该细胞的HOG,对一定数量的细胞HOG进行向量运算得到块空间HOG;其次,多个块空间HOG拼接组成整幅图像的HOG,图5是人脸图像以块空间为基本单位的HOG特征可视化。不同人脸图像的光照与背景差异会导致幅度取值范围较大,因此对各个块空间的HOG进行归一化,如式(13)所示:

图5 原始图像及其方向梯度直方图Fig.5 Ordinary image and HOG

其中,Hb为块空间HOG向量,ε为常量。采用滑动窗口,通过机器学习算法判断当前窗口内HOG特征向量是否与人脸区域匹配,从而根据窗口坐标定位人脸。
1.4 光流-纹理特征提取与融合
基于特征融合策略,设计了如图6所示的双通道卷积神经网络,网络输入包括人脸RGB图像与光流场变化特征图,二者分别通过纹理特征提取模块、光流特征提取模块完成中间层特征提取,随后利用特征融合模块对拼接后的中间特征进行信息融合,得到维度为2的输出特征。
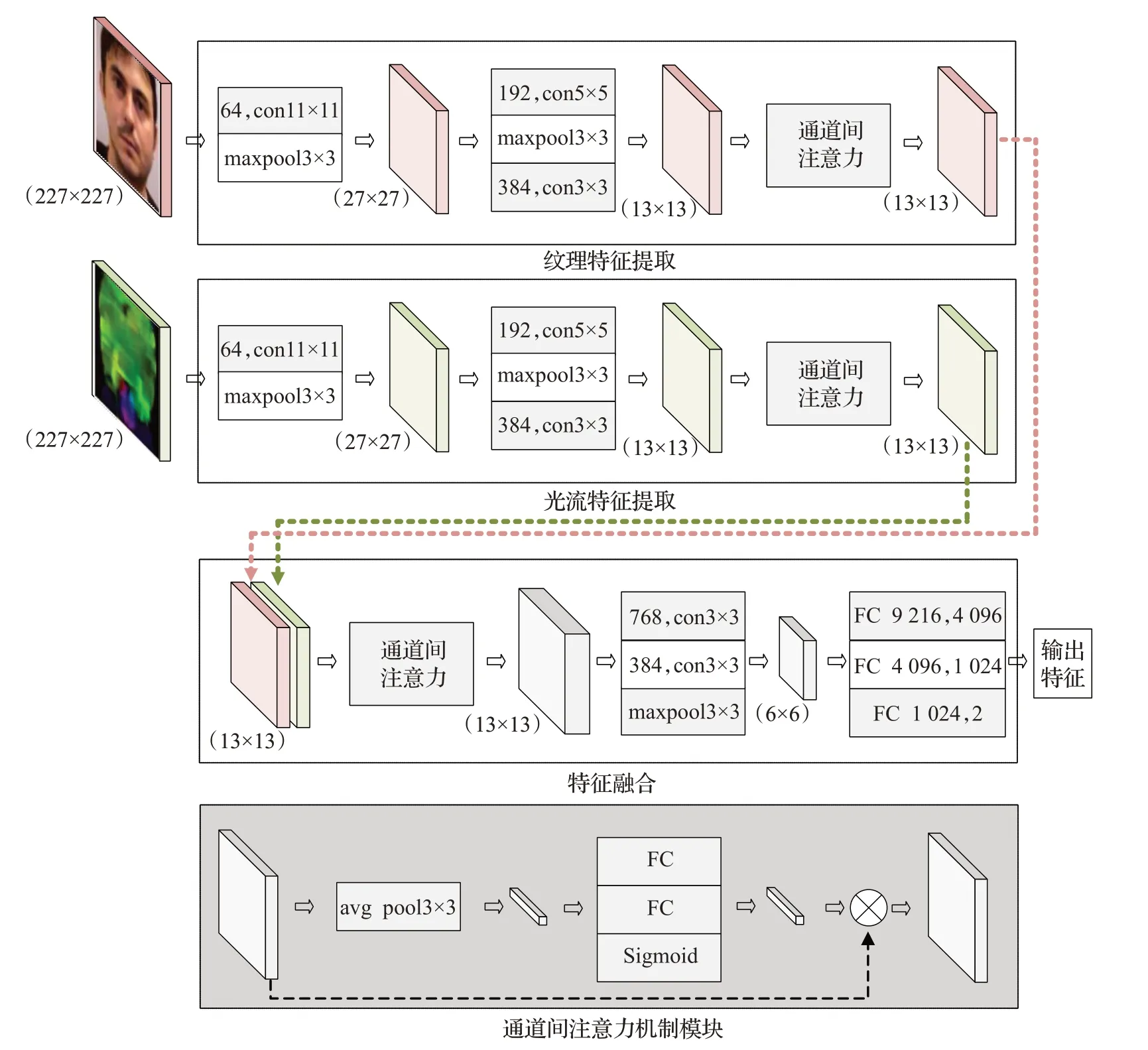
图6 基于融合策略的网络结构Fig.6 Network structure based on fusion strategy
纹理特征提取模块与光流特征提取模块结构类似,输入图像尺寸均为227×227×3,经由卷积层、最大值池化、通道间注意力等模块得到尺寸为13×13的中间层特征。采用Concatenate方式,将纹理特征提取模块与光流特征提取模块的输出结果进行拼接,作为特征融合模块的输入。特征融合模块包含:通道间注意力模块、卷积层、最大值池化层、全连接层,其中通道间注意力机制旨在动态地为两种输入特征分配权重,以强化某些通道的决策能力。特征融合模块中,利用3个全连接层完成特征提取与降维,得到2维活体表征值,作为网络输出结果。本文使用文献[23]提出的“Squeeze and Excitation”方法搭建通道间注意力模块:首先,对输入特征图进行全局平均池化(avgpool);其次,通过“全连接-激活函数-全连接层-归一化”结构计算输入特征图各通道的权重;最后,将输入特征与权重相乘,作为模块输出。在模型训练阶段,该结构学习了输入特征各通道间的一种非线性函数关系,依据此为各通道动态分配权重。其中2个全连接层分别用于系数降维与恢复,既提高函数复杂度,又减少模型计算。
2 实验分析
2.1 数据集处理
本文利用IDIAP的ReplayAttack人脸活体检测数据集实现模型训练与测试。Replay Attack训练集、开发集、测试集共包含1 300段人脸视频,每帧分辨率为320×240,每秒约25帧,数据采集自50个志愿者并且采集时设置了不同的环境变量,具体包括:(1)光源及背景控制:自然环境光且背景复杂、人造光源且背景简单;(2)欺诈种类:视频重放、照片重放;(3)人脸重放所使用的视频或照片分辨率;(4)人脸重放所使用的视频或照片载体:电子屏幕、纸张;(5)数据集采集设备是否固定:使用支架、手持。通过以上多种变量构造了较为复杂的采集环境,从而更贴近真实人脸识别系统使用场景。
为保证并验证攻击检测方法鲁棒性,本文实验将全部数据按照真实人脸与欺诈攻击分为两类,首先,使用影像放大算法将视频中0.04~0.4 Hz的动作放大20倍;随后,通过相邻帧选取、光流场变化计算等得到人脸纹理图像及光流特征图;并且,在纹理图像上进行人脸区域检测,在上述两种图像上截取人脸区域,如图7所示;最后将真实人脸数据标记为1,欺诈人脸数据标记为0。

图7 数据集处理示例Fig.7 Sample of dataset processing
2.2 性能评价准则
本文实验使用错误接受率(false acceptance rate,FAR)、错误拒绝率(false rejection rate,FRR)、等错误率(equal error rate,EER)及半错误率(half total error rate,HTER)等指标评估人脸活体检测算法。错误接受率是指将虚假人脸判断为真实人脸的比例,错误拒绝率是指将真实人脸判断为虚假的比例,其计算公式如(14)、(15):

其中,Nf_r为虚假人脸错判次数,Nr_f为真实人脸错判次数,Nf为虚假人脸检测次数,Nr为真实人脸检测次数。
本文实验采用阈值法(thresholding)进行人脸分类:在不同阈值下计算FAR和FRR并绘制接受操作者特性(receiver operating characteristic,ROC)曲线。ROC曲线用于度量分类问题中的非均衡度,曲线下的面积(area under curve,AUC)可直观表明算法分类效果,AUC越接近1代表分类效果越优秀。若使用开发数据集绘制ROC曲线,当FRR等于FAR时,二者均值为EER;若将此时的阈值用于测试集分类,FRR和FAR均值为HTER。
2.3 训练参数设置
实验采用Pytorch深度学习框架搭建本文所设计的基于融合策略的特征提取网络,并使用预训练的AlexNet 100分类模型对纹理特征提取子网络与光流特征提取子网络的conv11×11、conv5×5、conv3×3等6个卷积层进行参数初始化。模型采用了交叉熵损失函数,在训练阶段使用SGD优化器,分别设置batch size、学习率、权重衰减等参数为32、0.000 1、1E-4,实验使用Intel Xeon®E5-26500 CPU及Matro xG200eR2 GPU完成模型训练与测试。
2.4 真伪判别结果与分析
实验使用2.2节中所述的阈值法进行模型评估,具体而言,网络所输出的二维向量值分别代表了当前数据为虚假人脸、真实人脸的概率,本实验选择了其中的第二维值进行真伪判别,即若该样本的真实人脸概率超过阈值则判定其为真,否则为假。
表1是本文算法在Replay Attack开发和测试集上的实验结果,TP与TN分别为正确识别真实/虚假人脸的个数,FP与FN分别为错误识别真实/虚假人脸的个数。为探究预处理阶段使用的动作增强方法对算法的影响,使用未进行信号放大的数据进行缺省实验,未使用动作放大处理时,在Replay-Attack开发数据集上正确判定真实人脸10 992个、虚假人脸33 268个,等错误率为1.52%;测试集上正确判定真实人脸14 410、虚假人脸43 551,识别准确率为96.9%,半错误率HTER为3.03%。使用动作放大处理时,在开发数据集上正确判定真实人脸11 011个、虚假人脸33 333个,等错误率为1.33%;测试集正确判定真实人脸14 825个、虚假人脸44 085个,识别准确率为98.5%、错误接受率FAR为1.81%、错误拒绝率FRR为0.28%、半错误率HTER为1.04%。在开发数据集上选择不同的阈值并绘制ROC曲线,如图8所示,红色曲线为使用动作放大后的ROC曲线,绿色曲线为未使用动作放大的ROC曲线,其中使用动作放大处理后得到AUC指标为0.999,未使用时AUC为0.998。以上实验表明本文方法具有较优的人脸真伪分类效果,动作放大处理对本方法真伪结果判别产生积极影响。
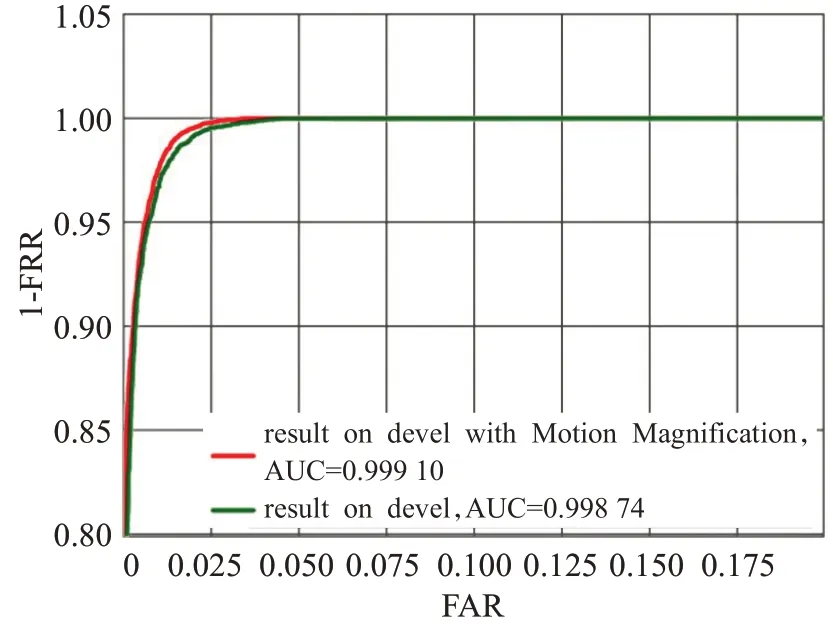
图8 本文算法在Replay Attack开发集上的ROC结果Fig.8 ROC curve on Replay Attack devel-set of proposed method

表1 本文算法在Replay Attack实验结果Table 1 Result of proposed method on Replay Attack
为进一步说明本文方法的有效性,将本文方法与其他基于图像纹理或人脸动态信息的活体检测方法进行比较,结果如表2所示。由表2可知,本文提出的基于光流与纹理特征融合的人脸活体检测算法在Replay Attack数据集上表现出较优秀的结果,相较SURF方法的HTER降低1.16个百分点,相较LBP特征的EER降低12.57个百分点,较LiveNet的HTER降低4.7个百分点,可见本文所提出的基于光流与纹理特征融合的人脸活体检测算法具有较好的效果。

表2 本文算法与相关算法在Replay Attack上的比较Table 2 Comparison of proposed method and others on Replay Attack
3 结论
本文提出了一种基于光流与纹理特征融合的人脸活体检测算法:利用影像放大算法增强采集视频中的人脸活体信号,并通过光流法生成相邻帧光流场变化特征图,同时采用基于梯度方向直方图的人脸检测方法截取人脸区域,此外,本文结合通道间注意力机制设计了双通道卷积神经网络用于人脸纹理及光流图高语义信息提取与融合,实验表明,本文算法在Replay Attack数据集上取得1.04%HTER,能够有效辨别活体。
人脸识别系统在真实应用环境下不仅会面临照片、视频等攻击,还可能遇到高仿真面具假体欺诈,研究活体检测算法在攻击手段下的鲁棒性具有重要意义。因此,下一步将针对算法在多种欺诈方式下鲁棒性展开研究,同时将探究如何在人脸活体特征提取阶段充分利用影像放大算法所提取的中间纹理特征与动作信号特征,从而提升活体检测准确率。
