课堂环境下用于头部行为识别的李群特征表示
2022-03-22孟凡荣贺恒桃闫秋艳
谢 冬,孟凡荣,贺恒桃,闫秋艳
中国矿业大学 计算机科学与技术学院,江苏 徐州 221116
近年来,人工智能(artificial intelligence,AI)飞速发展,计算机视觉(computer vision,CV)作为其重要分支,正在不断发展的计算机视觉技术正逐渐成为人们的认知世界过程中的主体应用技术[1]。在以人类为研究对象的计算机视觉研究领域中发现,人的头部包含丰富的表达信息,哈佛大学的Ambaby教授[2]对授课过程做过一个实验,得出结论:教师在课堂环境表达自己思想的过程中,非语言表达方式和语言表达方式同样重要,非语言表达方式可能有着更加明显的作用。这一结论对于授课的信息接收者——学生也同样适用,学生头部的姿态蕴含着丰富的信息,跟他的情绪、动作有着强大的潜在联系。基于头部特征的相关计算机视觉问题,目前成为了科研工作者的研究热点,并已经有落地实施的项目,比如在汽车安全驾驶、人机交互、刷脸支付等领域。
近年来,在头部行为识别领域,肌音信号(Mechanomyography,MMG)[3]——反映肌肉力学特性的一种肌肉收缩时产生的低频信号——使头部行为识别技术取得了显著进步,但是存在一些不适用性,比如课堂环境下为每个学生配置肌音信号传感器存在成本高、干扰教学秩序的问题。因此,如何从随堂采集的视频数据中直接实现学生头部行为的识别,并且克服传统课堂中光照、阴影等环境因素对头部行为识别造成的影响,是实现自动化评价教学质量的关键。
传统的头部行为识别大多是作用在RGB图像序列上,然而RGB图像数据缺少深度信息,基于RGB人脸图像提取的面部几何特征极易受到光照、阴影等因素的干扰,影响头部行为识别准确率。随着传感技术的发展,深度传感设备在市面上逐渐普及,例如市场流行的体感设备Kinect除了获取彩色图像还可以获取深度图像(DepthMap),深度图中每个像素值都是传感器距离物体的实际距离,通过深度图可以准确提取出物体关键点的空间3D数据。深度图不仅包含空间信息而且抗干扰能力强,可以解决RGB图像数据易受光照、阴影等因素影响的问题,受到越来越多研究人员的关注。
本文以计算机视觉技术为基础,以Kinect获取的深度图为数据对象,研究课堂环境下学生头部行为的识别方法,从头部行为深度图中提取头部行为的李群特征表示,提升课堂环境下学生头部行为识别的准确率,为后续分析课堂教学环境下学生的学习状态,评价教师的课堂教学效果奠定数据基础。
1 相关工作
目前,基于深度图的头部行为特征提取的方法主要分为两大类,即从深度图像中提取头部姿态角特征以及提取深度和速度特征。胡习之等人[4-5]利用Kinect摄像头进行人脸识别的基础上,计算得到头部姿态角特征监测驾驶员的驾驶状态,设定安全区域角度阈值。范子健等[6]通过Kinect设备获取学习者头部姿态坐标,计算得到头部偏转角度,当坐标大于阈值即判定为某一行为。胡占峰[7]借助Kinect传感器获取彩色图像和深度图像数据,获取人脸3D信息得到面部特征点,分析鼻尖、眼睛的运动方向、运动距离和运动偏转角度是否超过了规定的阈值,识别驾驶员行车途中左右转头或抬头低头不安全行为,将偏航角信息作为头部行为识别的特征却存在场景不适用性。Ohtsuka等人[8-9]提出利用深度传感器识别头部姿态运动,实现非接触式控制轮椅功能,作者将前倾姿态的变化分为四个阶段,为每个阶段设定头部的深度信息的阈值范围,生成控制轮椅的指令信号,这种方式只能识别前倾动作。Jindai等人[10]提出Kinect获取头部三维形状和颜色图像,利用AAM对面部跟踪测量头部节点计算点头角速度,并将角速度作为头部行为识别的特征。Patwardhan[11]的工作主要识别人体运动,其中为了追踪并识别头部运动,追踪头颅前后共12个特征点的坐标、距离和与水平线的角度,最后将它们合并为一个特征向量,这种特征表示方式得到的特征维度过高。现有的特征提取方法特征维度过高且难以同时表达时间空间的信息特征,对于课堂环境下的头部行为识别适用性偏低。
近年来,空间几何特征——李群[12-13]不再局限于数学领域的理论研究,这类连续变换群在计算机领域的应用也开始广泛起来。李群既满足群操作,又满足流形[14-16]的性质。人体各个部位的运动可认为是刚体运动,刚体(Rigid body)是力学中的一个抽象概念,是在任何情况下都不发生变形的物体,不论是否受力,刚体内部任意两点之间的距离总保持不变,因此,人体头部可以简化成物理学意义上的刚体,其运动可以应用刚体运动来表征。李群SE(3)和李代数se(3)间的转换有对数映射形式logSE(3):SE(3)→se(3)和指数映射形式expSE(3):se(3)→SE(3)。反对称矩阵(skew symmetric matrix)可以将三维向量和三维矩阵建立对应关系,就将流形空间中的特征映射到欧式空间中进行分类。为此,提出了一种适用于课堂环境的基于李群的特征表示方法。
2 本文方法
引入深度信息获取面部关键点坐标并且将每个头部动作序列视为沿空间和时间两个方向的变化序列,通过描述头部行为在时空方向的变化提取头部动作序列的李群时空特征,使用SVM分类器对提取出的头部李群特征进行分类识别。
2.1 深度图中获取面部关键点及关键段
目前头部行为识别领域尚未存在广泛使用的深度数据集,虽然已经存在从二维图像提取三维坐标的技术,但是其效果仍然存在偏差。含有深度信息的深度图能提供更准确的信息来源,因此,本文利用OpenFace[17]技术提取面部关键点的三维坐标,共可得到67个面部关键点信息,但是对于面部67个关键点,并非所有面部关键点对头部行为识别都起到重要作用,为了减少数据冗余,从面部67个关键点中提取出5个关键点信息,其中,提取第39、42关键点表征面部上部分区域,提取第30关键点鼻尖表征面部中间区域,对于提取第48、54关键点嘴角表征面部下部分区域,具体关键点如图1所示红色区域表示。

图1 OpenFace面部关键点Fig.1 Key facial points obtained by OpenFace
利用OpenFace得到对头部行为识别具有显著作用的面部关键点的三维数据,并根据需要将获得五个关键点的三维位置进行统一格式处理。随着类似Kinect深度传感器在市场上的普及,提取面部三维坐标相对容易,Kinect传感器提供场景的三维深度数据,对光照变化具有鲁棒性,为提取面部三维信息提供了可靠的数据来源。对课堂数据集,本文用Kinect提取出人脸5个关键点部位,为表述方便将脸部关键点简称关键点,并且为能够清楚描述本文提出的空间几何特征明确了关键点之间的坐标指向,以鼻子为中心指向其他关键点,构成脸部关键段简称关键段,具体表示如图2所示。

图2 面部关键点及关键段Fig.2 Face critical points and segments
对于人脸关键点信息,用符号S=(V,E)表示,其中V=(v1,v2,v3,v4,v5)表示关键点集合,E=(e1,e2,e3,e4)表示关键段集合。为下文表述方便,记关键段en∈E,其中en1∈R3,en2∈R3,分别表示关键段en的起始点和终止点,ln表示关键段长度。
2.2 李群特征提取
根据上述定义,可以将头部动作建模为流形空间的特征,即将头部行为看作为一条曲线。以向右做摆头动作为例,如图3所示,头部动作是由一帧帧的动作序列构成,当前帧与下一帧之间都存在某种时空联系,根据本文提出的李群表示模型将当前的面部关键段与下一帧的面部关键段之间的关系以旋转平移的方式表现出来,这种表示方式既表示出空间关系又表示出时间联系,头部行为的完整动作序列所对应的李群时空特征序列就构成了流形曲线,通过对李群SE(3)×…×SE(3)构成的曲线分类即可完成头部行为识别任务。

图3 头部行为的流形空间表示Fig.3 Manifold space representation of head motion
具体构成方式以某一对面部关键段em和en为例,为了描述它们的相对几何关系,用一个局部坐标系来表示它们,通过旋转和平移全局坐标系得到以某一面部关键段em为标准的局部坐标系,使得em与X轴重合并使em1为坐标原点,记旋转角度为Rm,平移向量为dm,如图4所示。

图4 全局坐标系变换Fig.4 Global coordinate system transformation
基于人脸关键点信息的李群表示模型如图5所示,其中Rm,n(t)表示在t时刻以en为局部坐标系,关键段em相对于关键段en局部坐标系的旋转矩阵,dm,n(t)表示为在t时刻关键段em与en之间的平移向量。

图5 en关键段为局部坐标系的旋转平移Fig.5 Rotation and translation of en segments
将面部关键段em通过旋转和平移与面部关键段en重合,则在当前t时刻可得到相对几何关系,见公式(1):

Gm,n(t)表示头部从t时刻向右转头运动到t+1时刻期间以en面部关键段为局部坐标系,面部关键段em和面部关键段en之间的空间几何关系。又因为各关键段长度ln不会随时间变化而变化,所以相对几何关系可忽略其长度在深度图像数据的变化。同时为了获得完整的时空信息,对于任意帧之间的所有关节点都通过公式(1)计算得出相应的几何关系,那么在相邻帧之间,所有关键段的相对几何关系就可以表示为李群上的一个点,如公式(2)所示:

其中,Gp,q′(t)中p表示当前帧的面部关键段,q表示下一帧的面部关键段,C(t)∈SE(3)×…×SE(3)。
头部行为就是由一帧一帧的动作序列构成,利用上述提出的李群表示模型表示出头部所有关键段相邻帧之间的相对几何关系,那么描述完整的头部动作序列就可以表示头部行为的时空上下文信息,由此得到李群的一条曲线,即一个流形结构。
李群的曲线位于流形空间,常见的欧氏空间操作在这个空间中并不适用,支持向量机等欧氏空间标准分类方法和傅里叶分析等时间建模方法也不能直接适用于该曲面空间。若要能够使用欧氏空间的方法,需要将李群从流行空间映射到欧氏空间,即需要将李群关键段表示模型映射为相应的李代数表示,通过李群到李代数的变换公式(3)可得到李代数向量空间:

其中,vec(·)表示李代数向量空间,由当前帧存在4个面部关键段与下一帧3个面部关键段的空间几何结构构成李群特征,从流形空间映射到欧氏空间,对于一个旋转平移矩阵可映射为6维李代数向量,则M为维数为6×4×3维度的向量,至此得到李群特征,用t在时域上的变化表示头部行为。
通过李群表示模型表示头部行为的时空信息得到李群特征后,若直接对获得的李代数向量空间的曲线进行识别,很可能会导致分类效果不佳,因为获取的深度数据存在速率变化(rate variation)、噪声(noise)和时间偏差(temporal misalignment)等干扰因素的影响,因此,针对速率变化采用动态时间规划算法(dynamic timewarping,DTW)进行调整,利用傅里叶时间金字塔(fourier temporal pyramid,FTP)处理时间偏差和噪声等问题[18]。
2.3 头部行为识别算法
基于李群特征的头部行为识别算法通过运用头部关键段在三维空间中旋转、平移的几何变换,对每对关键段在相邻帧之间的几何关系进行了表示,并将整个动作序列建模为李群空间上的一条曲线,以此表示头部行为特征,由于速率不同、表现形式不同等原因造成的头部动作复杂性,利用视频进行头部行为识别,采集到的各个动作视频是不等长的,因此首先需要对动作序列的帧数进行规整,对不同数据集尝试找到一个合适的帧数,将数据集中所有的动作序列都通过插值得到相同的长度。
在获取相同长度的动作帧数后,使用3.2节中介绍的李群特征表示模型获取动作序列的特征表示,对于待测试动作序列直接通过RBF核的一对多支持向量机对最终特征向量进行头部行为识别,在测试集上输出动作标签,最终实现基于李群特征的头部行为识别。
本文算法的流程如图6所示。
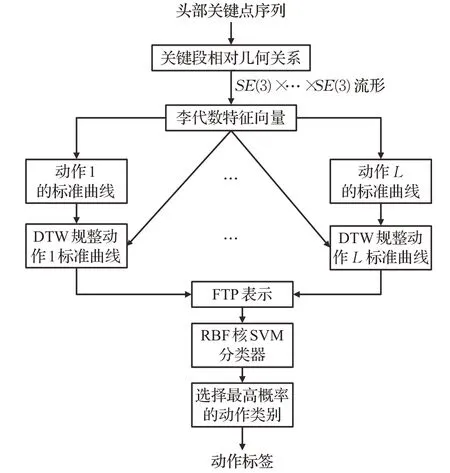
图6 头部行为识别算法流程图Fig.6 Head motion recognition training process
3 实验与结果分析
3.1 数据集
为了验证本文提出方法的有效性,分别在公共数据集和自定义课堂数据集上进行头部行为识别实验验证。
公共数据集:
(1)BUHMAP-DB数据库[19]旨在研究土耳其手语(Turkish sign language,TSL)相关的头部动作和面部表情,640×480分辨率,30 frame/s。该数据集涉及11个不同的实验人员,包含6名女性和5名男性,分别进行8种不同的头部动作或表情动作,数据库由8个不同类别的动作组成。BUHMAP-DB数据集包含的同意、不同意、困惑等头部动作为本课题提供很多可用于课堂环境的数据来源,但并非所有的数据都涉及头部运动,在本课题研究中,主要对BUHMAP-DB数据集中的HeadLR、HeadUp、HeadF、HeadUD、HappyUD共5个相关头部动作进行实验。
(2)KTH-IdiapCorpus[17]数据集由KinectV1摄像机拍摄,如图3~9所示,视频帧速率为30 frame/s。由于对话是围绕着圆桌进行的,所以在视频中参与者倾向于看着对方。视频持续约1 h,从9个不同的人的视频中选择了5 min的片段,为了验证本文所提出的方法,对77个点头动作视频进行实验。
课堂数据集(Kinect classroom database,KCRD):结合了Kinect传感器和VisualStudio2010软件平台进行数据的采集和处理工作,依靠Kinect的人脸跟踪的基础功能获取人脸面部深度图,并可准确获得的人脸关键部位。自定义课堂数据集包含8个头部动作,分别为Right、Left、Rightup、Leftup、Rightdown、Leftdown、Nod、Shake,在模拟的课堂环境下6个实验人员分别做这8个头部动作,利用Kinect采集数据,具体采集的动作如图7所示。

图7 课堂数据集头部行为视频Fig.7 Captured head motion video
3.2 实验结果分析
将头部行为获得的李群特征用RBF核的SVM进行识别、分类,表1展示了本文提出算法与其他头部行为识别算法的效果对比,可以看到,在公共数据集上,本文所提出的特征表示方法比基于关键点角度、距离等的表示法表现得更好。在KCRD数据集上进行实验,该数据集根据课堂环境设计的8个头部动作,针对该数据集的8个动作,使用交叉验证的方式进行验证,最终在此数据集上取得平均识别率为73.63%。

表1 头部行为识别效果对比Table 1 Comparison of head motion recognition effect
在BUHMAP数据库上进行实验的过程中,针对该数据库中的5个动作的头部行为序列,使用交叉验证的方式进行测试,在此数据库上,本文方法取得平均识别率为81.60%,比基于关键点位置轨迹的方法[20]高出4.2个百分点。在KTH-IdiapCorpus数据集上进行头部动作识别得到80.84%的识别率,比基于头部偏转角度序列识别点头动作评估注意力的算法[21]高出6.54个百分点。文献[20]从提取出面部关键点后,利用头部行为或面部表情过程中面部关键点位置的轨迹提取各种识别特征,如关键点二维坐标时间序列、面部几何特征等,这种特征考虑到时空信息但易受环境因素的干扰。文献[21]中利用人脸特征点计算头部运动的姿态参数即姿态角,将姿态角与设定的阈值范围进行比较,判定出学生异常行为,然而在某些特定环境下,姿态角因位置而异,无法利用姿态角阈值判定头部行为。而提出的李群特征能够有效避免这类环境、外貌以及位置因素的干扰,分类效果更优。
基于李群表示模型表示的特征的识别率比距离、角度等特征的头部行为识别率高,并且在KCRD数据集上实验结果可知基于相邻帧提取的特征的识别率比在单帧提取李群特征的头部行为识别率高47.94个百分点。
由实验结果可知,相邻帧之间不同的面部关键段的相对几何关系比当前帧关键段之间的相对几何关系能更好地表示出头部动作的时空上下文信息。同时为了证明取脸部5个关键点的有效性,在BUHMAP数据集的人脸图像提取5个面部关键点的基础上另加入眉心2个关键点,得到7个面部关键点构造的空间几何特征,最后得到61.84%的识别准确率,而基于面部5个关键点的空间几何特征的头部行为识别准确率比其高19.76个百分点,表明基于面部5个关键点的李群特征进行头部行为识别的有效性,增加了关键点个数并没有提高准确率,猜测是由于特征之间的冗余反而产生了干扰。实验结果说明了在头部行为识别中引入深度信息,并且根据李群表示模型提取的头部行为的相邻帧动作特征能够较好表示动作的时空上下文信息。
同时为了验证李群特征表示方法在课堂环境下适用性,进一步计算出在自定义课堂数据集KCRD上识别结果的混淆矩阵,如表2所示。

表2 KCRD头部行为识别混淆矩阵Table 2 Head motion recognition confusion matrix on KCRD
数据集包含了各种不同朝向的头部动作,实验人员在完成头部动作期间涉及其他头部动作朝向不可避免,但大部分动作混淆的概率都较低且多数都为0,证明本文所提出的算法在课堂环境下依然能取得不错的实验效果,并且最高对于Shake动作取得了0.82的识别率,表明使用李群特征表示进行的头部行为识别方法的有效性,并且适用于课堂这一特定环境。
4 结论
本文提出了一种基于李群的头部特征表示方法,该方法从深度图像中获取头部的时间空间特征,在流形空间中使用李群来表示头部行为,并使用这种特征表示方法完成了头部行为识别任务。实验结果表明这种基于李群的特征表示方法能够有效表达头部的时空信息,并且对课堂环境具有很好的适用性。
本文方法的主要改进方向是选取搭建先进的网络模型对提取的向量进行利用,并且课堂环境中存在语音文本等多模态数据,如何利用结合多模态数据结合图像特征进行动作识别,将是下一步研究的主要内容。
