基于混合架构的卷积神经网络算法加速研究
2022-03-22郭子博高瑛珂胡航天吴宪云
郭子博,高瑛珂,胡航天,弓 铎,刘 凯,吴宪云
1.西安电子科技大学 计算机科学与技术学院,西安 710071
2.北京控制工程研究所,北京 100089
3.西安电子科技大学 通信工程学院,西安 710071
近些年,随着算力和数据的激增,神经网络算法有了长足发展,在图像、语音、视频处理等任务上已展现出超越传统算法的精度和效率[1-2]。特别是2012年AlexNet[3]网络模型提出之后,基于卷积神经网络(convolutional neural network,CNN)的智能图像处理方法已经逐步成为主流方法并开始应用于航空航天、工业检测、自动驾驶等生产生活中的关键领域。
但卷积神经网络在提供强大的图像特征提取能力的同时也带来了庞大的计算参数和数以10亿计的浮点计算量。为了获取参数频繁访存以及浮点数计算也带来了十分可观的功耗,一个10亿神经元的全连接神经网络模型以20 FPS运行时,仅对内存数据的存取就需要12.8 W的能耗[4],即便MobileNet[5]、ShuffleNet[6]这样的轻量化网络在部署过程中也会产生不小能耗。为此,无论是拥有大规模服务器集群的数据中心还是计算资源较少的边缘设备都将面临计算时间、资源占用、能源消耗之间的矛盾。典型的CPU平台可以提供10~100 GFLOPS的算力,但其能效比通常低于1 GOP/J[7]。GPU平台可提供10 TOPS以上的峰值性能,但其能耗消耗较大不适合部署在能效要求高的场景。可灵活定制的FPGA和ASIC平台可针对卷积神经网络的模型结构设计并行计算的体系结构,优化计算和存取的流程,从而达到加速算法的效果。关于ASIC设计,中科院的DianNao系列神经网络处理器[8]、MIT的Eyeriss芯片[9]、Google的TPU芯片[10]都展现出了优秀的性能和能效比,但ASIC设计成本高、开发时间长,且结构固定难以不断适应新的算法。FPGA高并行、可编程、低功耗的特性十分适合加速基于CNN的算法,近些年学术界也开展了一些相关研究。Han等人在ICLR2016会议上提出了一种网络模型压缩方法[4],通过该方法可压缩网络参数中的冗余,且在推理阶段可使用定点数进行计算。在FPGA2017会议上,其又提出了一种LSTM稀疏网络的FPGA加速方法。该方法相较CPU有40倍的能效提升。Nakahara等人在FPGA2018会议上提出了一种轻量化的YOLOV2模型并实现了一种二值化卷积神经网络在FPGA上的实现方法,达到40.81 FPS处理速度,功耗为4.5 W[11]。美国东北大学Ding等人在FPGA2019会议上提出了一种在FPGA平台上针对tiny-YOLO目标检测算法的异构权重量化方法并在计算中通过FFT和IFFT来降低复杂度。在功耗21 W的情况下达到了314.2 FPS的检测性能[12]。
综上,权衡功耗和边缘化场景的计算资源,本文提出了一种FPGA和CPU混合架构加速CNN的方法,将少量涉及浮点操作的前后处理在CPU平台计算,用于特征提取的CNN骨干网络在FPGA平台使用指令控制数据流的高速DSP脉动阵列进行并行加速计算,两个平台通过PCI-Express(peripheral component interconnect express)总线传输数据。使用YOLO目标检测算法进行了大量实验,验证了这种方法的有效性。
1 模型加速方法
首先,为了有效利用FPGA内部较少的存储资源,本文在部署网络模型之前,对其进行了压缩优化。之后,在Xilinx FPGA上实现了一种由指令控制数据流的DSP阵列计算加速结构。最终,还使用多线程技术优化CPU处理速度,达到了流水处理效果。
1.1 模型优化
为了简化模型推理过程、优化存储空间,本文对原始网络模型做了BN层(batch normalization layer)融合与动态定点量化。
1.1.1 BN层融合
在训练过程中为了加速网络的收敛防止过拟合,许多CNN网络结构会在卷积层后加入BN层(统计该层数据根据最大值将所有数据映射到0到1之间)。含BN层的卷积计算公式如式(1)所示:
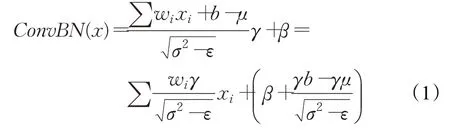
其中,γ为缩放因子,σ2为方差,μ为均值,β为偏置。

1.1.2 动态定点量化
除了BN层融合,为了去除网络模型冗余并适应FPGA计算方式本文还采用动态定点量化方法[13]对模型进行了量化压缩。
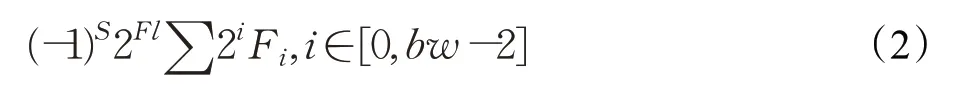
如公式(2)所示,动态定点数共享指数,第一位为符号数,其他位为尾数。Fl为指数位单独存储(在FPGA中在随指令存储),bw为数据位宽,Fi代表尾数位置的值。在每层卷积计算结束后,从指令读取Fl,采用移位的方式将数据进行量化后继续进行前向传播。
1.2 总体设计
本文在FPGA上实现了一种RTL级指令控制数据流的体系结构[14],该结构使用高速DSP阵列[15]加速卷积计算。除此之外,该结构保留了一定通用性,使用软件生成的专用指令集可控制数据流以实现不同骨干网络的前向传播。少量涉及浮点数计算的图像前处理和特征图后处理本文设计使用CPU进行计算,利用混合架构的形式加速卷积神经网络算法的推理计算。
整体设计的数据流和控制流图如图1所示,CPU将前处理的特征图通过PCI-Express总线存入片外内存。特征缓存与权重缓存根据指令操作码从片外内存中读取并缓存特征图与权重数据。这些数据经指令控制被送入DSP阵列进行乘加计算,计算结果在指令控制下经过量化、激活、池化、上采样等逻辑计算模块的计算后得到特征图。中间层特征图写回特征缓存参与后续的传播,输出层特征写回片外内存,CPU通过PCI-Express总线读取并根据不同的算法进行后处理得到最终结果并显示输出。其中,指令预存储在片上缓存(ROM)中。
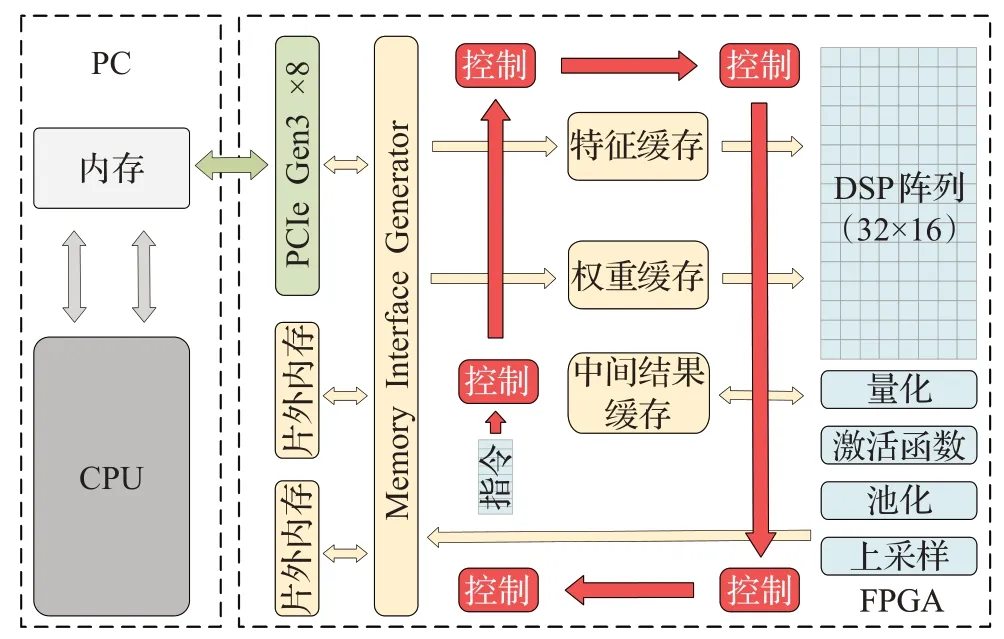
图1 混合架构总体设计图Fig.1 Mixed architecture overall design diagram
1.3 DSP加速阵列设计
卷积神经网络的核心算子是卷积,本文采用高速DSP脉冲阵列来实现卷积算子,其中核心设计就是DSP阵列以及适应阵列的卷积分块缓存。
1.3.1 DSP阵列设计
卷积计算本质就是特征图像素与各个卷积核权重的乘加计算。如图2所示,以输入输出均为32通道的1×1卷积为例,结果特征图Result的(1,1)位置第一通道像素来自输入特征图Fmap与卷积核W1对应通道位置数值相乘再叠加,即32次乘与31次加计算,而该位置的其他通道像素则来自Fmap与Wn的计算。
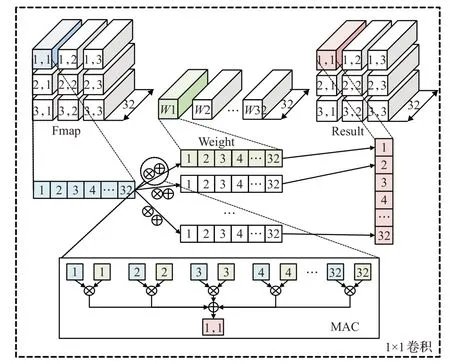
图2 1×1卷积计算示意图Fig.2 Schematic diagram of 1 by 1 convolution calculation
主流卷积神经网络通常有众多通道更深的卷积计算,浮点操作数(floating point operations,FLOPs)通常以10亿计,若串行计算必然导致可观的延时。但如图2下方MAC中所示,每个位置通道间的计算并无相关性,因此并行各通道乘与加计算可有效加速卷积计算。本文就用高速DSP阵列并行这部分计算达到了加速卷积计算的目的。DSP作为FPGA中的一种计算资源支持乘法、乘法累加、乘法加法、桶形移位等操作,而将多个DSP级联在一起,利用DSP不同的计算模式可形成乘累加链,进而实现并行乘加运算的效果。
DSP阵列的具体设计如图3所示,将32×16个DSP48E1资源级联成一个矩形阵列,每一列由32个DSP级联,第一行采用A×B的计算模式,其他用A×B+PCIN模式(PCIN来自上层DSP计算结果)形成一条乘累加链。当每列DSP传入特征图与权重的32个通道数值,可在一个时钟内完成图2中MAC所示的32次乘加计算,在列方向上实现了输入特征各通道间并行计算。
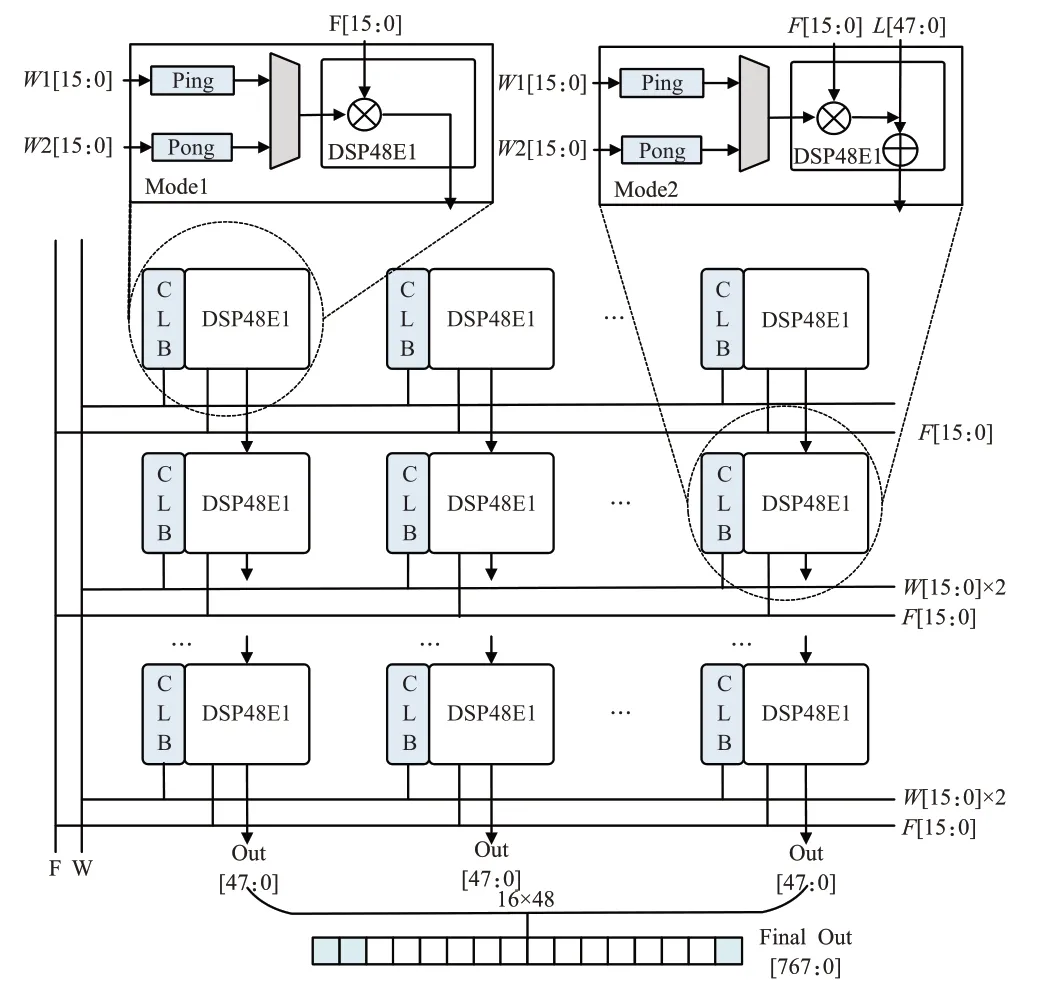
图3 高速DSP阵列设计图Fig.3 High speed DSP array design diagram
共16列则可同时做16个卷积核权重的计算,通过每列传入相同特征图,而不同列传入不同卷积核权重实现。每列的输出值为计算结果各通道数值,由此可在行方向实现输出特征各通道间并行计算。
Xilinx FPGA内部DSP工作频率经过测试最高可达800 MHz,但受FPGA本身的性能限制,除DSP之外的其他计算不能达到如此高的频率,换言之数据准备模块向DSP发送特征与权重数据的速度远小于DSP计算速度。为了最大限度地发挥DSP的性能,本文在每个DSP旁放置了两个CLB(可配置逻辑模块)配置成Ping、Pong两个缓存区,在DSP计算前加载权重数据。如图4所示,每个DSP会在200 MHz频率下进行乘加计算,而Ping、Pong两个CLB会以100 MHz频率同时缓存两个卷积核权重,Fmap则以100 MHz频率传入,减小存取所消耗的时间。通过这种双缓存结构,本文提高了DSP的时钟频率。故阵列可在单时钟周期(200 MHz)内,完成16个输出通道计算。每个通道结果的数据位宽为48 bit,16个通道结果拼接为768 bit数据后,流传输至其他模块进行计算。
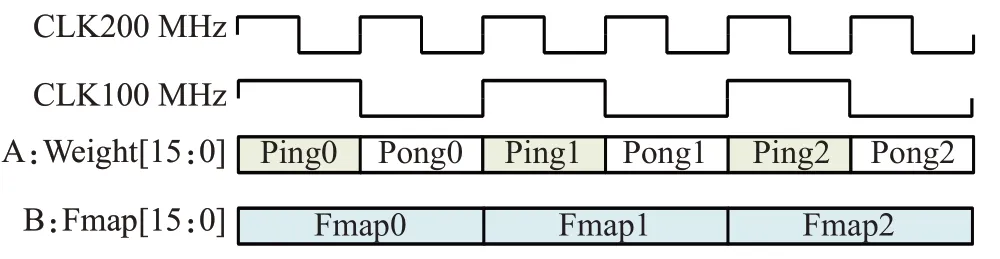
图4 DSP输入波形模拟图Fig.4 DSP input waveform simulation diagram
1.3.2 DSP阵列通用化设计
在多数CNN模型中不同尺寸的卷积会被同时使用,但无论3×3亦或5×5等更大的卷积本质依然是乘加计算,故也可用DSP阵列进行加速。
以3×3卷积为例,其结果可等价于9个1×1卷积结果的和,1×1的卷积每个时钟(100 MHz)会输出一个结果,而3×3卷积则需要9个位置的值相加,故为了适应大尺寸卷积,在最后一行DSP输出结果后需累加前8个位置的值,即最后一行的计算模式补充为A×B+PCIN+C,C累加每个时钟的输出结果,在第9个时钟(100 MHz)输出一个结果像素,波形模拟图如图5所示。只需通过指令控制传入阵列的特征与权重即可加速任意尺寸的卷积计算。
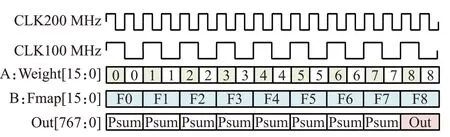
图5 DSP输出波形模拟图(3×3卷积)Fig.5 DSP output waveform simulation diagram(3×3 conv)
1.3.3 缓存与卷积分块设计
使用阵列加速的核心难点在于需要精确控制每个时钟阵列中所有DSP参与计算的A与B必须为Weights和Fmap正确位置的值。需要注意的是阵列每次计算一个像素点32通道的值,输入特征若超过32通道则需要对一次处理的32通道的中间结果进行缓存,即卷积要分块进行,按照32通道为单位进行计算,因此缓存数据的顺序也需与之对照。
图6展示了该操作以32通道为单位计算时的情况。在计算过程中首先取split0、split1、split2中slice0与Fmap-in中slice0对应位置乘加,得到X×X×96尺寸的中间结果Psum(Partial Sum)。之后再计算slice1,每得到一个像素值则取Psum中相应位置像素值进行累加得到最终结果,而Psum在FPGA中使用FIFO(first input first output)存储器缓存,通过指令控制是否需要取Psum进行叠加计算。
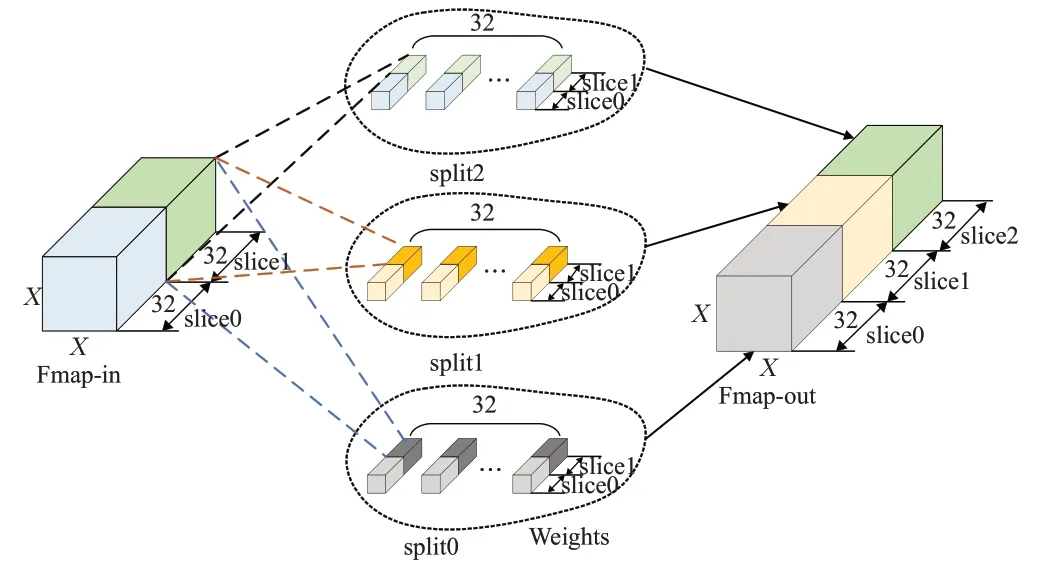
图6 分块卷积示例图Fig.6 Block convolution example diagram
通过分块卷积的策略,DSP阵列可适应32倍数的通道的卷积计算加速,而不足32通道的可以通过补0进行弥补。整个阵列可根据指令不同送入相应顺序的Fmap实现不同尺寸和步长的卷积操作,不必每次都重新设计加速方案。
2 CPU与FPGA交互设计
如图7所示,为了发挥不同平台的计算优势,本文设计在FPGA处理用以提取图像特征的CNN网络计算,在CPU计算少量涉及浮点计算的前后处理。
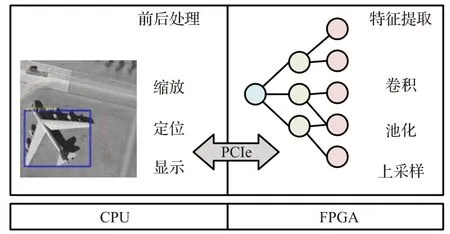
图7 混合架构加速设计图Fig.7 Hybrid architecture acceleration design diagram
FPGA从CPU端接收前处理后的图像进行特征提取,将输出特征图返回给CPU做后处理并显示最终结果。两者通过PCI-Express总线交互,FPGA存储使用AXI4传输协议统一编址,将Xilinx XDMA IP核挂载至AXI Interconnect即可在CPU通过驱动访问FPGA片上存储,Xilinx VC709 FPGA平台数据传输速率约为4 Gb/s。数据交互控制采用标志位轮询方式,在FPGA开辟BRAM(BAR空间)作为CPU与FPGA通信标志位,如图8所示,CPU将前处理后的数据加载至片外内存指定地址后将标志位0置1,FPGA轮询标志位0,当值为1时取指令计算,当FPGA处理结束将特征图加载至特定地址时将标志位100置1,CPU在发送完成后轮询标志位100,当值为1时读取特征图进行后处理。
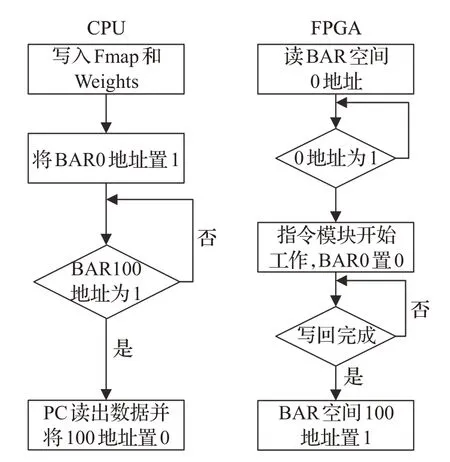
图8 混合平台数据交互流程图Fig.8 Mixed platform data interaction flow chart
由于不同平台的处理时间不同,在计算过程中若采用CPU与FPGA交替处理的串行方式,CPU与FPGA都将有部分闲置时间,无法真正发挥CPU与FPGA的性能。因此需要通过CPU多线程技术来实现CPU与FPGA并行计算。如图9所示,在上位机开设2个共享内存区,并对内存区设置标志位。根据实验,缩放图像并按照FPGA存储方式重排像素的前处理所耗时间远大于FPGA提取特征的时间,故CPU可使用多个线程同时对多幅图像进行前处理,并将图像依次写入内存区,FPGA驱动线程则按顺序轮询内存区标志位,当FLAG为1时发送内存区图像与图像序号到FPGA进行计算。同理,驱动线程与后处理线程共享输出内存区,由此可达到两个平台的流水处理。这将最大限度地发挥两种不同平台的性能。
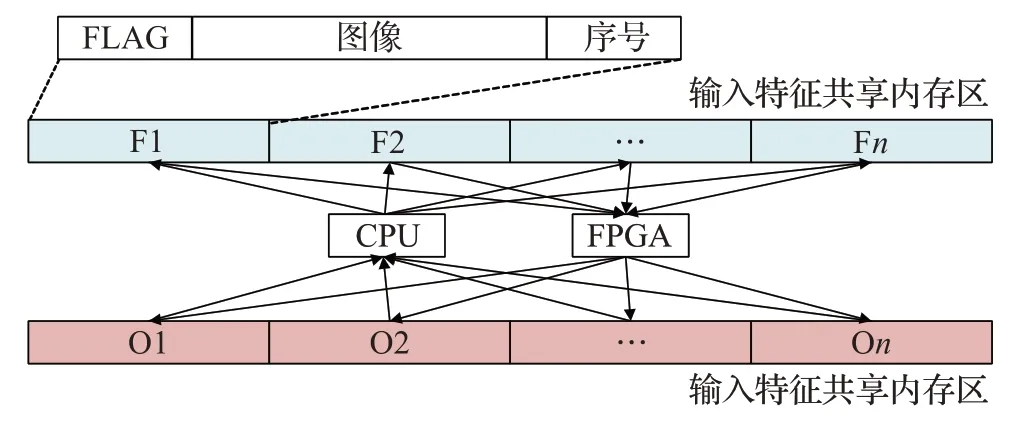
图9 多线程共享机制图Fig.9 Multi-thread sharing mechanism diagram
根据不同的任务,可配置相应的线程来使得CPU与FPGA并行计算,最大限度地发挥CPU与FPGA的计算性能。图10所示为前处理时间3倍于FPGA的时序对比图,可见多线程技术能有效缓解多平台计算等待延时大的问题。
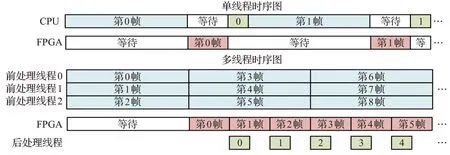
图10 时序对比图Fig.10 Time series comparison diagram
3 实验结果与分析
本文使用Xilinx VC709 FPGA进行了仿真综合实验,根据最终的综合报告,片上总功耗为7.36 W,主要资源消耗如表1所示。
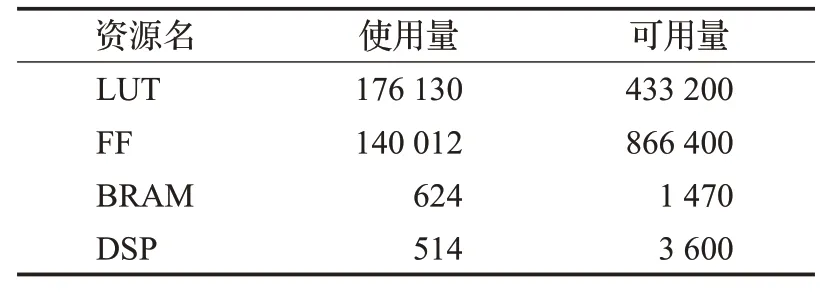
表1 资源消耗表Table 1 Resource consumption table
可以看出由于使用了指令控制数据流的形式,前向传播过程中所需的每种智能算子只会消耗一次片上资源,故有效地降低了资源的消耗,前向传播的过程如图11所示。本文采用目标检测领域经典的全卷积神经网络算法YOLO[16]来测试结构性能。用于提取图像特征的骨干网络选用的是一个24层的卷积神经网络即YOLOV3tiny检测网络,其中该网络的全部计算如表2所示。

表2 YOLO-V3tiny各层计算统计表Table 2 YOLO-V3tiny calculation table for each layer
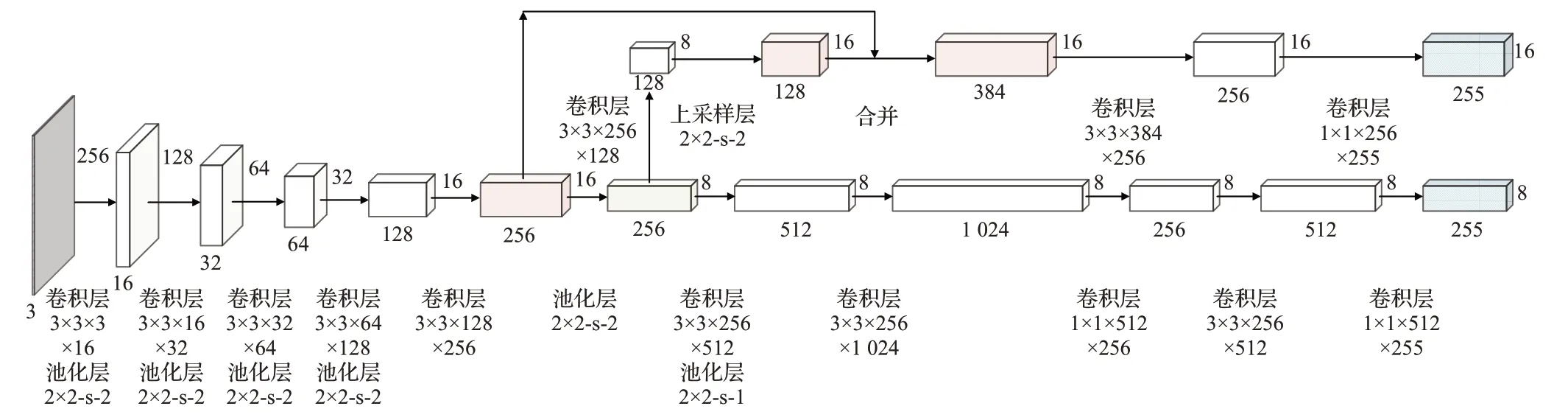
图11 YOLO-V3tiny前向传播示意图Fig.11 YOLO-V3tiny forward propagation diagram
3.1 实验结果
测试平台为CPU:Intel core i7 7700;FPGA:Xilinx VC709;内存:64 GB DDR4内存;测试操作系统:ubuntu16.04。训练与量化使用GPU平台完成,检测推理部分使用CPU与FPGA的混合架构完成,其中用于提取图像特征的骨干网络由FPGA进行加速,YOLO层后处理在CPU平台完成,最终在CPU平台显示检测结果。图12所示为遥感数据集测试结果,FPGA检测速率为58 FPS,相较于GPU平台平均精确度mAP(mean average precision)下降小于1%。

图12 遥感图像检测结果图Fig.12 Remote sensing image detection result diagram
3.2 结果分析
根据YOLO算法的计算量与检测时间,可以计算得到FPGA吞吐率可以达到120 GOPS,总功耗为7.36 W,能效比(GOPS/W)为16,表3是与其他一些CNN加速推理工作的对比。
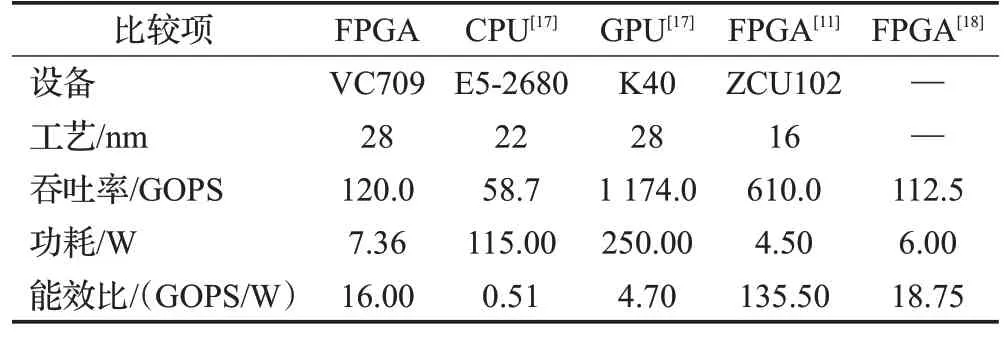
表3 与其他工作的对比表Table 3 Comparison table with other jobs
可以看出,FPGA平台在处理CNN卷积计算时的处理速度远快于通用性较强的CPU平台,虽然依然无法与GPU相比,但在星载、边缘计算等低功耗的场景下GPU难以比拟FPGA低功耗、高能效比的优势。图13为三种平台的效能对比图(为方便显示数据进行了归一化处理)。文献[11]提到了一种轻量化网络量化方法的FPGA结构具有较高的吞吐率,但其采用的二值化网络会在精准度方面有所损失。文献[18]中提到了一种在Zynq Ultrascale+平台上使用高级综合完成的FPGA实现方法性能与本文相似,但在数据吞吐率上不如本文。
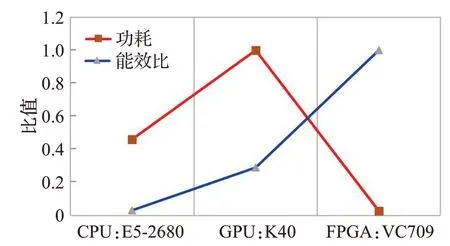
图13 不同计算平台能效对比图Fig.13 Comparison diagram of energy efficiency of different computing platforms
3.3 国产化平台实验
除了使用Xilinx VC709 FPGA进行实验外,本文还使用了全国产化平台进行了实验。测试平台为申威1621服务器CPU,128 GB服务器内存,复旦微国产FPGA(PCI-E接口,7 000万门级),操作系统为普华国产操作系统5.0。经过实验本文方法在国产FPGA上适配良好,吞吐率与VC709相当。
为了测试国产平台的稳定性本文还增加测试了4 000张800×800分辨率的SAR舰船图像在国产平台上的检测性能,最终的平均精确度mAP下降小于1%。
除此之外,本文在原版网络上进行了结构化剪枝实验,在保持SAR数据集检测精度下降在0.05之内的情况下,将网络删减至19层,检测速率最高可以达到110 FPS,图14为SAR舰船检测的效果图。
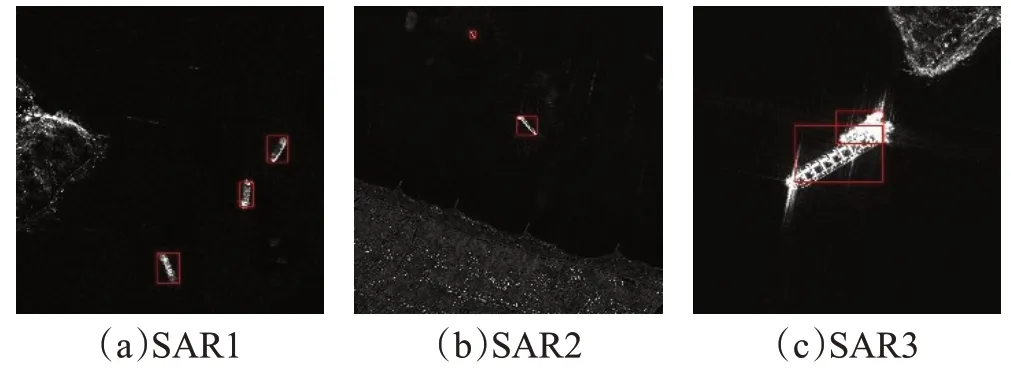
图14 SAR舰船检测效果图Fig.14 SAR ship detection renderings
4 结束语
综上,本文实现了一种基于DSP阵列的FPGA并行结构并与CPU协同实现了目标检测算法YOLO的检测过程,FPGA吞吐率达到120 GOPS。与典型GPU平台相比,具有更高的能效比,探索了边缘场景下应用深度学习算法的方法。
