学贯中西(3):欣赏AI的推论技能
2022-03-22高焕堂
0 引言
上一期[1]说明了在人们学习知识的过程中,除了会记忆(背)之外,还会进行归纳、抽象,然后对眼前或脑海里想象的新事物进行推论(如鉴往知来),甚至能举一反三。本期将以唐诗的4种平仄韵律为例,与您一起来欣赏AI的初步推论技能:见微知著。也就是,从部分信息推测(Predict)出全貌。
1 复习:分类型特征编码
回忆一下,在前2期[1-2]里曾经介绍了机器学习的特征(feature)含义;也说明了2种主要特征:数值型(numerical)与分类型(categorical)特征。其中,分类型特征又可分为:次序型(ordinal)和名目型(nominal)特征。如图1所示。

例如,有一家房产公司公布了4套房屋的相关数据,如图2所示。

其中,每一笔数据都包含了该房屋的4项特征。现在,从机器学习的视角来叙述这些特征的类型和编码方式。如图3所示。

其中特征1属于名目型特征,包括2种名目:新(屋)与旧(屋)。适合采用OHE(独热)编码,以[10]代表新(屋)、以[01]代表旧(屋)。而特征2也属于名目型特征,包括4种名目:东、西、南、北,也适合采用OHE(one-hot-encoding)编码,以[1000]代表东,[0100]代表西,[0010]代表南,[0001]代表北。而特征3则属于次序型特征,包括3种等级:大、中、小,适合采用标签编码(label-encoding),以3代表大,2代表中,1代表小。至于特征4,则是您已经很熟悉的数值型特征,表示为一般的浮点数(floating-point)即可。如图4所示。

于是,这些房屋的特征数据就能成为机器学习中的样本数据了,其中涵盖了华夏文化中的房屋方位的智慧。
2 细说OHE编码与坐标空间
关于OHE编码的使用,大家最常提出的问题是:在华夏的易经八卦智慧里,已经有了二进制(binary)编码方式,为什么在机器学习领域,这些阴阳五行等知识概念并不采用传统二进制编码,而要采用OHE编码呢?例如,上述的方位(东西南北),如果采用二进制编码,可编码为:
东 ---- > [00] 西 ---- > [01]
南 ---- > [10] 北 ---- > [11]
如果采用OHE编码,上述的方位(东西南北)可编码为:
东 ---- > [1000] 西 ---- > [0100]
南 ---- > [0010] 北 ---- > [0001]
两者相比,可以看出:后者比较冗长,需要占用更大的内存空间。
现在,来细说其中的缘由。因为在神经网络模型中,会以数学欧式空间(euclidean space)里的向量(vector)来表示分类型特征。因此,一项特征会对应到欧式空间中的某個点(point)。在机器学习领域,我们常称之为:把特征向量嵌入(Embedding)到欧式空间中。
一旦嵌入到欧式空间中,就能够计算出空间中各点之间的距离,然后依据此距离来得知事物之间相似度(similarity),进而支撑神经网络模型的分类(classification)、回归(regression)和分群(clustering)等典型算法和功能。
那么,计算距离又与OHE编码有何关系呢?答案是:例如上述房屋方位特征的4个名目(东西南北)之间,并没有大小或等级之分。所以在欧式空间中,它们相互之间的距离最好是相等的。而OHE编码则具有这种特质。来看一个简单的例子(图5)。

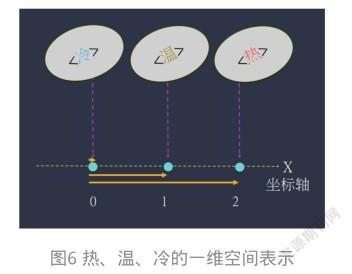
这里的冷热特征包括了3类:热、温、冷,以一维空间的3个向量来表示,如图6所示。
可以看出,其中的“冷”与“温”2个向量之间距离为1;而“温”与“热”2个向量之间的距离为1。然而,“冷”与“热”2个向量之间的距离是2。如果您觉得这种距离感是合理的(例如,会觉得冷与温比较相似,冷与热比较不相似),就可采用标签编码,以2代表“热”,1代表“温”,0代表“冷”。
那么,如果把图6更改为图7,您会觉得这种距离感还是合理的吗?

一般而言,我们通常会认为:天、地、人是三项并立的概念或名目。所以图7的距离感并不太合理。此时,就可以采用OHE编码,以三维空间的3个向量来表示,如图8所示。
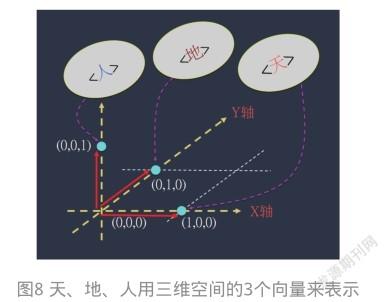
这通称为:把特征嵌入为三维的向量。于是,采用OHE编码,如下:
天 ---- > [100] 地 ---- > [010] 人 ---- > [001]
可以看出,图8中的3个点(即向量)之间的距离是相等的,能更精确计算出事物之间的相似度。凡是3项以上的并立名目(如方位、五行、十二生肖等)都适合采用OHE编码。
那么,一个比较特别的是:二元(binary)名目,只含有2项并立的名目,例如:太极图的阴、阳。此时,2种嵌入途径(即编码方式)皆可。可以采用OHE编码嵌入到二维空间:阳→[10];阴→[01]。如图9所示。

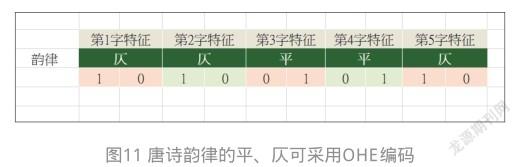
也可以采用binary编码嵌入到一维空间:阳→[1];阴→[0]。再如,唐诗韵律的平、仄。此时,2种嵌入途径皆可。可以采用OHE编码,如图11所示。
也可以采用binary编码,如图12所示。
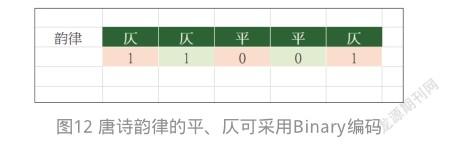
对于二元名目型特征,2种编码方式皆是适当的。但是后者比较节省空间,所以大多会采用后者(Binary编码)。
3 欣赏AI推论技能:以唐诗的韵律为例
基于上述的编码观念,就可以对五言绝句唐诗的韵律进行编码,以作为机器学习的材料。于是,把它放在Excel画面(图13)中,成为神经网络(NN)模型的训练数据(training data)。按下“学习”按钮,开始机器学习。

经过数分钟,训练完成。这时,AI模型已经记忆了这些韵律,还能进行简单的推论。接着进行测试。我们输入这首诗的前3段韵律(图14)。

然后,来检验AI模型是否能把欠缺的最后一段韵律填补起来。请按下“测试”,展开推论,并输出推论结果(图15)。

AI模型填补了最后一段:[0.1, 0.1, 0.9, 0.9, 0.1]。这非常接近于[0,0,1,1,0],代表了[平、平、仄、仄、平]的韵律。表示AI推论得很棒。仔细看看图16,所输入的测试数据中有1个错别字:春,使我们输入的编码是:0(代表平音),也是错的。此时,AI模型也有能力侦测出这个错误,自动将它更正为:0.8(代表仄音)。

以上2个范例展示了AI的记忆和推论能力。当我们给予正确的测试数据,它能够进行推论而填补起来。此外,当我们给予少数错别字时,它也能自动更正,而做出正确的推论。
在欣赏了上述的AI简单推论技能之后,如果意犹未尽,可继续阅读下一期,将介绍AI更多精妙的推论技能。
参考文献:
[1]高焕堂.学贯中西(2):认识AI的记忆(背诵)技能[J].电子產品世界,2021(12):28-30.
[2]高焕堂.学贯中西:让机器学习华夏智慧[J].电子产品世界,2021(11):17-19.
3681501908220
