藏文文本错误检错系统的设计与实现
2022-03-21西藏大学刘泽军杨士伟
西藏大学 刘泽军 杨士伟
随着信息技术的蓬勃发展,自然语言处理已经成为了热门话题。目前,中文、英文的分词方法也已经较为成熟。随着国家对少数民族地区文化的支持,越来越多的学者也对少数民族地区的文化保护做出了贡献。本文立足于藏文的信息化,设计制作了藏文文本错误检错系统,运用了Python、HTML5、JavaScript等。
当处理大量的数据文本时,若采用人工检测,会消耗大量的人力、物力与财力,且大量数据带来的疲劳感还将大大降低检错的效率。为此,我们开发了藏文文本错误检错系统,将检错成本尽可能的减至最低的此同时提升了检错的效率,性价比较高,方便可实行。后期做进一步的优化,还可将其设计为一款小程序,方便又快捷。此外,在Word等App中输入汉字或者英文时,系统会自动检错,并在出错的位置标红提示用户,但到目前为止,藏文在这一块的功能还比较缺乏,这也是我们此次设计的创新点。
使用的自然语言不同,所产生的文本错误也不相同,因为每一种语言在单位及组织结构上各有特点。就拿汉字和英文来看,英文以空格作为词的显式边界字符,而中文则较为复杂。(1)由于中文没有特定的符号显示边界,分割的依据必须是语义。有些汉字本身具有独立的含义,有些字则无任何含义,只有与其他汉字结合才能表达一定的含义。因此,在对中文文本进行分析前一般先做自动分词,为汉字串添加显示标识符。(2)因为汉语字符集是大字符集,它包含超过6700个汉字,这给汉语的处理带来了困难,因为许多对英文很有效的语言处理技术在中文处理中不适用。(3)汉字进入计算机的方式不同。在用键盘将信息键入计算机的过程当中,英语单词是一个字母、一个字母地被录入计算机,而由于中文字符只能以一种特殊的编码方式存储于计算机中,因此汉字符的录入也只能借助于汉字编码。录入员在键盘上键入的是汉字编码而不是汉字符本身,在将输入结果反馈给用户时,计算机系统需根据编码转换规则将汉字的编码形式转换回它的原始字形输出给用户。可见这种输入方式使得汉字在计算机内不存在字形上的错误,即不存在类似于英语中的单词内部的拼写错误。
1 需求分析
藏文文本检错是藏文文本校对的重要环节。藏文真词检错是藏文文本校对研究的重点和难点,也是藏文信息处理技术的基础工作。经过对现代藏文音节字分析,将藏文音节字分为规则音节字(遵循组件组合规则的藏文音节字)和不规则音节字(不遵循组件组合规则的音节字)两种。对规则音节字采用了音节字组件组合规则进行检错,对非规则音节字则采用建立梵源藏文词典、音译藏文词典和本体非规则音节字词典进行检错。根据我们的项目研究课题,我们需要做一个检错系统,且是整个文本的检错并标注错误信息,所以我们必须要有的功能是:(1)传入传出文本;(2)标注错误信息;(3)HTML界面可视化操作。
2 开发环境
我们的后端使用的是Python语言。选择此语言的原因有三点:(1)Python语言的语法非常简洁明了,即便是非计算机专业的初学者,也很容易上手;(2)与其他编程语言相比,实现同一个功能,Python语言的实现代码往往是最短的;(3)在处理自然语言上,Python具有很大的优势。
前端语言我们使用了HTML5。HTML5是构建Web内容的一种语言描述方式。HTML5是互联网的下一代标准,是构建以及呈现互联网内容的一种语言方式,被认为是互联网的核心技术之一。HTML5是Web中核心语言HTML的规范,用户使用任何手段进行网页浏览时看到的内容原本都是HTML格式的,在浏览器中通过一些技术处理将其转换成为了可识别的信息。
连接前端后端我们使用了JavaScript。JavaScript(简称“JS”) 是一种具有函数优先的轻量级,解释型或即时编译型的编程语言。虽然它是作为开发Web页面的脚本语言而出名的,但是它也被用到了很多非浏览器环境中,JavaScript基于原型编程、多范式的动态脚本语言,并且支持面向对象、命令式和声明式(如函数式编程)风格。
语言调用库:resource.txt。
3 藏文字一般结构
藏文字一般最多由七个构件构成,如图1所示。即藏文字的基本结构为[前加字+][上加字+]基字[+下加字]元音[+后加字][+再后加字]。如果把组合构件看成一个构件,则一个藏文字最多由四个构件构成,如图2所示,组合构件最多含一个,即藏文字的基本结构为[前加字+]基字/组合构件[+后加字][+再后加字],其中基字或组合必须存在。
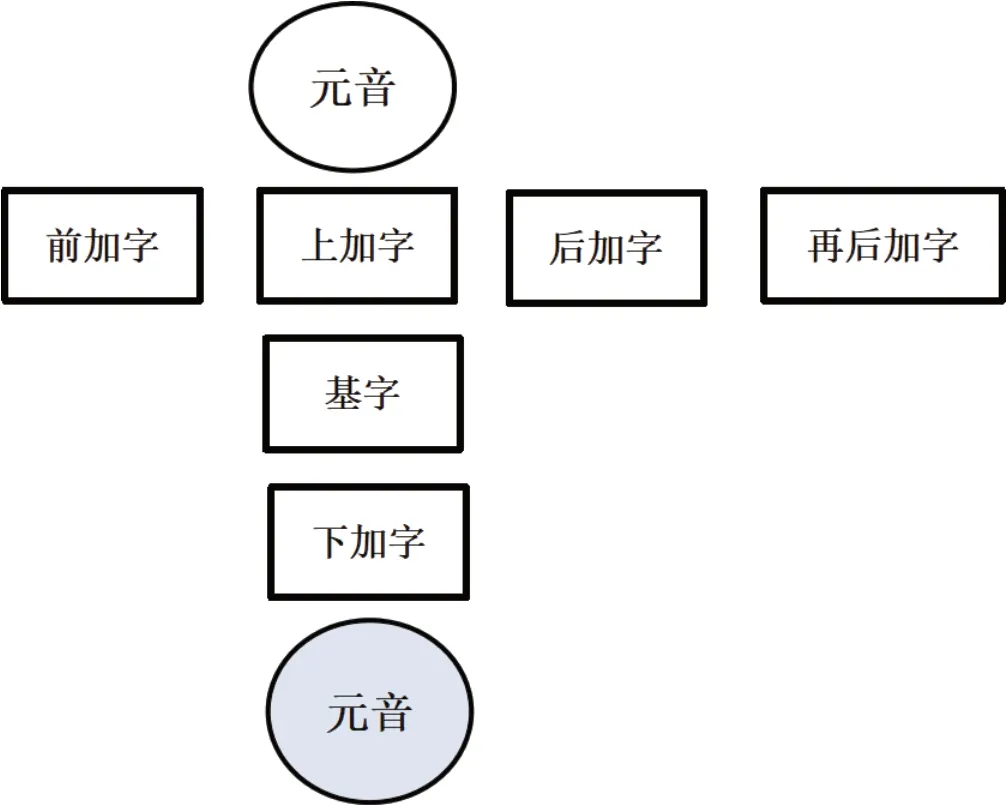
图1 藏文字七个构件结构Fig.1 The structure of seven components of Tibetan characters

图2 藏文字四个构件结构Fig.2 The structure of the four components of Tibetan characters
由于组合构件可数且规模不大,因此通过建立组合构件库可将组合构件分解为基本构件。组合构件库由组合构件字、基字序号、元音字母序号、上加字序号和下加字序号等组成,用于存放相应的组合构件及构成组合构件的序号。组合构件字字段中存放组合构件字,元音字母序号字段表示该组合构件是否含元音或所含元音,基字序号字段以自然序列存放30个基字,上加字序号字段表示该组合构件是否含上加字或所含上加字,下加字序号字段表示该组合构件是否含下加字或所含下加字, 用不同的序号表示不同的基字、元音、上加字、下加字。
4 功能实现
4.1 后端实现
后端我们采用的是Python语言,Python语言有着开发周期短、可移植性、可拓展性等优点,快速开发、后期还可移植到小程序、App上,符合我们的研究意义。
实现后端主要考虑以下几个问题:a.如何给传入文章中的藏字切段
传入文章后,我们首先让文件进入TibetanDocu mentProcessing.py程序中,让所有字段匹配所有的Unicode字符集:
parttern1匹配所有藏文字符[u0f00-u0fff]
parttern2匹配所有全角字符[u0f20-u0f29]
parttern3匹配所有特殊字符'》|)|'|'
然后我们考虑把所有特殊和全角字符用“d”替代以方便我们查找文字。然后我们就能把所有的藏文转化为可分析的藏文字段。
对于有加字的情况,我们利用藏文Unicode编码的规则来取有加字的基字,具体代码如图3所示:
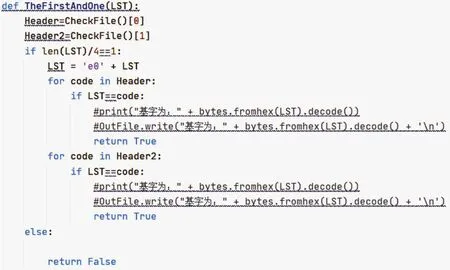
图3 代码Fig.3 Code
然后具体再判断元音、上加字、前加字、基字、下加字、再后加字的各种情况,代码忽略,不再一一赘述。
b.如何匹配字库判断错误
根据藏文的所有藏字组合规则,我们建了一个标准字库resource.txt里面包括所有符合规则的藏字,我们会把所有的传入文件并进行分割的字传入进行匹配,将长度不足7的字,用空格补全到长度为7,然后一一判断基字、上加字、前加字、下加字、元音、后加字、再后加字,最后返回ture/false,从而实现匹配字库检验错误。
4.2 前端实现
前端我们设计了网页,能有主要的传入传出文件,显示错误字段信息的功能就好,后期再优化一下布局。
最后页面成品如图4所示。

图4 界面Fig.4 Interface
4.3 算法分析
我们的关键算法是如何分割藏字和如何匹配字库判断错误,藏文字符的长度是构成该藏文字的构件的多少。如:一个构件构成的藏文字符长度为一,两个构件构成的藏文字符长度为二等以此类推。现代藏文字符最长由7个构件构成。在判断现代藏文字符的具体构件时,首先根据藏字长度将藏文字符分为7大类,然后每一类按照藏文从左到右,从上到下的书写顺序进行匹配,也就是构件进行识别。
算法实现:字符长度为1的藏文构件识别为基字。字符长度为2的藏文构件形式有4种,分别为:基字+元音,基字+后加字,上加字+基字,基字+下加字。字符长度为3的藏文构件形式有12种,分别为:前加字+基字+后加字,前加字+基字+元音,前加字+上加字+基字,前加 字+基字+下加字,上加字+基字+元音,上加字+基字+下加字, 基字+下加字+再下加字,上加字+基字+后加字,基字+下加字+ 元音,基字+下加字+元音,基字+下加字+后加字,基字+元音+后加字,基字+后加字+再后加字。字符长度为4的藏文构件形式有14种,分别为:前加字+上加字+基字+元音,前加字+基字+下加字+元音,前加字+基字+元音+后加字,前加字+上加字+基字+下加字,前加字+上加字+ 基字+后加字,前加字+基字+下加字+后加字,前加字+基字+后 加字+再后加字,上加字+基字+下加字+元音,上加字+基字+元音+后加字,上加字+基字+下加字+后加字,上加字+基字+后加字+再后加字,基字+元音+后加字+再后加字,基字+下加字+元音+后加字,基字+下加字+后加字+再后加字。字符长度为5的藏文构件形式有10种,分别为:前加字+上加字+基字+下加字+元音,前加字+上加字+基字+下加字+后加字,前加字+上加字+基字+元音+后加字,前加字+上加字+基 字+后加字+再后加字,前加字+基字+下加字+元音+后加字,前 加字+基字+下加字+后加字+再后加字,上加字+基字+下加字+元音+后加字,上加字+基字+下加字+后加字+再后加字,上加字+基字+元音+后加字+再后加字,基字+下加字+元音+后加 字+再后加字,具体识别结果如下:字符长度为6的藏文构件形式有5种,分别为:前加字+上加字+基字+下加字+元音+后加字,前加字+基字+下加字+元音+后加字+再后加字,前加字+上加字+基字+元音+后加字+再 后加字,前加字+上加字+基字+下加字+后加字+再后加字,上加字+基字+下加字+元音+后加字+再后加字。字符长度为7的藏文构件形式只有1种,是前加字+上加字+基字+元音+后加字+再后加字。流程图如图5所示:
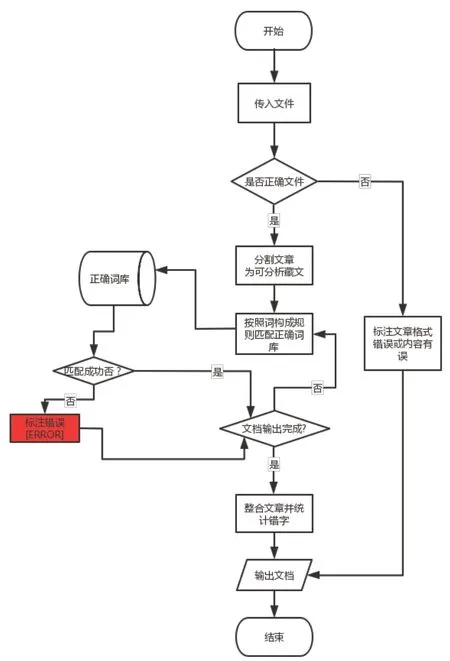
图5 流程图Fig.5 Flow chart
5 结果分析
图6为我们的登陆界面,图7为我们上传文件的操作,图8为识别到文档中的文字,图9为文字进行检错后的结果显示。

图6 登录藏文处理平台Fig.6 Logging in to the Tibetan language processing platform
图7 选择藏文文件Fig.7 Select Tibetan file

图8 开始检测Fig.8 Start detection

图9 导出检测结果Fig.9 Export test results
6 结语
此系统已经能够实现我们想要达到的效果,后期我们还可以对界面进行美化以及增加一些其他功能使系统更加完善,同时也可以进一步进行小程序和App的开发。
