聚类算法在情绪监测方面的应用研究
2022-03-19蒋雅宁
蒋雅宁

摘要:聚类是数据挖掘的一种手段,把特征相似的数据聚在一起,论文尝试通过不同的聚类算法对数据集进行聚类,得出不同聚类算法的轮廓系数并对其行分析研究,得出最佳算法,然后确定k值,结果是当k=2时基于K-means聚类算法的情绪聚类效果最好。研究结果可以应用到抑郁症治疗或者心理学领域方面,未来做一个分类器进行快速的情绪分析,可以预测患者是否会患上抑郁症或者抑郁症发作,有很好的社会应用价值。
关键词: 聚类算法;情绪监测;抑郁症;K-means
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2022)02-0031-02
1引言
所谓“物以类聚,人以群分”,聚类就是把相似的数据点聚在一起,相同特征的类具有高度的相似性,不同特征的对象之间存在较大的差异。通过聚类,可以将大数据集随机分成块。每个块都是一个样本集,可以保证原始数据集的独立采样,在足够小的范围内保证处理结果的可靠性。[1] 同时伴随着人类工作生活压力的不断增加,患有心理疾病的人群越来越多。如果可以及时监测情绪,便可以减少心理疾病的发病率,具有很好的应用价值。
2 聚类算法概述
2.1聚类算法
聚类的目的是寻找联系紧密的事物进行区分,将数据划分为有意义或有用的簇,聚类的目标是,尽可能扩大不同数据组与数据目标之间的差距,无监督学习取决于输入数据集是否被标记[1]。
2.2聚类算法的种类
基于划分的聚类:划分聚类算法就是最优化目标函数,将给定数据对象的数据集,划分为几个类,每一类别组就是赋予其的划分类别标签。最经典的划分聚类算法k-均值算法和k-临近算法在它们的基础上衍生出了无数种变形算法[2]。主要代表算法有:K-means算法、K-medoids算法、clarans算法。
基于密度的角聚类:K-means能检测非球面类别的数据分布,但是基于密度的方法可以检测不规则的形状。同时,它可以在有噪音的數据中发现各种形状和各种大小的簇而且可以很好地处理噪声数据,与划分和层次聚类方法不同,它是将簇定义为密度相连的点的最大集合.主要的密度聚类算法有:DBSCAN算法、DENCLUE算法等,其中的DBSCAN算法是靠连接高密度邻域点来发现簇的。
基于网格的聚类:数据空间被划分为网格结构,由底向上的网格分割法可以将用户输入的参数分成同等大小的网格单元。如果落入网格单元的数据点比较多,称为高密度网格单元。网格中的单元数量受到限制并且所有处理都在一个单元上完成。基于网络的方法最主要的优点是其快速的处理速度[3]。最有代表性的网格聚类算法有STING[4]、WaveCluster、CLIQLE等。
3 聚类算法及数据集介绍
3.1数据集简介
数据集是一种利用脑电生理和情感分析的数据集,参加数据集采集的相关人员是由英国实验室研究小组人员Sander Koelstra,伦敦大学玛丽皇后学院,英国;Christian MüHL,屯特大学,荷兰等5人和各国外高校指导专家Ioannis Patras博士,Anton Nijholt博士,Touradj Ebrahimi博士。由欧盟“Seventh Framework 计划”,荷兰经济事务部、教育部、文化科学部共建的“ BrainGain 智能混合方”,瑞士国家基础科学研究和教育互动的多模式联运信息管理委员会支持和资助。 数据集是32×40的元胞矩阵,32代表人数,40代表40个不同影片。
3.2 数据集来源
选择了32个测试者(男女各占一半)观看筛选出的40部影片,影片观看完毕之后,测试者进行填表评价,arousal, valence, liking and dominance这四个标签代表四种情绪的分值。arousal: 唤醒可以从不活跃(例如,不感兴趣,无聊)到活跃(例如,警觉,兴奋)valence: 效价则从不愉快(如悲伤、紧张)到愉快(如高兴、开心),dominance: 支配的范围从无助和软弱的感觉(没有控制)到强大的感觉(控制一切),liking: 喜欢度。
4 算法的实现
4.1实现过程
(1)读取数据:
import pandas as pd
datas = pd.read_csv('./labels.csv')
(2)查看数据维度
(shape):
print(datas.shape)
(1280,4)
(3)接下来查看数据的前8行数据。
当选择要挖掘的数据集后,开始在挖掘之前对这些数据集中的数据进行预处理。因为数据集中的值是标准化的,所以不需要统一数据集的属性,之后进行数据清理,主要解决的问题有: 空缺值、错误数据、孤立点、噪声[5]。其中空缺值和错误数据是这一步骤处理的重点。此数据集没有缺失数值,故不用使用填补方法来处理数值变量的缺失值。
4.2结果分析
(1)不同聚类算法的轮廓系数值
聚类是一种典型的无监督学习任务。由于没有标签,很难评价聚类结果的优点和缺点。直观上来看,聚类是把相似的样本化为一簇,不同的样本划分到不同的簇内。基于这个观点,研究人员研发了度量聚类结果的方法,其中轮廓系数适用于实际类别信息未知情况,正适合数据,如图1所示。
因为轮廓系数取值范围是[-1,1],所以同种特征的样本距离相近且不同特征的样本距离越远,分数越高,通过图1可以直观地看出,K-means算法的轮廓数值是最高的,高斯混合聚类的数值仅次于K-means算法后,数值最低的是DBSCAN算法。所以针对本数据集聚类效果最好的是K-means算法。
(2)模型优化
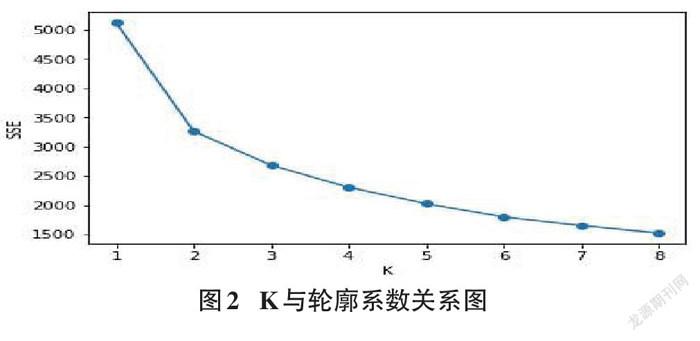
在前面部分,对比三种聚类算法的两种评价指标后,获得K-means聚类算法聚类效果相对较好一点,但是之前直接对其进行指定聚成4簇,所以在这部分内容,使用K-means最优的K值进行细分,也就是寻找到最优簇数。轮廓系数可以作为一个评价聚类效果的指标,现在可以让K值从2开始递增测试,找到选择K值后对应的轮廓系数最高的K值。因为scikit-learn中的K-means算法从1开始时,聚类的labels会等于0,这时会报错,所以在轮廓系数这里选择的K值下限为2,在选择最大簇数上限时一般不会太大,这里选择为8,结果如图2所示:
从图2可以看出当K值为2时,轮廓系数较高,也就是此时的聚类效果也会较好。
5 基于k=2的K-means聚类算法的应用
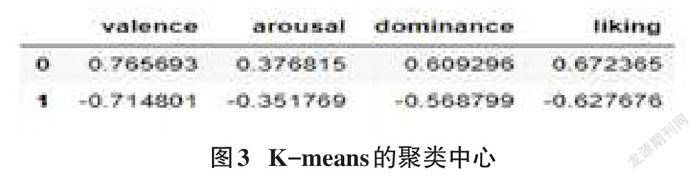
首先,观察K-means聚类出来的每一个类中样本的数目。在聚类的2个类中,第一个类中有618个样本,另一个类中有662个样本,相差不大。 但是为了更好地理解每一个类所代表的样本群体的特点,观察每一个类的聚类中心(cluster center)。聚类中心如3所示:
如果聚类中心在某一个变量取值大于0,代表该聚类所代表的群体在该变量取值大于群体平均水平。 首先对上述聚类结果数据框进行转置,然后对每一个聚类中心的变量取值从大到小进行排序。 通过观察每個聚类变量来分析聚类所代表的群体:
第一个聚类:
valence 0.765693 liking 0.672365 dominance 0.609296 arousal 0.376815
结果:第一个聚类所代表的样本群体的情绪为:愉快、喜欢、支配的范围强大、兴奋。
第二个聚类:
arousal -0.351769 dominance -0.568799 liking -0.627676 valence -0.714801
结果:第二个聚类所代表的样本群体的情绪为:不愉快、不喜欢、有无助的感觉、不活跃。
未来可以根据以上研究做出情绪分类器,应用在情绪监测的领域,可以有效地监测和预防心理疾病的发病率。
6 结束语
目前聚类的方法很多,分类方法也不尽相同。聚类算法可以应用到社会生活的各个方面,随着大数据时代的不断发展,不仅可以应用到抑郁症监测领域,还可以应用到商业分析中。本文通过比较不同的聚类算法,分别分析了他们的适用范围,虽然每种聚类算法都有适用的领域,但是也同时存在着需要改进的地方,本文只是选择了一个最适合此次实验的聚类算法并加以分析。
参考文献:
[1] 贺玲,吴玲达,蔡益朝.数据挖掘中的聚类算法综述[J].计算机应用研究,2007,24(1):10-13.
[2] 刘屹霄.考虑信息均衡与数据簇可分性的模糊软子空间聚类[D].厦门:厦门大学,2017.
[3] 陈伟,李红,王维.一种基于Python的K-means聚类算法分析[J].数字技术与应用,2017(10):118-119.
[4] 梁玉翰.基于STING与支持向量回归机的网络安全预警技术研究[D].郑州:解放军信息工程大学,2008.
[5] Famili A,Shen W M,Weber R,et al.Data preprocessing and intelligent data analysis[J].Intelligent Data Analysis,1997,1(1/2/3/4):3-23.
【通联编辑:闻翔军】
