相似重复记录检测研究与发展动态的知识图谱分析
2022-03-18董永权
顾 晴 董永权 胡 杨
(江苏师范大学智慧教育学院 江苏 徐州 221116)
0 引 言
随着信息技术的快速发展和信息化管理的不断推进,数据库中的记录数量呈指数上升,引发了大数据环境下相似重复记录检测的需求,是近年来数据挖掘领域的研究重点。大量相似重复数据在整合时降低了数据质量,对数据库的利用率带来直接影响。因此,如何高效率地检测出相似重复记录是数据清洗的关键点和提高数据质量的首要任务。
相似重复记录检测是识别出多个数据库中的同一实体,在不同研究领域中有多种名称表示,如duplicate record detection、entity resolution和 record linkage等,相应中文名称有相似重复记录检测、实体识别和记录链接等。Newcombe等[1]提出这个概念后,国内外研究者在各个领域进行深入的研究,提出大量的检测方法,检测精度也不断提升。Elmagarmid等[2]总结了当时国外的相似重复记录检测技术,从字符、标记、语音和数字四个方面分析相似性度量方法,从机器学习和概率推理两类技术进行归纳,提出减少记录比较数量和提高单记录比较速率两种提升相似重复记录检测效率的方法。自发表至今,一共被引用672次,是目前为止分析最全面、被引次数最多的相似重复记录检测综述。经过之后十多年的积累, 国内外相似重复记录检测方法又涌现出相当多的高水平成果,迫切需要对新的文献加以归纳整理。考虑到简单的文献回顾难以客观分析该领域的作者合作关系、研究热点及发展趋势,有必要通过文献计量和可视化的方式进行探究。
文献计量方法可以对海量文献进行可视化分析,得到特定领域的文献特征,能够全面分析某一领域的热点及发展趋势[3]。社会网络是指行动者 (个体、群体或组织等) 及其关系的集合[4]。社会网络分析则是对这些关系数据的分析与研究。科学知识图谱是结合文献计量法及信息可视化原理,以科学知识为对象,展示科学知识的演进过程与结构关系的一种图形表示方法。
本文收集了2008—2019年间国内外对相似重复记录检测的相关文献,分析了发文量的时间分布以及发文核心机构分布。通过社会网络分析软件Ucinet对这些论文的作者建立合作网络图谱,分析了核心作者群。使用数据可视化软件CiteSpace对文献关键词进行聚类,并根据时间脉络进行分析,呈现出近十年在相似重复记录检测问题的知识图谱,并对其研究热点和趋势进行了探究,提出面临的挑战,指明今后的研究方向。
1 研究方法与数据来源
1.1 研究方法
(1) 社会网络分析。社会网络分析采用Ucinet(University of California at Irvine NETwork)软件。Ucinet内置大量的网络指标计算模块,是一款功能强大的社会网络分析软件[4]。最初由社会网络研究的开创者Linton等网络分析者编写,之后由美国波士顿大学的Steve和英国威斯敏斯特大学的Martin共同维护。它可以生成多种可视化图谱,反映分析对象的结构和关系。
本文将EndNote格式的中文文献题录和.txt格式的外文文献题录分别导入Bicomb,通过格式转换后分别创建.txt格式的作者共现矩阵,之后将矩阵导入Ucinet生成.##h文本矩阵,通过对Netdraw的调用产生可视化图谱,并对社会网络参数进行中心度等计算。
(2) 知识图谱分析。知识图谱采用CiteSpace(5.5.R2)软件,CiteSpace是由美国德雷塞尔大学的陈超美博士开发的文献数据可视化软件[5]。该软件主要运用共引分析理论对某领域的文献信息进行计量,通过寻径网络算法等方法找出关键节点,绘制出相关的科学知识图谱,实现信息可视化分析[6]。通过它展现的知识图谱,可以较直观地显示该研究学科过往的演化历程、当今的研究热点、日后的研究趋势。迄今为止,CiteSpace被广泛运用于对文献的可视化分析。
本文在CiteSpace中将时间阈值设置为“2008”到“2019”, 连线阈值数据对象(Links)强度设为‘cosine’类型,节点阈值(Selection Criteria)中三个时间切片的最低被引次数(citation)、本切片内的共引次数(cocitation)和共被引率(Cocitation cosine coefficient)分别为1、1、20;1、1、20;2、2、20。剪枝(pruning)采用寻径网络算法(Pathfinder),filter为1。主要应用CiteSpace的聚类分析(Cluster)、文本主题共现(Term、Keyword),对文献关键词进行分析,进而总结出相似重复记录检测的研究热点及发展趋势。
1.2 数据来源
本文采集2008—2019年国内外有关相似重复记录检测的相关文献进行统计分析。采用的外文文献来源于World of Science(WOS)的核心数据库,以“duplicate record”“entity resolution”“record linkage”“ record ma-tching”“entity matching”和“record merge”为标题分别进行检索。中文文献来源于中国知网(CNKI),以“重复记录”“记录匹配”“实体匹配”“记录链接”和“记录合并”为篇名分别进行检索。经过相关内容筛选后共获得153条有效国外文献记录和149条有效国内文献记录。
2 文献发文量
文献的发表数量及其在时间上的分布,可以反映出该研究内容在研究历史上的被关注程度以及发展情况。将国内外关于相似重复记录检测的文献按照年份绘成发文量年度分布图(见图1)。

图1 国内外文献发文量年度分布
相似重复记录检测最早起源于国外,从每年度文献发表的数量上来看,近10年内国内外相关的文献发表量总体上逐步上升,这表明近10年国内外在相似重复记录检测研究上的关注度呈增长趋势。从图1可以看出,2008年到2012年,国外研究经历了一个低潮期,发文量较少。随着相似重复记录检测应用领域的扩大和检测技术的发展,自2012年起发文量开始逐步增长,2018年高达27篇文献。国内近10年一直持续着对相似重复记录检测的研究热情,发文量整体上波动幅度不大,每年稳定在15篇左右。2015年和2016年出现一个明显的低潮期,但从2017年起,由于深度学习等技术被重新关注研究和发展,以及其在自然语言处理领域的应用,相似重复记录检测这一研究又吸引了众多学者的目光,发文量呈现稳步回升。从整体数量上看,国内外文献近10年文献发表量相差不大,但是自2015年起国外文献数量均高于国内文献数量。
3 核心研究机构
通过对发文作者所在机构的统计,可以了解相似重复记录检测领域研究的核心机构。根据World of Science和CNKI的文献分析,获得相似重复记录检测文献发文量排名前五的国内外高产机构如表1和表2所示。

表1 国外文献高产机构

表2 国内文献高产机构
2008年以来,发文量并列排名第一的研究机构是澳大利亚国立大学(Australian National University)、谷歌公司(Google Incorporated)和哈尔滨工业大学(Harbin Institute of Technolog)。澳大利亚国立大学偏向于隐私保护的相似重复记录检测技术,通过分析各种不泄露隐私信息的方式进行相似重复记录检测[7]。谷歌公司发表的8篇文献中有6篇与斯坦福大学(Stanford University)合作,总被引用次数为341次,提出基于否定规则、web、多个数据集和主动抽样等一系列通用实体识别模型。哈尔滨工业大学在外文期刊上同样发表了8篇文献。希腊开放大学(Hellenic Open University)共发表6篇文献。
国内在相似重复记录检测方面发表文献最多的是东北大学,发表数量达18篇,对关系数据对象识别、复杂数据空间中的数据对象识别、具有时间特性的数据对象识别、隐私保护下数据对象识别和Deep Web环境下的实体识别研究等方面进行了深入研究。哈尔滨工业大学在国内期刊上发表了15篇文献,总产量属于国内外第一位。高红、李建中、李玲丽和王洪志等相继做了记录匹配的动态约束、基于规则的实体解析方法等相关研究。
4 社会网络分析
White博士[8]认为,作者共现频率越高,则作者在这一研究领域的学术相关性越强。因此,通过图谱和网络结构分析,可以了解相似重复记录检测领域的核心作者群。为了更明显地展示出主要合作团队,将阈值设为2,使用Bicomb生成作者共现矩阵。共现矩阵导入Ucinet社会网络分析软件,生成.##h文件,再进一步借助Netdraw,经过中心性度计算,去掉没有合作的单节点,生成作者共现社会网络图谱(见图2和图3)。
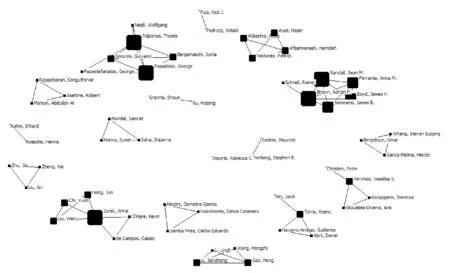
图2 国外文献作者合作社会网络图谱

图3 国内文献作者合作社会网络图谱
根据Ucinet统计以及图2和图3中的信息,在发表两篇及以上的作者中有合作关系的外文文献作者共57位,中文文献作者共24位,国外形成合作团体共16个,国内共6个,无论是作者数量还是合作团队数量都明显多于国内。网络密度的数值越大则表示网络中成员联系越紧密,国外文献作者合作网络的密度为0.071 6,国内为0.284, 国外研究学者主要是多个小团体的合作,总体合作情况要优于国内,而国内除了几个大团体的合作,其他作者之间的合作关系不明显。整体上看,国内外的作者合作结构都比较松散,作者之间联系不多。
根据发文量排名前十的作者 (见表3),并结合图2、图3的信息可以得出,发文量高的作者擅长团队合作,因此可以从团队角度分析其研究内容。

表3 作者发文篇数前十位
国外文献作者影响力较大的有四个合作团队。第一个是科廷大学(Curtin University) 的Ferrante、Randall、Semmens和Boyd等组成的团队, 在2016年和2017年互相合作4篇文献,主要研究在大型医疗数据集上,确保隐私的相似重复记录检测方法。提出的PPRL(Privacy-Preserving Record Linkage)模型,在不影响隐私和质量的情况下扩展了记录链接[9]。第二个是雅典大学(University of Athens)的Palpanas 、 Papadakis和George等组成的团队, 从2013年起共合作4篇文献,注重研究分块技术,希望通过元分块对生成的块进行重组以提高精度。第三个是哈尔滨工业大学的李建中、高宏和王宏志等组成的团队,共合作发表5篇外文文献,同时,这个团队在国内期刊上也合作发表5篇文献。研究主题包括基于规则的实体识别、异构数据库中的实体识别、基于Map-Reduce的大数据实体识别、基于二分图的最优匹配的记录相似度计算、基于并行机群的大数据实体识别等。研究范围十分广泛,可以看出这个团队在国内外相似重复记录检测领域都具有影响力。第四个是斯坦福大学(Stanford University)的Garcia-Molina 和Whang等组成的团队,共发表4篇合作文献。结合无监督学习中的聚类,研究基于规则的相似重复记录检测技术。高产作者中,Verykios、Vassilios和Christen也产生过合作关系,但是合作频次不大,仅有两篇合作文献。
国内文献作者合作中除哈尔滨工业大学的团队外,还有一个来自东北大学的申德荣、聂铁铮、寇月、于戈、孙琛琛、韩姝敏和杨丹组成的团队,2008年至今,围绕Deep Web、机器学习、异构网络、隐私保护几个主题,共发表13篇相关文献。其中,寇月、申德荣等发表的《一种基于语义及统计分析的Deep Web实体识别机制》是2008年起国内的第一篇有关相似重复记录检测的文献,被引用次数高达72次。该文献针对Deep Web数据集成中的实体识别问题进行了深入的研究, 提出一种基于语义及统计分析的实体识别机制, 能够有效解决Deep Web数据集成中的数据消重及表象整合等问题[10]。除了这两个团队,还有郭文龙和殷秀叶两人,更擅长独立探索,分别对异构数据库和大数据环境下的相似重复记录检测技术有一定的研究。
5 研究热点和趋势
5.1 研究热点
关键词是学术论文研究内容的高度概括,它的关联性在一定程度上可以体现出学科领域中的研究热点[11]。为了保证分析的全面性, 本次图谱构建没有限制主题词来源,将主题词类型设置为名词短语(noun phrases)及突现词(burst terms), 节点类型设置为关键词(keyword),得出国内外文献关键词共现图谱。之后在其基础上进行聚类,并使用对数似然率算法(LLR)抽取关键词对每个聚类进行自动标识,由此得到国内外相似重复记录检测研究的关键词聚类如图4和图5所示。模块值(ModularityQ)和平均轮廓值(Mean Silhouette)是反映聚类边界清晰度和聚类规模的两个指标。国外文献关键词共现图谱共有511个节点,1 394条连线, 网络密度为0.010 7,Q值为0.847 3(>0.3),Mean Silhouette值为0.543 8(>0.4); 国内文献关键词共现图谱共有371个节点, 760条连线, 网络密度为0.011 1,Q值为0.875 6(>0.3), Mean Silhouette值为0.932 4(>0.4), 这表明该共现图谱聚类结构显著, 各聚类同质性较好。对聚类结果进行统计后,得到国内外频数前十的关键词汇如表4所示。

图4 国外文献关键词聚类图谱

图5 国内文献关键词聚类图谱

表4 国内外高频关键词
由图4可知外文文献包括13个主要聚类,分别是实体匹配(聚类#0 entity matching)、元分块(聚类#1 meta-blocking)、重复数据删除(聚类#2 deduplication)、医疗记录联动(聚类#3 medical record linkage)、关联数据(聚类#4 linked data)、数据清洗(聚类#5 data cleaning)、近似串匹配(聚类#6 approximate string matching)、重复捕获(聚类#7 capture-recapture)、fellegi-sunter模型(聚类#8 fellegi-sunter model)、数据库管理系统(聚类#9 database management system)、数据链接(聚类#10 data linkage)、知识表示(聚类#14knowledge representation)、不确定属性(聚类#28 uncertain attribute)。由图5可知中文文献包括13个主要聚类,分别是实体识别(聚类#0)、实体匹配(聚类#1)、重复记录(聚类#2)、智能检测(聚类#3)、deep web(聚类#4)、数据质量(聚类#5)、信息集成(聚类#6)、大数据(聚类#8)、记录匹配(聚类#9)、编辑距离(聚类#10)、重复记录识别(聚类#11)、SNM(sorted-neighborhood method,基本邻近排序)算法(聚类#12)、mapreduce(聚类#13)。国内外的主要聚类出现实体匹配、数据清洗、数据质量等类似聚类,具有高度的相似性,总体说明在相似重复记录检测的研究主题上国内外的关注点是基本一致的。但是国外文献在医疗数据链接上产生较大聚类,显示出国外研究学者将相似重复记录检测应用在医疗数据中的程度较高,而国内文献大多将其运用在智能检测中。同时国内文献关于Deep Web和大数据形成两个较大的主要聚类,表明在2008年以来,国内对于有关deep web以及大数据的相似重复记录研究关注度要高于国外。
从表3中可以看出国内外相似重复记录检测研究的热点关键词主要可以分为两类。一类是应用环境与领域类,包括相似重复记录、实体识别、数据清洗、多源异构数据、大数据、deep web、数据质量、数据集成、隐私和医疗记录链接。另一类属于检测方法类,包括知识库、SNM算法、神经网络、聚类、分块和算法。
SNM算法和CURE算法属于相似重复记录检测中两种比较主流的算法,近几年,有较多学者对这两种基本算法进行了改进。SNM算法最早由Hemandez等提出。针对其在数据量过大时,传统排序需要大量的时间和空间的缺点,郭文龙[12]提出一种基于长度过滤和有效权值的SNM改进算法,将不可能构成相似重复记录的数据排除在外,减少记录比较的次数,提高检测效率。Wang等[13]提出将SNM和迭代相结合的机制(SIER),兼顾了检测效率与准确率。之后刘雅思等[14]针对属性值缺失时容易造成误判的情况,提出基于长度过滤和动态容错的改进基本邻近排序(SNM based on length filtering and dynamic fault-tolerance,LF-SNM)算法,根据记录其他字段的相似度情况,动态调整记录中属性缺失字段的相似度结果,提高检测精度。CURE算法对相似重复记录进行分层聚类,可以针对任意分布、类型的数据进行聚类,效率较快,因此被人们广泛地应用。王民等[15]针对CURE算法在随机抽样阶段存在的随机性问题,采用Binary-Positive算法进行改进,以获取数据集中更有用的样例进行层次聚类。伍恒等[16]在CURE算法的基础上引入了信息熵,利用信息熵计算样本的相似度,根据样本间的相似度量与不同簇之间的关系,将数据集分为高低两个阶段,对不同阶段的样本采用不同的选取策略。孙元元等[17]提出一种新的原型选择算法PSCURE(improved prototype selection algorithm based on CURE algorithm),针对CURE噪声点不易确定及代表点分散性差的特点,利用共享邻居密度度量的去噪方法和最大最小距离选取代表点方法进行改进,获得较高的检测准确率。
国内外研究学者在相似重复记录检测的应用领域及技术提升上有很高的关注度,提出了种类繁多的检测算法,应用范围也越来越广。根据有关国内外关键词知识图谱以及关键词聚类汇总结果表的分析可以得出结论,相似重复记录检测一直是数据清洗领域的热门话题,大量的国内外研究学者不断在扩展相似重复记录检测的应用领域、调整检测相似重复记录的角度、优化相似重复记录检测的算法、寻求更加高效的相似重复记录检测方案,提升检测效果。
5.2 研究趋势
时区演化图谱能够直观地反映研究领域文献的更新和关联程度,从而反映出研究的演进趋势和特点,以此预测未来研究的发展方向[5]。Citespace的时区演化图谱根据产生年份,使用节点大小和线条色彩来绘制研究热点发展全貌,可以清晰表征研究热点的发展轨迹。利用Citespace对国内文献和国外文献的关键词进行timezone操作,生成时区演化图谱,并且标记出每个年度的重点关键词 (见图6和图7)。各研究热点颜色差异表征该热点词首次出现的时间差异,由深到浅、由紫向黄的分布代表出现时间从先到后,呈现出相似重复记录检测领域研究主题的变迁。这两幅图侧重于在时间维度上表示研究热点的变化,能够更好地表达出研究主题的发展趋势。

图6 国外文献的关键词时区演化图谱

图7 国内文献的关键词时区演化图谱
2008年以来,国内外对相似重复记录检测技术的研究主要分为三个阶段。
第一个阶段处于2010年之前,国内外研究方向集中在对相似重复记录检测的不同应用领域的探索。在异构数据库上,Efthymiou等[18]提出一种并行执行方法,减少在异构数据上的数据交换消耗。在人口普查上,国外将相似重复记录检测应用于人口普查中,解决大规模人口普查问题,有效地对人口数据进行了数据清洗,提高了数据质量。在隐私保护上,国外掀起了在缺少值的情况下对隐私保护记录链接的研究[19]。国内在保持数据间相对距离的基础上进行记录链接,在保证链接效果的同时实现隐私保护。此外,韩普等[20]以多源大数据为数据源,建立出面向医疗领域实体识别知识图谱框架。
第二个阶段由2010年到2017年,研究方向集中在对相似重复记录检测方法的研究。机器学习方法研究热度久居不下,在监督学习中,支持向量机由于在相似重复记录识别上的良好表现,被国内外学者重点研究;在无监督学习中,孙琛琛等[21]就面向实体识别设计出一种聚类算法,来弥补匹配问题的缺失。由于2010年Hinton在Nature上发表的深度学习论文,研究学者也开始结合其他研究方法,将深度学习应用到相似重复记录识别领域。徐红艳等[22]针对Deep Web提出一种基于BP神经网络实体识别方法,该方法在提高实体识别的效率和准确率的同时能够减少实体识别中的人工干预。吴庆辉等[23]结合神经网络的非线性映射以及遗传算法的优化特性,获得了更佳的模型参数来解决大数据量情况下的相似重复记录检测问题。陈芬[24]提出的量子粒子群优化神经网络模型,大幅度减少相似重复记录检测时间,在数据整合方面有了很大的进步。除此之外,用于解决大数据量的相似重复记录检测问题的分块技术也有进一步发展。Papadakis等[25]通过分块扩展到大型数据集合。佟丹妮等[26]利用局部敏感哈希结合后缀分块的二次分块方法,设计适用于大型数据的基于安全多方计算的匹配算法。同一时段,国外在众包上做了深度探索,用人群的智慧和力量来提高实体解析的效率和质量,Chai等[27]搭建出具有成本效益的众包实体解决方案框架,在保证质量的前提下,将成本降低至现有方法的1.25%。国内也开始考虑到维度的增加会提升识别的难度,使用R-树构建索引保留记录的高维特性,避免了高维数据稀疏性的影响。
第三个阶段是2018年至今,国外开始更注重自动数据处理,以此减少人类的工作量,并且将关注点移动至特征选择,借助更典型的特征提升检测精度。国内在更多类型的数据上开始进行相似重复记录识别研究,包括工业大数据、文本大数据等。为了提升深度学习的学习速率,国外开始使用多GPU进行计算,Boratto等同时利用多核和多GPU架构来执行数据库的概率链接,同时提高了精度和性能[28]。国内更注重安全实体识别以及在大规模记录上的相似重复记录识别,并且在神经网络中添加了自注意力机制。
6 结 语
如今信息系统中数据量成指数增长,对相似重复记录检测方法要求的稳定性、准确性及检测速度提出巨大的挑战,国内外学者开始寻求各种检测方法的集成,希望能够借助各种方法的优势,达到更好的效果。
相似重复记录检测目前面临的挑战可以总结为3点。(1) 对数据缺失值的处理,数据缺失会对相似重复记录的检测制造出困难,需要根据具体数据的缺失类型,调整现有的相似度算法等。(2) 对多数据源的识别,在实际应用中,来自多个数据源的相同记录由于组织结构、格式等的不同导致表示形式差异较大,提升检测难度。(3) 分布式实体识别,在当今大数据时代,面向高级别数据量的相似重复记录检测一直是研究学者关注的热点,如何设计有效的分块技术,解决在大数据量环境下碰到的数据分布不均的问题也是相似重复记录检测如今面临的挑战之一。
本文运用可视化信息分析软件CiteSpace和社会网络分析软件Ucinet,结合World of Science和CNKI的数据分析,呈现了2008年以来在相似重复记录检测领域国内外相关文献的关键词演化图谱和作者合作网络,主要分析了相似重复记录检测领域文献发文量的年度分布、发文核心机构、作者合作群、研究热点和研究趋势,为今后探索相似重复记录检测方法提供了文献参考及研究方向。
