面向片段抽取式机器阅读理解的注意力网络*
2022-03-17赵加坤戴梦瑶刘江宁邱超凡赵子双
赵加坤 戴梦瑶 刘江宁 邱超凡 赵子双
(西安交通大学软件学院 西安 710049)
1 引言
机器阅读理解(MRC)是自然语言处理中的一项具有挑战性的任务。该任务在智能搜索、对话助手、智能客服等应用中发挥着重要作用。近年来通过众包或人工生成的方式,出现了许多激动人心的大型MRC 基准数据集[1~5],其中Stanford Question answer Dataset(1.1)[3]及其补充版本(2.0)[5]尤其受欢迎。
得益于深度学习技术[6]和大规模MRC 基准数据集[1~5]的快速发展,端到端神经网络在MRC 任务上取得了可喜的进展。Hu 等[9]迭代地将文章与问题以及问题本身进行对齐,以捕获长距离的上下文交互作用。Liu 等[10]在训练过程中采取了随机屏蔽预测方法。尽管有了这些进展,但这些模型都遇到了一个普遍的问题,即由于RNNs 的顺序性,它们在训练和推理方面都很耗时。这意味着需要等待很长一段时间才能得到直接反映所提方法正确性的实验结果,并指导下一步的改进方向。同时,缓慢的推理阻碍了MRC 系统在实时应用中的部署。
在文章中,我们提出了一个快速有效的细粒度注意网络,如图1 所示,旨在解决模型的慢度问题,同时保证良好的性能。
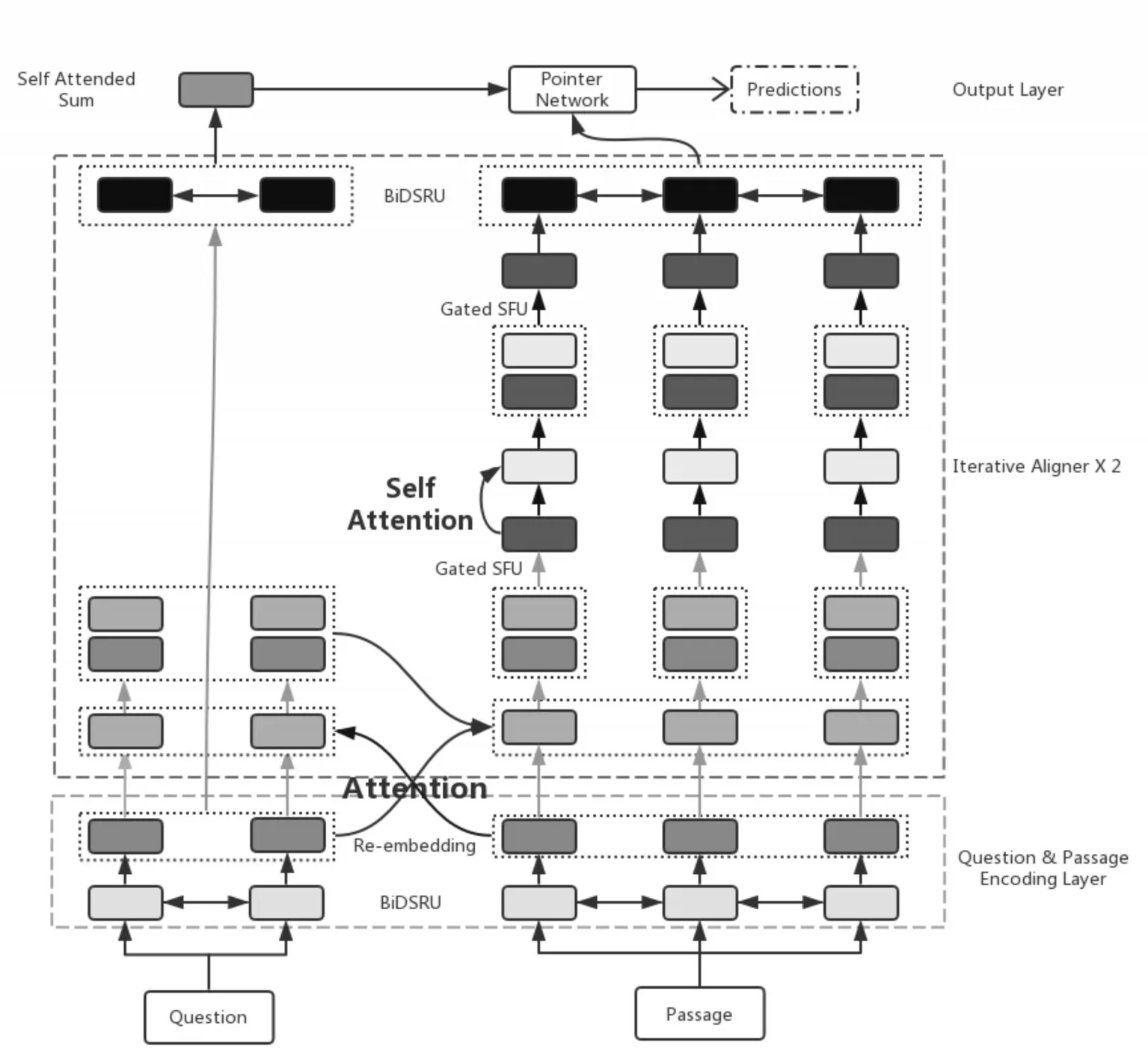
图1 模型的整体架构
这项工作的主要贡献有三方面。首先,我们提出了一个新的神经网DSRU。慢速堆叠式的RNN被快速的DSRU 取代。其次,我们提出一种新的指细粒度指针网络。最后,我们的单一模型在SQuAD1.1 dev set 上获得了77.9%的精确匹配精度和85.1%的F1分,与先进的结果相当。
2 模型结构

2.1 DSRU
我们设计DSRU 是为了取代传统的慢速叠加的RNNs,并获得比SRU 更好的性能。在SRU 的基础上叠加另一个SRU,其中第二层的输入是第一层输入和输出的组合。DSRU可以表述如下:


2.2 MRC的结构
1)问题和文章编码层


2)迭代对齐器
由于细粒度注意力机制的计算成本(时间、空间复杂度)比一般的注意力机制高,所以在迭代对准器部分,FGAN 使用多头的注意力机制而未采纳细粒度注意力机制。
(1)对齐文章的问题层

在上下文向量中应用门控机制的动机是在文章中可能存在若干个相同的词语与问题中的某个词具有相似的语义,但只有部分词与回答问题相关。我们希望门控机制可以掩盖不相关的文章内容并强调重要内容。
(2)对齐问题的文章层
类似于RNet[7],FGAN 通过共同关注机制在文章中搜索与问题相关的线索,该机制首先计算文章uˉP与问题uˉQ之间的相似性,然后基于相似性为文章生成问题表示u͂Q的上下文信息cˉP。为了将问题的上下文信息融合到文章中,文章提出了一个名为gated_SFU 的双重门控语义融合单元,其吸收了以下两类门控机制的思想:①R-Net 模型中的附加门控机制,②本模型中对齐文章的问题层中的门控机制。得到问题的上下文向量u͂Q。

基于初始状态向量h0和文章表示üP,FGAN预测出答案在文章中的开始位置p1,其根据如下公式可获得:

式中:ṡt为一个大小为D 维度的、表征问题的固定长度特征注意文章第t 个词的得分向量;s̈t为ṡt的张量得分;ȧt为文章中第t 个词为答案起始位置的概率。
然后,FGAN 应用两种不同考量的归一化机制对细粒度分数ṡt进行归一化,通过加权求和计算出上下文向量c1,如下所示:

通过使用隐藏状态h1,以类似于计算起始答案位置p1的方式来计算答案结束位置p2,其如下所示:

3 实验结果及分析
3.1 评价指标
本文主要通过SQuAD1.1 数据集进行试验评估。斯坦福大学官方给定了两个度量准则用以评估模型的性能:精确匹配(Exact Match,EM)得分测量模型预测的结果精确匹配其中一个真实答案的比率;F1 得分,其在字符层面上度量预测答案和真实答案之间的匹配度。F1 得分是预测答案和真实答案之间精确率(precision)和召回率(recall)的调和平均值,即:
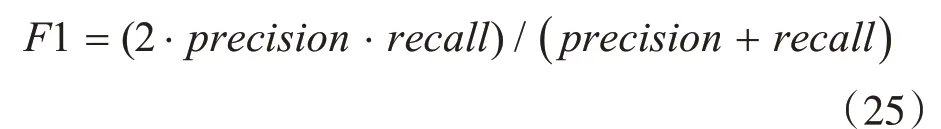
3.2 实验结果及有效性分析
表1 反映了本文提出的模型和其他竞争方法在SQuAD1.1 的评估结果。本文提出的模型FGAN在开发数据集上获得了77.9%的EM 得分和85.1%的F1得分。
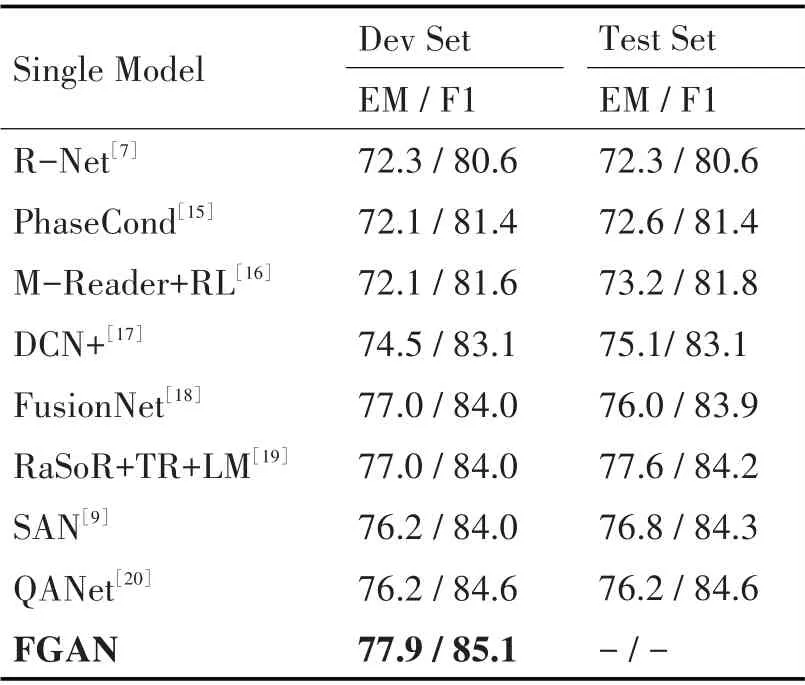
表1 FGAN模型及其他模型在SQuAD1.1数据集上的性能表现
本文评估了分别基于DSRU和stacked-RNN的FGAN 模型的速度。如表2 所示,在该实验中,以2层GRU 为基础的FGAN 模型,其每次训练100 个批次数据的时长为3.86min~4.34min,每秒处理6 个样本;而以DSRU 为基础的FGAN 模型其对应时长为1.95min~2.15min,每秒处理13 个样本。该结果反映DSRU的速度是两层GRU速度的两倍。此外,本文没有使用CUDA 优化过的SRU 对FGAN 进行加速。

表2 基于DSRU和stacked GRU的FGAN模型在SQuAD1.1上的速度比较
为了评估FGAN 模型每个组成部分的个体贡献,本文在SQuAD 开发集进行了减量研究,如表3所示。减少ELMo 特征导致模型性能下降4%,这表明具有语境信息的语言表示对阅读理解模型的重要性。本文分别用两层的GRU(stacked_GRU)和两层SRU(stacked_SRU)替换DSRU,模型性能分别下降3.2%和3.6%;该结果表明本文提出DSRU的结构比直接堆叠两层的GRU 或SRU 效果好。最后,本文用一般的注意力机制替换本文修改后的细粒度注意力机制,模型的性能下降了接近1%,其有力地揭示了细粒度注意力机制的性能优于一般的粗粒度注意力机制。

表3 FGAN在SQuAD1.1开发集上的减量结果(Ablation results)
SQuAD2.0 的评估准则与SQuAD1.1 一致,即根据EM 得分及F1 得分对模型的性能给予评估。实验结果:基于SQuAD2.0 开发集,FGAN+模型的实验结果如表4 所示;FGAN+在SQuAD2.0 开发集上的得分优于该任务的两个基准得分,但略低于最佳基准得分。

表4 本文提出的FGAN+和三个基准模型在SQuAD2.0开发集上的性能表现
4 结语
本文提出了面向机器阅读理解的快速有效的细粒度注意力模型FGAN。 FGAN 引入了更快的双向DSRU 而不是传统的堆叠式的双向RNN 来编码问题和文章;然后其通过多头的共同注意和自我注意力机制以及门控语义融合单元组成的迭代对齐器去获得注意问题的文章表示;最后其通过一个细粒度的指针网络来预测答案边界。在SQuAD1.1上的实验表明,本文提出的快速模型可以获得有竞争力的结果,优于许多出色的系统。在未来的工作中,我们将尝试设计新的推理方法来处理一个问题和包含答案的句子之间的句法分歧,并将语法和常识运用到我们的系统中。
