基于深度卷积神经网络的语音信号去噪关键技术研究*
2022-03-17李祎男王连祺
杨 帆 李祎男 乔 涵 王连祺
(1.31008部队 北京 100080)(2.32085部队 北京 100080)(3.陆军勤务学院 重庆 401331)
1 引言
周围环境的声音干扰是人们在进行语音通信的过程中无法完全避免的,由于这些外界干扰声的存在,就使得原本的语音信号变得不纯净,最终使得接收者接收到的并不是发送者发出的最原始语音信号,这些干扰都会或多或少会对所需传输的语音信号有所影响,也就是所谓的噪音。
目前语音识别处理系统的发展非常迅速,但噪音的干扰却使得识别的精度极大的降低。在没有噪音的理想环境中,语音识别系统已经可以达到百分之百的识别率,但处于现实环境中,识别率便会直线下降。正是由于这些原因,语音信号去噪已经成为了目前信号处理领域中的一个热门话题,而使用人工神经网络是非常方便且有效的方法。随着对人工智能的研究不断深入,语音识别技术[1]一直在不断创新突破,语音技术在最近三四十年发展迅速,语音信号处理已经对人们的工作生活产生了重要影响,可见语音对现在的社会非常重要[2],为了提高语音信号分析的效果,人们以傅里叶变换作为基础提出了大量的分析方法,比如Gabor 变换、短时傅立叶变换、小波变换及时频分析等[3]。1975年,B.Windrow等研究出了智能相互消减去噪算法,随后该算法得到进一步的发展[4];1978 年,Lim 和Oppenheim 针对语音信号利用维纳滤波法来实现去噪效果,通过该方法提高了去噪性能[5];1979年,Boll S F 利用去除噪声频谱来获得原始语音信号的方法来进行语音去噪[6];1980 年,Maulay 和Malpass研究出软判决法来对噪声进行去除,有效分离原始语音和噪声[7];1984 年,Ephraim 与Malah 研究出了基于MMSE的短时谱去噪法,该研究将短时谱去噪技术在信号去噪领域中得到一定的发展[8];1987年,Paliwal研究出了卡尔曼滤波法来进行语音去噪研究,该方法是基于测量方差已知的条件下对带噪语音进行最优估计[9];1995年,Ephraim 研究出了信号子空间法来进行语音去噪,该方法是基于线性代数理论的知识,其原理是将纯净语音和噪声分解到不同的两个空间[10];2004年,Hu Yi和Loizou研究出了通过小波变换阈值函数的方法对语音信号进行去噪,该方法具有多分辨率的特点[11]。2011 年,张君昌等提出了一种基于清浊音分离的动态阈值小波去噪方法[12]。2012 年,谢巍盛等针对语音增强技术中的信号去噪问题,提出了一种非线性小波自适应阈值去噪方法[13]。2013 年,陈晓娟等针对语音信号去噪问题,提出小波熵自适应阈值去噪法[14]。2014 年,李洋等提出一种基于经验模态分解(EMD)的小波阈值去噪方法[15]。2015 年,靳立燕等提出了一种奇异谱分析(SSA)和维纳滤波(WF)相结合的语音去噪算法SSA-WF[16]。2016年,张雪等提出一种基于集合经验模态分解(EEMD)的联合能量熵与小波阈值的自适应去噪方法[17]。2017年,唐鹏等研究出一种改进的带调整参数小波阈值函数,并采用粒子群优化算法寻找改进阈值函数在某一背景噪声环境中的最优参数值,通过重构处理后得到最优小波系数的语音信号,将改进的小波阈值函数与贝叶斯阈值方法相结合[18]。2018 年,陆振宇等提出一种基于变分模态分解和小波分析去噪的方法[19]。2019 年,陈召全提出了一种基于模糊控制的小波包多阈值语音减噪新算法[20]。
近十几年来,研究人员在传统软硬阈值小波阈值去噪的基础上,提出了许多新的去噪方法,主要是对小波阈值函数、阈值进行改进。
2 数据预处理
2.1 检查数据集
本实验使用的语音数据集是来自Mozilla 公共语音数据集网站上下载的汉语数据集。该数据集包含大量48kHz 录音的主题说短句。使用audio Data store 为cv-valid-train 程序文件夹中的文件创建数据存储。使用shuffle 可随机化数据存储中文件的顺序。由于语音通常低于4kHz,因此首先将干净和嘈杂的音频信号向下采样到8kHz,以减少网络的计算负载。预测器和目标网络信号分别是噪声和干净音频信号的大小谱。网络的输出是去噪信号的幅度谱。回归网络使用预测输入最大限度地减少其输出和输入目标之间的均方误差。去噪音频使用输出幅度谱和噪声信号的相位转换回时域。
短时傅里叶变换(Short-Time Fourier Transform,STFT)是研究非平稳信号使用最为广泛的重要方法。因为语音信号通常是非平稳信号,所以使用短时傅立叶变换(STFT)将音频转换为频域,窗口长度为256 个样本,重叠为75%,并具有Hamming窗口。通过丢弃与负频率相对应的频率样本,可以将光谱矢量的大小减小到129。预测输入由8个连续的噪声STFT 向量组成,因此每个STFT 输出估计都是根据当前噪声STFT 和前7 个噪声STFT向量计算的。
2.2 使用STFT获得目标和预测
从一个训练文件生成目标和预测信号。首先,定义系统参数:

定义用于将48kHz 音频转换为8kHz 的采样率转换器。使用read 从数据存储获取音频文件的内容。确保音频长度是采样率转换器抽取系数的倍数。将音频信号转换为8kHz。从洗衣机噪声矢量创建随机噪声段。向语音信号添加噪声,使信噪比为0dB。使用stft 从原始和嘈杂的音频信号生成大小stft 矢量。从嘈杂的STFT 生成8 段训练预测信号。连续预测值之间的重叠为7 段。设置目标和预测值。这两个变量的最后一个维度对应于音频文件生成的不同预测目标对的数量。每个预测值是129×8,每个目标是129×1。
3 网格训练
3.1 去噪模型
如图1 去噪模型流程图所示,去除噪音的大概流程是分别把干净的声音和加噪处理过的声音进行短时傅里叶变换,分别作为目标和预测输入到深度学习网络,再把得到的结果进行逆短时傅里叶变化得到去噪语音模型。

图1 去噪模型流程图
3.2 使用全连接网络进行语音去噪
首先,可以考虑由全连接的图层组成的去噪网络。将输入大小指定为大小为为129×8。定义两个隐藏的完全连接的层,使用ReLU 函数作为激活函数,神经网络中的激活函数的作用是激活神经元的特征然后保留并映射出来,这是神经网络能模拟人脑机制,解决非线性问题的关键,ReLU函数更是其中的佼佼者[21]。ReLU(Rectified Linear Unit,Re-LU)线性整流函数是一个人工神经网络常用的分段函数,如果输入值为正时就保持原来的值不改变,反之则输出的结果为0。它的定义式:f(x)=max(0,x)。该方法会将某些数据直接修改为0,但同时增强了训练后网络的稀疏性,这更加符合神经元信号激励原理,不仅削弱了参数之间的耦合关系,而且大大降低了发生过拟合问题的概率。
添加一个完全连接的层与129 个神经元,其次是一个回归层。接下来,指定网络的培训选项。将Max Epochs 为3,以便网络通过训练数据进行3 次传递。将Mini Batch Size 为128,以便网络一次查看128 个训练信号。将Plots 为“training-progress”,以生成随着迭代次数的增加而显示训练进度的绘图。Verbose false,以禁用将与绘图中显示的数据相对应的表输出打印到命令行窗口中。将Shuffle为“every-epoch”,以便在每个时代开始时洗牌训练序列。指定Learn Rate Schedule 在每次通过“piecewise”一定数量的时间点(1)时将学习速率降低指定因子(0.9)。Validation Data 为验证预测值和目标。设置Validation Frequency 以便每个世纪计算一次验证均方误差。本次实验使用自适应矩估计(Adam)求解器。Adam 算法通过将Momentum 算法和RMSProp算法相结合使用产生的一种新的算法,来为每一个不同参数设计它们独立的自适应性学习率。该方法使用偏置校正每一次迭代学习率,可以使得参数趋向于平稳。
3.3 使用卷积层进行语音去噪
二维卷积层将滑动滤波器应用于输入。该图层通过沿输入垂直和水平移动筛选器,计算权重和输入的点乘积,然后添加偏置项。定义中描述的完全卷积网络的层,包括16 个卷积层。前15 个卷积层是由3 层组成的组,重复5 次,滤码宽度分别为9、5 和9,过滤器的数量分别为18、30 和8。最后一个卷积层的过滤宽度为129和1筛选器。在此网络中,卷积仅在一个方向(沿频率维度)执行,除第一个图层外,所有图层的沿时间维度的滤波器宽度都设置为1。与完全连接的网络类似,卷积层之后是ReLU和批处理归一化层。训练选项与完全连接网络的选项相同,只是验证目标信号的维度被修改为与回归层预期的维度一致。使用trainNetwork 网络对网络进行指定的培训选项和层体系结构培训。
图2 表示全连接网络训练误差的降低,虽然误差已经很低,但仍然存在,不能完全消除。图3 为卷积网络训练误差的降低。
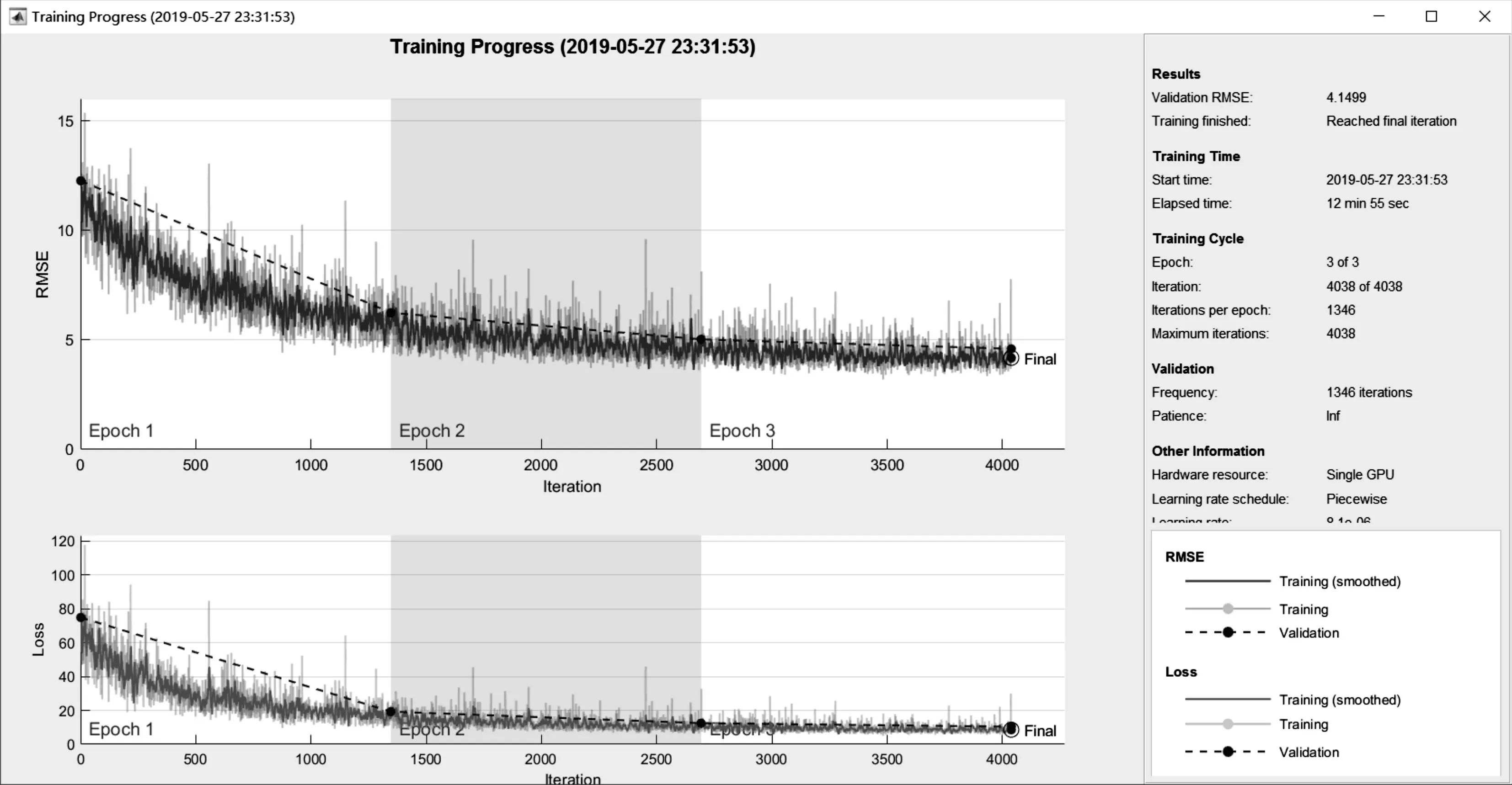
图3 卷积网络训练误差降低图
4 测试去噪网络
4.1 通过全连接和卷积对语音信号进行处理
使用“cvv-vex-vitest”文件夹中的语音信号来测试训练后的网络的性能。使用audioDatastore 为“cv-有效性测试”文件夹中的文件创建数据存储。洗牌数据存储区中的文件。从数据存储中读取文件内容。将音频信号转换为8kHz。在这个测试阶段,用洗衣机噪音腐蚀语音,而不是在训练阶段使用。从洗衣机噪声矢量创建随机噪声段。向语音信号添加噪声,使信噪比为0dB。使用STFT 从嘈杂的音频信号生成向量。从嘈杂的STFT 生成8 段训练预测信号。连续预测值之间的重叠为7 段。通过在训练阶段计算的平均值和标准偏差来归一化预测值,利用predict训练网络的预测来计算去噪幅度STFT。按训练阶段使用的平均值和标准偏差缩放输出,计算去噪语音信号,执行逆STFT。利用噪声STFT向量的相位重建时域信号。
4.2 实验结果
试听得到的经过去噪处理的音频,发现不论是经过全连接网络还是卷积神经网络处理后的音频,都有着明显的去噪效果,但距离最初的干净的音频,还是会有一定的噪音存在。
从图4 中可以看出不论是使用全连接还是卷积方法对语音信号进行去噪,效果都是很明显的,但两者之前还是有一定区别,全连接对语音高振幅进行了大量的削弱,而卷积网络则进行了大量的保留,各有优缺。

图4 音频幅度对比图
通过图5 中可以明显地看出卷积网络对声音频率更加还原。这是因为使用的短时傅里叶方法是通过频率来进行语音去噪,所以从频域上看,卷积网络的去噪效果更加明显。
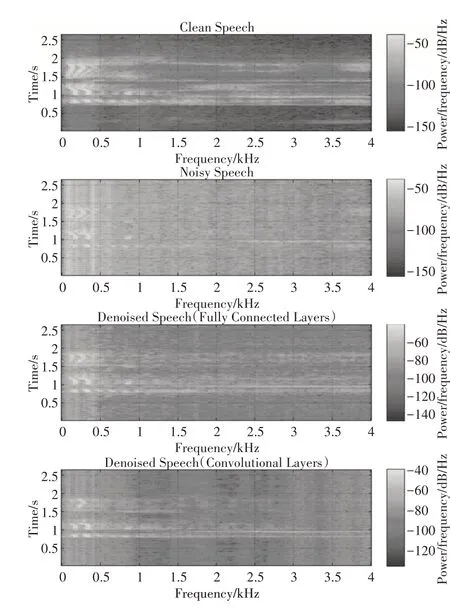
图5 光谱对比图
5 结语
通过应用全连接网络和卷积神经网络对带有洗衣机噪音的语音信号处理,得出结论为不论是全连接网络方法还是卷积网络方法,对语音信号中噪音的去除效果都是十分明显的,全连接对语音高振幅进行了大量的削弱,而卷积网络对声音频率更加还原,去噪效果更加明显。
