一种基于深度学习的头部姿态估计模型*
2022-03-17刘亚飞王敬东林思玉
刘亚飞 王敬东 刘 法 林思玉
(南京航空航天大学自动化学院 南京 211106)
1 引言
头部姿态作为进行人体行为分析的重要手段,在社区安防、智能家居以及室内行为监控等领域得到广泛应用。头部姿态估计是指计算机通过对输入图像或者视频序列进行分析、预测,确定人的头部在三维空间中的位置以及姿态参量[1]。如图1所示,头部的姿态包括俯仰角(pitch),偏航角(yaw)和翻滚角(roll),其中,俯仰角作为头部姿态中的关键信息之一,在教室学生注意力分析、判断驾驶员疲劳状态等方面有诸多应用,因此,本文主要针对俯仰角进行展开研究。
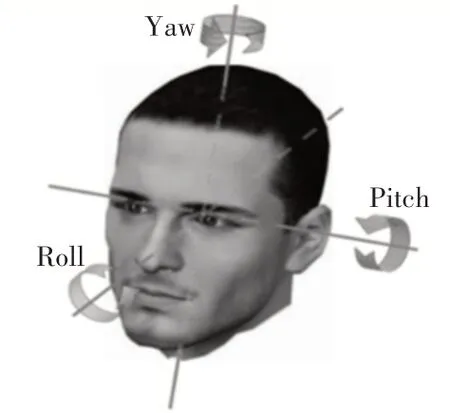
图1 头部姿态三个旋转角度
目前,头部姿态估计的方法有多种,主要可分为基于模型的方法和基于表观的方法,基于模型的方法[2~4]是先获取脸部的多个关键点,通过PnP 算法[5]实现2D 到3D 的转化,构建头部模型与姿态之间的空间立体的对应关系。但该方法在头部转动角度大时,难以对脸部关键点进行准确定位,造成头部图像与3D 头部模型之间的匹配度降低。另一种基于表观的方法[6~8]则是直接对头部图像进行分析,通过学习不同头部姿态对应的角度信息,可以不受角度限制,因此受到广泛关注。基于此方法,Patacchiola 与Cangelosi 等[6]测试了dropout 和基于自适应梯度的方法与CNN 相结合进行头部姿势估计的效果,提出将自适应梯度与CNN 结合使用。Nataniel 等[7]利用ResNet50 进行特征提取,并对俯仰、偏航和翻滚三个角度分别采取分类与回归双重损失,增强对误差的约束。Shao 等[8]在此基础上,研究了不同人脸边界框对头部姿态估计的影响,并将文献[7]中对三个角度先分类后预测改为了回归与分类结果同时输出,以减小分类与回归之间的换算误差。
但是头部姿态估计网络需要提取和保留比较多的空间结构信息,如由于头部转动所形成的与原竖直头部之间的俯仰角。上述基于表观的方法均是通过使用深层次网络以提取更多、更丰富的语义信息,而增加网络深度就意味着需要增加相应的MaxPooling 池化层以降低参数量,加快网络训练速度,但由于MaxPooling 是取一定尺寸范围内的最大值,即最显著特征,而忽略最显著特征所处图像的位置与角度,使得特征丢失了原本图像中所存在的空间结构信息。因此,构建的网络模型一方面应当尽量避免MaxPooling 池化的使用,另一方面也应当对头部的角度信息能够进行有效地提取,使头部的姿态信息传递至最终的输出。
为此,本文利用胶囊网络充分保留空间结构信息的优点,并结合传统的卷积神经网络进行特征提取,提出将胶囊网络(Capsule Networks,CapsNet)[9]与传统卷积神经网络(Convolutional Neural Network,CNN)相结合,利用设计的三级网络输出特征后,将特征编码为胶囊形式传入胶囊网络进行传递至输出,使整个网络既能对语义特征进行充分的提取,又能利用CapsNet特性,保留图像中存在的姿态关系,实现对头部姿态的准确估计。本文模型具有以下三个优点:1)采用单输入异构双流的特征提取结构,使不同的卷积流提取更为丰富的信息;2)采用三级输出策略,使得每级输出能够提取到不同的空间结构特征和语义特征;3)将CapsNet引入其中,并在三级输出的特征转成胶囊向量后,以动态路由确定最终输出,从而能够使空间结构特征得以保留。
2 胶囊网络
2.1 胶囊
如图2 所示,相比于传统的单个神经元,胶囊由多个神经元构成,因此在卷积层上,普通的单层卷积是二维,而单层的胶囊则是三维。胶囊中的每个神经元表示一种属性,如大小、方向、色调、纹理等特征,故相对而言,胶囊可以记录更详细的信息。当图像中头部发生角度变化时,胶囊中神经元也会产生相应的变化,接着使用动态路由算法对胶囊进行筛选传递,进而影响最终的输出。而传统的CNN 由于MaxPooling 的存在,只会保存显著特征,丢弃非显著特征,造成空间结构信息丢失。为了更形象地将二者相区分,常用标量表示普通神经元,向量表示胶囊,向量的长度表示识别目标存在的概率,方向表示目标的各种属性。

图2 普通神经元与胶囊对比图
2.2 动态路由算法
首先利用卷积神经网络进行特征提取,并将其转换为胶囊形式,经过姿态矩阵得到初始预测胶囊,即子胶囊。姿态矩阵用于子胶囊对父胶囊的预测,不同的姿态矩阵代表子胶囊的不同预测方向,所有子胶囊对父胶囊的预测,实际是聚类的过程,如图3 所示,子胶囊Caps1、Caps2、Caps3 以及Caps4等均对多个父胶囊进行预测,当多数子胶囊输出一致时,会对不同的父胶囊形成簇,作为对父胶囊的预测,从而激活对应父胶囊。而对于如何使簇更紧密,以形成对父胶囊的准确预测,则由动态路由算法确定。

图3 子胶囊向父胶囊聚类示意图
根据动态路由算法,子胶囊与父胶囊之间是类似全连接的形式,所有子胶囊都会与父胶囊相连,并尝试预测父胶囊的输出,但是它们的权重并不相同,若子胶囊的预测与父胶囊的输出一致,则这两个胶囊之间的权重会增加,这样就可以将对父胶囊贡献大的子胶囊的权重变大,贡献小的权重变小,造成预测相同的子胶囊逐渐接近,差别很大的逐渐远离,经过迭代三次,最终根据权重大小,确定每个子胶囊对父胶囊的贡献程度,进行加权求和,得到综合的输出。相比于MaxPooling 简单地选择最大值,更有利于保存最符合预期的信息。
3 基于CapsNet 与卷积神经网络结合的头部姿态估计模型
由于原来的CapsNet仅含有一个卷积层用于提取特征,其对于语义信息的提取是不够的,为了既能进行充分信息提取,又能将其中的空间信息保留[10~11],本文借鉴了SSR 网络[12]的多级输出思想,提出了一种新的头部姿态估计网络模型。如图4所示,该模型利用深度卷积结构用于提取特征,采用异构双流的方式,并将网络分为三级,分别在一层、三层和七层卷积输出,每级输出均通过同维度胶囊对实体的语义信息以及空间结构特征进行编码,然后将三个CapsNet 通过三个不同的姿态矩阵得到胶囊网络的全连接层,并通过动态路由的方式将上一级胶囊对输出胶囊进行聚类,最终得到类别输出。在整个特征提取网络中,一层卷积对输入图像的特征提取较浅,基本保留了空间结构信息;而第三层卷积既保留了一部分空间信息,也对语义特征进行了一定的提取;第七层则是通过不断的卷积池化,将语义信息进行了充分的提取。这样,既能得到丰富的空间结构信息,也能对语义信息进行充分提取,而通过CapsNet 模块对特征信息进行编码并传递至输出,从而既实现丰富的信息提取,又能够将特征充分传输不丢失。这种深度和多级的协调融合有利于空间特征和语义特征的提取和保留,使网络对头部姿态有更好的检测和识别效果。
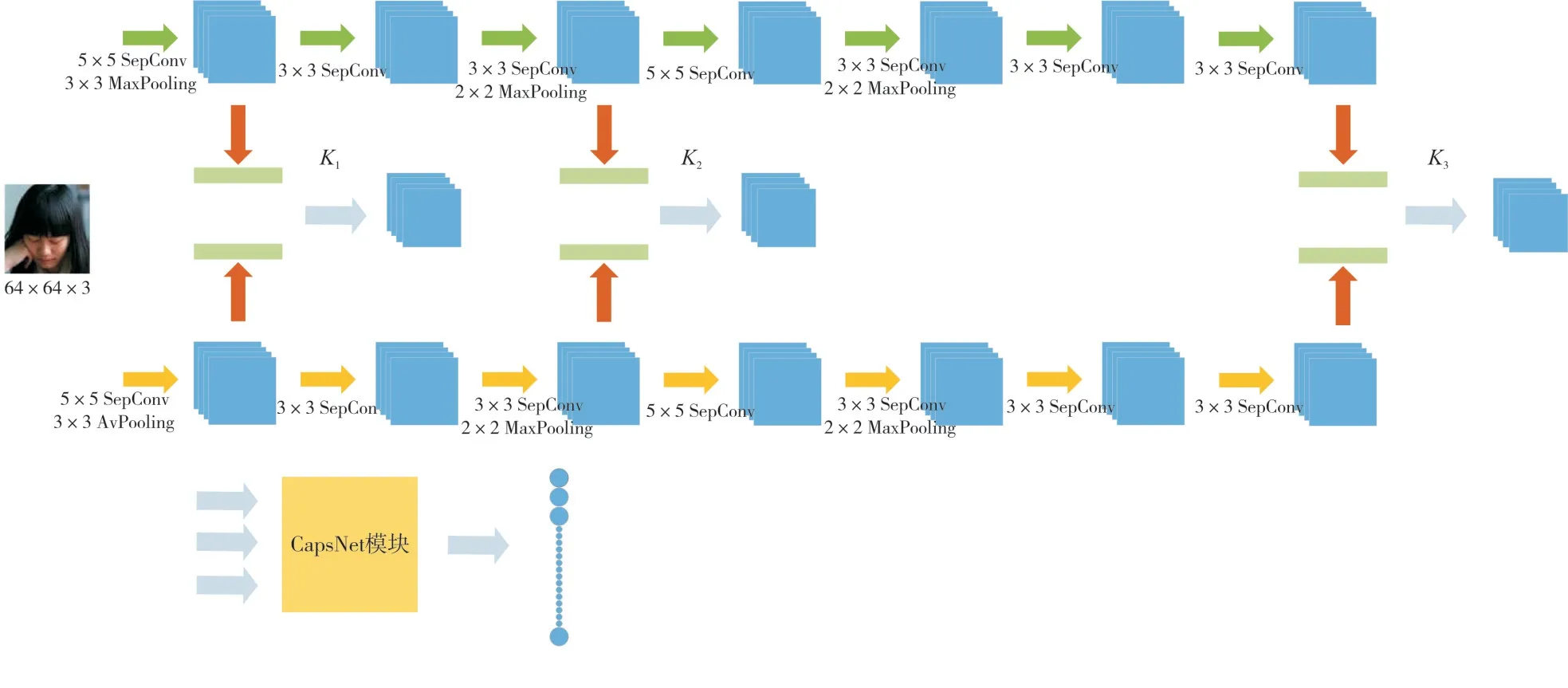
图4 用于头部姿态估计的CNN与CapsNet相结合的网络结构示意图
如图4所示,将尺寸大小为64×64 的头部图片分别送入上下两个输入进行深度可分离卷积,每个输入在K1、K2、K3三个阶段均进行特征提取,并通过1×1 卷积和element-wise 的方式进行点乘融合,其中,为提高网络收敛的速度和防止过拟合,将处理后的卷积层进行批归一化(Bacth Normalization)处理。本文网络的基本构建块由3×3 卷积、批归一化、非线性激活以及2×2 池化组成,每个输入采用不同类型的激活函数和池化以使它们异构,上输入采用ReLU 与AveragePooling,下输入采用Tanh 和MaxPooling,这样可以通过不同的激活函数和池化对图像信息进行提取,通过相互融合以提高性能,最后将融合后的特征送入CapsNet进行信息编码。本文所设计的CapsNet模块的结构如图5所示。
本文对于图4 中CapsNet 模块的设计如图5 所示,三级输出进入CapsNet模块后,首先通过一层卷积使其变为胶囊形式,继而利用姿态矩阵将其转化为类胶囊的形式的初始预测胶囊,通过dropout 的方法舍弃一部分后,通过动态路由算法将其转为最终预测胶囊。具体设计为CapsNet模块的输入是三个N×M×D的卷积层,输出为大小为1×Q的O个胶囊向量,中间过程如下:在三级输出后,通过在原有卷积层的基础上再进行C次相同卷积操作,使得原有卷积层从三维扩展至四维,形成了含有N×M×D个胶囊,每个胶囊含有C个神经元的初始胶囊层,其中每个神经元代表着不同的含义,诸如方向、大小、纹理等信息,由于输出胶囊层中所含胶囊的个数对应着输出类别O,因此该层中共含有O个胶囊,且每个胶囊是1×Q的向量。初始胶囊层需要经过三个N×M×D个C×Q的姿态矩阵(即图6 中的W1、W2以及W3),从而得到初始预测Û,然后Û经过动态路由算法最终得到O×1 个长度为Q的胶囊。其中,姿态矩阵与常规的变换矩阵一样,在初始化之后通过反向传播训练得到,而动态路由算法中各胶囊的权重则是在不断的迭代更新中确定的。

图5 CapsNet模块结构示意图
由于dropout 可以使某些胶囊暂时不起作用,防止了网络过度依赖某些特征,提高网络泛化能力,使网络能够通过子胶囊的共性对头部的俯仰角度进行正确预测,本文采用文献[13]中的dropout方法,将每个输出的胶囊作为整体对待,以保证每个胶囊的方向不变,通过伯努利分布对胶囊进行随机丢弃,即保持子胶囊与父胶囊之间的姿态矩阵参数不变,将子胶囊中各神经元的输出置为0,从而使整个胶囊在网络训练中不起作用,避免因为丢弃胶囊中部分元素导致胶囊的方向发生变化。
本文所采用的损失函数是Marginloss,该函数常用于多类别损失的计算。在输出父胶囊后,计算各向量的L2 范数,能够得到对应于pitch 角度的60种不同类别的预测值与损失值,具体如式(1)所示:

4 实验结果和分析
4.1 实验准备
为了验证本文提出的网络模型的有效性,并便于与其他经典模型进行对比,本文选取在头部姿态估计领域具有代表性且常用的300W-LP 数据集、AFLW2000数据集以及BIWI数据集。300W-LP 数据集是一个大型人脸姿态数据集,共有122450 张图片,这些图片通过三维密集面对齐(3D Dense Face Alignment,3DDFA)[14]合成出不同的偏航角。各图片间差异较大,背景环境复杂,人物之间差异性较大,具有不同年龄段、不同光照、不同表情以及不同的遮挡程度,最大程度体现了真实环境下的头部各个姿态。另外,该数据集中还对原有的数据进行了水平翻转,在增加了不同角度的同时,也对数据集进行了扩充。本文使用数据集进行训练,300W-LP数据集的部分图片如图6 所示。

图6 300W-LP数据集部分实验用图
AFLW2000数据集是由2000张头部图片组成,该数据集包含有不同光照和遮挡条件的头部姿势,是头部姿态估计中常用的用于测试的数据集。由于头部的俯仰角基本位于[-90°,90°]之间,因此本文删除了AFLW2000中存在角度不在[-90°,90°]之间的图片,并归一化为64×64 大小进行测试。

图7 AFLW2000数据集部分图片

图8 BIWI数据集部分图片
BIWI 数据集包含有24 个人拍摄的约15000 张图片,每个人都有较为丰富的头部姿态,并提供了每张图片的深度图像以及姿态信息。由于该数据集未提供头部检测框信息,故本文使用MTCNN(Multi-Task Convolutional Neural Network)进行头部检测和截取,针对部分图片中多人存在的情况,采用分离区域检测手段进行处理。
根据文献[8]经实验证明,边界框边缘参数K取0.5时,改善了俯仰角,偏航角和翻滚角在各个角度值上精度,因此,为保证一致性,本文所有的数据集均采用边界框边缘参数K=0.5 进行头部区域裁剪。
本文使用Python 语言,基于Keras 和Tensorflow框架进行算法实现,其硬件环境为Intel i7-7200H@2.7Hz×8 CPU和GTX1080Ti GPU,卷积神经网络的训练参数设置为训练的迭代次数为numEpochs=90,采用AdamOptimer优化器,每批次大小batch size为16,初始的学习率为0.001,每30步缩小0.1倍。
4.2 实验结果
为了能够更好地体现CapsNet与卷积神经网络结合的头部姿态估计模型的优势,将该模型与FAN[15],Dlib[16],HopeNet 分别在在AFLW2000 数据集以及BIWI 数据集上进行测试,并采用平均绝对误差(Mean Absolute Error,MAE)作为评价指标。
本文采用上述不同的方法对BIWI数据集的数据进行预测,并通过类别×3-90°的转换公式将类别转为对应的角度值,根据MAE 计算公式得到测试数据如表1所示。
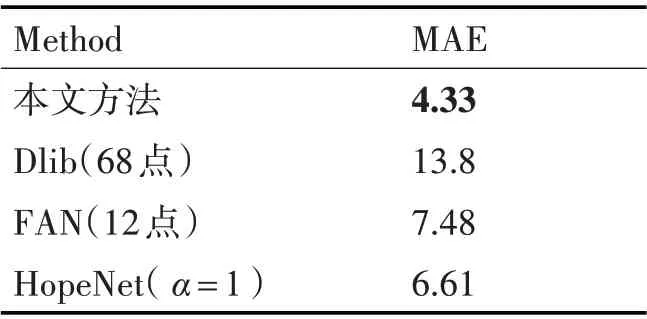
表1 BIWI数据集在俯仰角上的MAE对比
由表1 可以看出,本文在俯仰角上所得出的MAE 具有最优值,且BIWI 数据集在角度姿态展现出多样性,更能体现本文方法的表现优异。
另外,在AFLW2000 数据集上的测试结果如表2所示。

表2 AFLW2000数据集在俯仰角上的MAE对比
实验结果表明,本文方法以及HopeNet 在俯仰角上与经典的Dlib 与FAN 算法相比,具有明显的优势,也证明了基于表观的方法相比于基于模板的方法能够克服头部姿态变化的差异,更加准确地估计;并且本文方法相较于目前较为先进的HopeNet也有了很大程度的提高,在MAE 上取得了最佳的测试值。表2 的测试结果整体优于表1,是由于BIWI 数据集是在单一背景下拍摄的,而AFLW2000数据集背景构成较为复杂,从而影响了最终的估计精度,可见复杂背景对头部姿态的估计精度影响较大。
为了验证模型在实际应用中的有效性,本文拍摄了生活中的常见情形,分别为正常光照、昏暗光照、戴帽子以及复杂背景。数据采集自6 个人,每人在4种环境下分别做15种头部姿势,俯仰角取值为{-30°,0°,30°},偏航角取值为{-45°,-30°,0°,30°,45°},部分测试图片如图9所示。

图9 不同条件下的部分测试图
考虑到在实际操作过程中,由于人为标注以及实验人员本身造成的误差,故进行了本文模型与HopeNet的对比实验,实验结果如表3所示。
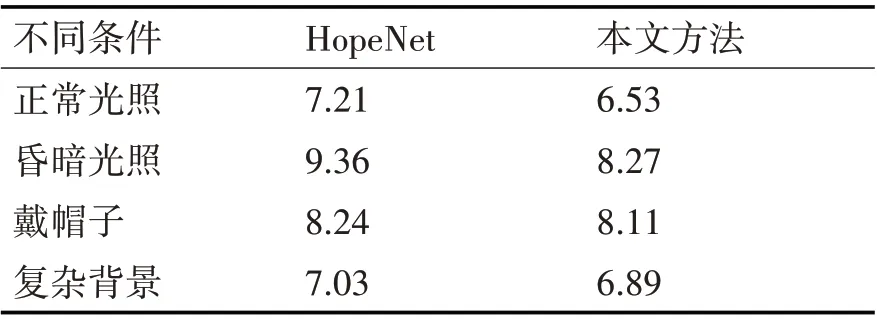
表3 不同条件下在俯仰角上的MAE对比
由表3 可以看出,本文方法在各个不同的场景中,都具有优异地表现,并且MAE 值均较小,鲁棒性较强,没有出现大幅度的起伏变化,在四组实验中,昏暗光照下的表现最差,原因是实验本身光照强度较低,且出现黑影,对头部俯仰角的预测产生较大的影响。另外,由于测试的头部区域均按照脸部边界框边缘参数K=0.5,因此背景所占比例较大,对最终的头部姿态估计造成了一定的干扰。
5 结语
本文通过传统卷积神经网络提取图像特征,并将特征信息传入CapsNet 进行空间信息保留与传递,从而构建了一种新的头部姿态估计模型,解决了传统卷积神经网络存在的MaxPooling 池化所造成的空间结构信息丢失的缺点。通过本文算法与FAN,Dlib 和HopeNet 分别在AFLW2000 数据集和BIWI 数据集上进行的俯仰角实验对比结果表明,相比于其他算法,本文模型在俯仰角的估计上具备更加优异的表现。
