基于LSTM的关键词识别系统设计
2022-03-17何蕊伽夏秀渝
何蕊伽 夏秀渝
摘要:为快速、准确地判断语音流中是否含有关键词,提出一种基于LSTM两步检索的关键词识别系统。将连续语音流分割成独立音节,然后采用过零率直方图进行初步检索,基于过零率直方图的相似度比较的计算量小,可快速排除非关键词。对初检时判断为关键词的音频片段进行精检,使用基于LSTM的分级系统进行音素识别,通过贪心搜索算法解码以确认是否为目标关键词。仿真结果表明,基于LSTM的网络能更有效提取音素特征,基于两步检索LSTM的关键词识别系统计算量小、速度快、识别率较高,且易于动态扩展目标关键词,具有较好的實时性。
关键词:关键词识别;语音分割;音素识别;循环神经网络;过零率直方图
中图分类号:TP391.4文献标志码:A文章编号:1008-1739(2022)02-64-6

0引言
随着信息化时代的到来,人机交互的需求越来越大,语音识别是人机交互的热点研究方向,关键词识别作为语音识别的重要领域,逐步应用于语音检索、人机交互、语音监听等领域[1]。关键词识别不同于语音识别,不需要将语音流准确无误地把整段语音逐词逐句地翻译出来,只需要检测出语音流是否含有特定关键词即可。
目前关键词识别方法主要分为3类:①基于模板匹配的关键词识别:直接将待检音频的特征与模板音频特征进行匹配计算和判断,不需要先验知识,总运算量少、识别速度快,但是识别率不高[2]。②基于HMM的关键词-垃圾模型的关键词识别:难点在于垃圾模型的建立,一旦变换应用场景,需要重新建模,实时性有待提高。且集外词数量巨大,导致模型训练以及匹配计算量大。③基于大词汇量连续语音识别的关键词识别:可以克服前2种方法的缺点,不需要构建垃圾模型,且识别率较高,但是需要大量的训练数据,在测试阶段对于非关键词部分也进行了识别,解码空间大,造成资源浪费。
传统关键词识别方法,难以同时在准确率、识别速度、实时性等方面均取得较好效果,针对传统方法的不足,本文提出基于音节过零率直方图和音素识别的两步检索关键词识别方法,该网络考虑了语音的时序性,有利于提高识别率。由于初检与精检均操作简单,利于动态扩展目标关键词,提出的关键词识别系统从识别速度、精度以及实时性上对关键词系统进行了优化。
1系统设计原理及方案
1.1系统总体框架
关键词识别系统总体框架如图1所示。
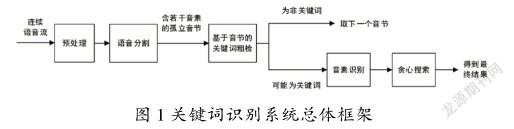
系统流程分为2个阶段:
①初检阶段:作为关键词识别的第一步,目标是从连续语音流中快速筛选出与目标关键词相似度高的音频片段。使用基于短时能量的语音分割法,将语音流大致分割为独立的音节片段,统计每个音节片段的过零率,得到其过零率直方图,然后计算目标关键词音节和待检音频片段之间直方图的相似度,当相似度大于给定的门限值时,则认为搜索到可能的目标关键词音节。
②精检阶段:初检的虚警率比较高,进行精检以完成最终的关键词确认。首先对初检判断为关键词音节片段的语音进行音素划分,使用LSTM网络进行音素识别,最后通过贪心搜索得到待测语音片段所包含的音素序列,当音素序列与目标关键词音素序列一致时,确认该语音片段为关键词音节。
1.2音节分割
音节是表音语系中元音音素和辅音音素组合发音的最小语音单位,单个元音音素也可自成音节。英语的单词有单音节、双音节以及多音节单词。音节分割的目的是将连续语音流分割为若干独立音节,语音流中单词若为单音节单词,则一个音节为一个单词,若为多音节单词,则一个单词切割为若干个音节。本文提出一种基于短时能量峰谷点的语音切割方法进行语音端点检测和音节分割。因为每个音节具有元音能量大,辅音以及音节间隙能量小的特点,[3]所以将信号的短时能量与阈值进行比较,把每个音节片段分割开。主要包括以下步骤:
①对音频信号进行预处理,包括提升信号高频成分和分帧,信号采样率为8 000 Hz,帧长取25 ms,帧移为10 ms。

④语音二次分割:语音语速较快时,无法有效分割一些紧邻的音节,需要进行二次分割。对音频短时能量波形进行平滑处理,若当前音频片段包含不止一个峰,相邻峰的幅值相差较大且相隔较远,找到2个局部最大值之间的局部最小值,以此为分割点再次分割。
通过以上步骤,可以切分出以元音为中心的单个音节。若目标关键词为单音节单词,针对切分出的每个音节片段进行关键词识别即可,若目标关键词为多音节单词,需要分别分析分割后相邻的音节与关键词各个音节的相似度。
基于短时能量的端点检测及音节分割算法,使用短时能量作为声学特征,与MFCC、小波系数等特征相比,不需要进行复杂的变换,仅需少量的乘加运算,计算复杂度低,有利于提高语音分割速度。
1.3基于音节过零率直方图的关键词初检
关键词初检的目标是快速排除与目标关键词相似度低的音节。不同音节特征参数的概率分布不同,可以利用各音节特征参数概率分布与目标关键词音节特征参数概率分布的相似性筛选出候选音节[5]。常用音频特征有:短时过零率、MFCC、LPC等,过零率计算简单、便于统计,能较好表现音频变化特征,本文采用短时过零率进行关键词音节初检索。具体步骤如下。


設定阈值,当相似度大于阈值,认为其可能是目标关键词的音节,送入精检网络进行识别。当相似度低于阈值,则判定为非关键词。
过零率与短时能量一样,不需要复杂的变换,甚至不需要相乘运算,只需要比较大小、相加相减等简单计算即可获得,直方图的统计计算类似,所以基于音节过零率直方图的关键词初检计算复杂度低。由于此阶段可以排除大量非关键词,减少了精检阶段的识别量,避免了对这些非关键词进行识别的复杂运算。
1.4基于音素识别的关键词精检
基于音节过零率直方图的初检仅采用了简单的过零率特征,且没考虑语音时序信息,虚警率较高。为降低虚警率,进行精检以完成最终关键词确认。关键词由音节构成,音节由音素构成。使用LSTM网络进行音素识别,分析每个待检音节的音素序列,比较其与目标关键词的音素序列是否一致,判断待检音频片段是否为关键词或关键词的音节。
1.4.1 LSTM循环神经网络
循环神经网络是一种内部为递归结构、具有记忆功能的一种神经网络。因为梯度爆炸或梯度消失问题,普通RNN无法长时间保留上下文信息。长短时记忆网络LSTM是在RNN基础上进行改进的一种可以有效记忆长期信息循环神经网络。长短时记忆网络结构如图2所示。
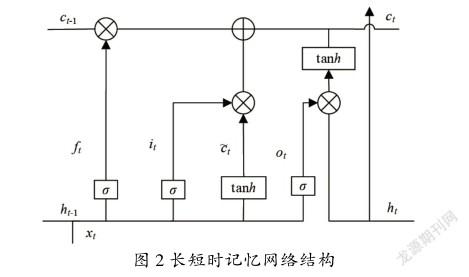
LSTM模型在循环神经网络的基础上,增加了一个细胞状态储存网络长期状态,用以实现对长距离信息的记忆。时刻的状态由3个部分决定,分别是:当前时刻网络输入值、上一时刻隐藏层输出值-1、上一时刻细胞状态-1。时刻有2个输出,分别是当前时刻的隐藏层输出值,当前时刻细胞状态,其中记忆短期特征,记忆长期特征。LSTM可以通过3个结构门来实现对3个输入部分接收信息的控制,分别是遗忘门、输入门和输出门。
遗忘门保留上一存储单元的记忆信息更新单元状态,计算公式如下:

通过3个门的控制,LSTM实现长短时记忆的功能。LSTM适合用于处理与时间序列高度相关的问题,使用LSTM进行音素识别,可以充分考虑音素序列的时序关系,提高音素识别准确率。
1.4.2分级音素识别系统设计
音素种类多,在英语国际英标中,英语音素可以分为元音与辅音2类。元音能量较大,过零率较低,辅音则刚好相反。元音持续时间较长,辅音持续时间较短。考虑了元音辅音的这些特性差异,设计出一种分级识别的音素识别系统,如图3所示。
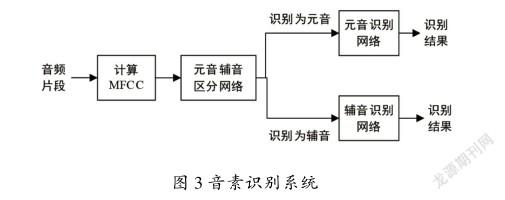
模型共包括3个神经网络。分别为元辅音区分网络、元音识别网络以及辅音识别网络。3个网络均为双层LSTM网络,元音辅音区分网络循环核时间展开步数为1,判断每一帧为元音还是辅音。元音识别网络循环核时间展开步数为5,对元辅音区分网络识别为元音的部分进行元音识别;辅音识别网络循环核时间展开步数为3,对元辅音区分网络识别为辅音的部分进行辅音识别。按以下步骤进行音素识别训练和音节片段的音素识别。
①将TIMIT库中训练集句子进行分帧,计算MFCC,作为神经网络的输入,利用TIMIT库中的音素切分文件,确定样本的标签。
②根据①得到的训练样本及标签,通过反向传播算法训练网络。
③将初检判断为关键词的音频片段送入元音辅音区分网络进行识别,识别为元音的部分送入元音识别网络进行识别,识别为辅音的部分送入辅音识别网络进行识别。
④3个网络识别结果均是逐帧给出的,采用贪心搜索[7]算法逐帧给出识别结果。根据元音辅音区分网络的帧识别结果进行音素段划分,连续识别为元音的帧为元音段,连续识别为辅音的帧为辅音段。由于划分出的元音或辅音段可能包含不止一个音素,采用如下方法确定每个音素段的音素组成。若该段识别为某个音素的帧数超过该段总帧数的80%,判定该音素段只包含一个音素;若该音素段识别出多个音素,则判定该段由频率较高的几个音素(保留帧数超过该音素段总帧数30%的音素)组成。然后考察各音素的时序关系是否与关键词音节的音素时序一致,若一致,则确认为关键词音节。
2实验结果及分析
2.1实验条件及评价指标
2.1.1 TIMIT库
实验采用的语音数据均来自TIMIT语音数据库。一共包含6 300个句子,来自美国8个主要方言地区的630个人每人说出给定的10个句子,其中每个句子均进行了音节切割以及音素切割。TIMIT库包含两部分,即训练集和测试集[8]。
2.1.2评价指标
关键词识别是从连续语音流中检测出目标关键词,而不关心其余单词的具体内容。本文采用有以下2种指标评价关键词识别系统的性能[9]。

2.2端点检测及音节切分实验
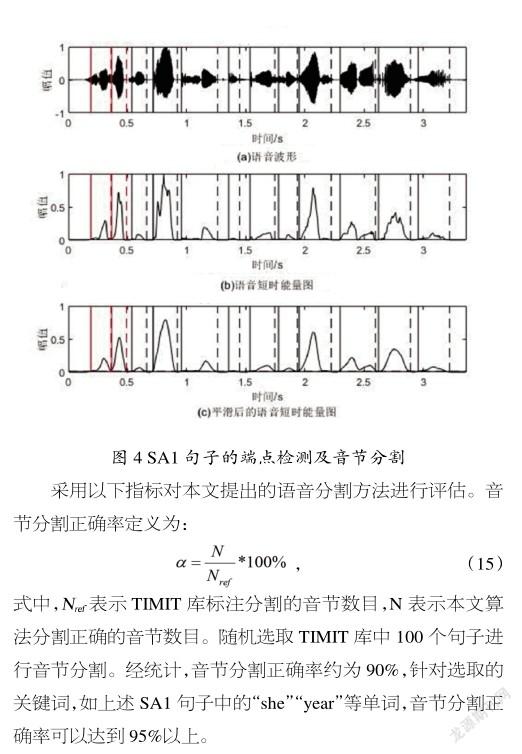
对基于短时能量峰谷点的音节切割方法进行实验,以TIMIT库中SA1句子为例,其内容为“She had your dark suit in greasywash water all year”,切分结果如图4所示。
图4中(a)表示语音波形图,(b)为语音短时能量波形图,(c)为平滑后的短时能量波形图。句子的短时能量呈“山峰”状,每隔一段时间后到达局部最大值然后逐渐下降,对应句子中元音部分能量大,辅音部分能量小。若单词为单音节单词,一个峰即可表示一个单词,若单词为多音节单词,若干峰表示一个单词。对于第1个音频片段,第1次切分时没有把相邻音节分开,但第2次切分完成了有效切割。
2.3基于过零率直方图的关键词初检
2.3.1目标关键词音节直方图模板生成
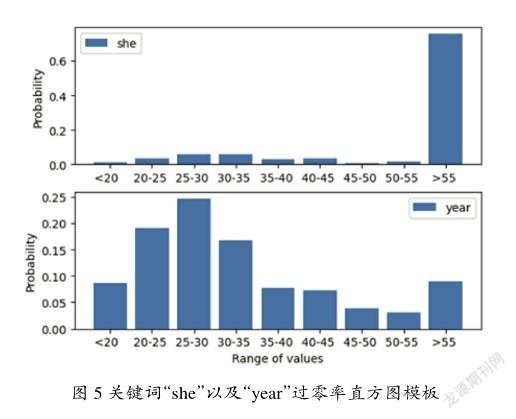
选择TIMIT库出现次数较多的单词“she”“year”作为目标关键词进行关键词粗检实验。每个单词提取32个样本,帧长为50 ms,帧移为20 ms,每个样本统计一个直方图,取所有样本的直方图平均作为模板。关键词“year”的过零率直方图模板使用同样的方法得到。关键词“she”“year”过零率直方图模板如图5所示,对比可知不同单词过零率直方图模板差异较大。
2.3.2基于过零率直方图的关键词粗检
随机选取单词“she”“year”“like”“dark”各自一个样本,计算其过零率直方图以及与目标关键词的相似度。不同待检单词过零率直方图对比如图6所示。
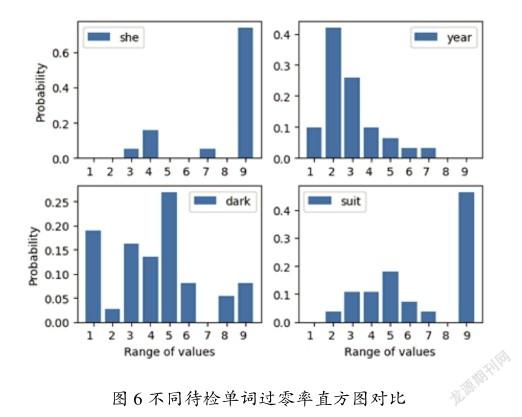
“she”“year”“dark”“suit”4個单词相对于目标关键词“she”模板的相似度分别为0.85、0.22、0.35、0.68;相对于目标关键词“year”模板的相似度分别为0.11,0.81,0.49,0.26。因此,待检音频为关键词时,它们与各自目标模板的相似度较高,若待检音频为非关键词,则它们与模板相似度低。将目标模板与待检音频片段的相似度与阈值进行比较,可以排除大量非关键词,但是一些与目标关键词相似的单词无法排除,如“suit”和“she”相似,和“she”模板的相似度也较高,需要进一步精检以确认其是否为目标关键词。
2.4关键词音素识别实验 2.4.1元辅音区分、元音识别、辅音识别实验
根据本文提出的分级音素识别方法训练音素识别模型。库中音素共有61种,有些音素发音相近甚至不发音,为减小模型规模,将音素合并,合并后音素有31类,其中元音11类,辅音20类。音素种类如表1所示,其中前20类为辅音音素,后面的类别为元音音素。

训练样本由TIMIT库整个训练集构成,包含元音样本约40000个,辅音样本约8 0000个。测试集从TIMIT库测试集随机提取得到。包含元音样本8 000个,辅音测试样本16 000个。元辅音区分网络、元音识别网络、辅音识别网络均为双层LSTM,元音辅音区分网络第一层节点数为80,第二层节点数为100,另外2个网络第一层节点数为200,第二层节点数为250。循环核时间展开步数分别为1,5,3。为防止模型过拟合,将Dropout值设为0.2。采用Adam方法进行模型的训练,batch_size设置为128。音素识别结果如表2所示。
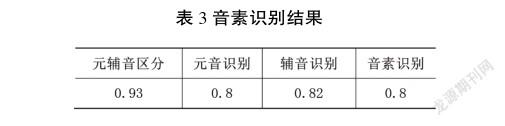
与不分级的LSTM音素识别网络进行对比,同样采用双层LSTM,第一层节点数200,第二层节点数为250的规模,循环核时间展开步数取3,其识别率约72%。由表3可知本文提出的分级音素识别网络音素识别率大约提高了8%。
2.4.2待检单词音素识别概率图
选取关键词“she”,使用训练好的分级识别网络分析其音素分布,识别结果如图7所示。
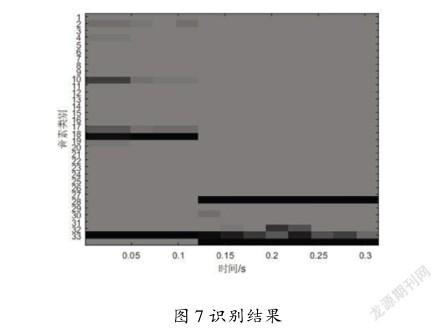
由图7可知,前半段第32类(辅音)概率高,第33类(元音)概率低,后半段则相反,由此可将该单词划分为辅音和元音2个音素段2个音素段;前半段识别为第18类,对应音素“sh”,后半段时间识别为第27类,对应音素“iy”,“she”由“sh”以及”iy”构成,该关键词音素识别成功。
2.5关键词识别实验
选取库中出现较多的单词she,like,dark,good,year,以及多音节词doctor作为目标关键词。选取包含关键词的100个句子进行实验,其中关键词数量为100,非关键词数量大约为1 000。dotor由2个音节组成,分别为:d aa kcl,t er。
选择合适的阈值对于关键词初检很重要。相似度阈值设置得过高,检出率会变低。相似度阈值设定过低,检出率高,但是虚警率也高。本文通过大量实验发现,不同单词设置不同的阈值可以得到较好的效果,最终将关键词“good”“like”相似度阈值设为0.5,其他关键词相似度阈值设为0.55,可以获得较高的检出率和合适的虚警率。
首先基于过零率直方图进行初检,对初检识别为关键词的单词,使用训练好的音素识别系统进行识别,关键词识别结果如表4所示。
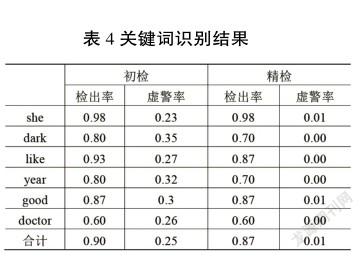
观察结果可得,在初检阶段虚警率较高,很多非关键词被识别为关键词,但是经过精检阶段的检测,可以使检出率、虚警率均得到较理想的结果。对语音识别的运行时间进行了粗略统计,仿真实验在Windows10操作系统,使用Python作为编程语言,在Tensorflow2.0环境下进行,若不采用本文提出的初检方法,直接对句子进行精检,一个句子的识别时间平均超过20 s,而采用本文提出的两步检索法,一个句子的识别时间平均约为5 s,运行时间大为缩减,为下一步嵌入式应用系统提供了可能的参考。
3结束语
本文提出了基于LSTM的关键词识别系统。在初检阶段,提出了一种快速筛选方法,利用基于过零率的直方图法可以快速排除与目标关键词区别很大的词语,过零率计算简单、统计简便、时间花费少。精检阶段使用分级LSTM网络,最大程度提取音素特征,且考虑了语音时序性,得到更好的识别结果。实验结果表明,本文提出的关键词识别系统识别率检出率高、虚警率低、计算复杂度低、速度较快。关键词直方图模板构建简单,音素识别系统一经建立,便对所有音节有效,故系统易于动态扩展目标关键词。下一步研究可针对音素识别系统或是所使用特征进行改进,以达到更好的识别率以及更小的时间开销。
参考文献
[1]孙彦楠,夏秀渝.基于深度神经网络的关键词识别系统[J].计算机系统应用,2018,27(5):41-48.
[2]刘鑫.按例查询型关键词识别系统的研究[D].北京:北京邮电大学,2018.
[3]王琳,阴桂梅,陈国梅.基于端点检测的语音分割方法[J].电脑编程技巧与维护,2020(10):151-153.
[4]宋知用.MATLAB在语音信号分析与合成中的应用[M].北京:北京航空航天大学出版社,2013.
[5]乔立能,夏秀渝,叶于林.基于音频指纹的两步固定音频检索[J].计算机系统应用,2017,26(5):266-271.
[6] CHAI Shuzhou,ZHANG WeiQiang,LV Changsheng,et al. An End-to-end Model Based on Multiple Neural Networks with Data Augmentation for Keyword Spotting[J]. International Journal of Asian Language Processing,2020,30(2) 2050006.
[7]羅敏娜,侍啸.贪心优化的搜索算法在RGV动态调度中的应用[J].沈阳师范大学学报(自然科学版),2019,37(4): 315-320.
[8]郑鑫.基于深度神经网络的声学特征学习及音素识别的研究[D].北京:清华大学,2014.
[9]汤志远,李蓝天,王东.语音识别基本法:Kaldi实践与探索[M].北京:电子工业出版社,2021.
3281501908222
