基于智能语音技术的闪电哨声波自动识别
2022-03-15袁静王子杰泽仁志玛王志国丰继林申旭辉吴鹏王桥杨德贺王统领周乐
袁静,王子杰,泽仁志玛,王志国,丰继林,申旭辉,吴鹏,王桥,杨德贺,王统领,周乐
1 防灾科技学院,河北三河 065201 2 应急管理部国家自然灾害防治研究院,北京 100085 3 清华大学,北京 100084 4 湖州师范学院体育学院,浙江湖州 313000
0 引言
闪电是高空频发的自然灾害,全球范围平均每秒发生约44次,全年累计约14亿次(Christian et al.,2003).闪电产生宽频带的电磁脉冲,能够传播到电离层并激发起电磁哨声波.哨声波是由于电磁波在传播过程中高低频成分之间存在相速度差,通常情况下高频相速度快提前到达卫星高度,低频相速度慢后续到达,导致其在卫星记录的电磁场时频图中呈现频率随时间下降的“L”形态的色散状(Barkhausen,1930;Storey,1953;Helliwell,1965).我国首颗电磁监测试验卫星张衡一号卫星记录的典型闪电哨声波如图1所示.当闪电哨声波传播的路径较长、电子密度较高或磁场强度较强时,色散变大(Carpenter and Anderson,1992).由于闪电哨声波的形态携带了大量的空间环境信息,被广泛用于空间环境监测中,是揭开圈层耦合机理的重要研究手段(Chen et al.,2017;Carpenter and Anderson,1992;Singh et al.,2018;Oike et al.,2014;Bayupati et al.,2012;Clilverd et al.,2002;Kishore et al.,2016;Záhlava et al.,2018;Parrot et al.,2019;Horne et al.,2013;罗旭东等,2017).

图1 张衡一号卫星记录的VLF频段磁场X分量上的闪电哨声波(Bx分量)Fig.1 The lightning whistler observed at VLF magnetic field′s X component by ZH-1 satellite (Bx component)
当前,基于闪电哨声波的空间物理研究主要针对卫星记录的单个闪电哨声波事件进行深入分析并反演其空间物理环境的相关参数,然而通常闪电哨声波事件淹没在卫星观测的海量电磁场数据中,完全依赖人工识别效率低下,难度极高,导致了闪电哨声波全球时空分布规律和相关参数的研究甚少.
2008年,国内外学者开始借助人工智能技术克服难点,初步发展了闪电哨声波图像自动识别算法.目前闪电哨声波识别算法的流程是首先对观测波形数据进行带通滤波,然后利用快速傅里叶变换将波形数据转化成时频图,最后借助机器学习或计算机视觉技术等自动识别时频图中的L色散形态.比如Lichtenberger等(2008)在反演电子密度时提出依赖人工处理大量地面甚低频(Very Low Frequency,VLF)观测数据将导致相关研究面临巨大的技术瓶颈,并提出了基于滑动模板匹配技术的闪电哨声波自动检测方法,其模板制作符合Bernard提出的闪电哨声波的形态特征(Bernard,1973).该算法已经大规模应用于Marion和SANAE的VLF地面观测站数据处理,其存在的缺陷是需要事先从时频图中移除闪电脉冲、地面电力系统谐波辐射和人工发射源等引起的干扰现象,具有较高虚警率和漏检率(Lichtenberger et al.,2008).Zhou等(2020)针对武汉VLF地面观测数据中隐藏的闪电吱声(tweek)现象,通过设置能量谱阈值和时间宽度阈值的方式提出了简单快捷地自动识别算法.但该方法不适用于从张衡卫星数据中识别闪电哨声波,因为张衡一号卫星电磁场观测载荷具有高灵敏度的特点,导致时频图的背景噪声的能量谱强度与闪电哨声波轨迹的能量谱强度相差不大,难以通过设置能量谱阈值的方式对闪电哨声波进行粗定位.斯坦福大学的VLF电波研究小组Stanford VLF Group(2009)最早对电磁卫星的闪电哨声波现象开展自动识别:截取固定时间窗的时频图,结合去噪处理、网格划分、计算平均幅度值等计算机视觉技术完成特征提取功能,最后采用模板匹配的分类策略实现闪电哨声波粗定位.Dharma等(2014)认为该特征的性能受制于网格划分的数量,利用闪电哨声波区域的颜色变化较小且具有明显连通的特点,提出了基于连通域分析的闪电哨声波粗定位方法.其缺陷是特征鲁棒性不高,算法效果受背景噪声影响很大.Oike等(2014)和Fiser等(2010)以Eckersley公式(Eckersley,1935)为基础,借助观测数据分别制作了白天和夜间的闪电哨声波模板,再采用互相关熵的模板匹配策略完成闪电哨声波识别和粗定位.Ali Ahmad等(2019)认为上述闪电哨声波模板不符合实际情况,借助边缘提取等计算机视觉技术提出了表达多种色散形态的特征提取方法,最后利用基于决策树规则的分类算法完成识别.袁静等(2021a)认为按照上述方法提取的闪电哨声波特征鲁棒性差且分类器的泛化性能低,则根据闪电哨声波的色散形态设计了能够增强闪电哨声波L色散特征的卷积核并采用支持向量机做分类器获得了较高的识别性能.
鉴于深度神经网络在提取图像特征和拟合非线性函数等方面获得的巨大突破(LeCun et al.,2015;Liu et al.,2018),Konan等(2020)提出了两种基于深度神经网络的闪电哨声波粗定位算法:基于滑动深度卷积神经网络(Sliding Deep Neural Convolutional Neural Network,SDNN)算法和基于YOLOv3 (You Only Look Once version 3rd)神经网络算法.SDNN神经网络主要包含两部分:3个卷积层和2个分类层.该算法的实施过程:截取某固定时间宽度的时频图,利用卷积层提取图像特征,再利用分类层进行识别,从而实现闪电哨声波粗定位(Konan et al.,2020).该算法具有高鲁棒性特征的提取功能,泛化能力强的分类功能,但漏检率高,原因是基于固定时间宽度的定位策略容易漏检其他时间宽度的闪电哨声波(Konan et al.,2020;袁静等,2021b).YOLOv3神经网络的闪电哨声波检测算法包含两个主要组成部分:YOLOv3主体网络和非极大值抑制(Non-Maximum Suppression,NMS)算法.YOLOv3主体网络主要由75个卷积层构成,无全连接层,适应任意大小的输入图像;无池化层,尺度不变特征能传送到下一层;采用残差结构极大地降低了学习鲁棒特征的难度;利用上下文图像信息构造目标定位的数学模型;通过上述过程主体网络将输出多个粗定位的预测框,最后再采用NMS算法对主体网络输出的预测框进行过滤和优化,从而实现闪电哨声波区域粗定位;以上优势使得YOLOv3深度神经网络较其他粗定位算法具有更高的精度、更快的速度和更高的效率(Konan et al.,2020;袁静等,2021b),但需要配置高性能的GPU设备,且消耗的内存资源高达233M.
总之,目前主流的闪电哨声波识别算法需要将原始波形数据转化为时频图,对算力和存储设备的要求较为苛刻,适合离线数据,因而无法直接应用于星载.张衡一号感应磁力仪(Search Coil Magnetometer,SCM)载荷探测到的闪电哨声波形数据以语音方式播放出来后能够非常清晰地听到类似口哨的声音,意味着其频率正好在人耳可听到的范围之内(Wicks et al.,2016).梅尔频率倒谱系数(MFCCs)恰恰模拟了人耳的听觉特性(Davis and Mermelstein,1980)能有效提取闪电哨声波的听觉特征,LSTM神经网络引入了时间维信息适合处理听觉特征中的声音事件(Hochreiter and Schmidhuber,1997),这使得采用语音识别技术识别闪电哨声波成为可能.因此,本文以张衡一号卫星SCM观测的磁场波形数据为研究对象,首次提出了基于智能语音技术的闪电哨声波自动识别算法.
1 数据处理流程
2018年2月,我国首颗电磁卫星张衡一号(ZH-1)发射成功,具备了天基观测闪电哨声波的能力.ZH-1卫星覆盖南北纬65°,在中国大陆及周边1000 km区域及全球两个地震带(太平洋地震带和欧亚地震带)进行详查模式的观测,其他区域为巡查模式(Zhang et al.2018).ZH-1卫星在轨飞行高度约507 km,其位置接近电离层顶部和等离子层边界,这个区域有丰富的ELF/VLF频段波动事件(Yan et al.2018;Wang et al.,2018),如闪电哨声波、准周期辐射等(Zhima et al.,2020).ZH-1轨道倾角97.4°,属于太阳同步轨道,降交点地方时为下午2∶00;轨道回归周期为5天,即每5天星下点轨迹相同;在一个回归周期内能够实现全球约500 km 空间分辨率的观测.卫星绕地球飞行一圈约94 min,大部分载荷在±65°纬度范围开机工作,观测数据按升轨(夜晚)和降轨(白天)分别存储,每半轨(升/降轨)观测约34 min;在同一天内相邻的升轨(或降轨)空间分辨率约2000 km.所搭载的感应磁力仪载荷(SCM),通过法拉第电磁感应定律获得电离层的感应磁场数据,能够捕获全球闪电哨声波信号,其在巡查模式下仅获得功率谱数据(Zhou et al.,2018;Huang et al.,2019).到目前为止,ZH-1已经在轨观测3年多,采集了大量的全球电磁场的波形和功率谱数据,其中SCM的三分量X/Y/Z包含3个频段 ULF/ELF/VLF,频点范围ULF:10 Hz~200 Hz,ELF:200 Hz~2.2 kHz,VLF:12.5 Hz~20 kHz,原始波形数据的采样率为51.2 kHz,功率谱数据的频点间隔ULF:0.25 Hz,ELF:2.5 Hz,VLF:12.5 Hz,详查模式VLF波形数据80 ms包含4096个点,每天产生大约10 G的数据量(Wang et al.,2018;Cao et al.,2018;Shen et al.,2018a,b).面对海量数据的挑战,亟需实现基于原始波形的闪电哨声波自动识别.
基于原始波形的闪电哨声波识别方案主要由三部分组成,如图2所示:数据整理、数据预处理和基于智能语音的闪电哨声波自动识别算法.
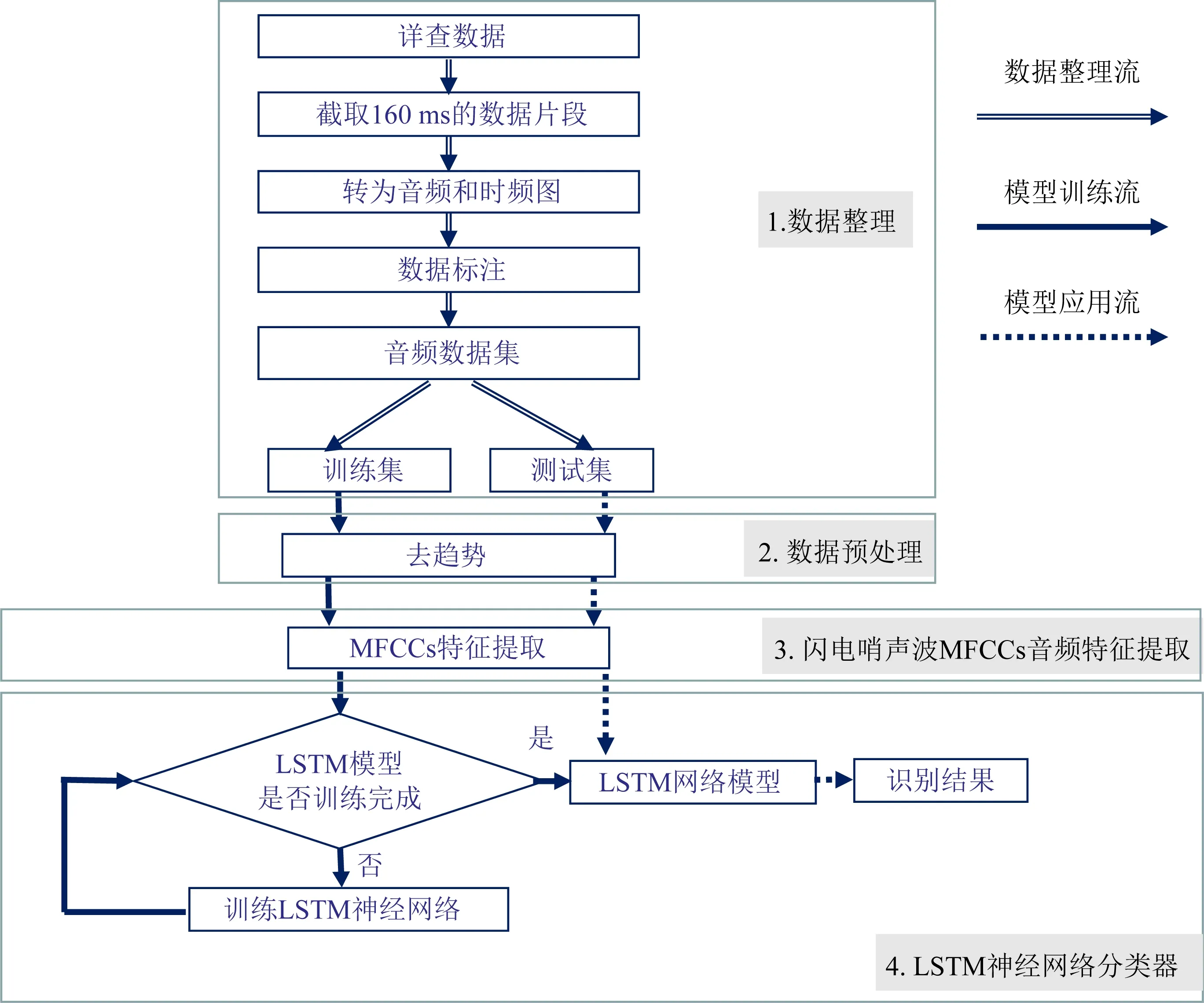
图2 自动识别ZH-1卫星记录闪电哨声波的数据处理流程图Fig.2 The diagram of automatic recognition of the lightning whistler recorded by ZH-1 satellite
(1)数据整理
本文的数据收集主要来自ZH-1卫星2018年8月SCM载荷VLF波段的详查数据.首先,以0.16 s的时间滑动窗从原始波形数据中截取数据,该数据含有8192个点,将其转化为音频片段;再对截取数据进行重复短时傅里叶变换得到其时频图;然后根据时频图是否存在L色散形态特征进行人工标注;最终获得10200段音频数据集(闪电哨声波数据5100段,非闪电哨声波数据5100段).请注意本文中的时频图仅仅是为了查看是否存在闪电哨声波,并不参与识别算法的计算.
(2)数据预处理
为了有效避免由于噪声和信号的不稳定导致的干扰,增强闪电哨声波的波形特征,首先对原波形数据进行去趋势处理,如式(1)所示:

(1)
其中,s(n)为原始信号,S(k)为去趋势后的信号.结果如图3所示.图3a是含有闪电哨声波的原波形,对其进行趋势处理后的结果如图3b所示,图3c是不含闪电哨声波的波形数据,对其进行去趋势处理的结果如图3d所示.
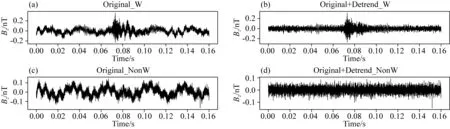
图3 VLF磁场的原始波形和去趋势处理(a)含闪电哨声波的原始波形;(b)对图(a)去趋势处理;(c)不含闪电哨声波的原始波形;(d)对图(c)进行去趋势处理.Fig.3 The raw and detrended waveform of the VLF magnetic field data(a)The raw wave containing the lightning whistler;(b)The result by processing the (a)with detrended method;(c)The raw wave not containing the lightning whistler;(d)The result by processing the (c)with detrended method.
(3)闪电哨声波MFCCs音频特征提取
由于人耳能明显地听到闪电哨声波的嘶嘶声,依据人耳的听觉机理所设计的MFCCs能够提取闪电哨声波的声音特征,将在第二节详细介绍其提取过程.
(4)LSTM神经网络分类器
该环节主要包含训练神经网络和应用神经网络两个过程.其中,训练神经网络指的是在训练样本集上提取MFCCs特征,利用该特征训练LSTM神经网络;应用神经网络指的是在测试集上提取MFCCs,将其输入训练好的LSTM网络,得到最终的识别结果,将在第三节详细介绍其实现过程.
2 闪电哨声波MFCCs音频特征提取算法
MFCCs特征提取过程见图4所示,主要包括预加权重,分帧加窗,快速傅里叶变换,Mel滤波组,对数运算,离散余弦变换(DCT)和动态差分.

图4 MFCCs特征参数提取流程示意图Fig.4 Flow chart for extracting MFCCs parameters
2.1 预加重、分帧、加窗和快速傅里叶变换
预加重处理:目的是对语音的高频部分进行加重,增加高频部分的分辨率.
s(n)=sn-μsn-1,(2)
式中sn是原始信号,s(n)为处理后的信号,参数μ的值介于0.9~1.0之间,由于SCM采样率是51.2 kHz,则本文选取μ=0.97.
分帧处理:先将N个采样点集合成一个观测单位,称为帧,本项目中N为512.为了避免相邻两帧的变化过大,设置两相邻帧之间存在重叠区域,此重叠区域包含了M个取样点,通常M的值约为N的1/2或1/3.对应的时间长度是:
512/51200×1000=10 ms,(3)
加窗处理:窗长40 ms,窗移8 ms,对信号加窗以避免短时语音段边缘的影响(Jibbs效应).加窗的定义如下:
sω(n)=s(n)×ω(n),(4)
式中ω(n)为窗函数,sω(n)为加窗后的信号,本文选用Hamming窗来进行加窗处理,ω定义如式(5)所示:
(5)
不同的α值会产生不同的汉明窗,默认选取0.46.
快速傅里叶变换:由于信号在时域上的变换通常很难看出信号的特性,所以通常将它转换为频域上的能量分布来观察,不同的能量分布代表不同语音的特性.对分帧,加窗后的各帧信号进行快速傅里叶变换得到各帧的频谱,并对语音信号的频谱取模平方得到语音信号的功率谱,如式6所示:
(6)
其中,sω(n)为加窗后的信号,X(k)为快速傅里叶变换后得到的信号,N表示傅里叶变换的点数.
2.2 Mel滤波器组
将能量谱通过一组Mel尺度的三角形滤波器组,采用一个有M个滤波器的三角滤波器,中心频率为f(m).M为滤波器个数,本文M选默认值26,Hm(k)表示能量谱权重.其中Hm(k):
Hm(k)=
(7)
其中f(m)满足:
2Mel(f(m))=Mel(f(m-1))+Mel(f(m+1)),(8)
Mel标度频率域提取出来的倒谱参数与频率成非线性对应关系,见图5所示,用式(9)近似表示为

图5 Mel频率与线性频率的关系图Fig.5 Relationship between the Mel frequency and the linear frequency
(9)
其中,f为频率.
2.3 对数运算、离散余弦变换DCT
对数运算:将FFT得到的频谱系数X(k)用顺序三角滤波器进行滤波处理得到一组能量系数m1,m2,m3….滤波器组中每三个滤波器的跨度在Mel刻度上是相等的.所有的滤波器总体上覆盖的范围从0 Hz到采样频率的二分之一,计算能量系数s(m)的公式如下:
(10)
其中,X(k)为快速傅里叶变换后得到的信号,Hm(k)表示能量谱权重,M为滤波器的个数.
计算滤波器组输出能量系数的对数能量,其公式为
s′(m)=lns(m),0≤m≤M
(11)
其中,s(m)为能量系数,s′(m)为对数能量系数.
离散余弦变换:目的是去除各维信号之间的相关性,将信号映射到低维空间.将上述的对数能量带入离散余弦变换,求出L阶的Mel-scale Cepstrum参数,如式(12)所示:
(12)
其中,c(n)为倒谱系数,L为阶数在MFCC中通常选取8~13,本文L选取13.
2.4 动态差分
标准的倒谱参数MFCC只反映了语音参数的静态特性,语音的动态特性可以用这些静态特征的差分谱来描述,把语音的动、静态特征结合起来能有效提高系统的识别性能.其差分谱的计算公式如式(13)所示:
(13)
其中,dt表示第t个一阶差分,Ct表示第t个倒谱系数,L表示倒谱系数的阶数,K表示一阶导数的时间差,可取1或2.
最后将c(n)、dt(K=1)和dt(K=2)拼接得到一个16×39的二维张量,其每行表示一帧的能量值.帧能量的组成是由39维MFCC参数(13维MFCC倒谱系数+13维一阶差分参数+13维二阶差分参数).按照上述方法分别提取图3中各子图的MFCCs特征,将其绘制成如图6所示的帧能量图.横坐标表示MFCC倒谱的个数,纵坐标代表时间.图6a是含有闪电哨声波的原始波形的MFCCs特征,对图6a的原始波形进行去趋势处理后的MFCCs特征如图6b所示,图6c是非含有闪电哨声波的原始波形的MFCCs特征,对图6c的原始波形进行去趋势处理后的MFCCs特征如图6d所示.观察发现:闪电哨声波和非闪电哨声波在MFCCs特征上具有较强的鉴别性,比如MFCCs特征图的第三列存在明显差异.

图6 MFCC-Time帧能量图(a)含有闪电哨声波;(b)对图(a)去趋势;(c)不含有闪电哨声波;(d)对图(c)去趋势.Fig.6 The energy map of MFCC-Time Frame(a)Containing the lightning whistler;(b)The result by processing the (a)with detrended method;(c)Not containing the lightning whistler;(d)The result by processing the (c)with detrended method.
3 LSTM神经网络分类器算法
磁场原始数据是时序信号,当出现闪电哨声波时,通过语音播放器能够听到明显“哨声”,提取其MFCCs特征发现其具有明显的序列关联性.LSTM 恰恰是一类专门用于处理序列关联数据的神经网络.LSTM网络中存在的细胞单元使该网络具备“记住”长时间历史信息的能力,从而可以通过学习捕捉到当前时刻的信息与历史信息之间的依赖关系,以此提升对序列数据建模的能力,最终获得较好的分类效果.鉴于以上优势,本文采用LSTM网络对闪电哨声波的MFCCs特征进行分类建模,其基本结构见图7所示,主要由4部分组成:细胞状态、遗忘门f、输入门i和输出门o三种门控单元(Hochreiter and Schmidhuber,1997).
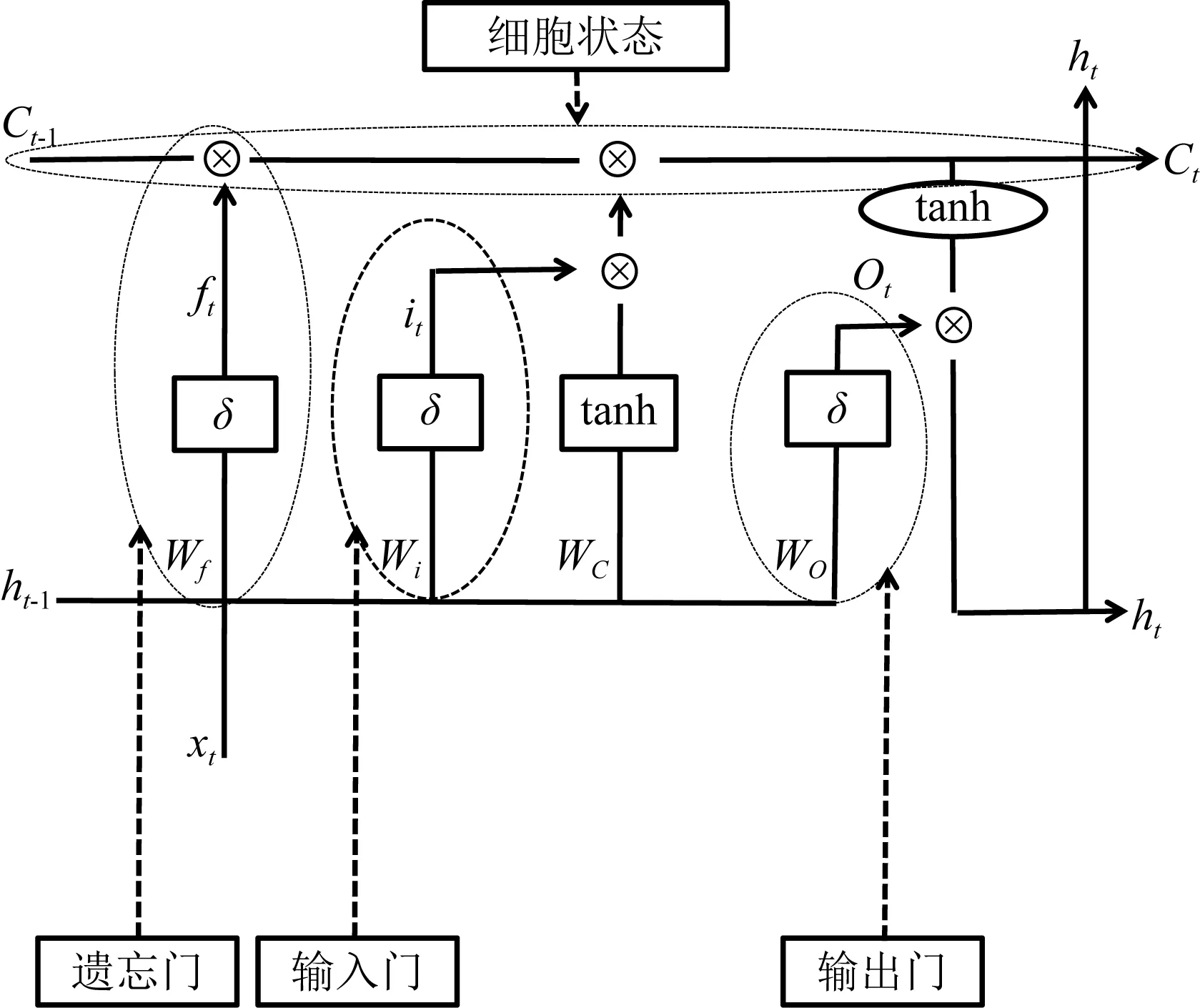
图7 LSTM单元结构示意图Fig.7 The unit structure of LSTM
遗忘门:用来决定当前需要丢弃之前的哪些磁场信息.LSTM网络通过学习决定让网络记住哪些磁场数据内容,遗忘门定义如下:
ft=δ(Wt·[ht-1,xt]+bf),(14)
其中,xt是网络在t时刻的输入,其数值是MFCCs序列中的第t个数值;δ表示取Sigmoid函数值;Wt表示t时刻的权重矩阵;ht-1表示将1到t-1时刻的MFCCs序列数据(x1,x2,…,xt-1)输入到 LSTM 神经网络后的输出的抽象特征信息;bf表示t时刻的偏置量.ft的元素取值范围是0到1,表示t时刻的遗忘程度,0表示全忘,1表示全记住.遗忘门具有过滤掉与闪电哨声波无关的特征信息的功能.
输入门:处理MFCCs序列数据中当前位置的数据.图7中间部分的左侧是sigmoid激活函数,这个函数是用来决定哪些输入的特征会被记住,其定义如式(15)所示.
it=δ(Wi·[ht-1,xt]+bi).
(15)
细胞状态:细胞状态是隐状态,类似一个存储信息的容器,保存序列数据中的关联性信息,具有历史记忆功能,其定义如式(16)所示.
Ct=ft×Ct-1+it×Rt,(16)
其中,Rt是输入门右侧的tanh部分,该部分的主要作用是利用上一次的输出和本次输入计算新的候选的细胞状态信息,其定义是:Rt=tanh(Wc·[ht-1,xt]+bc);ft×Ct-1意味着通过前一个时刻的细胞状态Ct-1与遗忘门ft结合,忘记旧细胞状态中一些信息;it×Rt意味着通过输入门it和候选细胞状态Rt结合,记住新候选细胞状态中一些信息.
输出门:控制当前隐状态的输出信息,其基本计算过程为
ot=δ(Wo·[ht-1,xt]+bi),(17)
其中,ot是输出门,通过将前一个时刻的输出信息ht-1和当前的数据xt输入到Sigmoid函数得到的.
最后输出当前时刻的重要信息ht,其定义如下:
ht=ot×tanh(Ct),(18)
该信息是通过联合输出门和当前的细胞状态Ct进行计算而得到.最后将ht输入到sigmoid函数实现自动识别.ht含有序列之间的关联性信息,这使得序列数据的识别效果得到了大幅提升.
4 实验和分析
4.1 实验流程及LSTM神经网络模型参数设置
实验流程包括数据整理、MFCCs特征提取、LSTM模型训练和评估指标值,并进行1000次重复实验.具体详细步骤如下:
(1)数据集:含有5100个闪电哨声波波形样本集WD和5100个非闪电哨声波的样本集NWD.
(2)训练集:分别从样本集WD和NWD中各随机选取50%作为训练样本,构建训练集.
(3)测试集:将样本集WD和NWD剩下的样本组建成测试集.
(4)特征提取:用4种不同的特征提取方法提取训练集的音频特征,4种特征分别是:原始波形数据特征,用Original表示;对原始波形数据进行去趋势处理后的特征,用Original_Detrend表示;对原始波形数据采用MFCCs处理后的特征,用Original_MFCC表示;先对原始波形数据进行去趋势处理,再采用MFCCs处理后的特征,用Original_Detrend_MFCC表示.
(5)训练过程:用(4)中提及的4种特征分别训练LSTM分类模型,得到4种不同的LSTM分类器.
(6)测试过程:在测试集上先采用步骤(4)中4种不同的特征提取方式提取特征,再将4种特征分别输入到4种不同的LSTM分类模型中进行识别,输出识别结果.
(7)评估:对识别效果采用4种指标进行评估:精确度(Precision)、召回率(Recall)、F1值和ROC面积(AUC-ROC)(袁静等,2021b).
采用不同的输入特征训练LSTM神经网络所需的超参数也不尽相同,对每一种特征分类器,均采用十折交叉的方式获得LSTM神经网络模型的超参数,见表1所示.其中优化器选择的是自适应梯度优化器(Adaptive Gradient Algorithm,Adagrad)(Duchi et al.,2011);损失函数选择的是适用于二分类的二元交叉熵损失函数(Binary_CrossEntropy)(Goodfellow et al.,2017).

表1 基于4种不同特征的LSTM神经网络的参数Table 1 The parameters setting of four LSTM neural networks
为了全面地评估本文算法的有效性,开展1000次实验:每一次实验的训练集和测试集均使用4种不同的特征提取方法提取图像特征,并以此训练得到4个不同的分类器,最后采用精度、召回率、F1和AUC-ROC评估每一个分类器的性能,4种指标的详细定义请参考袁静等(2021a)的文献资料.由于每次的训练集和测试集不同,单次的4个评估指标难以充分评价本文提出的闪电哨声波识别算法的效果,因此,开展实验1000次,并在4个评估指标的基础上制定了如下的评价策略:
(1)训练集和测试集的表现;
(2)部分识别结果展示;
(3)总体识别精度评价:对1000次实验的评价指标进行求平均值的评价策略;
(4)稳定性评价和差异性评价:对1000次实验的评价指标采用盒形图评估分类的稳定性.为了评价不同的特征分类器之间是否具有明显差异,采用 T 检验进行差异性评价.阈值p=0.05,即小于0.05为具有明显差异,若大于0.05表明不具有明显差异.
4.2 训练集和测试集的表现
利用表1的超参数开展1000次实验,得到每次实验的测试集和训练集在精度指标上的表现,对其进行求平均得到如表2所示的结果,说明本文提出的算法无论在训练集和测试集的表现均为最佳.

表2 基于4种不同特征的LSTM神经网络在训练集和测试集上的表现Table 2 The performance of four LSTM neural network models on training set and test set
4.3 部分识别结果展示
部分识别结果的波形图和相应的时频图绘制如图8和图9所示,其中波形图是识别结果,此处的时频图仅仅是为了可视化波形中是否存在闪电哨声波.图8是闪电哨声波的识别结果,图8a是正确识别出的闪电哨声波,图8b是未识别出的闪电哨声波,识别不成功的原因是:闪电哨声波的能量较弱且背景干扰强,导致闪电哨声波的趋势特征不明显,采用去趋势处里后哨声波趋势被干扰淹没,造成了不存在闪电哨声波的假象,如图8c所示.图9是非闪电哨声波的部分识别结果,(a)是正确识别出的非闪电哨声波,(b)是误识别的非闪电哨声波,误识别的原因是:原始波形数据中存在强烈的干扰信号且出现近似闪电哨声波的趋势特征,如图9b的时频图的黑框处,对相应的波形进行去趋势处理后的结果如图9c所示.
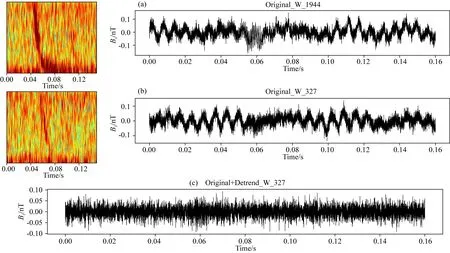
图8 闪电哨声波(a)正确识别(右子图是原始波形,左子图是其时频图);(b)未识别(右边是原始波形,左边是其时频图);(c)对图(b)进行去趋势.Fig.8 Results of recognition of lightning whistler(a)Accurate (The right panel is the wave and the left panel is the time-frequency plot of the right panel);(b)Wrong (The right panel is the wave and the left panel is the time-frequency plot of the right panel);(c)The result by processing the (b)with detrended method.

图9 非闪电哨声波(a)正确识别(右子图是波形数据,左子图是其时频图);(b)错误识别(右子图是波形数据,左子图是其时频图);(c)去趋势后的(b).Fig.9 Results of recognition of non lightning whistler(a)Accurate (The right panel is the wave and the left panel is the time-frequency plot of the right panel);(b)Wrong (The right panel is the wave and the left panel is the time-frequency plot of the right panel);(c)The result by processing the (b)with detrended method.
4.4 总体识别精度评价
1000次实验后分别获得1000个精确度(Precision)、召回率(Recall)、F1值(F1socre)、ROC面积(AUC-ROC)值、时间消耗(Cost time)和内存消耗(Cost memory),分别对其进行均值计算以评估基于智能语音技术的哨声波识别效果,如表3所示.
表3中Original+LSTM表示用原始波形训练LSTM分类器,Original_Detrend+LSTM表示对原始波形进行去趋势处理后再训练LSTM分类器,Original_MFCC+LSTM表示对原始波形提取MFCCs特征,Original_Detrend_MFCC+LSTM表示对原始波形进行去趋势处理后再提取其MFCCs特征,最后用该特征训练LSTM分类器.通过观察表3发现:直接用原始波形数据训练LSTM分类器的识别算法(Original+LSTM),具有最少的时间消耗和内存消耗,分别是2.08 s和82.790 MB,但该算法在分类精度、召回率、F1值和AUC-ROC四个指标上的表现最差.本文提出识别算法(Original_Detrend_MFCC+LSTM)在4个指标上的表现效果最佳,分别达到0.967,0.842,0.900和0.907,且由于采用了MFCCs特征,将每段0.16 s的音频数据量从8192减少到684(16×39),使得其时间消耗和内存消耗与Original+LSTM相近,达到2.24 s和82.89 MB.而Original_Detrend+LSTM算法为了得到较好的分类结果使用了双层LSTM网络,导致该算法损失了更多的时间和和内存.值得注意的是目前最佳的基于时频图的闪电哨声波识别算法采用的是YOLOV3深度卷积神经网络(袁静等,2021b),其在CPU上消耗的时间成本是6.71 s,消耗的内存资源是233 MB.

表3 1000次实验后平均效果Table 3 Statistical results of 1000 experiments
总之,在基于原始波形的闪电哨声波识别中,联合MFCCs音频特征提取和LSTM神经网络技术的闪电哨声波识别算法的分类效果最优.与基于时频图的识别算法比较,其消耗的时间成本和内存资源最小.
4.5 稳定性和差异性评价
本小节将针对不同的LSTM分类器的分类效果进行稳定性和差异性评价.
(1)稳定性评价:对每种指标的1000个数据,绘制其箱型图,如图10所示.闪电哨声波的识别精度(Precision)的1000组数据分布图如图10的Precision图所示:其横轴是不同的特征分类器,纵轴是精度.可发现采用Original_Detrend_MFCC特征分类器的Precision箱体的高度低于Original、Original_Detrend和Original_MFCC特征分类器,说明该特征分类器在Precision指标上的表现更稳定;该箱体的位置高于Original、Original_Detrend和Original_MFCC特征分类器,说明该特征分类器在Precision指标上的表现更优.用上述方法观察图10的Recall、F1score和AUC-ROC的箱体,均能得出上述同样结论.总之,本文提出的分类器在4个评价指标上均最优且最稳定性.
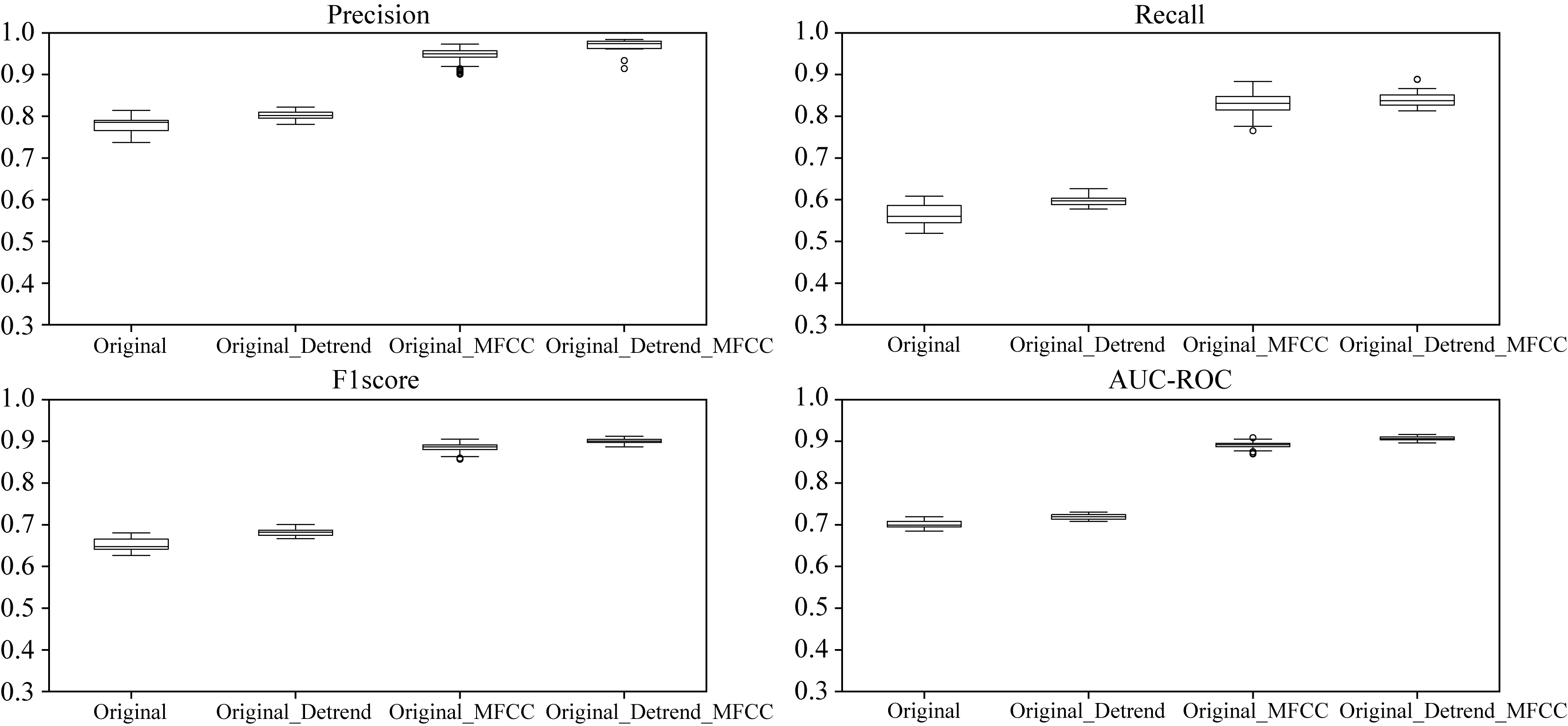
图10 评估LSTM分类器性能的箱型图Fig.10 Box plot for evaluating the performance of four LSTM network models
(2)差异性评价:为检验不同分类器的性能是否存在明显的差异,采用两两独立样本的T检验方法对显著性差异进行定量评价,其显著性P值越高,表明差异性越小,通常采用的阈值是0.05,其含义是若差异性小于0.05则认为存在明显差异;若大于0.05则认为两组实验不存在明显差异.结果见表4所示.
观察表4的Precision 的T值检验表中的第一行第二列的值是0,说明采用Original特征分类器与Original_Detrend特征分类器在精度指标上存在明显差异,继续观察发现,Original_Detrend_MFCCs特征分类器的精度与其他两个特征分类器的精度也存在明显的差异;但相同特征分类器在精度指标上的T检验值是1,说明相同特征分类器在精度指标上未表现出显著性差异,比如第三行第三列的值是1.用上述方法观察表4的Recall的T值检验表、F1score的T值检验表和AUC-ROC的T值检验表,可以得到同等结论.总之,本文提出的识别算法与其他识别算法在精度、召回率、F1值和AUC-ROC 4个评价指标均表现出了明显差异,说明本文提出的算法显著地改善了识别效果.

表4 T检验Table 4 The T test
5 讨论
上述实验表明本文提出的闪电哨声波自动识别算法具有一定的效果.算法方案中的原始波形特征提取和LSTM神经网络对闪电哨声波自动识别结果有非常重要的影响,本章将对其产生的影响进行较深入的讨论和分析.
5.1 提取波形特征
为了分析4种特征的时间轨迹,本小节随机选用10个闪电哨声波样本和 10 个非闪电哨声波样本的音频数据,绘制4种波形特征的时间轨迹如图11所示.
图11a是原始波形数据的时间序列,图11b是对原始波形数据进行去趋势处理后的时间序列,图11c是对原始波形数据进行MFCCs特征提取后的时间序列,对图11b进行MFCCs特征提取,得到16×39维的特征图,参考图6的效果,将该特征图的第三列特征按照时间顺序展开,得到如图11d所示的结果;其中W表示闪电哨声波波形样本,NonW表示非闪电哨声波波形样本.观察图11a发现,含有闪电哨声波原始波形的时间轨迹和非闪电哨声波的轨迹杂糅在一起,增加了分类的难度;对原始波形数据进行去趋势处理后,含有闪电哨声波的样本轨迹的类内差变小,如图11b所示,但分类难度依然较大;对原始波形数据提取MFCCs特征后,含有闪电哨声波的样本轨迹具有可分性,但有部分杂糅在一起且内类差较大,如图11c所示;对原始波形进行去趋势处理并提取MFCCs特征,绘制其时间轨迹如图11c所示,发现:含有闪电哨声波的时间轨迹和非闪电哨声波的轨迹具有明显的可分性.
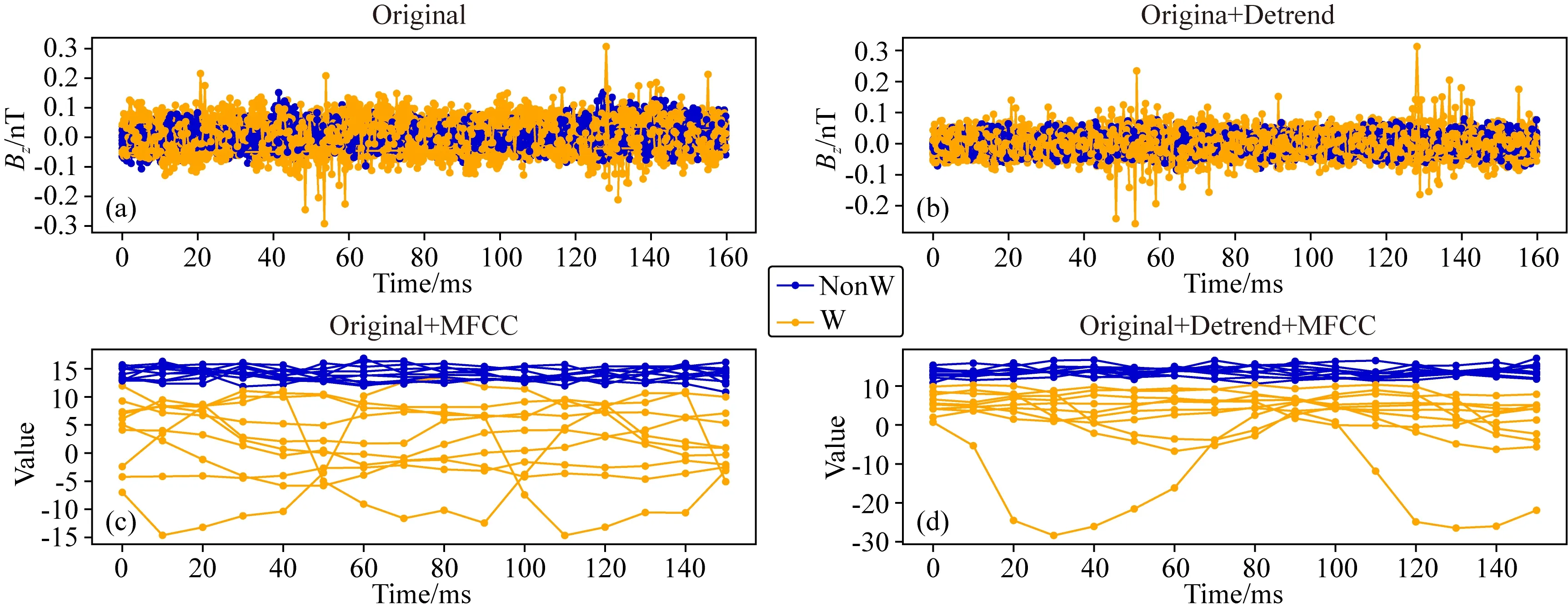
图11 波形数据中的语音特征的时间轨迹(a)原数据;(b)原数据去趋势;(c)原数据+MFCCs特征;(d)原数据+去趋势+MFCCs特征;橙色和蓝色曲线分别代表闪电哨声波和非闪电哨声波.Fig.11 The visualization of the audio feature,the orange and blue curves represent the lightning induced whistler waves and non-whistler waves(a)The audio feature from the raw waveform (Marked as Original);(b)The audio feature from the detrended raw waveform (Marked as Original_detrend);(c)The audio feature extracted from MFCCs of the raw wave (Marked as Original_MFCCs);(d)The audio feature extracted from MFCCs of the detrended wave (Marked as Original_Detrend_MFCCs).
5.2 LSTM神经网络的抽象映射
LSTM神经网络的输出门的最后时刻的隐藏信息特征ht含有时间序列的抽象特征,该抽象特征包括该时间序列的历史信息和趋势信息等,对最终的分类结果产生关键影响.本小节在测试集中随机选择200个闪电哨声波波形样本(WD)和200个非闪电哨声波波形样本(NWD),将这些样本通过4种不同特征的LSTM分类器的抽象特征绘制成图12,其中W表示闪电哨声波波形样本,NonW表示非闪电哨声波波形样本.
根据这些样本数据,计算不同的LSTM网络的抽象特征的类内差异度和类间差异度,得到见表5所示的结果.
通过观察图12和表5可以发现,基于MFCCs的LSTM分类器的抽象特征,其闪电哨声波类内差是0.06609,非闪电哨声波的类内差是0.00024,这说明同类样本的聚集性强;同时,闪电哨声波和非闪电哨声波的类间差是0.26357,说明不同类间的差异性强.总之,本文提出的算法具有类内差小、类间差大的特点,意味着该算法更容易实现准确分类.

图12 不同LSTM网络中的抽象特征(a)原数据+LSTM网络;(b)原数据去趋势+LSTM网络;(c)原数据+MFCCs+LSTM网络;(d)原数据+去趋势+MFCCs特征+LSTM网络.Fig.12 The abstract features from four LSTM networks(a)Original+LSTM;(b)Original+Detrend+LSTM;(b)Original+MFCCs+LSTM;(d)Original+Detrend+MFCCs+LSTM.
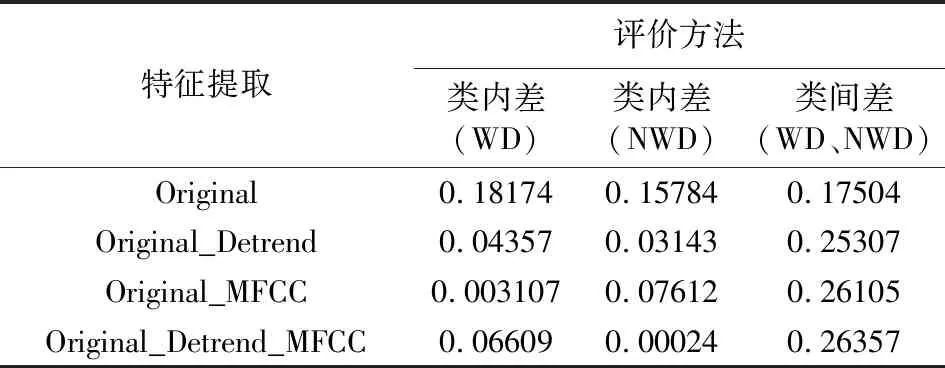
表5 4种LSTM网络中的抽象特征的差异Table 5 Comparison of the abstract features among four LSTM networks
5.3 网络结构对LSTM分类结果的影响
从实验结果发现不同的网络结构对LSTM神经网络的分类效果产生不同的影响,接下来将从LSTM网络的性能和抽象特征可分性两个方面进行讨论.
(1)性能评估
本小节对不同网络结构的LSTM网络进行十折交叉验证并计算交叉验证得分和训练所需的时间消耗,结果见表6所示.

表6 不同超参数的LSTM网络Table 6 LSTM network with different parameters
通过观察表6发现,使用加入Dropout的单层LSTM网络(LSTM网络C)比另外两个LSTM网络在十折交叉验证中得分高,达到0.947,其分类器的平均时间消耗也是最少,为43.673 s.由于神经网络会发生过拟合现象,加入Dropout能起到一种Vote的作用和减少神经元之间的共适应性,能提升了网络的精度和泛化能力.
(2)特征可分角度分析
为了定性的比较不同超参数下的LSTM网络的抽象特征是否具有可分性,本小节将60个闪电哨声波和60个非闪电哨声波分别输入到不同超参数的LSTM网络中提取隐藏信息特征ht,并将其随着时间变化的轨迹绘制如图13所示.其中W表示闪电哨声波波形样本数据,NonW表示非闪电哨声波波形样本数据.
图13a的时间轨迹是来自加入失活层的双层LSTM网络,图13b的时间轨迹来自加入失活层的单层LSTM网络,图13c的时间轨迹来自去掉失活层的单层LSTM网络.观察图13发现,LSTM网络-A的W和NonW的特征存在重叠,总体区分度不是很高;LSTM网络-B的W和NonW的特征区分度相对较高,仍然存在不同类别的特征交错的情况;相比之下,LSTM网络-C的W和NonW的特征主要分布在两个不同区域,特征交错较少.该现象说明LSTM网络-C能够提高闪电哨声波和非闪电哨声波的区分度,具有较强的闪电哨声波识别能力.

图13 不同LSTM网络隐藏特征的时间序列(a)LSTM网络A;(b)LSTM网络B;(c)LSTM网络C.Fig.13 The plots of the time series of hidden features in four LSTM networks(a)LSTM A;(b)LSTM B;(c)LSTM C.
6 结论
在ZH-1卫星运行过程中,其搭载的SCM每天产生大约10GB的数据量,其中绝大部分是不存在闪电哨声波的数据.如何实现星载实时识别闪电哨声波、传回更有意义的数据、减少存储压力变得尤为重要.鉴于闪电哨声波的频率范围在人耳听觉范围之内,基于语音识别技术的闪电哨声波自动识别已经成为可能.
本文在ZH-1号卫星的SCM数据上开展星载闪电哨声波自动识别算法的探索和研究.根据闪电哨声波能被人耳听到的特性,采用了MFCCs特征提取方式增强闪电哨声波的听觉特征,并采用浅层长短期记忆(LSTM)回归神经网络对特征进行分类,其分类结果在精度,F1socre以及AUC值指标上均高于90%,同时将此方法与基于YOLOv3神经网络的闪电哨声波检测算法进行对比发现:准确率相当,却能够节省150.11 MB的存储空间以及4430 ms的时间消耗,极大地增加了星载实时识别闪电哨声波的可能性.MFCCs是模拟人耳听觉特性所设计的,但由于Hz-Mel频率非线性的对应关系,使得在低频区域使用的滤波器数量较多,分布密集,而中高区域使用的滤波器较少,分布稀疏.使得MFCCs随着频率的提高其计算的精度就随之下降.而闪电会产生强烈的宽带无线电波,尤其是在300 Hz至20 kHz的甚低频(VLF)频带中,因此后续将通过增加中高频的滤波器的方式进一步改善MFCCs特征,从而提高其高频部分的计算精度.
致谢本工作使用了中国国家航天局和中国地震局支持的张衡一号卫星的观测数据(http:∥leos.ac.cn),特别感谢来自应急管理部国家自然灾害防治研究院的张衡一号卫星团队的所有成员为本文研究数据提供的技术服务支持.
