改进两阶段分解的熵变混合短期风速预测研究
2022-03-15李家骅刘宇陆
杨 奎,邱 翔,3,李家骅,刘宇陆,3
(1.上海应用技术大学理学院,上海 201418;2.上海应用技术大学城市建设与安全工程学院,上海 201418;3.上海大学应用数学和力学研究所,上海 200444)
1 引言
风能是一种高效率、无污染的可再生能源,当前能源需求日益增长,风能的开发日益受到重视。由于风速的非线性、间歇性和随机性给风电厂的稳定运行带来了挑战。为了大规模开发利用风电,准确的风速预测对于风能的有效利用有着重大的经济效益[1-2]。
目前,风速预测主要分为物理方法、统计方法、深度学习方法[3]。其中,物理方法基于数值天气预报(NWP)利用温度、气压等气象因素进行周期较长的风速预测,不适用于短期预测[4]。统计方法利用时间序列分析对历史风速数据的研究从而发现内在规律进行风速预测。统计方法有自回归滑动平均模型(ARMA),自回归集成滑动平均模型(ARIMA)等[4],但由于其缺乏非线性拟合的能力,在风速预测方面的精确度不理想,通常需要结合其他预测模型才能实用化。深度学习方法以其特有的强非线性特征提取和拟合能力被广泛运用于风速预测,例如Zhao等人,提出了CEEMD-模糊熵(FE)的二次分解模型,有效降低风速序列的不平稳性,使用深度信念网络预测短期风能,模型预测精度高[6]。Wang等人建立小波变换为数据前处理方法,分解出的高低频子序列分别进行模型预测,以捕获风速中的隐藏信息并增强预测能力[7]。为了能进一步解决风速时间序列的复杂性问题,有效追踪风速信息变化,提高预测精度,混合模型方法逐渐被研究者所关注,成为了解决风速预测问题的主流方法。
本文在以上的研究基础上,在混合模型方法的框架下提出了一种改进CEEMDAN-SE-VMD两阶段分解的CSSA优化LSSVM短期风速预测模型。通过ICEEMDAN分解的子序列,采用SE计算各子序列熵值,熵值近似的子序列重构为新的序列,熵值最高的子序列进行VMD的二次分解,由此得到新的子序列再进行CSSA-LSSVM模型预测,叠加得到最终风速值。
2 具有自适应噪声改进的互补集成经验模态分解
ICEEMDAN可用于前处理和后处理,作为前处理可以处理原始风速序列,作为后处理可以处理误差序列。ICEEMDAN在自适应噪声的互补集成经验模态分解(CEEMDAN)、集成经验模态分解(EEMD)、经验模态分解(EMD)的基础上不仅解决了模态混叠而引起的残留杂散问题,还减少了模式中噪声等问题[8-9],从而使分解更加准确。
基于CEEMDAN的ICEEMDAN的步骤总结如下:
采用EMD计算风速序列I次实验实现xi=x+β0E1(wi)的局部均值以获得第一个残差
r=
(1)
其中β0=β0std(x)/std(E(wi)),M(·)是运算产生信号的局部均值,wi具有零均值和单位方差的高斯白噪声;
当k=1的时,计算第一个模态分量:
(2)
估计第二个残差作为实现r1+β1E2(wi)的局部均值的平均值且得到第二个模态分量
(3)
当k=3,…,K时,计算第K个残差rk=
(4)
重复步骤4)直到第k个。
3 样本熵
样本熵是条件概率的负自然对数,不受时间序列长度的影响,通过计算出熵值的大小来衡量时间序列的复杂度。样本熵值越大,相应序列复杂度越大,反之则越小[10]。样本熵的表达方式如下
SampEn(m,r,N)=lnBm(r)-lnB(m+1)(r)
(5)
式(5)中N是数据长度,m是嵌入维度,r是相似容限,B表示序列自相似度概率。
4 改进的最小二乘支持向量机模型
4.1 最小二乘支持向量机
最小二乘支持向量机(LSSVM)是支持向量机(SVM)的一种改进类型,LSSVM中对二次规划问题的求解转变为线性方程组问题的求解[11-12]。因此,LSSVM求解速度更快,求解精度更高。LSSVM的方法原理如下:假设给定一个数据集G={((xi,yi)|xi∈Rd,yi∈R,i=1,2,…,n)},xi∈Rd和yi∈R分别表示输入向量和相应的输出,所对应的目标函数可以表示为
f(x)=wTφ(x)+b
(6)
式(6)中,w为权值向量,b为偏置项。据结构风险最小化规则,LSSVM的回归问题转化成约束优化问题可表示如下
(7)
式(7)中,C是正则化因子,ξi是松弛变量。式(7)可以通过拉格朗日函数和最优化理论的KKT条件求解,其表达式为
(8)
式(8)中K(xi,xj)为核函数,σ为核宽度,由于高斯核函数(RBF)参数较少,可用最小的代价发挥核函数的性能,选择其可实现特征空间的线性可分。由上述可知,LSSVM的学习能力很大程度上取决于正则化因子C和核宽度的平方σ2。
4.2 混沌麻雀搜索算法优化最小二乘支持向量机模型
麻雀算法(SSA)是由Xue等人在2020年受到麻雀的觅食和抗掠夺行为的启发,提出的一种新颖的群智能优化方法[13]。为避免SSA易陷入局部最优的问题,CSSA利用 Tent 混沌序列初始化麻雀种群,使初始个体尽可能均匀分布,同时引入高斯变异和混沌扰动,对种群出现“聚集”或者“发散”现象时对个体进行调整,帮助个体跳出局部最优,继续在全局范围内的寻优[14]。
CSSA优化LSSVM的正则化因子和核宽度的平方,搜寻全局的最优解,使LSSVM预测误差最小化[15]。合理的参数选择很重要,设定种群数量pop=10,最大迭代次数M=100,搜索维度dim=2,适应度值曲线如图1所示。通过观察曲线,CSSA能在较短时间内搜索到各参数最优解。可见CSSA算法参数寻优能力强,效率高。CSSA优化LSSVM的步骤如下:
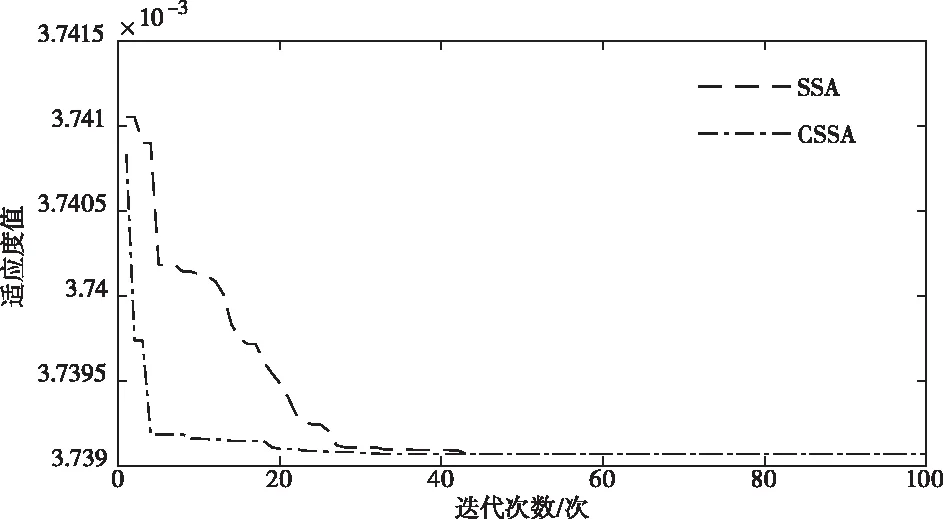
图1 适应度值曲线
1)首先对数据进行归一化操作,并建立训练集与测试集;
2)然后初始化麻雀种群规模,设置最大迭代次数,种群数量,搜索维度和LSSVM的正则化参数、内核参数等相关参数;
3)迭代一次,发现者搜索得到当前种群最好位置源,并计算适应度值。若跟随者搜索到其他位置的适应度值要好于之前的位置,则修正当前位置;
4)引入高斯变异和混沌扰动遍历种群个体置,更新种群当前状态,直到搜索得到全局最优位置,即为参数C和σ2的最优值;
5)判断是否达到了最大迭代次数,如若满足就停止迭代,输出最佳适应度值对应的C和σ2,否则重复步骤4)继续搜索;
6)将最优解C和σ2代入LSSVM模型,进行训练,反归一化得到预测值。
5 ICEEMDAN-SE-VMD-CSSA-LSSVM预测模型
5.1 ICEEMDAN-SE-VMD-CSSA-LSSVM预测模型
为进一步削弱风速的波动性和不平稳性,提高预测精度。本文提出了ICEEMDAN-SE-VMD-CSSA-LSSVM预测模型。预测模型流程如图2所示。模型构建思路具体步骤如下:

图2 短期风速预测流程图
1)ICEEMDAN分解原始风速序列,并用样本熵算法计算各子序列熵值;
2)针对熵值最大的子序列进行VMD的二次分解,且熵值相对近似的进行重构合并新的子序列;
3)分别对二次分解后的子序列和重构后的子序列建立CSSA-LSSVM预测模型;
4)最后将各子序列预测结果叠加,得到最终的风速预测值;
5)模型选择均方根误差(RMSE)、平均绝对误差(MAE)、平均绝对百分比误差(MAPE)来评估预测结果。
5.2 数据说明
本文选择上海市奉贤区气象局在海湾地区(经度为121.47,纬度为30.92),2019年5月所测风速数据,每间隔10分钟收集一次风速值,共收集了1588个数据。其中划分80%数据作为训练集,20%数据作为测试集。为了提高预测精度,我们采用一步滚动预测,通过图3可以观察出,最大风速值为4.52m/s,最小风速值为0m/s,说明了风速有着极强的波动性。

图3 原始风速序列
6 案例分析
6.1 风速序列预处理
本文首先采用ICEEMDAN分解原始风速序列,分解结果如图4所示。然后利用SE计算各子序列的熵值大小,具体结果如图5所示[16]。从图5可知,原始风速分解10个子序列,第1个序列熵值相比较其余9个最大,说明复杂程度高,因此考虑用VMD进行二次分解。第9和第10个序列熵值最小,复杂程度低,对预测模型影响较小,考虑合并重构为新的子序列。由于VMD分解时要人为设定分解个数[17],为了避免出现过分解和欠分解的情况,分解层数与ICEEMDAN分解个数相一致为合理结果。
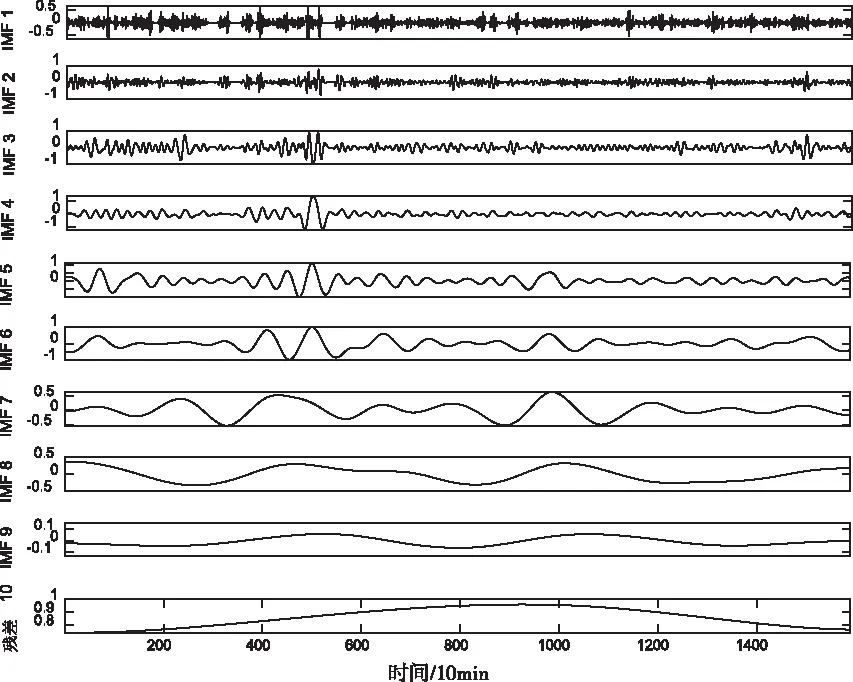
图4 ICEEMDAN分解结果

图5 各子序列熵值
至此,原始风速序列经ICEEMDAN-VMD两阶段分解后共有18个子序列,分解次数越多的子序列意味着发现风变化趋势的可能性越大。为了验证二次分解后的修正效果,其对应的各阶序列概率密度函数(Probabilitydensityfunction)显示了预处理后子序列的统计特性,如图6所示。其中,绝大多数的子序列服从高斯分布,只有极少数不服从高斯分布,说明二次分解对原始风速序列的预处理有着良好的效果,具有针对性的降低风速序列的波动性。

图6 各子序列的PDF
6.2 模型对比与分析
本文提出ICEEMDAN-SE-VMD-CSSA-LSSVM模型与ICEEMDAN-LSSVM、CEEMD-SSA-LSSVM、EEMD-SSA-LSSVM、EMD-LSSVM、LSSVM等经典预测模型进行对比,得到的风速预测结果如图7所示。从图中可以观察出六种模型预测趋势与原始风速序列基本一致,但是所提模型预测效果最佳,能有效应对风速突变的情况,预测性能最好。由表1直观体现本文模型各项指标均最优。

表1 预测性能评价指标

图7 各模型预测结果对比
由图7可知,经典模态分解方法不如在此基础上改进的分解方法预测效果好,单一算法明显不如混合算法预测精度高,EEMD-SSA-LSSVM模型虽加入SSA优化算法,但是预测准确度却比其余三个改进组合模型低,这也是由于EMD本身存在的非自适应弊端。当采用改进的CEEMDAN不添加SSA算法时,预测效果优于以EEMD和CEEMDAN为基础的模型,间接说明采用ICEEMDAN方法可以进一步减少噪声和风速序列不确定性。在此基础上为加强子序列间的相关性,减少计算量,引入样本熵和VMD二次分解,通过改进SSA的LSSVM模型有效提高预测性能,降低误差。
7 结论
本文基于一种两阶段分解的数据预处理短期风速预测方法,提出ICEEMDAN-SE-VMD-CSSA-LSSVM集成模型。通过案列分析对比,得出以下结论:
1)ICEEMDAN和VMD的两阶段分解增强了风速序列局部特征,实时跟踪风速变化信息,引入样本熵降低预测难度,较好的解决了风速序列非线性、不平稳和预测延迟的问题;
2)改进的SSA引入 Tent 混沌扰动和高斯变异,增加了种群多样性,提高了算法的搜索和延拓性能,避免陷入局部最优。增加CSSA对神经网络模型参数的调优,用最优的网络结构预测分析,具有较好的稳定性;
3)组合利用好所提模型各自模块的优点融合性能更好的混合模型,增加了模型的鲁棒性,预测误差小,预测精确度高。
