基于改进LeNet-5的压印字符识别
2022-03-15汪志成何坚强翁嘉鑫
汪志成,何坚强,翁嘉鑫,苗 荣
(1.江苏大学电气信息工程学院,江苏 镇江 212000;2.盐城工学院电气工程学院,江苏 盐城 224000;3.江苏怡通控制系统有限公司,江苏 盐城 224000)
1 引言
在工业生产中,产品上压印字符的内容承载着产品的重要信息[1]。对压印字符采用自动化图像识别替代人工识别有助于提高生产线的生产效率、减少人工成本。压印字符具有立体感,而且器件表面很多场景下并不平整,因此采集的数据质量与采集的平面字符数据质量相比有差距,所以识别难度较大[2]。
对于二维字符的识别,研究学者提出了许多方法[3-4],但是这些方法应用到压印字符识别领域时,并不满足预期,因此在二维字符识别方法的基础上需要进行一些改进。常见的压印字符识别方法主要包括基于支持向量机的方法[5]、基于Gabor滤波器的方法[6]、基于BP神经网络的方法[7]、基于圆周投影和矢量和的方法[8]。上述方法虽然在压印字符识别领域取得了一些进展,但是仍存在识别精度不够高,实际应用困难等问题。
自2012年卷积神经网络在ImageNet(ImageNet Large Scale Visual Recognition Challenge,ILSVRC)大赛中取得压倒性胜利以来,国内外众多专家学者对卷积神经网络进行了研究,因此卷积神经网络飞速发展。其中LeNet-5是一种经典的卷积神经网络[9],它被成功地应用在手写数字识别领域,自LeNet-5被提出以来,已有多种变形版本被开发用以解决车牌识别[10]、交通标志识别[11-12]、人脸识别[13]、图像分类[14-16]等任务。鉴于LeNet-5的强大图像识别功能,本文采用LeNet-5对压印字符进行识别。为满足压印字符识别对准确性、快速性的高要求,对LeNet-5进行了进一步的改进。
2 卷积神经网络
卷积神经网络核心有两点:卷积和池化。
1)卷积层通过卷积核的卷积操作来提取图像的特征,公式如式(1)所示

(1)

以及Relu函数的变式。
2)池化层通过池化操作对特征图降维。应用最广的池化方式有两种:平均池化与最大池化。
平均池化公式如式(2)所示
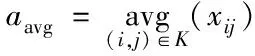
(2)
最大池化公式如式(3)所示
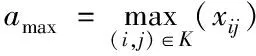
(3)
式(2),(3)中,aavg、amax分别代表平均、最大池化值,K代表池化区域,avg(·)、max(·)分别代表平均池化函数和最大池化函数,xij代表池化区域的第i行、第j列的参数值。
3 改进LeNet-5模型
3.1 传统LeNet-5模型
LeNet-5网络作为卷积神经经典之一,包含七层结构(主要包括卷积层、池化层、全连接层),被成功的应用在支票编码识别,对卷积神经网络的发展具有指导作用,现代卷积神经网络中仍然沿用着它的一些构想。LeNet-5结构如图1所示。但是,压印字符与手写数字相比,识别难度更大,传统网络的轻型结构已经不能满足压印字符识别的高要求。

图1 LeNet-5网络基本结构
3.2 改进LeNet-5模型
本文提出了改进型LeNet-5网络,其主要包括:
1)采用小卷积核。Szegedy等人[17]在文献[17]中提出了小卷积核的构想,并通过实验证明其有效性。小卷积核能够在不影响特征提取的前提下,减少网络模型的参数。
更少的参数可以带来更快的训练速度,并且可以提取更多特征,而卷积过程是不断循环的,这意味着小卷积核方案在多次运算中,可以节省大量的时间。表1是两种卷积核方案的对比。

表1 卷积核比较
2)嵌入Inception-v2卷积模块。Christian Szegedy在2014年提出了被称为Inception的全新卷积结构[19]。本文的方法是使用改进型的Inception-v2模块代替LeNet-5网络结构中的第五层C5,加深网络宽度,提取更多特征。
1)采用全局平均池化。全连接层能够对卷积、池化后的特征进行“投票”分类,但是它的参数量巨大,占整个网络模型的十分之八。而2014年Min Lin提出了全局平均池化的概念[18],实践证明全局平均池化能够精简网络、有效对整个网络做正则化防止过拟合,因此本文采用全局平均池化代替F6全连接层。
3)采用Relu函数作为激活函数。本文采用Relu函数作为主要激活函数。Relu函数的数学公式如式(4)所示

(4)
根据Relu函数特性可知,Relu函数在x<0时硬饱和;当x>0时导数为1,梯度不衰减。这种特性使Relu函数具有单侧抑制性,并且使网络中的神经元具备了稀疏激活性,因此Relu函数能够克服Sigmoid函数的缺点,缓解梯度消失问题,加快模型收敛、提高识别精度。
模型结构如图2所示,模型参数如表2所示。
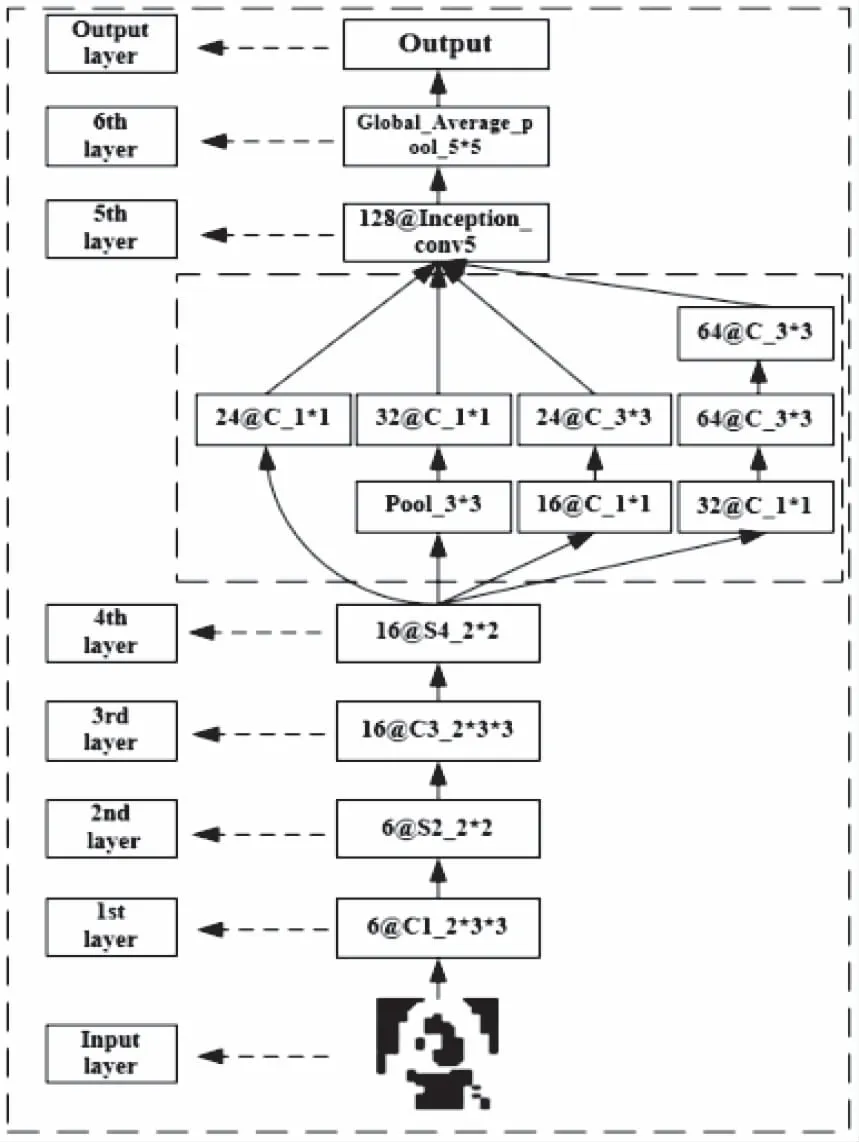
图2 改进LeNet-5网络结构图
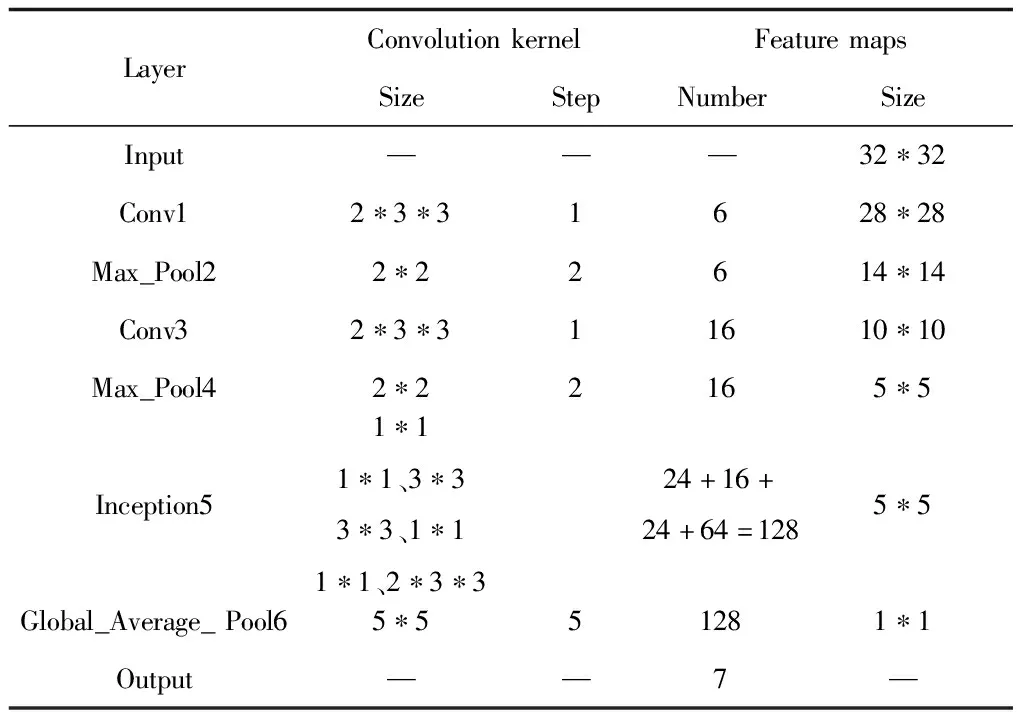
表2 改进LeNet-5网络参数
4 实验结果与分析
4.1 数据集预处理
本文使用的数据集是采用大恒工业相机,在实验室中采集而来,相机型号为MER-500-14GM。因为实验样品有限,采集的压印字符图片样本不足,为了提高本文网络模型的识别精度,本文采用数据增强的方法对数据集进行扩充。扩充后的训练集样本数达到5000张,测试集样本数达到1000张。数据集包含7个字符,分别是0、1、2、5、7、A、M。
压印字符表面并不平滑,存在光散射,并且字符与背景颜色相近,因此需要对原始图像进行预处理才能得到可靠的数据样本。预处理的过程包括:灰度增强、二值化、字符分割等。采集的原始压印字符图像如图3所示。

图3 原始图像
4.1.1 灰度增强
因为金属表面存在光散射的问题,因此采集的原始图像质量受到影响,灰度增强的目的是增强图像的对比度,突出字符的细节,提高识别的成功率。图4是原始图像的灰度直方图。

图4 灰度分布直方图
从图中可以看出图像的灰度值,并没有均匀分布,0-75灰度值几乎为0;75-125存在峰值,灰度值主要集中在这个区间;125-250区间内灰度值少量分布,这就造成了压印字符图像的模糊,给识别带来难度。因此本文将75-255之间的灰度值均匀分布在0-255之间,以此增强原始图像的质量。灰度值平均化后的图像如图5所示。从图5可以看出,灰度值平均化后,干扰区域灰度值增加,与字符区域差异化增大。与原始图像相比,字符特征变得更加明显,有利于接下来的处理。

图5 灰度增强图片
4.1.2 二值化
在经过灰度变换增强后,接下来需要对图像二值化,利用字符与干扰区域的灰度值差异,提取字符特征。本文采用具有自适应性的迭代式阈值分割法,对压印字符图片进行二值化,得到压印字符图像。如图6所示。

图6 二值化图像
4.1.3 字符分割
在得到二值化图像后,只需要对图像进行分割便可得到本文的数据集,本文采用的是连通域分割法,通过扫描图中白色区域确定字符位置。
最终得到的数据集部分样本如图7所示。

图7 可视化数据集
4.2 实验环境与过程
实验在MATLAB2016a环境下实现,计算机处理器型号为I5-9600KF,主频3.7GHz,内存为16GB,显卡为Nvidia1060。
实验开始之前,统一将图片的大小转换为32*32,初始学习率设置为0.008,批训练样本数batch设置为100,迭代次数epoch设置为500,记录每次迭代的识别率并绘制曲线图。识别流程如下所示:
1)经过预处理的压印字符图片,由Iuput layer输入,图片尺寸为32*32。
2)图片输入后,进入1st layer,该层为卷积层。该层的作用是提取压印字符的特征。小尺寸卷积核卷积操作后得到6幅特征图,特征图尺寸为28*28,再经过激活函数添加非线性特征后输出。
3)上一层卷积操作得到的特征图,进入2nd Layer。该层是池化层,作用对输入特征图进行降维,减少参数、降低在识别压印字符时发生过拟合的概率。该层会输出6张特征图,尺寸为14*14。
4)上一层池化操作得到特征图,进入3rd layer。该层是卷积层,作用与1st layer相似,进一步提取压印字符的特征,从此层开始,压印字符图像更加抽象化,如图8所示,人眼已无法分辨图像。该层输出16幅特征图,尺寸为10*10。
5)上一层得到高度抽象化的16幅特征图进入4th layer。该层也是池化层,作用与2nd laye相同,对降维图像降维,最后输出16幅特征图,尺寸为5*5。
6)5th layer是Inception-v2模块层。不同于1st layer和3rd layer的单层卷积结构。Inception-v2层由1*1卷积模块、3*3池化模块、3*3卷积模块、级联3*3卷积模块组成。Inception-v2各模块的通道数分别为24、32、24、64。各模块操作完成后会进行聚合过程,最终输出128张特征图,尺寸为5*5。
7)经过Inception-v2卷积聚合后得到的128幅特征图,输入6th layer,该层是池化层。不同于2nd layer和4th layer,该层池化操作是针对整幅特征图。池化方式是将5*5特征图内的25个参数值求平均值,然后输出。因此特征图尺寸降维为1*1,最后输出128幅1*1的特征图。
8)网络模型的最后一层为Output layer,采用softmax分类器。
部分特征图可视化如图8所示。
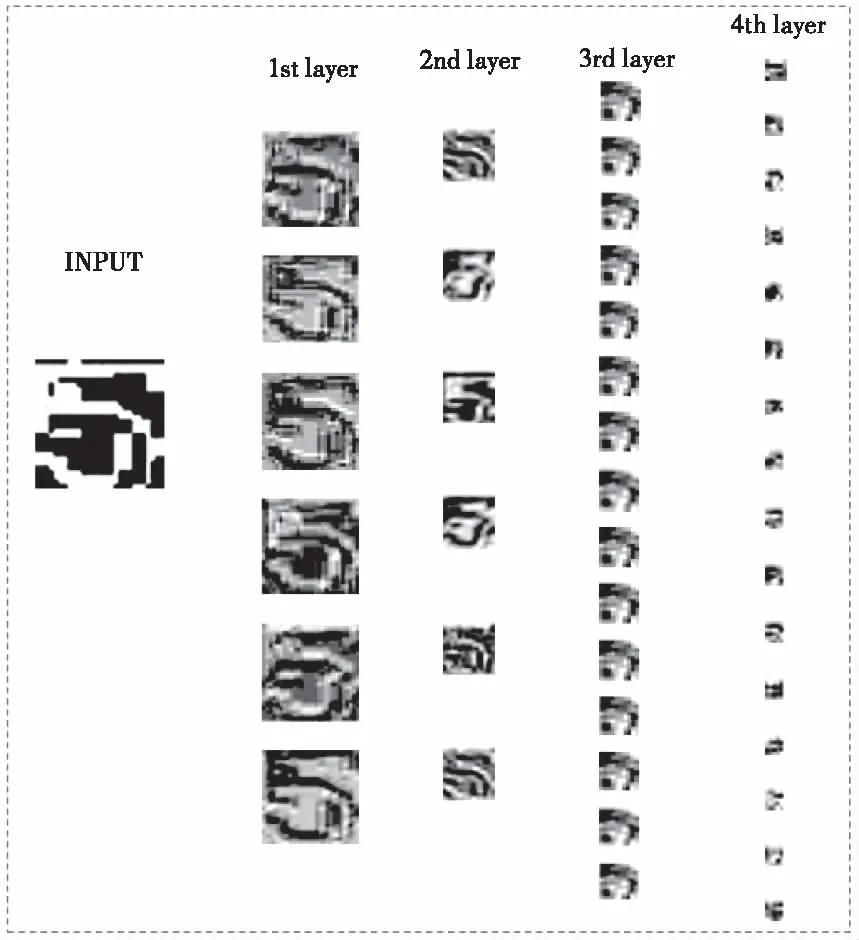
图8 部分可视化特征图
4.3 实验结果对比
4.3.1 改进LeNet-5网络性能对比
传统LeNet-5网络模型识别率曲线如图9所示。迭代500次,在前50次迭代中,曲线波动明显,识别率仅达到约60%,在迭代到100次时曲线趋于平稳,识别率达到94.2%。

图9 传统LeNet-5识别率曲线图
将本文的LeNet-5网络模型,在同一数据集中进行训练,迭代500次,识别率曲线如图10所示。从图中可以看出,在前50次迭代中,识别率快速上升,短时间内达到约96%。在150次迭代后,识别率曲线趋于平稳,达到98.57%。对比图9,10可以看出,相比较于传统LeNet-5网络,改进后的LeNet-5网络的识别率与收敛速度都有了大幅的提高,证明了本文改进LeNet-5网络的优越性。
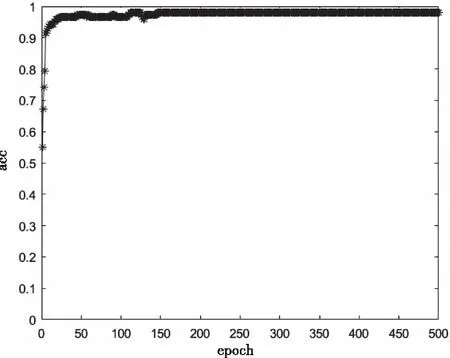
图10 改进LeNet-5识别率曲线
4.3.2 不同学习率对比
表3记录了不同学习率下改进LeNet-5网络的识别精度。从表中可以看出,在其它参数条件不变的情况下,学习率对识别精度也具有较大影响。本文共实验了四种学习率,可以发现从0.001开始,识别精度逐渐提高,但是在0.009时识别精度呈现出下降趋势,因此综合考虑后本文将网络模型的初始学习率设置为0.008。

表3 不同学习率对比
4.3.3 不同算法识别结果
表4为3种算法在同一数据集下的识别率对比。从表中可以看出改进的LeNet-5网络的识别率达到98.57%,与传统LeNet-5、BP神经网络相比,识别率分别获得了4.37%和3.47%的提升。这证明了本文改进方法的有效性,使网络具备了更好的识别、分类能力。

表4 不同方法识别率对比
5 结论
本文针对传统网络识别精度不够的问题,改进了LeNet-5网络,得到了本文网络的模型结构以及模型参数参数。在本文数据集上进行多次实验,证明了本文改进网络的有效性,识别率达到98.57%;在不同的学习率下进行实验,证实了学习率能够影响网络的识别精度,并找到了适合本文网络的学习率;与传统LeNet-5网络、BP神经网络进行实验对比,在参数减少的情况下,识别率提高了3到4个百分点,验证了本文网络的优越性。
