基于深度强化学习实时战略卡牌游戏对战设计
2022-03-15杜智华赖振清
杜智华,赖振清
(深圳大学计算机与软件学院,广东 深圳 518000)
1 引言
目前深度强化学习已经成为机器学习里一个非常热门的研究方向,在2019年的人工智能顶级会议ICLR上,强化学习是最热门的关键词。强化学习的应用非常广泛,在机器人[1]、翻译[2]、智能交通[3]、广告推荐[4]、计算机视觉[5]、自动驾驶[6]等领域都有非常具体的应用。而在这些领域中,强化学习在游戏中的应用最引人注目且成功,从DeepMind公司使用DQN玩Atari游戏,到开发AlphaGo击败围棋世界冠军,还有OpenAI组织使用强化学习在MOBA游戏Dota 2中击败世界冠军队伍等,强化学习一直与游戏相辅相成,互相促进。游戏多样的环境为强化学习提供了很好的训练材料,而强化学习在游戏中的成功应用则给游戏注入了新的活力和更多样的玩法。尽管强化学习在游戏中的应用非常多,在棋类游戏、视频类游戏、MOBA对战游戏中都有非常多的应用,但在即时策略的卡牌类游戏的应用却很少,这类游戏状态空间大,策略具有多样性而且信息并不完全。《皇室战争》就是一款即时策略卡牌游戏,由游戏公司Supercell在2016年推出,发行之后就霸占各个排行榜。游戏开始前,玩家选取8张卡牌进入游戏,在限定时间内通过卡牌拆毁对方防御塔并保护己方防御塔来赢得游戏胜利。由于进入游戏时无法获得对方卡牌的信息,所以这是一款不完全信息的游戏博弈,另外由于放置卡的位置非常多,它还具有状态空间巨大的特点,根据战场局势不同出卡的策略也有很大差异,所以还具有策略多样性的特点。所以将深度强化学习方法应用到《皇室战争》中是个不小的挑战。为解决这些问题,程序在深度强化学习方法的基础上,使用了简化状态空间的方法,使得程序的实现成为可能。
最早引起学术界深度强化学习热度的是2013年的论文《Playing Atari with Deep Reinforcement Learning》[7],将深度强化学习应用到Atari游戏中,效果非常显著,在实验的大部分游戏中,超过了之前的方法。对于将深度学习、强化学习应用到游戏中,最知名、引起广泛大众热度的则是DeeepMind公司开发的AlphaGo[8][9],采用了深度学习方法,在2016年击败世界冠军李世石。其之后的版本AlphaGo Zero则采用的是强化学习,对战旧版AlphaGo的战绩为:100:0。围棋属于完全可观测游戏,双方能获得全部的信息,这与《皇室战争》不同。对于深度强化学习在部分可观测游戏中的应用,有OpenAI开发的用于Dota 2对战的程序,曾击败世界冠军队伍OG,还有知名Atari第一射击游戏《毁灭战士》,在VIZDOOM平台上举行的2016年竞赛中,田渊栋和吴育昕的 F1 团队获得限制赛道冠军[10],2017年竞赛中,Arnold获得了完整版赛道的冠军[11],marvin获得了限制版赛道的冠军,它们都使用了深度强化学习。
2 相关技术介绍
本节先从程序的核心算法Deep Q-learning(DQN)开始介绍,然后介绍程序中用于获得游戏状态的YOLO V3对象检测算法,最后介绍程序中用来识别手中卡牌的CNN图像识别技术。
2.1 DQN算法
DQN算法属于强化学习算法中的一种,所以在介绍DQN算法之前,先来简单介绍下强化学习。强化学习是智能体通过试错的方式进行学习,通过与环境交互获得奖励来指导行为,最终目的是最大化期望累积奖励。强化学习的主要特征有:1反馈具有延迟性,不是瞬时获得;2没有监督,只有奖励;3时间对于数据影响很大;4 智能体的动作会影响之后获得的数据。
强化学习的四个主要要素:动作、状态、策略、奖励,根据这四个要素,强化学习可以解释为在当前状态下,应用策略采取动作来获得当前奖励,并根据得到的反馈,更新策略,不断进行这些步骤从而使长期累积奖励最大化的过程。DQN算法属于强化学习算法的一种,为了得到一个策略使得长期累加奖励最大化,需要评估一个策略的期望回报,因此需要定义值函数,而对于状态非常庞大的环境,精确的值函数定义并不现实,因此DQN采用了神经网络的方法来近似值函数,这就是Q网络。另外,为了更好地训练网络,DQN算法采用了经验回放技术和e-greedy策略。
2.2 YOLO V3对象检测算法
对象检测就是在图像中,识别出物体的种类,以及该物体的坐标。YOLO(You Only Look Once)是一种基于深度学习的目标检测算法,目前已经发展到YOLO v3[16,17],YOLO v3 是目前为止性能最好的YOLO系列的目标检测模型。YOLO的思想是直接对输入图像中的目标位置和目标 类别进行回归预测,这使得YOLO具有更快的检测速 度。在YOLOv3中,直接对图像进行推断,便能获得物体的位置、类别以及物体属于某种类别的概率。YOLO检测网络包含2个全连接层和24个卷积层,其中全连接层,也就是输出层,用来预测图像中物体的位置和物体所属类别的概率值,卷积层则用来提取图像的特征。YOLO将输入图像分成S × S个格子,每个格子负责检测在其中的物体,输出多个物体属于哪种类别的概率以及物体中心点的坐标,然后选择概率最高的那个类别,所以一个格子只能识别出一个物体,即使其中有多个物体,这也是对于密集物体的检测,YOLO精确度不够高的原因。在检测时,YOLO训练模型只支持分辨率为448 × 448的图像,这个分辨率与YOLO的训练图像一致。
2.3 CNN图像识别技术
卷积神经网络(Convolutional Neural Networks,CNN),在深度学习领域占据很重要的位置,对深度学习的发展起到很大的作用,主要用来进行图像处理。
CNN中有三个基本概念:池化、共享权值以及局部感受野。
1)池化。为了简化卷积网络计算的复杂度,采用类似于图像压缩的方法,对图像进行卷积,然后进行下采样,从而减小图像大小。
2)共享权值。在CNN的卷积层中,多个神经元共享同一个权值,从而减少训练的参数量。
3)局部感受野。这一步同样是为了减少参数训练量,采用的方式是将每一个隐藏节点只连接到图像的某个局部区域,而不是图像中的每个像素点。
程序对图像进行分类主要使用的CNN网络为LeNet。LeNet-5[15]是Yann LeCun等人提出的卷积神经网络结构,是最早出现的卷积神经网络之一。LetNet-5虽然比较小,但是包含了深度学习的基本模块:池化层、卷积层和全连接层。LeNet-5包含7层网络,包括三个卷积层,一个全连接层以及两个池化层和一个输入层,输入数据为32 × 32像素的图片。
3 基于强化学习动态对战策略介绍
3.1 游戏背景介绍
《皇室战争》是一款曾经风靡全球的实时策略卡牌手游,游戏过程中,两位玩家通过手中的卡牌,在规定的时间内摧毁比对方更多的防御塔来获得胜利。双方各有两座公主塔,一座国王塔,任何一方摧毁了国王塔都会直接获胜,相当于摧毁了三座塔。该游戏运行在电脑安装的逍遥模拟器中。
游戏开始前,玩家选择8张卡牌进入游戏。游戏开始后的对战界面如图1。图1最大的黑色矩形框圈出来的就是作战区域,所有卡牌释放不会超过那个范围,双方有两座公主塔,一座国王塔。每人手上有四张卡牌,一开始4张卡牌出现的顺序是随机的,当你用完一张卡后,就像栈一样,那张卡会压到最底下,在其余七张卡出现过后再次出现。不同的卡有不同的特性,卡牌之间有一定的克制关系,利用这种关系来获得对战的优势。场上的作战队伍如图1圈出来的作战区域内的两个矩形框。最下方的是圣水数量,它会随着时间而增加,每2.8秒增加一滴,加时赛速度翻倍,最多能保存10滴,使用卡牌则会消耗卡牌对应的圣水。右上角则是剩余时间,如果在3分钟内没有决出胜负,则进入加时赛,加时赛任意一方推掉一座塔即获胜。

图1 游戏开始前选择卡牌界面
3.2 基于强化习动态对战策略框架
程序对战策略是通过强化学习网络来动态实施对战策略,并通过python调用win api操纵电脑进行游戏。实时采集对战训练营动作,经过图像识别和对象检测技术完成实时状态识别和位置识别,然后分析对战训练营状态,并转换为对战策略的动态控制数据,从而控制游戏人物做出与玩家运动相应的动作,并根据游戏规则判断游戏是否结束,更新游戏状态,直到游戏结束。具体算法1如下所示。
算法1 强化学习的动态对战策略

程序流程图如图2所示,其中程序通过YOLO V3对象检测技术以及CNN图像识别技术实时获取游戏状态(图中①截图)。获取游戏状态具体描述如图3所示。
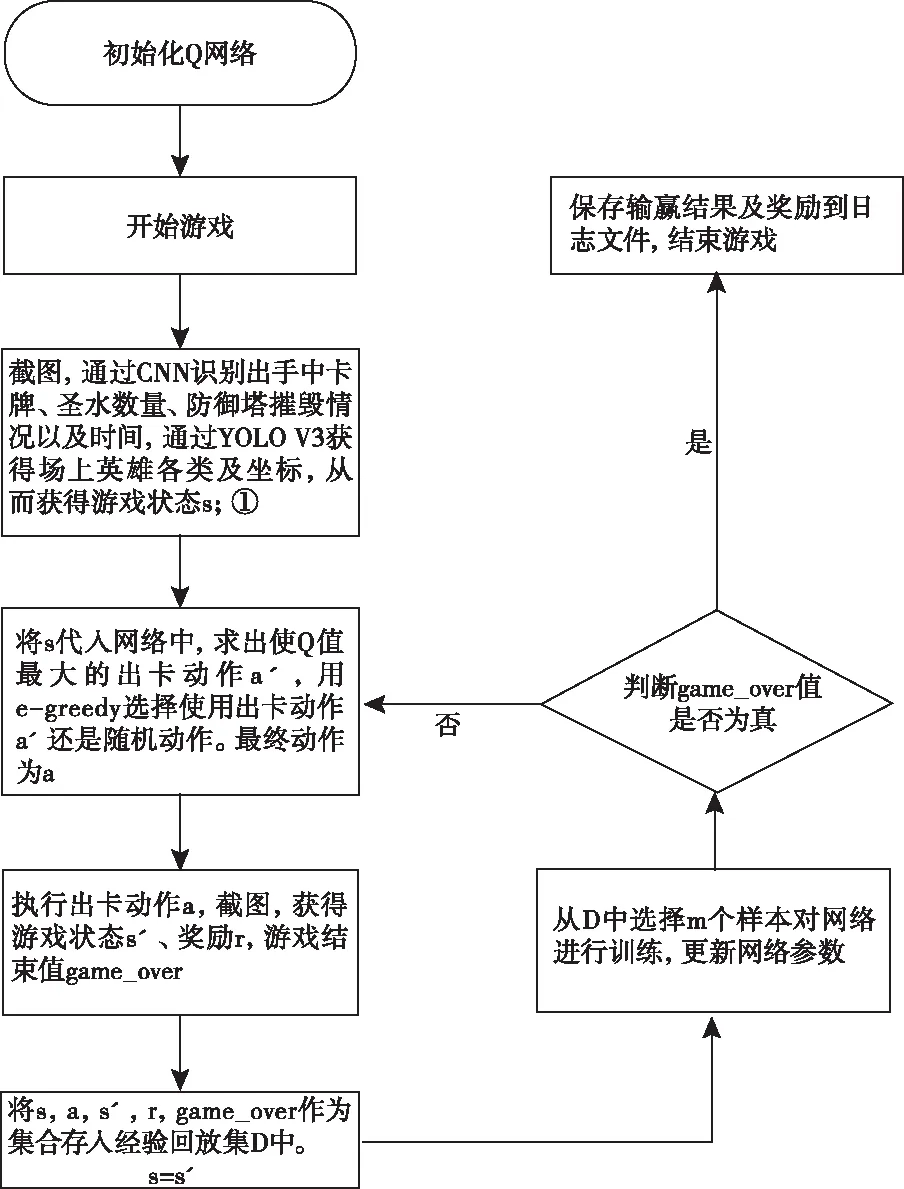
图2 程序流程图
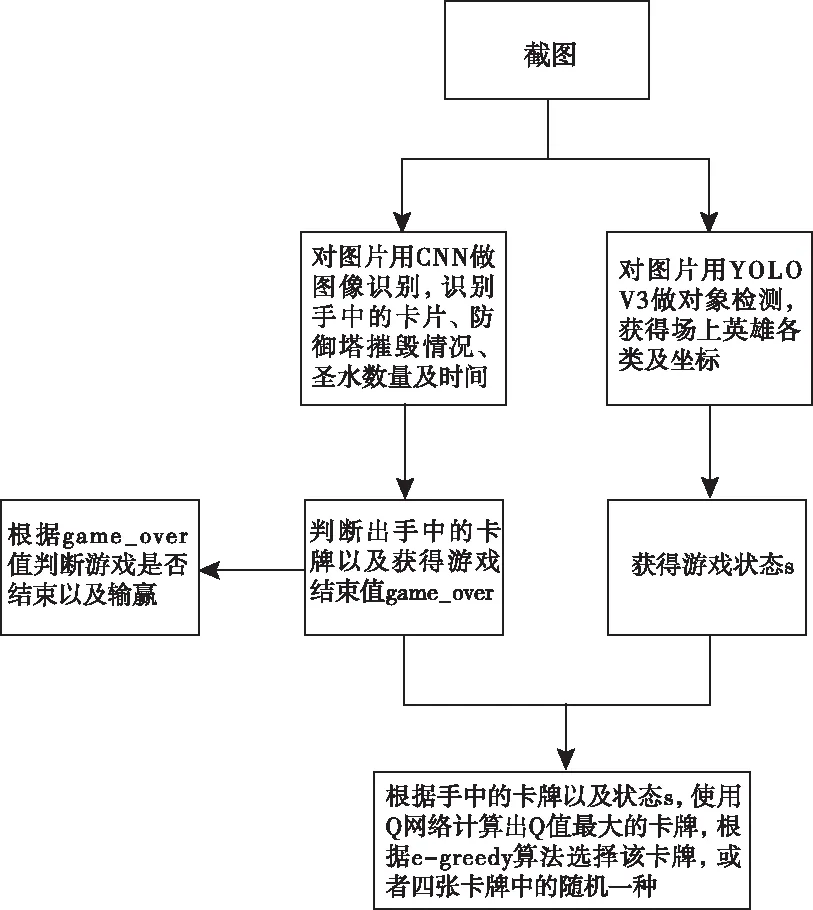
图3 实时获取游戏状态的策略
3.2.1 DQN网络构成及更新
DQN算法使用神经网络来近似值函数,该神经网络就称为Q网络。构成:Q网络由两个隐藏层,三个卷积层以及两个完全连接层构成,输入层为64 x 64 x 4。
更新:每次训练从经验回放集中抽取m个样本{Sj,Aj,Rj,S’j,game_overj},j=1,2,…,m,计算当前网络Q值Yj。如式(1)所示,其中γ为衰减因子,程序中设定为0.9,w为网络参数
(1)
求得当前网络Q值后,使用均方差损失函数,通过神经网络的梯度反向传播来更新Q网络的所有参数w。
3.2.2 出卡选择
首先需要用到3.3节的对象检测技术和3.4节的图像识别技术,来获得场上队伍最多的区域和手中的卡牌是什么。程序出卡选择总共有9种,即出8种卡牌各算一种动作,还有一种动作是不出卡。在圣水数量没有4时,采取的动作是不出卡。圣水数量在4以上时,在当前时刻t,状态St的情况下,获得出手上四张卡以及不出卡对应的网络值,假设网络参数为ω,所有动作为a,网络值函数为Q,求得这5种选择中Q值最高的选择a′,如式(2)所示
a′=argmax(Q(St,a;w))
(2)
然后用e-greedy贪婪法选择动作a′,还是随机的5种动作。e为探索率,随训练场次增加而减小,初始设置为0.5,之后到1000场递减为0.01。程序产生一个0到1之间的随机数k,如果k小于等于1-e,选择动作a′,如果k> 1-e,选择随机的5种动作。
出某张卡确定后,程序需要确定出卡的位置。在获得游戏状态后,程序根据战斗队伍最多的区域,将作战区域划分成30x18块,求出每块区域的英雄数,将卡投放到最多英雄的格子里。
3.2.3 计算奖励
动作a带来的游戏奖励Rstep划分成四个部分:摧毁塔获得的奖励Reto、被摧毁塔获得的奖励Rmto,击杀敌方队伍获得的奖励Rtroop,出卡的奖励Rcard,关系如式(3)所示
Rstep=Reto+Rmto+Rtroop+Rcard
(3)
摧毁塔获得的奖励Reto,由执行动作a后摧毁的塔减去执行动作a前摧毁的塔获得,摧毁一座公主塔的奖励为10,摧毁一座国王塔的奖励为20。Reto和摧毁公主塔数Neprincess和摧毁国王塔数Neking的关系如式(4)所示
Reto=Neprincess× 10+Neking× 20
(4)
被摧毁塔获得的奖励R被摧毁塔,由执行动作a后被摧毁的塔减去执行动作a前被摧毁的塔获得。被摧毁一座公主塔的奖励为-10,被摧毁一座国王塔的奖励为-20。所以Rmto和被摧毁公主塔数Neprincess和被摧毁国王塔数Nmking的关系如式(5)所示
Rmto=-10 ×Nmprincess-20 ×Nmking
(5)
击杀敌方队伍获得的奖励,由执行动作a前敌方场上的队伍,减去执行动作a后敌方场上共有的队伍获得。而摧毁一个敌方英雄的奖励由该卡消耗的圣水决定,比如飞龙宝宝该卡消耗的圣水为4,则摧毁该英雄获得的奖励为4。假设被摧毁的敌方英雄为1到T,英雄消耗的圣水为N1到NT,则击杀敌方队伍获得的奖励Rtroop如式(6)所示
(6)
出卡获得的奖励,由该卡消耗的圣水决定,出一张卡获得的奖励为该卡消耗的圣水的负值,假设某张卡为k,其消耗的圣水数量为Nk,则出卡k获得的奖励如式(7)所示
Rcard=-Nk
(7)
以上均为一步动作的奖励,总奖励为每一步动作奖励的累加。在训练的初期,由于出卡带来的奖励必为负值,而摧毁敌方队伍和防御塔则较为困难,为了减少程序因为出卡而获得更低的奖励导致的消极行为,摧毁敌方防御塔和摧毁敌方队伍获得的奖励都乘以系数1.5,这个系数会在训练过程中逐渐减少,到200场时为1。
3.2.4 判断游戏是否结束及输赢
程序使用3.4节中图像识别技术获得初始时间,以及场上防御塔摧毁情况。获得初始时间,是为了避免网络延迟带来的时间误差,之后由程序自主计时。
判断游戏结束总共分为四部分,一部分是常规时间3分钟内,程序获得状态时,判断场上双方国王塔的情况,任意一方国王塔被摧毁,游戏结束。第二部分时常规时间刚好结束时,任意一方场上的塔数更多,游戏结束。第三部分,若三分钟内游戏未结束,任意一方防御塔减少一座,游戏结束。第四部分,加时赛的第三分钟过去,游戏结束。
判断输赢,在判断游戏结束后返回输赢结果。如果常规时间内游戏结束了,则谁的国王塔被摧毁,谁失败。如果常规时间结束时游戏结束了,则根据双方的塔数判断输赢,塔数少的一方失败。如果加时赛时间内结束,塔数少的一方失败。如果加时赛时间过去了,游戏结束,则存在三种情况,根据最后一刻的状态来判断,如果双方塔数相同,则为平局,如果有一方塔数更少,则失败。
3.3 对象检测
本程序采用YOLO V3对象检测识别场上英雄的位置和坐标。程序通过python截图获得原始图像,使用精灵标注助手标注图片,制作并划分VOC数据集,进行训练。
获得原始图片:这步使用python调用win32 api进行游戏截图,每隔一秒截图,多局游戏,共有1050张截图,每张图片的名称格式为:00xxxx.jpg,6位数字,按顺序编号。为了适应VOC数据集的要求,对图片长宽进行0.4 x 0.4的压缩处理,获得的原始图片如图5所示。

图4 训练集的原始图像
图5 YOLO V3测试识别图片
YOLO V3则直接通过regression一次既产生坐标,又产生每种类别的概率。
训练:训练模型,程序使用的是阿里云GPU计算型 gn4系列NVIDIA M40 12GB的gpu,训练了大概18个小时。使用训练出来的模型进行测试的结果如图6所示,三个英雄都识别正确,速度只需要两三毫秒。
3.4 图像识别
本程序主要使用CNN网络结构LetNet来识别游戏中的时间,防御塔摧毁情况,手中的卡牌以及圣水数量等四种内容。这四种内容使用的网络结构一样的,训练次数均为1800次,只有原始数据和种类有所不同。LetNet网络使用keras实现,包括了三个模块:卷积层,池化层,全连接层。网络包含14层,其中输入层为32×32×3。
识别防御塔情况:识别防御塔情况,对于整个程序来说,是比较重要的工作,因为胜负判断就是靠防御塔摧毁情况来判断的,而且防御塔摧毁的奖励在设定的奖励计算中也占很大的比重。原始图像如图6所示,总共有5张,分别是敌方国王塔、敌方公主塔、防御塔被摧毁、己方国王塔和己方公主塔。公主塔和被摧毁的塔只算一次,是因为对于同一方,公主塔的形状是一样的,所有塔被摧毁后也是一样的。

图6 用来训练识别防御塔情况的原始图像
识别手中卡牌:识别手中卡牌,在游戏中同样有重要作用,因为除开获得游戏状态的各种工作,程序的核心就是出手中的卡牌,所以能准确识别出手中的卡牌很重要。需要识别的卡牌总共有8张,分别是飞龙宝宝,炼狱飞龙,矿工,猎人,公主,皇家幽灵,骑士,黑暗王子。提供的原始图片如图7所示。

图7 训练识别手中卡牌的原始图像
识别圣水数量:识别圣水数量,是为了判断是否有足够的圣水出某张卡。提供的原始图片如图8所示。

图8 训练识别圣水数量的原始图像
4 实验结果与分析
《皇室战争》中训练营总共有14种,训练营难度会根据玩家的杯数逐渐提高,其中4000杯内的玩家,进入前十二种训练营,4000杯到4300杯的玩家进入训练营格拉维,4300杯以上的训练营齐达难度最高,拥有无限圣水和满级传奇卡。本程序对战的是训练营格拉维,难度仅次于最强训练营。《皇室战争》中,卡牌等级和国王塔等级对对战都有很大影响,等级越高越强,程序使用的卡牌等级和训练营相比基本差两级,国王塔则差三级,所以程序对训练营开始就处于很大劣势。
4.1 程序训练情况
本程序记录在日志文件中的对局共有2300场对局,如图9是每百局程序的胜场,x坐标对应的是坐标值100的场次,y坐标为胜场数,可以看到程序从一开始0胜场到500场开始出现胜场,然后胜场数一直提升,到1500场后,胜场基本稳定,每百场18胜场到19胜场之间。如图10则是每百局程序的平均奖励,x坐标对应的是坐标值 100的场次,y坐标为奖励数,从-42.2到后来基本稳定在-10多。单局的奖励为全场摧毁对方防御塔以及作战部队的奖励加上被摧毁防御塔及出卡的负奖励,奖励越高,说明程序在对战中表现越好。由图10可以看到奖励逐渐提高,到稳定在-10左右,这个曲线和胜场曲线相似,对局中的表现会体现在游戏的输赢上,而最终奖励依然为负数,说明程序的表现还是低于训练营。

图9 程序每百局胜场数
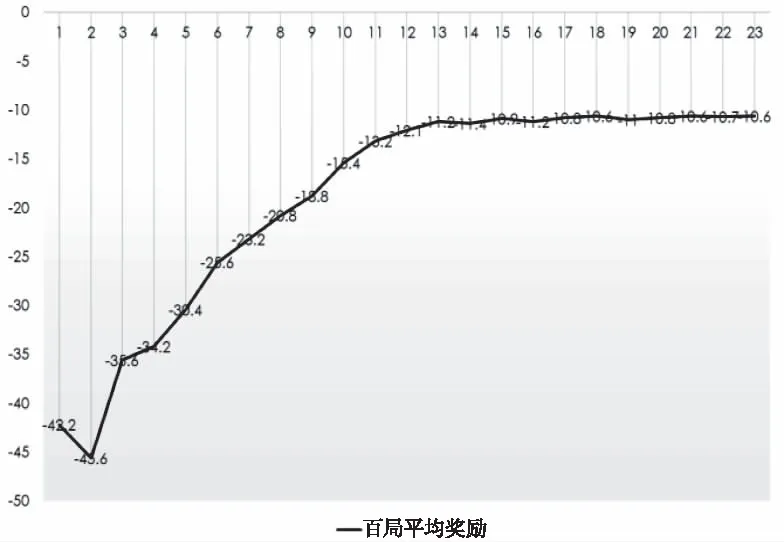
图10 程序每百局平均奖励
4.2 与普通玩家的对比
作为程序训练情况的对比,一共安排了两名测试人员进行了测试。测试人员1是一名游戏胜场648场,最高奖杯数为4711的玩家,测试人员2则是游戏胜场475,最高奖杯数为3973的玩家。如表2,是测试人员各自用同样的卡组与同样的训练营对战了100局之后的战绩与程序2200场——2300场战绩的对比。可以看到程序最后的战绩比测试人员都更好,胜场比测试人员1高38%,比测试人员2高100%。

表2 普通玩家战绩与程序战绩对比
5 总结
本程序使用强化学习算法,使程序在多次游戏中不断完善自己的出卡策略,提高游戏水平。使用CNN来识别卡牌、防御塔以及时间,通过YOLO V3来获得场上英雄坐标,从而获得游戏状态,通过投放卡牌到最多卡牌的区域来减少动作空间。从结果来看,由于卡牌等级被压制,后期对战训练营的战绩胜率在18%左右,超过了4000杯测试玩家的水平。后续为进一步提高程序胜率,需要进一步识别所有卡牌,并进行玩家间的排位,从而达到最高的段位,并能够进行多种卡牌的组合,从而获得多套强势卡组。
