一种改进窗函数的低时延语音增强算法
2022-03-15吴君钦王迎福
吴君钦,王迎福
(江西理工大学信息工程学院,江西 赣州 341000)
1 引言
随着现代通信技术的不断演进和突破,人们对于其在智能设备上的语音质量和清晰度的需求也极大的提高了。在实际中,信号在通信设备中进行传递时往往会受到来自周围情景中各种干扰源的污染,从而导致终端收到的源信号出现变形或失真。这一问题在一些室外的工作场所或者嘈杂的工厂环境中是普遍存在的,而语音增强技术使其获得极大的改善。语音增强技术是指发送端发送的语音信号在传递过程中被周围环境中各种噪声、干扰污染或者是覆盖后,能从污染后的语音信号中分离出所需要的纯净语音信号,从而达到有效抑制或减弱噪声干扰的技术。语音增强技术属于语音数字信号处理中的一个预处理模块,对于提升语音总体质量和可识别度等方面起到了不可忽视的作用。其主要作用为:尽可能提升语音信号的总体质量和可辩别度。语音增强已经应用在很多领域。例如:残疾人助听设备、多说话人识别、微信、QQ等语音通话、智能手机通话、语音识别等。在这些模块中,语音增强技术是整个系统至关重要的一部分,其结果直接关系到最终语音识别的质量和准确性。因而,语音增强技术是现代语音通信系统中的关键技术之一。
近年来,各国的学者和研究者根据现有的非负矩阵分解(Non-negative Matrix Factorization,NMF)算法,推出大量以NMF为理论基础的语音增强算法并在这些算法基础上进行改进和优化。然而在进行问题的目标函数的确定时,大部分的NMF增强算法采用了Lee等人[1]提出的乘性迭代更新算法,这样导致算法产生的结果并不理想。为解决这一问题,稀疏和卷积非负矩阵分解方法[2]先后被提出来,从而增加了字典学习的速度和字典的精确性。A.T.Cemgil将NMF算法与统计模型相结合,提出了贝叶斯非负矩阵分解(Bayesian NMF,BNMF)[3]。N.Mohammadiha等[4]将该算法结合到语音增强技术上以及进行改进[5][6],均获得了较大的提升。
NMF从非负数据中学习基于部分的表示形式。对于语音信号,通常将NMF使用幅度谱图进行表示,以便学习并捕获典型声源模式的频谱或者时间谱原子。在语音增强的背景下,必须确定哪些原子属于目标说话者,哪些原子属于干扰。基于监督的基于模型的方法通过独立的预学习每个声源的字典来解决此问题,从而允许实时操作,因为在运行时仅需要当前或者是之前的频谱帧进行实时操作。基于模型的无监督方法利用基础源的空间分布来学习没有先验信息的单个源字典,这些单独的词典没有语音和噪声的单独数据集的形式。这些无监督方法无法实时操作,因为空间信息不适用于一些未知的场景。基于此,需要对语音和噪声信号的字典原子进行更深入的研究。
2 非负矩阵分解和广义互相关声源定位法
在本节中,介绍了GCC-NMF增强算法的基础,即NMF字典学习算法和广义互相关(Generalized Cross Correlation,GCC)声源定位方法。
2.1 非负矩阵分解
当将NMF应用到音频信号中时,假设输入语音信号的幅度谱为|Vft|,f和t分别表示频率和时间。NMF将频谱分解为两个非负矩阵:字典矩阵Wfd(见图1(a)),其列包含的原子谱由d表示和一组对应的激活系数矩阵Hdt,使得|V|=WH,例如NMF字典原子(见图1(b))。输入语音信号的幅度谱|Vft|的每一列,即每一帧t,可以近似为NMF词典原子与来自H对应列的激活系数的线性组合。对于本文研究的立体声谱图,沿时间轴将左右输入声谱图连接起来,V=[VL|VR],即对于大小分别为F×T的左声谱图和右声谱图,连接矩阵的大小为F×2T。这样,生成的NMF词典原子仅捕获谱信息,而在相应的激活系数矩阵中捕获的左右声道之间的差异为H=[HL|HR]。

图1 NMF在混合语音信号中学习的词典
在传统的NMF中,字典学习和激活系数推断是通过随机初始化字典和激活系数矩阵,然后根据乘法更新规则迭代更新它们来同时进行的。更新规则收敛到β散度重构代价函数的局部最小值,其一般情况是广义Kullback-Leibler(KL)散度,定义如下
D(|V|,Λ)=|V|(log|V|-logΛ)+(Λ-|V|)
(1)
其中,Λ=WH为重构的输入矩阵V。从而得到KL散度的代价函数更新规则如下
(2)
(3)
其中,矩阵的次方、除法和Hadamard乘积是逐元素计算的,而I是全值为1的矩阵。NMF字典原子通常在每次更新后进行标准化,并且其激活系数会相应缩放。
2.2 GCC声源定位方法
在有噪声、干扰和混响的情况下,GCC是一种稳健的声源定位方法。GCC函数利用任意频率加权函数扩展了频域互相关定义,从而在计算互相关时提供了对信号组成频率相对重要性的控制,GCC函数定义如下
(4)
其中,Re为取实部运算符,ψft为任意频率加权函数,VLft和VRft是通过STFT计算得到语音信号的左右复制的时频变换,*是复共轭,f、t和τ分别表示频率、时间和到达时间差(Time Difference of Arrival,TDOA)。

(5)
然后,可以随时间合并生成GCC-PHAT相位频谱图,其中3个最高峰分别对应于3个源的TDOA估计,用蓝色虚线标识,如图2所示。

图2 说话人混合信号的源定位
时间t(s)到达时间差(s)
3 基于GCC-NMF的语音增强算法
在本节中,首先介绍了GCC-NMF增强算法和其二进制系数掩码方法,并根据其空间来源进行分组,然后独立地重建每组原子。此外,提出了一种替代的软掩码方法,并介绍了字典预学习、激活系数矩阵以及在线定位方法。
3.1 GCC-NMF
根据2.2小节知识,考虑到GCC定义中的任意频率加权函数ψft,以及单个NMF词典原子本身就是频率的非负函数这一事实,可以构造一组原子特定的GCC频率加权函数,定义如下
(6)
这样,对于给定的原子d,频率将根据其在原子中的相对大小进行加权。然后,将所得的原子特定的GCC-NMF相位谱定义如下
(7)

(8)

(9)
该掩码消除了干扰产生的原子,从而将目标语音从混合信号中分离出来,然后通过类似于维纳滤波器对输入信号随时间变化来估计复杂目标的频谱。该滤波器在频域中被构造为目标估计频谱和混合信号估计频谱之间的比率,即语音信号的幅度输入频谱|Vcft|的重构估计。然后,将滤波器与复杂的输入频谱图Vcft相乘,即
(10)
Λcft=∑dWfdHcdt
(11)
(12)

3.2 系数掩码
在时频域中,软掩码[9][10]替代二进制掩码是提高语音增强性能的常用技术。在本节中,提出了一种软掩码替代方法,用来替代式(8)中的二进制激活系数掩码方法。该NMF激活系数软掩码函数定义如下
(13)

3.3 字典预学习
使用NMF进行有监督语音增强的一种典型方法是预先学习一对NMF字典:一个使用单独的语音信号作为NMF字典进行预学习,另一个使用单独的噪声信号为NMF字典进行预学习。对于给定的测试信号,在保持字典不变时,推测出两个字典的激活系数。通过从包含单独语音和噪声信号中的数据集中预学习单个NMF字典,并将这种方法推广到无监督的情况。
与有监督方法相反,由于无需使用任何先验知识就可以为语音和噪声信号学习单个字典,因此该方法是纯无监督的。由于单个预学习的NMF字典同时包含了语音和噪声信号的特征,然后根据式(8)和(13)将各个NMF字典原子在每个时间点与目标说话者或者干扰相关联。这种方法允许单个NMF字典原子在不同的时间点对语音或噪声信号进行编码,从而克服了有监督情况下单个字典原子只能编码单个源的限制。因此,字典预学习方法能够在这些条件下适用,从而避免了当训练和测试数据源自不同数据集时引起的不匹配问题。
3.4 激活系数
通过随机初始化激活系数向量并根据式(2)进行迭代更新,可以逐帧推导出输入混合语音信号预学习字典的激活系数。由于估计目标信号为W(H⊙M),估计干扰信号为W(H⊙(1-M)),因此可以得到估计混合信号为WH(目标和干扰信号之和)。因此,混合信号的系数矩阵H与掩码系数矩阵M的估计是相互独立的。然后,系数掩码根据其TDOA估计值抑制属于噪声信号的字典原子。在实验中证明:将激活系数H去掉,可以实现更好的性能。在这种情况下,可以将激活系数矩阵Hdt替换为单位矩阵,从而将式(10)定义的类似维纳滤波器简化为如下形式
(14)
3.5 在线定位

(15)
其中,L是滑动窗口的大小。窗口大小的影响可以实时交互地探究,其中较小的窗口可跟踪源位置中更快的变化,但可能会在语音短暂停顿期间切换到背景噪声,而较大的窗口会在追踪更多缓慢的移动扬声器时表现更加稳定。
4 基于低延迟的GCC-NMF语音增强算法
由于以短时傅里叶变换(Short-Time Fourier Transform,STFT)为基础的语音增强算法会产生固有的算法等待时间,即窗口大小加跳数,这与计算机的处理速度无关。在充分考虑频谱分辨率和窗口大小的情况下,包括在线GCC-NMF在内依赖高频谱分辨率的算法通常具有大于64ms的延迟。但是,这样的高延迟对于包括助听器等的语音增强的许多实际应用来说容忍度很低。因此,本节提出了将非对称STFT窗口化方法与在线GCC-NMF语音增强算法相结合,从而将算法的延迟大大降低。
4.1 STFT和低延迟
STFT以帧为单位处理语音信号,即较短时间的语音信号重叠段,其中在计算其傅里叶变换之前,将每一帧信号都乘以分析窗口,即对信号加窗。而帧的重新合成则是通过对加窗后的帧进行傅里叶逆变换,再将所得样本乘以合成窗口并通过重叠相加(Overlap-Add,OLA)方法[12][13]合并相邻帧来实现的。如果帧变换具有恒定的重叠相加(Constant Overlap-Add,COLA)特性,即如果分析和合成窗口矩阵点积的重叠和不随时间改变,则可以实现理想的帧重构。常用的分析和合成窗是逐点平方根的周期性汉宁窗,其中帧大小的周期性汉宁函数定义如下
(16)
其中n表示窗函数的长度,N表示窗口大小。以上通过OLA重新合成的重叠信号加窗过程产生了等同于窗口大小N的延迟LOLA。为了保持实时性,包括傅里叶变换及其逆变换在内的所有处理都应在单个帧内提前R进行,从而使得系统总共产生了N+R的延迟。例如,对以16kHz采样的输入语音信号进行GCC-NMF语音增强,其窗口大小为1024个采样和256个采样超前帧,将导致系统总共产生80ms的延迟。
减少实时GCC-NMF语音增强系统延迟的一种简单方法是直接减小窗口大小N。但是这种方法不仅会降低频谱的分辨率,而且会使得客观语音增强质量和清晰度显著降低。因此,本文提出了一种基于非对称STFT窗口化方法来减少GCC-NMF系统的延迟。
4.2 非对称的STFT窗口化方法
与传统的具有相同周期的对称分析和合成窗口不同,非对称窗口能够通过将长的分析窗口与短的合成窗口相结合来同时实现高频谱分辨率和低延迟。本文使用的非对称窗口方法源自于文献[14]的改进,其它非对称窗口化方法可以参考其它文献[15]-[17]。
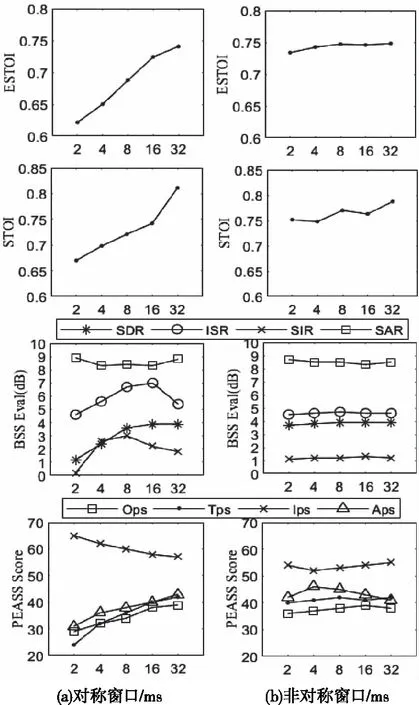
对于给定的帧大小N,非对称分析和合成窗口的设计应满足它们的乘积是大小为2M 图3 帧长为N的对称和非对称STFT窗函数 (17) (18) 这些窗口函数相对于分析窗和合成窗乘积得汉宁窗的中心分为两部分,即n=N-M。在N-M的右侧范围内,分析和合成窗均由大小为2M平方根的汉宁窗口的右半部分组成。在左侧范围内,分析窗口由大小为N-M的汉宁窗口的左半部分组成,而合成窗定义为分析窗与乘积汉宁窗两者的比值,其范围限制为N-2M≤n 在本小节中,使用语谱图分析法、盲源分离(Blind Speech Separation,BSS)评测[18]、声源分离的感知评价方法(Perceptual Evaluation for Audio Source Separation,PEASS)[19]、短时客观可懂度(Short-Time Objective Intelligibility,STOI)[20]、扩展短时客观可懂度(ExtendedShort-Time Objective Intelligibility,ESTOI)[21]作为客观语音评测指标对该算法在语音质量和清晰度方面进行评估,并将所提出的无监督的低延迟语音增强算法与其它无监督和半监督方法进行对比,然后探究了合成窗大小对对称方法与非对称方法的影响。 4.3.1 实验参数设置 在本小节中,在噪声开发数据集中的SiSEC 2016语音集[18]上评估实时GCC-NMF算法,该语音数据集包括语音和实际背景噪声的双通道混合信号,麦克风相隔8.6cm。在CHiME 2016开发集的一个子集[22]上进行无监督的词典预学习,并在单个麦克风的语音和背景噪声信号之间平均分配随机选择的帧。SiSEC和CHiME的采样率均为16 kHz,使用STFT具有1024个采样窗口(64 ms),采样大小为256跳(16 ms)以及平方根汉宁的分析和合成窗函数的对称窗口情况。默认的GCC-NMF参数设置为字典大小为1024,NMF字典预学习更新次数为100,运行时NMF激活系数推断更新次数为100,TDOA样本数为128和目标TDOA窗口大小为总范围的3/64,即6个TDOA样本。 语音增强质量使用PEASS方法工具包和BSS Eval性能测量工具进行量化。PEASS是一种基于感知的方法,与BSS Eval提供的基于SNR的传统指标相比,它与主观评估的相关性更好。这些开源工具包都提供了总体增强质量,目标保真度,干扰抑制和伪像的度量,这些分数越高越好。对于PEASS,分别将与总体感知有关、与目标感知有关、与干扰感知有关和与伪像感知有关的值分别命名为总体感知分数(Overall Perceptual Score,OPS)、与目标相关的感知分数(Target-related Perceptual Score,TPS)、与干扰相关的感知分数(Interference-related Perceptual Score,IPS)、以及与伪像相关的感知分数(Artifacts-related Perceptual Score,APS),在BSS Eval情况下分别命名为信号失真率(Source to Distortion Ratio,SDR)、噪声抑制比(Interferencesto Source Ratio,ISR)信号干扰率(Source to Interferences Ratio,SIR)、和信号伪像率(Sources to Artifacts Ratio,SAR)。语音清晰度通过STOI和ESTOI度量进行量化,其中相比STOI,ESTOI与听力测试分数相关性更好[23]。 4.3.2 实验结果分析 1)非对称窗口和NMF字典原子 在图4(a)中,使用了不同延迟的对称STFT窗口方法学习NMF字典原子。随着窗口尺寸的减小,字典原子的频带越来越宽,并且使用更长周期的窗口捕获的谱细节也会丢失。与传统的加窗方法相反,非对称加窗可以保留较长的分析窗口,同时减小了合成窗口的大小。随着合成窗口大小2M的减小,分析窗口的大小固定为帧大小N,其形状越来越接近理想化。图4(c)显示使用了不同延迟的非对称窗方法学习的NMF字典原子。学习的NMF字典原子保留了谱细节,而与合成窗口大小无关。因为在所有情况下均使用了相同的训练数据和随机种子,从而使得所得的字典原子在所有算法的延迟中非常相似,在学习的NMF字典原子中的细微差异是由不同的分析窗口所产生的。 图4 NMF字典和对应的STFT分析窗口 2)非对称窗口以及语音增强质量评估 在表1、2和3中,使用ESTOI、PEASS、STOI以及BSS分别对所提出来的方法进行评估,并将该方法与其它语音增强算法的在相同的数据集得到的测试结果进行比较。其中,实验数据都是以平均分离分数±标准偏差呈现,从而确保实验结果的相对稳定,数据集取自SiSEC dev1实时语音记录数据集。除了文献[28]提出的方法外,所提出方法在各项性能上均由于其它方法,这些方法大都依赖于监督学习或不适合在线环境。略优于所提方法的是一种使用区域增长排列对齐方法的频域盲源分离技术。尽管作者表示该方法具有在线运行的可能性,但并未提供在线方法的实现。而相对于传统的对称窗口化方法,本实验采用的是改进的非对称汉宁窗,所提方法在语音增强质量和可懂度两项指标上均略好于对称窗方法,且其各项评测值相对更加稳定,因此可以说所提出STFT非对称窗口化对GCC-NMF方法在性能上是有所提升的。 表1 PEASS评测值 表2 STOI和ESTOI评测值 表3 BSS评测值(单位:dB) 3)合成窗大小对增强性能的影响 在图5(a)中,给出了对称窗口情况下客观语音增强质量和可懂度度量与算法延迟之间的关系。注意到,总体质量得分以及清晰度得分都随着窗口尺寸的减小而降低,而对于小于8ms的窗口,PEASS总体性能会显着下降。这很可能是由于语音和噪声源与图4(a)中所示的带宽较大的NMF字典原子可分离性降低,从而导致所得在线GCC-NMF语音增强的质量下降。同时还注意到干扰抑制与目标保真度和伪像PEASS分数之间存在重大折衷,其中较小的窗口尺寸会导致干扰抑制增加,但代价是明显的伪像和较差的目标保真度。在图5(b)中,展示了在与上述相同的条件下非对称加窗方法的延迟的影响。这里的分析窗口在16 kHz(64 ms)时固定为1024个样本,而合成窗口的大小则从512到32个样本(32到2 ms)变化,在每种情况下,每个窗口使用的合成窗口都有75%的重叠部分。从图中可以看到,对于不同的合成窗口大小,所有评测值都保持相对恒定,即使对于低至2 ms的延迟也是如此。这些结果表明,提出的非对称加窗方法是一种可行的解决方案,可将GCC-NMF算法的延迟降低到远低于听力设备所需阈值,同时还能保持较高延迟的对称加窗方法的质量。因此,该方法能小幅提升传统对称窗法的性能,还能降低算法的延迟。 图5 不同的合成窗大小对语音增强性能的影响 此外,在图6中,分别给出了对称加窗法和非对称加窗法结合GCC-NMF进行语音增强后的语谱图,相比于源信号,增强后的语音信号大大减弱了静音段和帧间的底噪干扰,同时保留了高频段的有用信号成分,实现了源语音信号的降噪和增强。 图6 源信号与增强后的语音信号语谱图 本文提出了一种将广义互相关方法与非负矩阵相结合的两通道语音增强算法。该方法通过对输入混合信号进行字典预学习,然后随机初始化激活系数向量并进行迭代更新,从而可以逐帧推导出输入混合语音信号预学习字典的激活系数。此外,使用了最大池化广义互相关相变技术进行在线目标定位,不仅确保了算法的实时性,而且极大地保证了重构后的语音质量和辨识度。在此基础上,针对以STFT为基础的语音增强算法会产生固有的算法延迟,提出了一种非对称短时傅里叶变换的窗口化方法代替传统的对称窗方法,该方法使用较长的分析窗和较短的合成窗相结合来实现算法的低时延。实验证明,该算法能将固有算法时延降低至2ms而不会降低语音的质量和清晰度。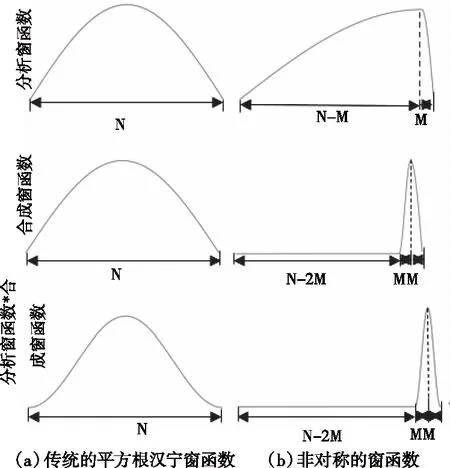
4.3 实验测试与结果分析





5 结论
