机器学习对上市公司年报错报的识别研究
——财务重述预测的视角
2022-03-15曾庆超许诺
| 曾庆超 许诺
一、引言
财务报告作为上市公司对外披露信息的主要载体,是投资者获得公司信息的重要途径,也是审计师出具审计意见的重要参考。错报导致的财务重述,是自愿或被审计师及监管者责令进行修正的一种事后补救行为;造成严重负面影响的财务重述主要是由于收入确认不恰当、成本费用不真实等原因所导致的,这些行为本身就是实现盈余管理目标而运用的具体方式,反映了上市公司前期发布的盈余信息不真实,存在误导投资者决策的错误。根据美国会计总署(GAO)的研究报告,在1997到2002年间,由于企业发布关于盈余的重述公告,给投资者造成了1千亿美元的损失。错报导致的重述不仅使财务报告的可靠性受到质疑,损害了投资者的利益,也意味着以前年度财报是低质量的,从而加大注册会计师审计当期财报的风险。之前研究表明,在财务重述的样本中,调减盈余的样本占到了七成左右;因错报导致的重述表明会计系统存在问题(甚至是经营管理问题),导致预期的未来现金流下降,并且暗示管理层试图通过粉饰来掩盖收入下降问题,因而财务重述通常会向投资者传递消极信号,从而造成更大的市值下降,使得市场反应显著为负。因此,研究错报及其导致的财务重述具有现实意义。现有研究从公司业绩、股权结构、治理结构等方面分析了财务重述公司的特点,监管部门为了保障上市公司会计信息披露的质量,对其年报强制执行外部审计,并陆续出台了中国注册会计师审计准则,以降低审计风险,提高审计质量。然而本文的财务重述年报样本中,九成被出具了标准无保留审计意见(即错报在当年未被识别出来),这说明随着上市公司的盈余管理手段愈发隐蔽,单纯依赖传统的风险评估方法可能难以有效识别错报风险。
机器学习是当下被广泛应用的信息技术,它让计算机能够自动地从某些数据中总结出规律,并得出某种预测模型,进而利用该模型对未知数据进行预测。分类是重要的机器学习方法,其目的是从给定人工标注的分类训练样本中学习一个分类模型,面对新数据,根据这个分类模型将其映射到给定类别的某一个类中,甄别上市公司财报是否存在重述的可能,比较适合采用分类方法中的二分类方法。目前运用较广泛的分类方法有极限梯度提升树(xgboost)、神经网络、随机森林(random forest)、K近邻(K-nearest neighbor)、支持向量机(support vector machine)、朴素贝叶斯(naive bayes)等。
错报与财务重述具有因果关系:后期出现的财务重述,很大程度上由于当期的错报未被识别;若能预测后期将发生财务重述,说明当期财报很可能存在错报。因此本文的研究逻辑是,通过机器学习预测财务重述的能力反映其识别错报的能力,研究的主要贡献有:第一,在统一的输入样本基础上,通过与logistic回归比较,实证检验了极限梯度提升树、神经网络、随机森林、K近邻、支持向量机、朴素贝叶斯等机器学习方法在预测上市公司年报调减盈余的财务重述方面的良好效果,从而证明机器学习应用于识别上市公司年报错报的可行性。第二,检验了现有文献关于财务重述公司特征的甄别能力,发现营运能力、盈利能力、流动比率与股权集中度等特征对上市公司年报调减盈余的财务重述的预测起到重要作用。
二、研究设计
(一)样本选择与配对
以2016至2018年沪深A股制造业上市公司为研究对象,结合现有研究方法,若公司年报之后因错报进行了调减盈余的财务重述,选为为正样本(若同一公司有多个年度的年报发生重述,视为不同正样本),并对其进行配对选取年报未财务重述的公司作为负样本。负样本的配对遵循以下原则:(1)参考证监会 2012 发布的《上市公司行业分类指引》选择大类相同或相近的;(2)非财务重述的年报披露年度与相匹配的财务重述年报一致;(3)非财务重述年报对应的上市公司在以后年度也未发生过财务重述行为;(4)总资产规模相近;(5)剔除数据缺失的样本。最终获得104个样本,正样本和负样本各52个,数据来源于csmar数据库。运用机器学习方法对上市公司年报财务重述行为进行预测,是通过从既有数据中挖掘公司进行年报财务重述的共同规律并学习之,从而在未知数据上对重述行为进行预测;因此,将2016、2017年的样本作为训练集,将2018年的样本作为测试集,即通过在2016、2017年样本上分别学习重述样本与非重述样本的规律,并将其运用于2018年样本财务重述的识别,样本分布如表1。重述样本中有约10%当年被外部审计师出具了非标准审计意见,即绝大多数因错报而后期发生调减盈余的财务重述的年报,当期并没有被审计师发现,可见仅仅依靠传统的风险评估方法可能难以有效识别调减盈余的错报风险。
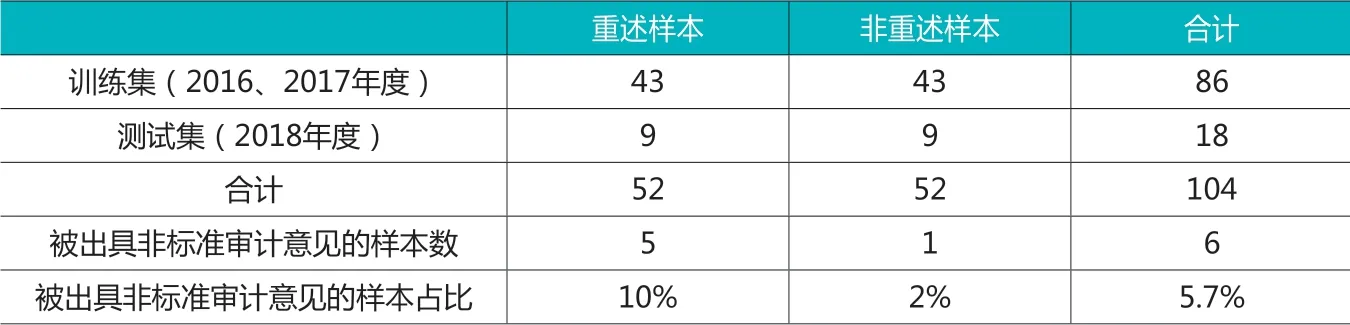
表1 训练集与测试集样本分布
(二)特征选择
1.财务重述与财务业绩。资本市场压力,比如对未来盈利增长的高预期、更高的未偿债务水平,会促使公司采取激进会计政策,以提高当期收益并在随后进行调减盈余的财务重述,即财务重述的重要动因就是盈余操纵,公司管理层为了达成财务预期、满足融资需求或完成薪酬契约,可能运用各种手段进行盈余操纵,若此行为被识破,随之而来的便是财务重述;而业绩不好的公司更可能进行盈余管理;重述公司在重述期的业绩通常会恶化,包括收入方面和现金流方面,具体地,重述公司往往盈利水平低、流动性差、资产周转速度慢、负债水平高,且自由现金流不足,总应计水平与财务重述行为具有部分显著的正相关关系。
2.财务重述与公司治理及股权结构。内部控制缺陷是导致财务重述发生的最为主要的原因,区分公司治理实践优劣的因素对于财务重述的预测可能有帮助,监事会规模较大的公司发生财务重述的概率较低,外部独立审计也是保证公司财务信息质量的有效措施。重述公司往往股权分散,大股东的监管能有效降低管理层机会主义行为,尤其是股权集中度较高时,大股东的利益与公司的绩效更为密切,从而促使其对公司的会计系统进行更有力地监督以控制会计差错的发生,同时对管理层的机会主义倾向产生震慑作用。
基于以上文献的研究结论,选取特征变量如下:选取总应计率代表公司盈余管理情况,选取总资产净利润率、扣除非经常性损益后的总资产净利润率、净资产收益率和扣除非经常性损益后的基本每股收益代表公司盈利能力,选取流动比率代表公司流动性,选取总资产周转率代表公司营运能力,选取资产负债率代表公司负债水平,选取经营活动产生的现金流量净额/资产总额代表公司自由现金流状况,选取监事比例代表公司监事会规模,选取是否披露内控审计报告及内控审计报告意见代表公司外部独立审计情况,选取股权集中度代表公司股权结构。由于需要对年报在将来会否因错报而重述做出预测,而重述公司的年报财务数据在当年披露时是不准确的,故涉及年报财务数据的特征变量取重述期的前一期数据,其他特征变量取重述期数据,如表2。
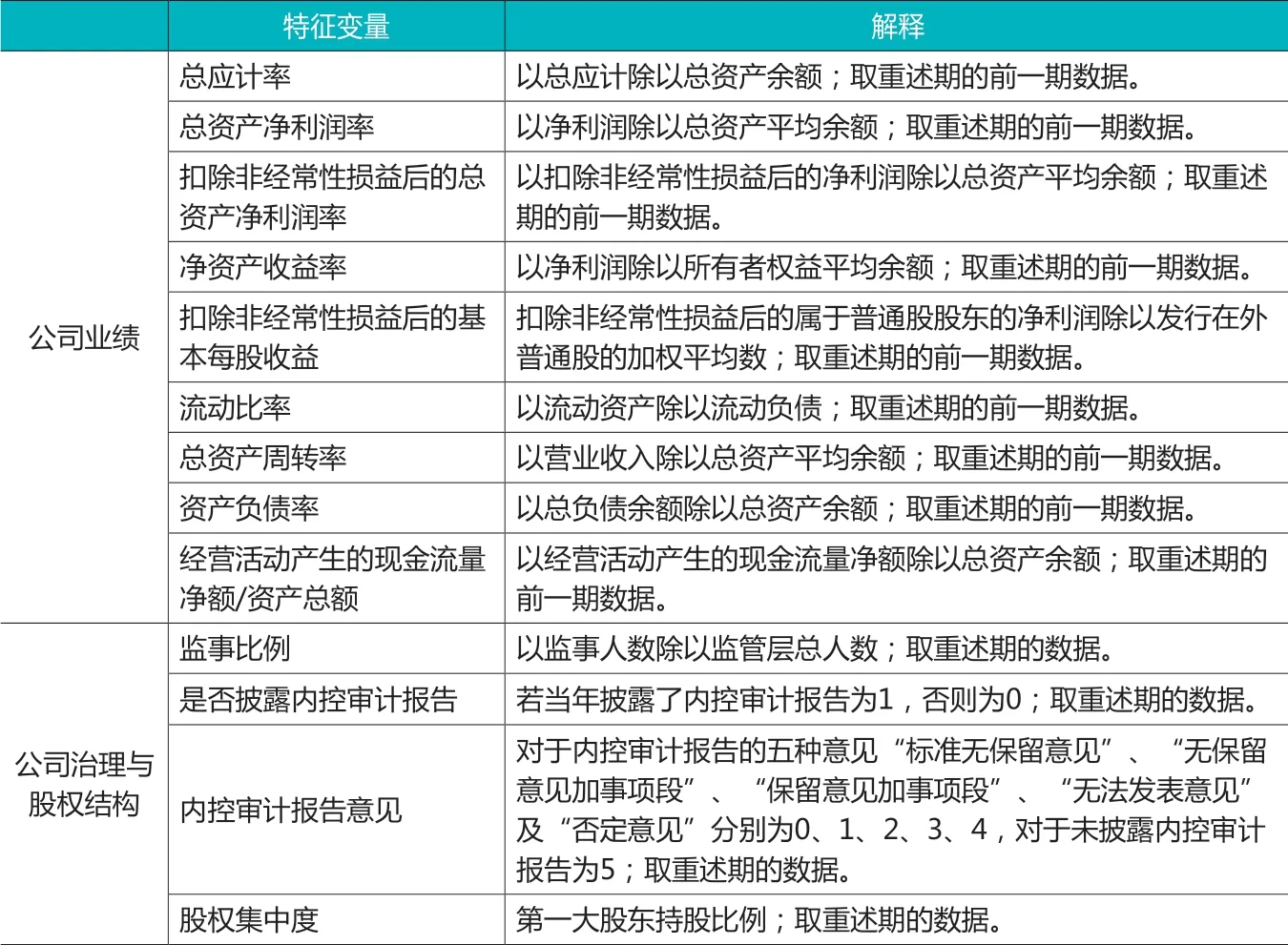
表2 特征变量及其解释
(三)分类方法及其评估指标
1.常用的机器学习分类方法。极限梯度提升树(xgboost)是一个基于梯度提升模型的可扩展树学习系统。它将多个弱评估器通过迭代的方式结合成一个强评估器,在每次梯度提升的迭代中,之前学习的残差被用于校正先前建立的评估器从而优化损失函数;同时,xgboost模型在损失函数中加入正则化从而防止过拟合,而它的输出是迭代过程中各个弱评估器共同投票的结果。在2015年机器学习竞赛—Kaggle的29个获胜方案中,xgboost模型被17个方案所使用,成为最流行的机器学习模型。
神经网络是模拟和简化生物神经元的机理,将多个神经元相互连接组成复杂模型,通过神经元之间的复杂联系建立输入到输出的映射关系,从而实现自学习的过程。多层感知机(MLP)神经网络是一种基础的神经网络模型,它的输入层、隐藏层和输出层是全连接的,每一层的神经元接受大量其他层神经元的输入,通过非线性输入、输出关系,实现从输入状态空间到输出状态空间非线性映射的。作为神经网络的基础模型,多层感知机神经网络对于内部规律不太清晰或难以用一组数学表达式进行概括的情境,可达到良好的预测效果。
随机森林是采用装袋法(bagging)进行集成学习的模型,它利用决策树作为基评估器,在树分枝的节点选择时,使用特征的随机子集而非从所有特征中挑选某个特征。通过将随机性添加到树的构造过程中,使得每颗树都不相同,最后综合所有树的结果作为输出,在保障预测能力的同时降低过拟合,提高模型的泛化能力。
K近邻是一种非参数分类方法,对于一个给定的被预测值,在训练集中寻找K个最接近它的值(近邻),将这K个近邻的投票结果作为被预测值的取值。由于其原理简单、误差可控及能处理非线性问题等优点,仍然是机器学习的重要成员。
支持向量机是根据VC维理论和结构风险最小化原则,在学习能力和模型复杂度之间寻求平衡;为了提高泛化能力,通过核函数的选择,把低维向量映射到高维空间中并寻找超平面,在所有训练样本中寻找处于决策边界的支持向量(support vector)并据此进行分类的。其目标函数的优化为凸优化问题,使得其在寻找全局最优解、扩展性等方面表现不俗,在应用中能良好适应各种数据集。
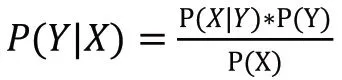
2.分类的评估指标。对于上市公司年报财务重述行为的预测,本文采用二分类方法,即分类的输出有且只有两种情况:阳性(Positive)或阴性(Negative),而相对于真实情况,分类的输出可能是正确的(True)或错误的(False),因此,二分类的结果可归纳为正确的阳性(TP)、正确的阴性(TN)、错误的阳性(FP)和错误的阴性(FN)四种情况,而FP与FN的数量分别代表第Ⅰ类错误和第Ⅱ类错误的数量;相应的有如下评估指标。准确率(Accuracy)是评估分类结果最基本的指标,取值在0至1之间,计算所有样本中被正确分类样本的比例,通常准确率越高则分类结果越好,此指标直观而解释性好,但不能具体查看各个类别的分类结果情况。精确率(Precision)又称查准率,计算所有被分类为阳性的样本中的正确比例,取值在0至1之间,越大表示对阳性样本的识别越精准。召回率(Recall)又称查全率,计算所有真实的阳性样本中被正确分类的比例,取值在0至1之间,越大表示对阳性样本的识别越完全。精确率与召回率是一对此增彼减的评估指标,而无论哪一个太低都不理想,为了整合二者的评估结果,可使用F1分值进行评估,在分类方法对正样本的识别能力上做出综合的评价。第Ⅰ(Ⅱ)类错误率,错误的阳性(错误的阴性)样本占所有阴性(阳性)样本的比例。具体计算公式如下。

上述四个指标以比率的方式评估分类结果,如果要以数量的方式查看分类结果,可使用混淆矩阵(Confusion Matrix),正确的阳性、正确的阴性、错误的阳性和错误的阴性各有多少样本,如表3。本文数据分析工具使用基于Python 3.9.5的NumPy 1.20.3、Pandas 1.3.1、Matplotlib 3.4.2、SciPy 1.7.0、Scikit-Learn 0.24.2及Excel 2019。

表3 混淆矩阵
三、实证检验与分析
(一)描述性分析
表4对重述样本和非重述样本在特征方面进行了对比,发现二者在公司业绩、公司治理与股权结构方面存在明显差异。重述样本的盈利水平显著更低,表现为总资产净利润率(在10%水平上显著)、扣除非经常性损益后的总资产净利润率(在10%水平上显著)、净资产收益率(在10%水平上显著)及扣除非经常性损益后的基本每股收益(在5%水平上显著)都更低;流动性较差,表现为流动比率偏低;营运能力更差,表现为总资产周转率更低(在5%水平上显著);负债水平偏高,表现为资产负债率更高(在5%水平上显著);现金流状况显著更差,表现为经营活动产生的现金流量净额/资产总额更低(在1%水平上显著);盈余管理的可能性较高,表现为总应计率偏高,支持了之前研究的结论。在公司治理方面,重述样本的监事比例与披露内控审计报告比例反而更高,这与之前研究的结论不一致,但这种差异不存在显著性;而内控审计报告意见的严重程度显著偏高(在10%水平上显著),支持了关于重述公司的治理能力较差的结论;股权集中度显著更低(在1%水平上显著),支持了关于重述公司的股权更为分散的结论。
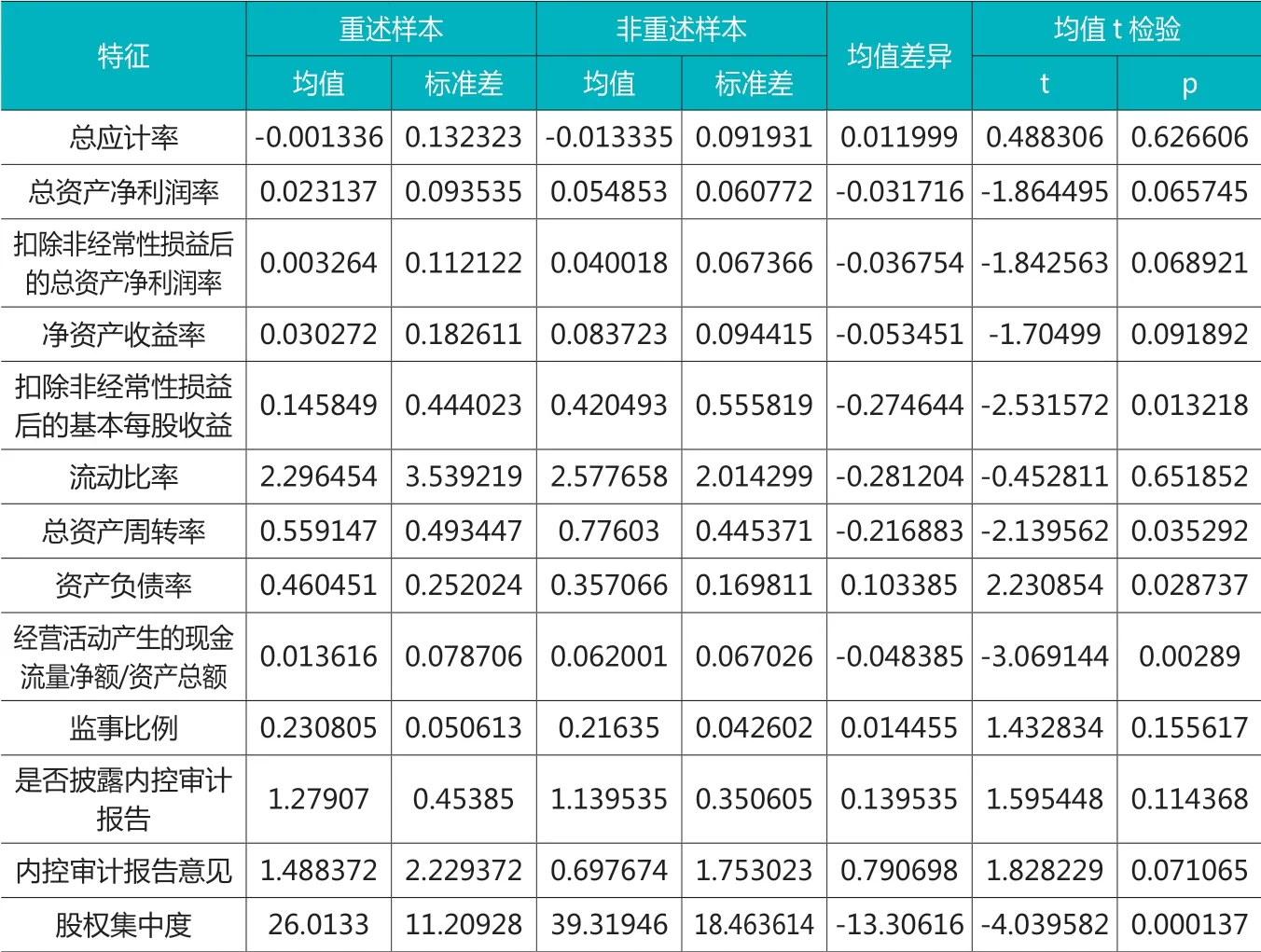
表4 特征的描述性统计
(二)机器学习预测结果分析
为了提高机器学习的学习能力和学习速率,在使用机器学习分类方法之前,对特征数据进行无量纲化(采用标准化方法),即将训练集的各个特征列缩放成均值为0、方差为1,并按相同的缩放比例对测试集的各个特征列进行缩放处理。之后依次使用各分类方法,在2016、2017年训练集上学习规律,然后对2018年测试集的样本执行甄别并检验其结果,如表5。

表5 机器学习分类方法评估结果
在准确率方面,多层感知机神经网络、极限梯度提升树、K近邻、随机森林与支持向量机都优于logistic回归,朴素贝叶斯与logistic回归持平,其中极限梯度提升树、多层感知机神经网络与K近邻最高,表明多数机器学习分类方法在区分调减盈余的年报错报与未错报年报方面表现较好。在精确率方面,所有机器学习方法都优于logistic回归,且多数机器学习方法的精确率超过80%,最高者为朴素贝叶斯(达到100%);可见机器学习分类方法对调减盈余的年报错报识别的误判率较低(准确性较好)。在召回率方面,多层感知机神经网络高于logistic回归,朴素贝叶斯低于logistic回归,其他机器学习方法与logistic回归持平,表明多数机器学习分类方法对调减盈余的年报错报识别的遗漏率较高(全面性较差)。机器学习分类方法对于调减盈余的年报错报识别强于准确性而疏于全面性,注册会计师在应用于风险评估程序时,对于预测为阳性的年报样本应警觉并设计进一步审计程序;对于预测为阴性的年报样本亦不能放松警惕。进一步分析混淆矩阵,发现在错误的阳性样本数量(或第Ⅰ类错误率)方面,所有机器学习方法表现都优于logistic回归,表现最好的朴素贝叶斯对于阳性的误判率为零(第Ⅰ类错误率为零),体现了机器学习方法在调减盈余的年报错报识别方面规避第Ⅰ类错误的能力更强;而在错误的阳性样本数量(或第Ⅰ类错误率)方面,多层感知机神经网络高于logistic回归,朴素贝叶斯低于logistic回归,其他机器学习方法与logistic回归持平,反映了机器学习方法在调减盈余的年报错报识别方面规避第Ⅱ类错误的能力不突出。特别地,多层感知机神经网络在各个指标的表现都优于logistic回归。
除了可以分析各分类方法的表现,某些分类模型在建模过程中对各个特征的重要性进行了计算,从而能够观察各个特征对于分类方法的重要性程度。选取能够查看特征重要性的分类方法中表现较好的极限梯度提升树和随机森林,其特征重要性排序如图1和图2;为便于分析,制成表6。可见各个特征对于两种分类方法的学习都产生了一定的影响,但影响大小并不完全相同。其中对于极限梯度提升树的学习影响最大的前五个特征分别是总资产周转率、股权集中度、是否披露内控审计报告、扣除非经常性损益后的基本每股收益以及流动比率;而对于随机森林的学习影响最大的前五个特征分别是总资产周转率、股权集中度、扣除非经常性损益后的基本每股收益、经营活动产生的现金流量净额/资产总额以及流动比率;其中总资产周转率、股权集中度、扣除非经常性损益后的基本每股收益和流动比率四个特征在两个分类方法中都属于重要性排名前五的特征,且前三个特征在之前样本均值t检验中都有显著差异(显著性分别为5%、1%和5%),表明营运能力、盈利能力、流动比率等公司业绩特征与股权集中度特征在调减盈余的财务重述行为的预测方面起到了重要作用;而是否披露内控审计报告与经营活动产生的现金流量净额/资产总额两个特征,在两个分类方法中分别属于重要性排名前五位和重要性排名后五位的特征,其重要性表现不稳定。同时,对于两个分类方法影响排名后五位的特征中,都出现了内控审计报告意见和总应计率,表明二者对调减盈余的财务重述行为的预测的作用不明显。

图1 极限梯度提升树特征重要性
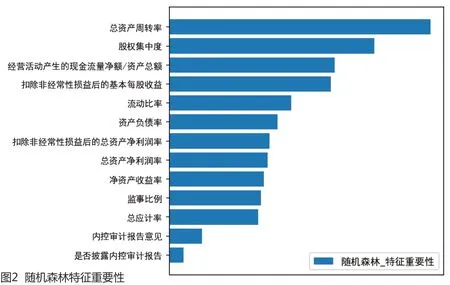
图2 随机森林特征重要性

表6 特征重要性比较
四、结论
选取2016至2018年沪深A股制造业上市公司中年报发生调减盈余的财务重述的52家公司和年报未发生财务重述的52家配对公司为样本,以2016和2017年的样本作为训练集,以2018年的样本作为测试集,分别运用机器学习和logistic回归对财务重述进行预测并比较结果,同时检验现有文献关于财务重述公司特征对财务重述行为的预测能力。结果显示,与logistic回归相比,多层感知机神经网络、极限梯度提升树、K近邻、随机森林与支持向量机等机器学习方法在上市公司财务报告重述行为预测的准确率、F1分值和第Ⅰ类错误率等方面都表现更优,其中多层感知机神经网络在各个指标都表现更优;表明机器学习能有效识别调减盈余的年报错报,可在注册会计师执行风险评估程序中运用,以降低审计风险。研究还发现,营运能力、盈利能力、流动比率与股权集中度等特征对上市公司年报调减盈余的财务重述行为的预测起到重要作用。
会计信息质量对于内部管理者的管理、股权与债权人的决策,分析师的预测等利益相关者都有重要影响,而注册会计师的审计质量是披露会计信息质量的重要保障,财政部2019年更新了18项关于中国注册会计师的审计准则,推动了风险导向审计的实施。通过研究机器学习对上市公司年报错报的识别,以期给注册会计师识别错报风险提供参考,给监管部门监督、查处信息披露失真行为提供借鉴,给投资者、分析师等对财报的甄别使用提供参考。
