基于卷积神经网络的胃癌癌前病变图像分类方法
2022-03-14张育赵轶峰苏卓彬杨永江
张育,赵轶峰,苏卓彬,杨永江
河北北方学院附属第一医院胃肠肿瘤外科,河北张家口 075000
前言
卷积神经网络(Convolutional Neural Network,CNN)是近些年来最流行与最成功的图像分类方法。胃癌被称为全球第4大癌症,并且在所有的癌症中其致死率排名第2。根据癌症进展,胃部病变一般可以分为胃癌癌前病变、早期胃癌和晚期胃癌。通常早期胃癌患者在其接受治疗的5年后生存率超过90%,而晚期胃癌患者通常生存率低于30%。早期胃癌诊断通常会通过检查患者的息肉、糜烂和溃疡等各种癌前病变进行推断,如胃肠息肉通常认为是癌症前兆,因此在早期发现和治疗这些息肉就可以大大降低患癌风险。通常医生使用相关的成像检查设备协助检查患者的胃肠道,以此进行胃肠道疾病诊断。就胃癌诊断而言,建立一个能够帮助医生找到癌前息肉等病理区域的智能系统是非常必要的,该系统通过对息肉进行分类,并根据息肉类型进行适当标记,可以获得更准确的诊断。近年来,研究人员根据不同类型胃癌癌前病变提出了不同的诊断方法与分类方法。他们使用形状和纹理等不同特征,借助机器视觉和机器学习技术对图像进行分类和标记。很多研究都使用了对息肉的表征非常有效的双树复小波变换方法。文献[1]引入了一种基于纹理和边缘属性的方法,进而通过使用带有提升方法的支持向量机模型取得了较为准确的结果。然而,传统的机器学习方法需要手工制作特征,通常耗时较长且缺乏鲁棒性。如今,基于神经网络的方法在诊断或分类医学图像方面非常有效。在神经网络中有卷积层(convolution)、池化层(pooling)和全连接层(fully connected)的组合,它们通过这些层使用反向传播算法进行训练。文献[2]、[3]使用CNN将多种息肉特征集成到一个息肉检测系统中。文献[4]也使用CNN实现了结肠息肉分类。文献[5]将CNN 作为特征提取器,SVM 作为分类器,实现了内窥镜下的图像病变检测。表1讨论了基于手工特征的模型,表2讨论了使用CNN的方法。
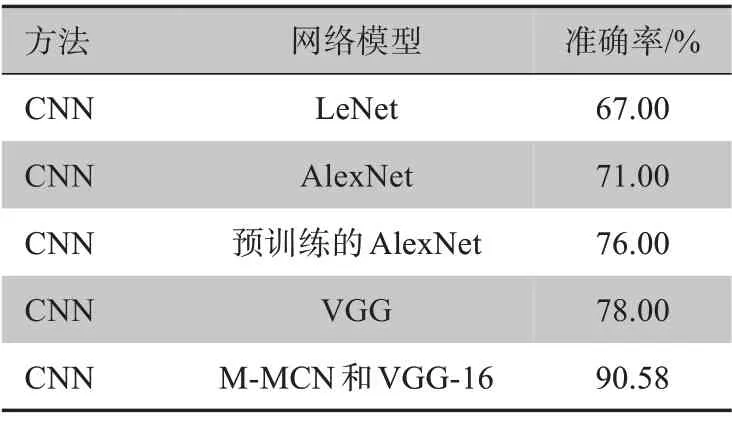
表1 使用手工特征的常见模型Table 1 Common models using manual features
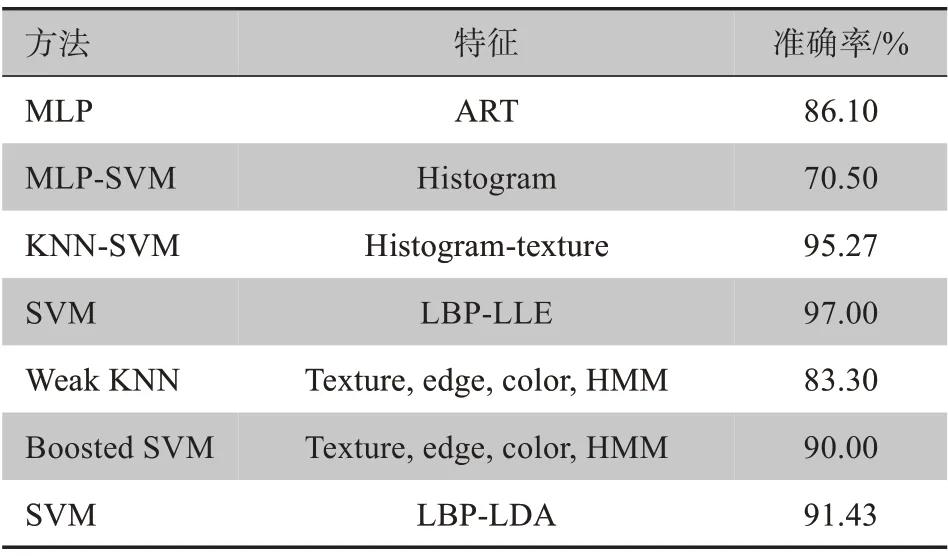
表2 使用卷积神经网络的常见模型Table 2 Common models using convolutional neural networks
1 提出的方法
本节中首先介绍所用的图像集,然后引入用于胃癌癌前病变的CNN 模型,最后对实验设置进行介绍。
1.1 图像集
为了训练神经网络模型,使用由文献[6]收集的经相关患者书面许可的胃癌癌前病变图像。本图像集包含两个专业临床医生标记的3 种胃息肉类型共1 342 张图像,其中包含378 张糜烂图像、447 张息肉图像、477 张溃疡图像。原本该图像集的图像尺寸为460×475,经过对感兴趣区域的裁剪与旋转等图像预处理后,图像集中包含尺寸为32×32的3 677张图像,其中包括1 214张糜烂图像、1 219张息肉图像和1 244张溃疡图像。
1.2 CNN模型
本文提出的CNN 模型如图1所示。可以看出,其基本架构来源于AlexNet。然而,由于AlexNet 保留了全连接层,所以需要更多的参数,这会增加模型的尺寸,且更容易过拟合。为了减少CNN 的尺寸和提高模型分类的准确性,本文受到SqueezeNet[6]的启发,用fire模块(由一个只有1×1滤波器组成的压缩卷积层和一个混合了1×1 和3×3 卷积滤波器的扩展层组成)替换了AlexNet 的一些卷积层。目前的神经网络结构包括两种卷积层,即之前CNN 的卷积层和两个新的fire模块。
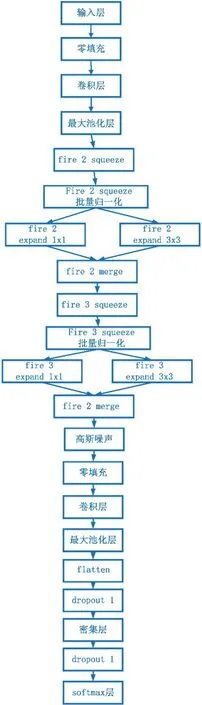
图1 本文提出的CNN模型架构Figure 1 Architecture of the proposed CNN model
1.3 训练设置
本文的CNN是在Keras[7]框架下实现的,涉及卷积网络的方法是用Python 编写的,所有实验都是在Windows 10上进行的,GPU 为NVidia GeForce GTX1060(6 GB)。训练时包含3类胃息肉图像的数据集,其中75%进行训练,其余25%用于测试。损失函数如式(1)所述,以此进行网络参数的更新与迭代。
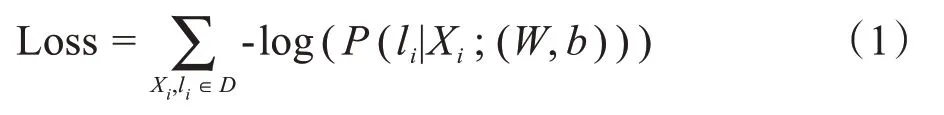
本文采用带有动量[7]的随机梯度下降法对损失进行最小优化。在建立了CNN 的基本结构后,它可以更新每个训练样本的参数。此外为了通过超参数调优来提高性能,本文使用了如下所述的一些tips:
(1)L2正则化
本文使用权重衰减法惩罚大权重。其中采用的L2 正则化可以使得权重很小但不强制它们完全为零。将L2项加入损失函数后,如式(2)所示:
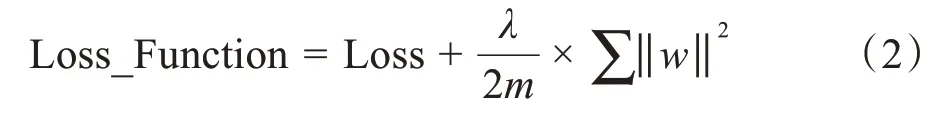
(2)学习率优化
本文的CNN首先以一个基础的学习率开始学习,在随后的每个epoch皆慢慢减少,以此提高模型的准确性,这被称之为阶跃衰减。其计算如式(3)所示:
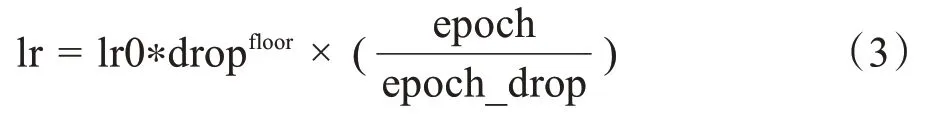
(3)高斯噪声
本文在CNN 的密集层之前应用零均值高斯噪声,从而进行数据增强,此操作有助于缓解过拟合,而且可以提高泛化能力。
(4)ReLU
为了避免出现梯度消失,本文采用ReLU 函数作为激活函数,如式(4)所示。
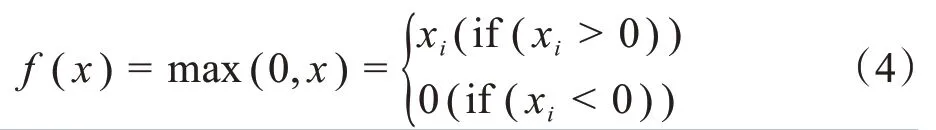
2 实验结果及分析
如上节所述,CNN 学习过程中一些重要的超参数是学习率[8]、高斯噪声、L2正则化[9]和阶跃衰减[10]。在本节中,我们将比较和讨论这些参数对最终精度、时间复杂度和损失函数的影响。
2.1 L2正则化的选择
L2 是最常见的正则化类型之一[11]。本文将式(1)与式(2)结合以得到带有L2正则化损失函数。该参数对精度的影响见表3和图2(1 个epoch 为整个训练集的全部数据进行的一次完整训练[12])。图2a~2d中的L2 正则化系数分别为0.1、0.01、0.001、0.000 1,可以看出最佳的L2系数为0.01。
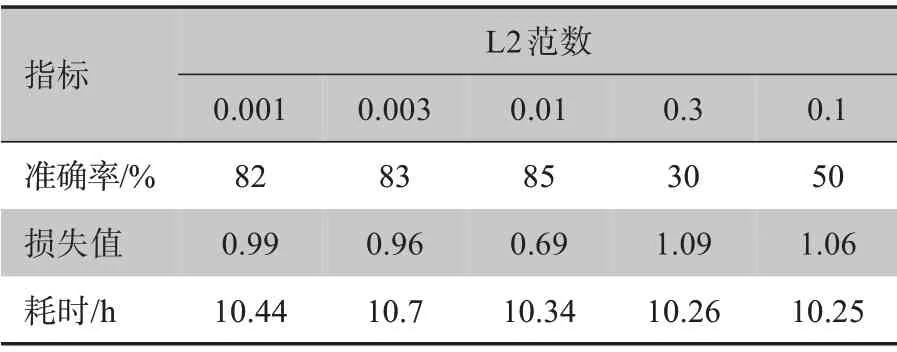
表3 不同的L2正则化系数对分类准确率、损失值和耗时的影响Table 3 Effects of different L2 regularization coefficients on classification accuracy,loss value and time consumed
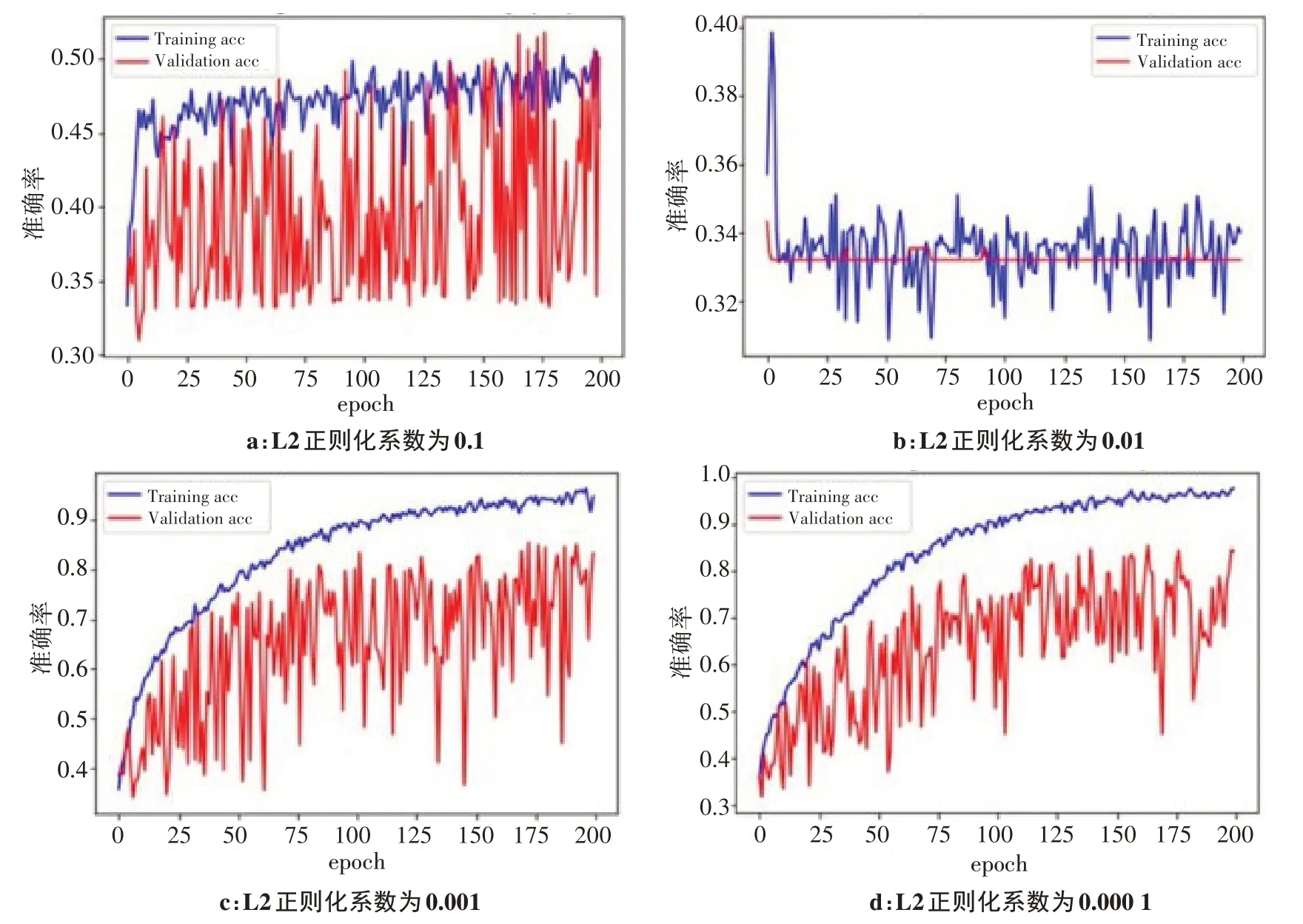
图2 不同的L2正则化系数对分类准确率的影响Figure 2 Effects of different L2 regularization coefficients on classification accuracy
2.2 学习率的选择
图3与表4为不同学习率对最终准确率的影响。图3a~3d 中的基础学习率分别为0.1、0.01、0.001、0.000 1,可以看出LR=0.001 的学习率参数在模型训练过程中效果最好。
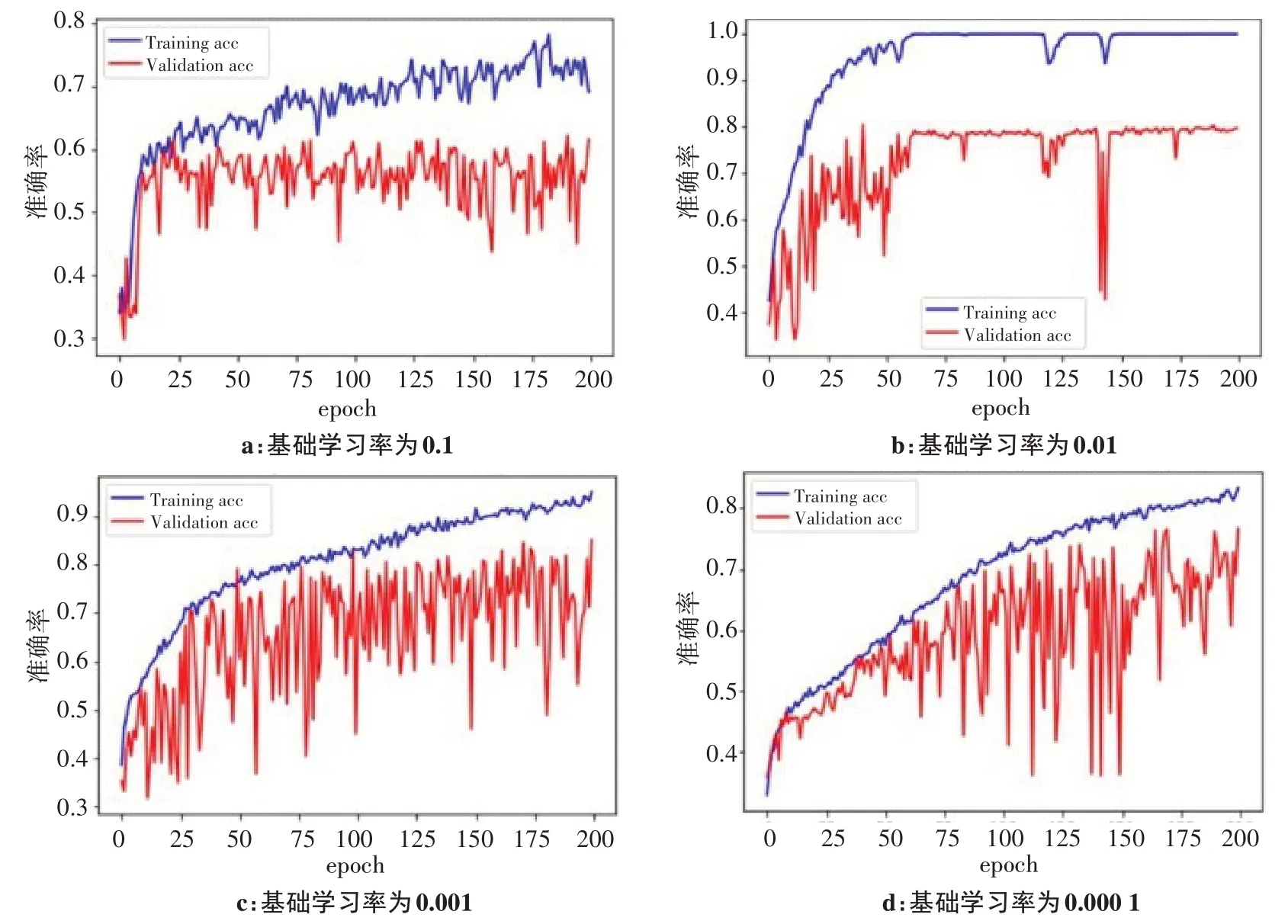
图3 不同的学习率对分类准确率的影响Figure 3 Effects of different learning rates on classification accuracy
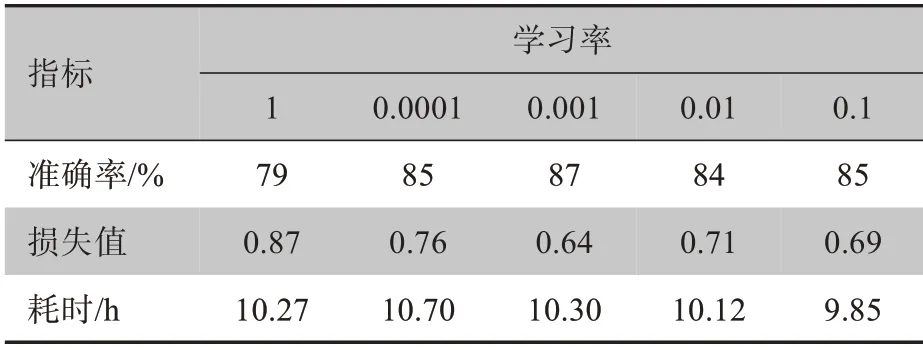
表4 不同的基础学习率对分类准确率、损失值和耗时的影响Table 4 Effects of different basic learning rates on classification accuracy,loss value and time consumed
2.3 高斯噪声参数的选择
CNN 中的高斯噪声定义参考文献[13]和[14]。使用不同的高斯噪声值检验该参数对模型精度和损失函数的影响[15-16],图4给出了结果的对比,图4a~4c中的高斯噪声参数分别为0.1、0.01、0.001。由表5可见高斯噪声参数的最佳值为0.01。
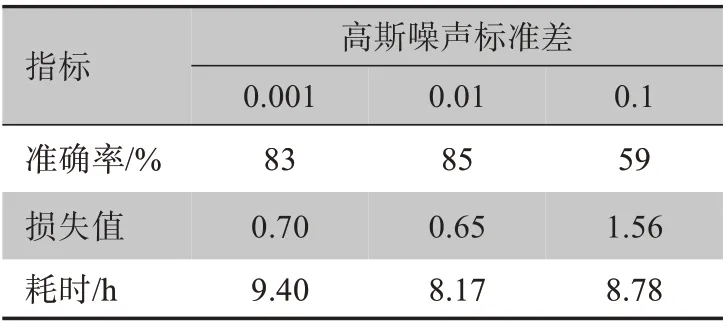
表5 不同的高斯噪声标准差选择对分类准确率、损失值和耗时的影响Table 5 Effects of different Gaussian noise standard deviations on classification accuracy,loss value and time consumed
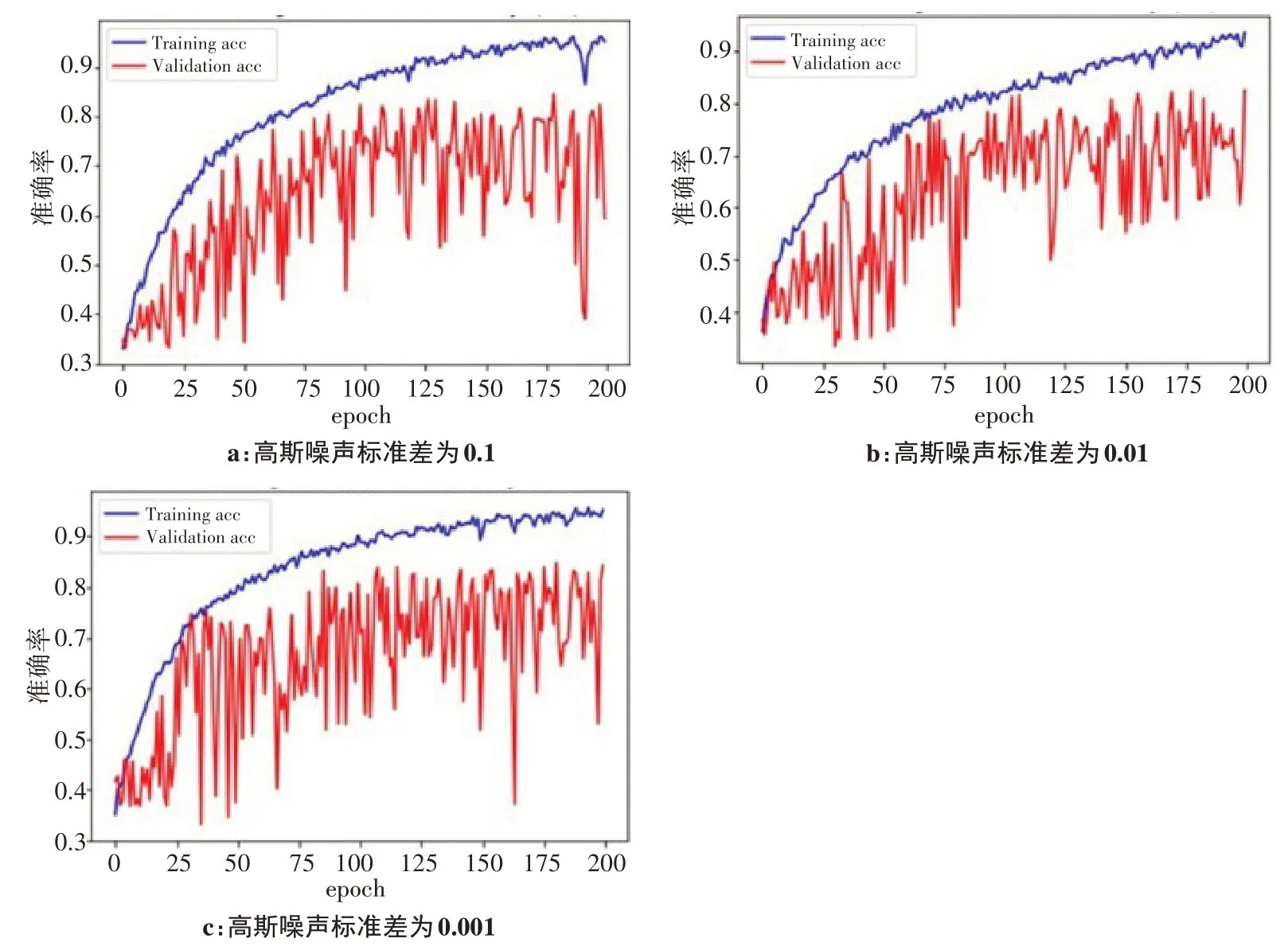
图4 不同的高斯噪声参数对分类准确率的影响Figure 4 Effects of different Gaussian noise parameters on classification accuracy
2.4 阶跃衰减
学习速率可以由式(3)所示逐epoch 降低。为了应用这个参数,我们定义了一个称为step_decay 的函数,并使用它来更新随机梯度下降函数中的学习率[17-18]。图5为该函数,该函数的输入包括初始学习速率、drop的数量和epoch-drop的数量。

图5 定义的阶跃衰减函数Figure 5 Defined step decay function
图6为本实验的曲线图。图6a~6c 中的epochdrop 参数分别为50、100、200。表6为学习率作用后的结果,可以得出本模型中权重损失对应的最佳衰减值drop为0.01。
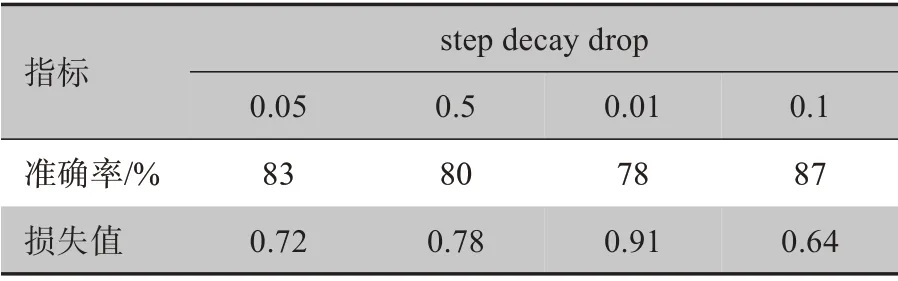
表6 不同的drop参数对分类准确率、损失值影响Table 6 Effects of different drop parameters on classification accuracy and loss value and time consumed
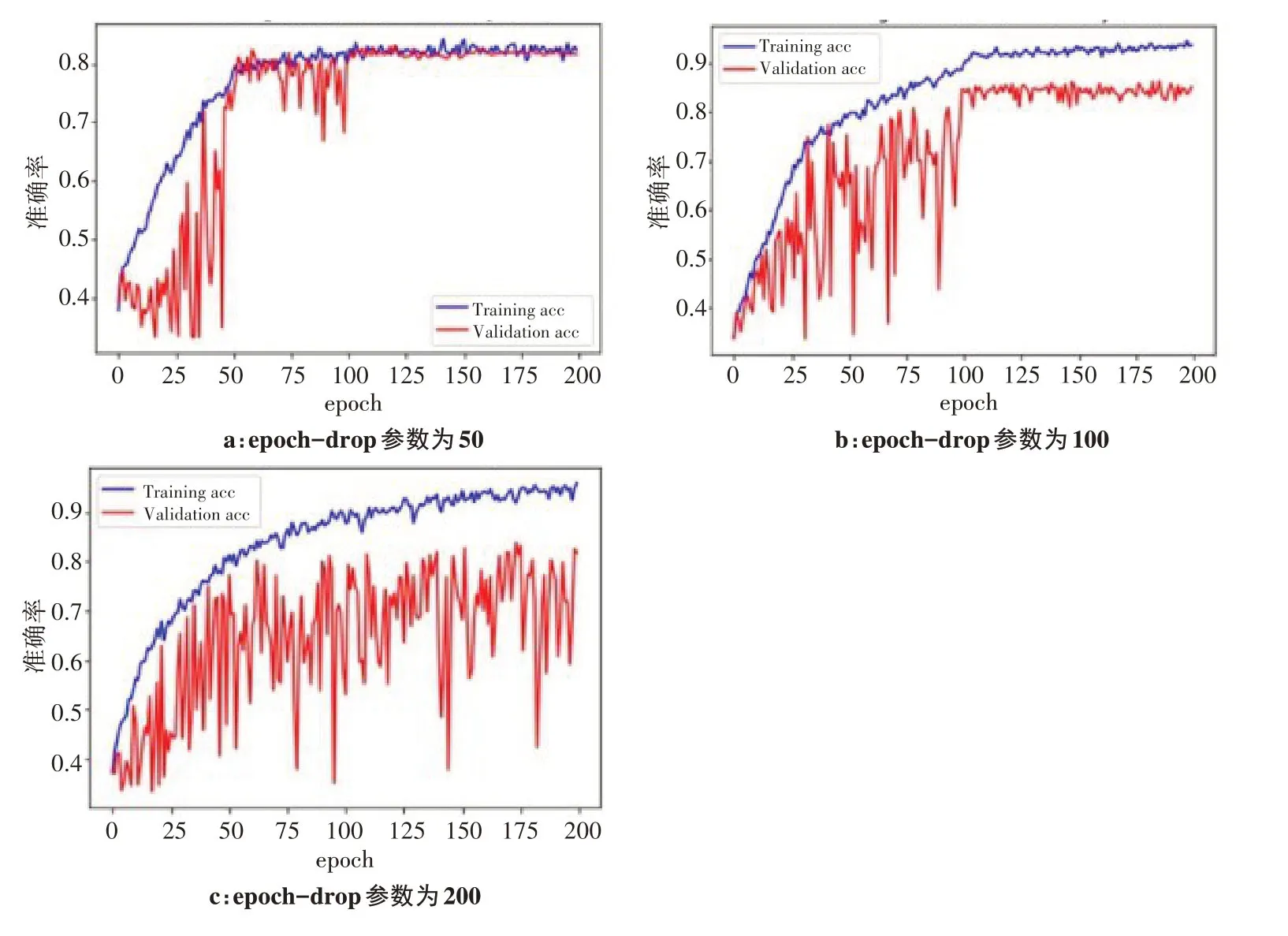
图6 不同的epoch-drop参数对分类准确率的影响Figure 6 Effects of different epoch-drop parameters on classification accuracy
2.5 CNN的重训练
对CNN 模型进行训练并定义超参数:epoch 为200,L2 系数为0.01,高斯噪声标准差为0.001,dropout 为0.1,学习率为0.001 与step decay drop 为0.1 后,分类准确率达到87%。然后每隔200 个epoch对模型进行再训练直到第1 000 个epoch,模型的精度达到89%,如表7所示,其中超参数:epoch 为100,迭代次数为4,L2 系数为0.01,高斯噪声标准差为0.001,dropout 为0.1,学习率为0.001 与step decay drop为0.1。训练算法如图7所示。
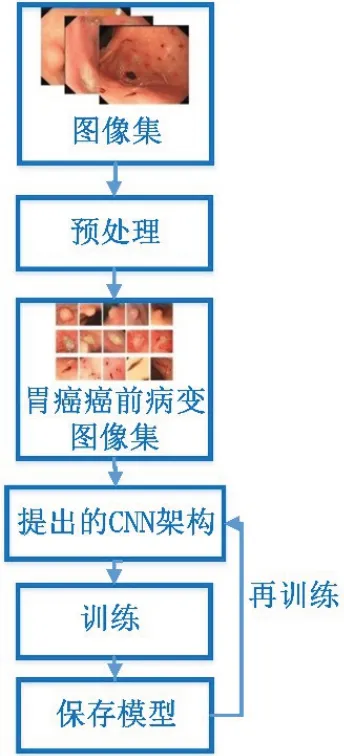
图7 重训练算法Figure 7 Retraining algorithm
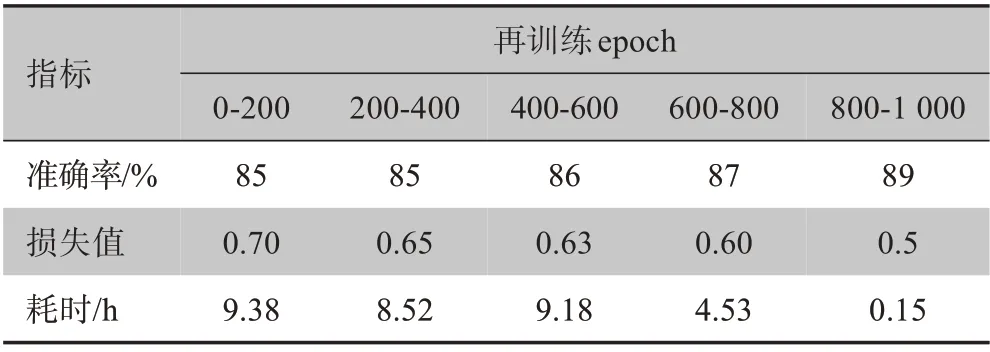
表7 再训练模型的迭代次数对分类准确率、损失值和耗时的影响Table 7 Effects of number of iterations for retraining model on classification accuracy,loss value and time consumed
3 小结与展望
随着医学影像学技术的飞速发展,内窥镜图像种类繁多,根据这一问题的敏感性,对不同类型的疾病进行正确诊断和分类是非常重要的[19]。内窥镜检查通过观察患者的胃肠道情况,可用于胃癌诊断。早期发现胃癌癌前病变的类型有助于胃癌预防,因此,检测准确性非常重要[20]。由于内窥镜操作过程依赖于器材操作者,基于人为因素,出错的概率很高,通过设计基于CNN的智能系统,可以更准确地对不同类型的病变和疾病进行分类[21]。本文通过设计CNN 架构并使用数据增强、噪声和权值衰减等技术训练CNN模型,最后通过精度、损失值和混淆矩阵等性能指标,证明了本文提出方法的有效性。