非小细胞肺癌淋巴结转移预测模型研究
2022-03-14卢孔尧黄钢左艳
卢孔尧,黄钢,左艳
1.上海理工大学医疗器械与食品学院,上海 200093;2.上海健康医学院附属嘉定中心医院上海市分子影像学重点实验室,上海 201318
前言
肺癌依然是全世界癌症相关死亡的主要原因[1]。肿瘤的早期发现和分期对肺癌的治疗非常重要[2]。而非小细胞肺癌(Non-Small Cell Lung Cancer,NSCLC)患者约占所有肺癌患者的80%~85%,其治疗方式主要根据TNM(Tumor, Lymph Node, Metastasis)期系统确定[3]。国家综合癌症网络指南(2018)指出,早期NSCLC患者应首选手术,晚期NSCLC 患者应首选放疗和化疗[4]。而淋巴结转移是肺癌最常见的转移途径。决定肺癌分期、治疗方案和预后的关键因素之一是淋巴结转移(Lymph Node Metastasis,LNM)。术前对肿瘤转移的了解可以为选择辅助治疗或手术切除方案提供有价值的信息,从而帮助临床医生做出正确的决定[5]。为了保护肺功能,对于没有淋巴结转移的患者,应行有限切除,如楔形切除或节段切除[6]。已有调查研究表明,肺癌患者的5年生存率与淋巴结转移相关,无淋巴结转移患者的5年生存率约为56%,而有淋巴结转移仅为38%[7]。因此,术前确定NSCLC 患者的淋巴结转移情况非常重要。目前,评价NSCLC 淋巴结是否有转移的方法有很多,这些方法包括计算机断层扫描(Computed Tomography,CT)、正电子发射断层扫描(Positron Emission Tomography-CT,PET-CT)、超声引导活检、胸腔镜等[8-9]。PET-CT 检查可以较好地评估淋巴结转移状态,对肺癌患者的淋巴结分期具有较高的特异性。然而,PET-CT 检查方式存在的误诊[10]和假阴性率[11]仍然是一个值得关注的问题。此外,发展中国家的许多患者负担不起PET-CT 扫描的较高费用[12]。而胸腔镜检查和活检等病理检查方式也能对NSCLC 的淋巴结状态进行评估,但是其有创性的操作会给无淋巴结转移的患者带来负面影响。因此,找到非侵入性的方法来预测患者淋巴结转移情况对后续的临床治疗尤为重要[13-15]。
近年来,影像组学作为一种新兴的方法,受到了越来越多学者和专家的关注.影像组学在癌症患者的个体化治疗中显得越来越重要。有研究表明,影像组学方法可以从数字医学图像中提取定量特征,使在图像上挖掘出的高维数据能够应用于临床决策支持,从而提高诊断、预后和预测的准确性[16-17]。本研究的目标是开发和验证一个基于影像组学的模型,用于术前预测NSCLC患者的淋巴结转移情况。
1 材料和方法
1.1 试验材料
本研究的病人数据一部分来自癌症影像档案(The Cancer Imaging Archive,TCIA)中 的NSCLC Radiogenomics 公共数据集[18],使用数据库中的134例NSCLC 患者的临床和CT 影像数据。另一部分数据来自上海市胸科医院经病理证实的44 例NSCLC患者的临床和CT 影像数据。患者的影像数据包括178 组CT 图像序列,每幅图像的尺寸大小为512 像素×512 像素,所选病例的纳入标准为:(1)年龄均大于18 周岁,肺已发育完全,可以避免其他因素干扰;(2)病理诊断为NSCLC且已确定其LNM情况;(3)有完整的CT 图像和个人的基本信息。排除标准为:(1)术前接受过放疗或化疗等治疗;(2)没有明确的病理分期。为了保证试验本身的客观和可靠性,并且能更有价值地预测淋巴结转移状况,在数据集的分配上,以公共数据集作为训练集,总共134例样本,其中109例无淋巴结转移,25例有淋巴结转移。从上海胸科医院采集的数据作为测试集,总共44例样本,其中17 例无淋巴结转移,27 例有淋巴结转移。两部分患者的临床信息如表1所示。
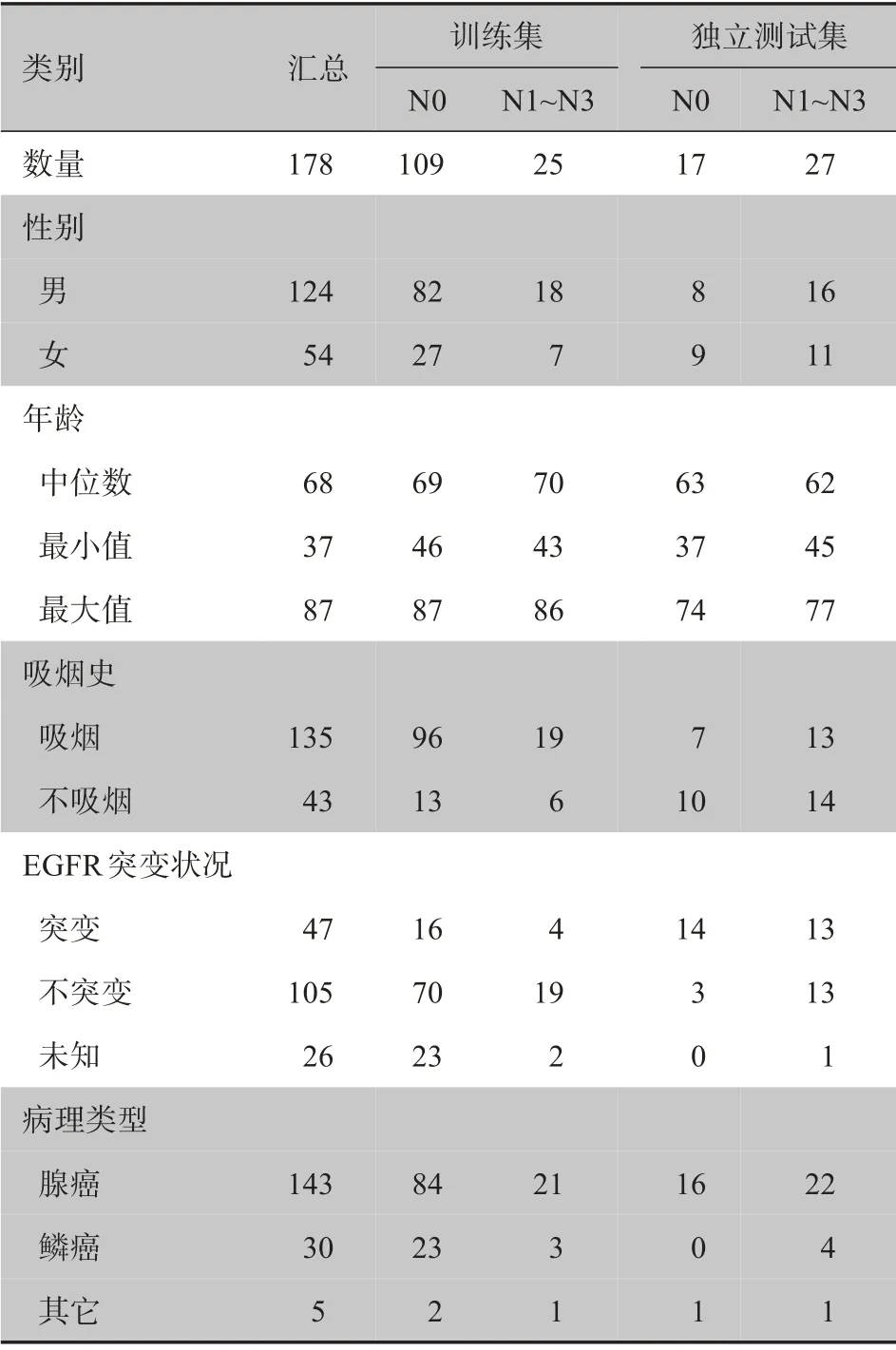
表1 两中心纳入病例的临床信息(n=178)Table 1 Clinical information of the enrolled cases from two centers(n=178)
1.2 方法
首先,由经验丰富的放射科医生通过开源软件ITK-SNAP[19](3.6.0 版本,www.itksnap.org)手工勾画感兴趣区域(Region of Interest,ROI)。两个病例样本最大直径处勾画的肿瘤标记CT 切片图和最终经三维重建得到的三维肿瘤图见图1。然后,再从中提取形态学特征、一阶统计学特征和纹理特征。接着采用综合采样人工合成数据算法(Synthetic Minority Over-sampling Technique, SMOTE)对训练集数据做平衡化处理,再用主成分分析(Principal Component Analysis,PCA)方法进行特征降维,而后用Relief、方差分析(Analysis of Variance,ANOVA)和递归特征消除(Recursive Feature Elimination, RFE)算法进行特征选择,最后将预处理后的数据对5种分类器进行训练,并经过5 折交叉验证,建立NSCLC 淋巴结转移预测模型,然后进行外部验证。工作流程如图2所示。
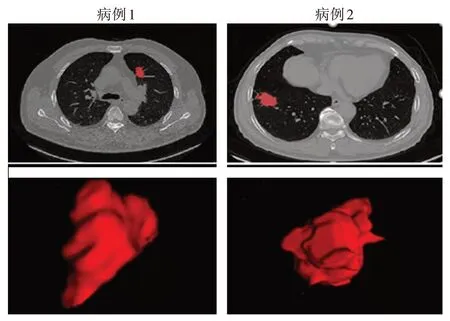
图1 两个病例肿瘤切片标记图(上)和三维重建图(下)Figure 1 Tumor slice labeled images(up)and three-dimensional reconstruction images(down)of 2 cases
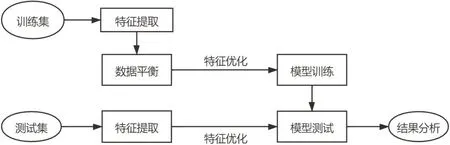
图2 本文工作流程Figure 2 Workflow of the proposed method
1.2.1 特征提取特征提取是影像组学中非常关键的一步,通过此步骤可以从医学影像中获取有用的信息和数据,以便于后续对肿瘤异质性的定量分析和描述。为了使CT 影像组学特征更准确地分析并预测NSCLC淋巴结转移状况,应该多角度、多种类地提取相关的定量指标特征。本研究使用python 中的开源软件包Pyradiomics[20](https://github. com/Radiomics/pyra-diomics)从分割的肿瘤区域中自动提取出1 648 个影像组学特征,其中包括形态学、纹理、一阶统计学特征,具体的特征类型及名称如表2所示。
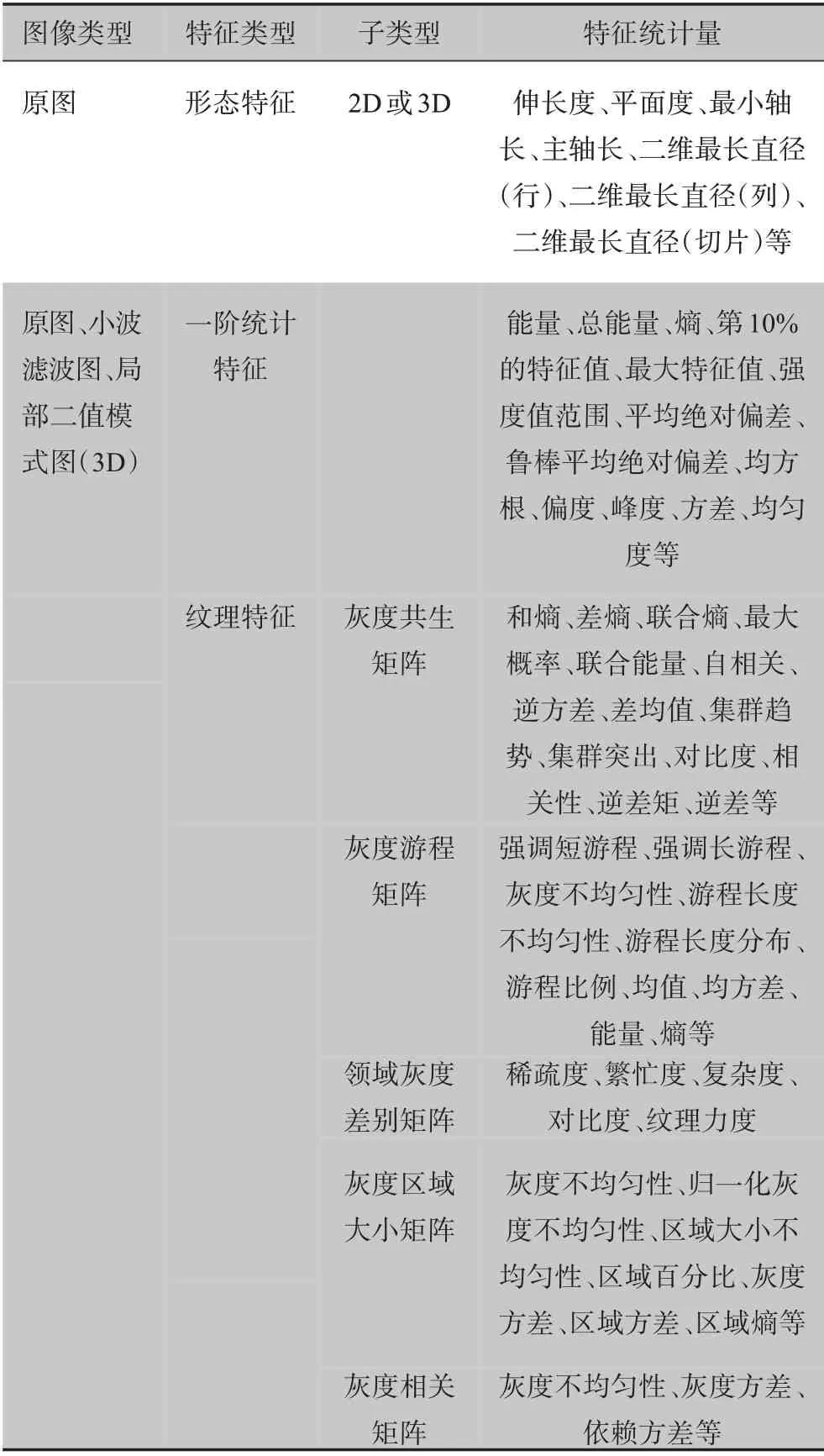
表2 所提取的特征Table 2 Extracted features
1.2.2 数据平衡在试验中,由于训练集的样本中有109例无淋巴结转移,25例淋巴结转移,两者在数量上的比例不均衡。而这种样本类别之间的比例失调,往往会导致预测得出的结果出现很大的偏倚,即预测分类结果会更偏向于多数类样本,致使分类结果不准确。因此,为了解决数据不平衡问题,采用SMOTE算法对训练集数据做平衡化处理。SMOTE算法是2002年Chawla等[21]提出的一种技术,这种技术可以用过采样方法合成少数类样本的数量,以达到类别数量之间趋于均衡的效果。算法的具体流程如下所示。
(1)在特征数据空间中,取每一个少数类的样本m,找到该样本的k个最近的相邻样本,一般k值取5。(2)根据自身试验所需样本的过采样量,确定过采样倍率,然后从k个最近的相邻样本中随机选择n个样本(n<k)。(3)先算出某一少数样本与其最近邻样本的差值,然后将该差值乘以0 和1 之间的一个随机数,最后将其加入原来的少数样本中,从而合成新的样本。(4)本文采用SMOTE 算法,使训练集数据的无淋巴结转移样本扩充到109 例。由于使用该算法得到的样本并不是真实样本数据,所以该部分样本只参与分类器模型的训练过程,而不参与模型的测试过程,测试过程选用的是44 例外部数据集作为测试集进行模型验证。
1.2.3 特征优化通过影像组学的方法可以从肿瘤区域中提取出大量的定量特征,但是由于提取的特征中包含一些噪声和冗余的特征,会使后续的计算变得更加复杂,甚至会导致预测模型出现过拟合现象。因此,特征优化是一种非常有必要的方法,借助此方法可以选到一些对提高模型预测性能和数据处理速度真正重要的特征子集。试验中首先通过PCA 方法压缩和简化提取到的高维特征数据,去除无关和冗余信息对预测模型的干扰。然后再使用Relief、ANOVA 和RFE 算法进行特征选择,最终达到特征优化的目的。
本文采用PCA 算法进行特征降维,PCA 可以将多个变量转化为重要的几个综合主成分,而忽略掉其中不重要的成分,这些主成分是通过原始数据的变量特征经过线性变换转化而来的组合,组合之间是互不相关的,但是能反映原始数据的大量信息,从而实现高维特征向量向低维特征向量的转换。其具体的算法流程如下。
假设有一个特征数据集,其样本数量为n,特征数量为p,将其组合成一个大小为n×p矩阵x,如公式(1)所示:
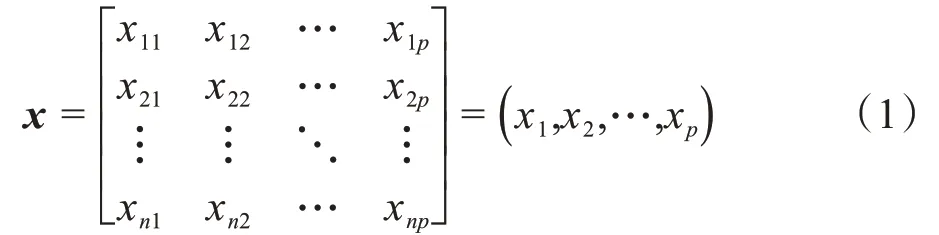
由于每个特征的度量单位不一致的情况容易影响后续的的特征降维,所以先对数据集中的每一个特征进行标准化处理,即按列计算出每个特征的均值和标准差,然后通过计算得到标准化数据,使标准化数据的每一个特征减去对应该列特征的平均值,得到新的矩阵X,如公式(2)所示:
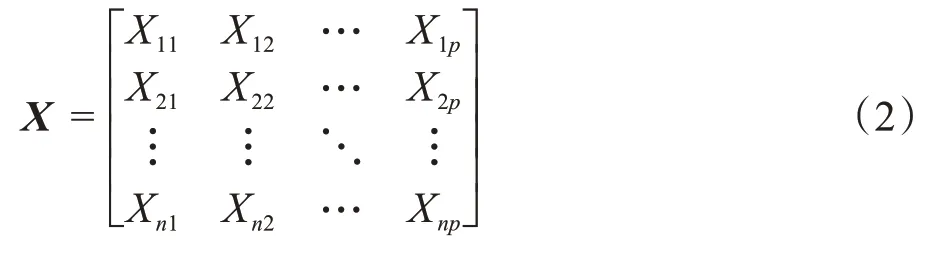
然后计算标准化样本的协方差矩阵R,如公式(3)所示:
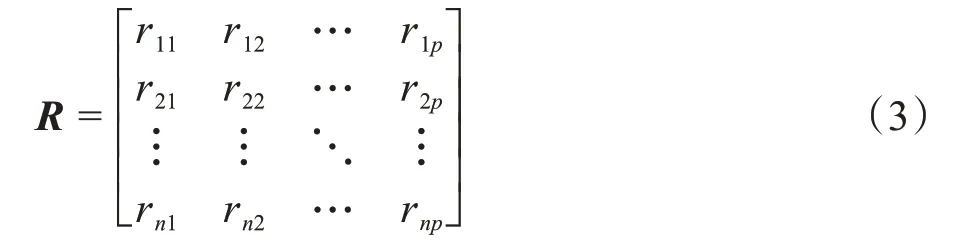
一般来说,贡献率越大,表明该成分综合的信息越多。而为了达到降维又尽可能地保证原数据信息的完整性,保留累计贡献率达到较高值的k个特征向量作为主成分。本试验选取累计贡献率超过80%的前几个特征作为主成分,在保证原数据信息完整的条件下,去除噪声和冗余信息,达到特征降维并优化的效果。在试验中,将原来提取的1 648个影像组学特征通过PCA方法降维到60个更具代表性的主成分特征,既达到了特征压缩的目的,又能充分代表原数据的信息,为后续分类预测模型的建立奠定了良好的基础。
经过PCA 特征降维之后,再使用Relief、ANOVA和RFE 算法进行特征选择,最后得到特征冗余量小并与淋巴结转移更显著相关的特征子集。
1.2.4 预测分类模型的建立和验证为了得到最优的预测分类模型,进行了大量的试验研究和测试,最终采用了5种泛化性强、适合小样本数据的代表性分类算法,包括朴素贝叶斯(Naïve Bayes,NB),线性判别分析(Linear Discriminant Analysis, LDA)、逻辑回归(Logistic Regression,LR)、支持向量机(Support Vector Machine, SVM)和高斯过程(Gaussian Process, GP),再用优化后的训练集数据训练分类器,接着用测试集数据进行分类预测研究。此外,在试验中还引入了5折交叉验证的方法,该方法既能提升模型的可靠性,还能在很大程度上提高现有数据的利用率。
2 结果
使用基于5 种不同的机器学习分类算法和5 折交叉验证的方法进行分类试验和模型评估,并使用准确率(Accuracy, ACC)、受试者操作特征曲线(Receiver Operative Characteristic Curve, ROC)的曲线下面积(Area Under Curve, AUC)、敏感性(Sensitivity, SEN)及特异性(Specificity, SPE)这些指标评价分类结果的好坏。在训练集和测试集上的评价结果如表3所示,5 种分类器模型最优子类型的ROC曲线如图3所示。
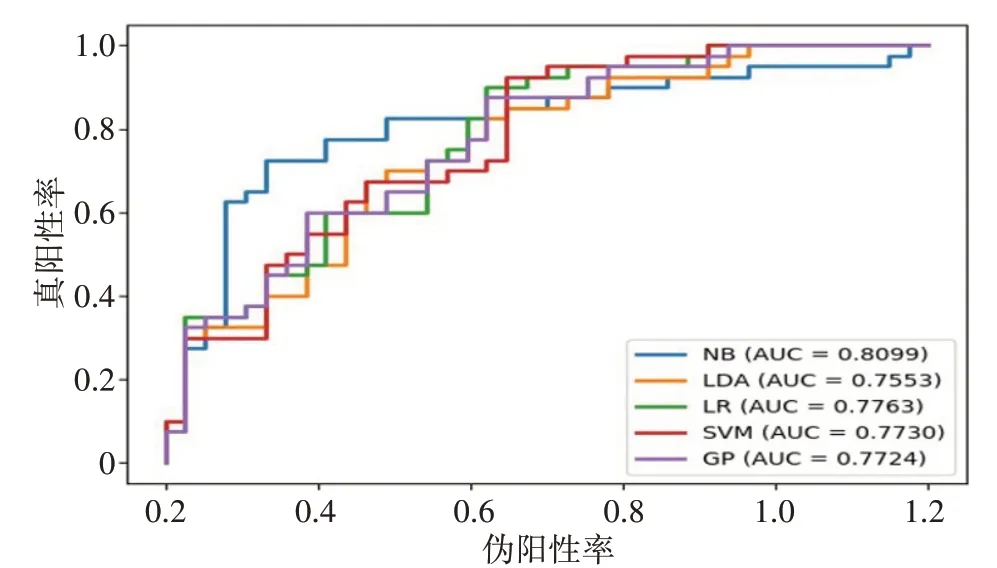
图3 5种模型的最优子类型ROC曲线图Figure 3 ROC curves of the optimal subtypes of 5 models
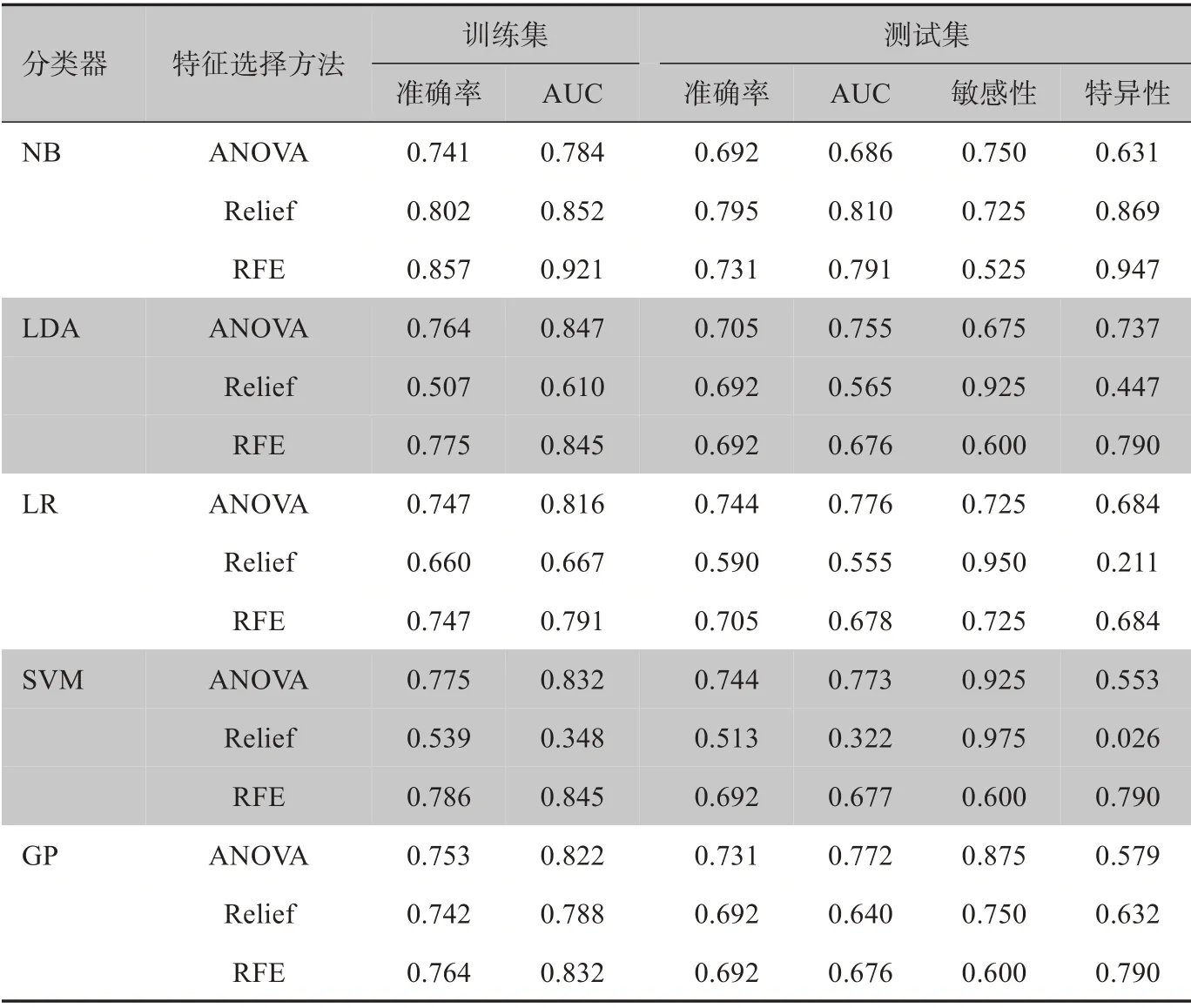
表3 5种分类器的分类结果Table 3 Classification results of 5 classifiers
为了得到一个稳定有效的模型,并且保证该模型在训练时不会出现过拟合现象。于是对多个分类器进行训练,在保证较高的准确率和AUC 值的情况下,还要使模型的敏感性和特异性保持在一种较为均衡的状态。如上面试验结果所示,用不同模型进行训练和预测时,采用Relief 特征选择方法下的NB预测模型为本试验中最好的模型,在所有模型中,此模型下测试集的准确率和AUC 的值均为最高,分别为0.795 和0.810,敏感性和特异性也处于较高水平,分别为0.725和0.869,表明通过该影像组学模型能较准确地对NSCLC患者的淋巴结转移情况进行预测。
3 讨论
本研究基于影像组学的方法,通过高通量计算,从CT图像中提取定量特征,将数字医学图像转换为可挖掘分析的高维特征数据,然后通过数据统计分析探究CT图像的影像组学特征与NSCLC患者淋巴结转移的相关联系,并以多中心实验数据开发并验证一个稳健有效的影像组学预测模型,进一步实现对NSCLC患者淋巴结转移状况无创准确的预测。其中所创建的最优影像组学模型在测试集上(AUC=0.810)具有良好的鉴别分类能力,并且其预测NSCLC患者LNM的有效性显著高于CT报告中淋巴结状态模型和形态学模型[22-23]。结果表明,影像组学特征可以为我们提供更丰富的信息,以其为基础建立的模型在很大程度上提高NSCLC患者LNM的预测准确率,从而辅助医生做出更精准的决策,因此在临床应用上具有重要的指导意义。本研究有如下创新点,第一,我们所开发的影像组学预测模型是基于多个中心获得的数据建立的,因此可以从外部数据验证预测模型的稳健性和可重复性。第二,从CT医学影像提取1 648个定量影像组学特征,并进行有效的统计分析,更全面准确地反映CT图像中的肿瘤信息,大大提高了影像组学模型的预测准确性。第三,采用了SMOTE算法,解决了模型训练过程中的数据不平衡问题,使试验得到的预测模型更加稳定和准确。第四,采用PCA特征降维和Relief、ANOVA和RFE特征选择方法做特征优化处理,最后获得相关性最高的最优特征,为建立更准确的预测模型奠定良好的基础。最后,通过5折交叉验证的方法对NB,LDA,LR,SVM和GP 5种泛化性强、适合小样本数据的代表性分类算法进行分类训练,再用外部数据评估验证模型的准确性和稳定性,这些方法既能降低数据集产生的偶然性,提高模型的泛化能力,还能高效地利用现有数据,并通过试验结果对比得到性能最优的预测模型。
目前已有学者开发相似的基于影像组学的预测模型用于预测NSCLC患者的LNM状态,Cong等[24]从411例NSCLC患者的CT图像中提取影像组学特征,然后使用ANOVA和最小绝对收缩和选择运算(LASSO)方法选择最优的10个影像组学特征,并使用LR算法建立预测模型。朱静等[25]从200例样本中提取影像组学特征,使用LASSO和LR方法建立预测模型。然后将文献[24-25]中用到的方法建立的预测模型结果与本文相比,以预测模型的AUC值作为评估指标进行对比,其对比结果如表4所示。从结果上看,本文采用的算法所开发的预测模型的AUC值比其他两者都高,说明本文提出的预测模型分类性能更好,准确度更高。
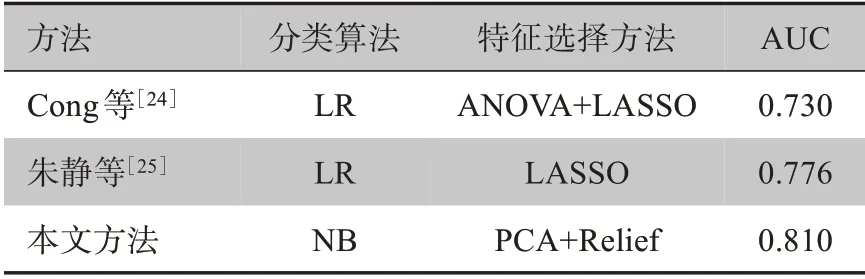
表4 不同方法的预测模型结果比较Table 4 Comparison of results of prediction models with different methods
虽然本文开发的预测模型分类鉴别效果良好,但是还是存在一些不足之处。一、本试验研究所用到的数据样本量比较少,今后需要获取更多的试验数据进行下一步测试和验证。二、仅基于影像组学特征建立预测模型,没有将患者的临床和基因组学特征纳入试验研究中。总之,我们开发并验证了一种基于影像组学的淋巴结预测模型,可以对NACLC患者的淋巴结状态进行无创并有效地评估,并辅助临床决策。