共享单车停放需求影响因素分析和预测研究
2022-03-11杜开瑞
杜开瑞,贺 蓉
(长安大学运输工程学院,陕西 西安 710064)
0 引言
随着交通需求和道路基础设施间的矛盾激化,城市交通拥堵愈演愈烈,随之而来的交通事故频发、能源短缺和环境恶化也越来越严重。共享单车凭借其绿色、畅通和存取灵活等优势,在短距离出行和短途接驳中得到了广泛的应用。据统计,截止到2018年底我国已有超过70家共享单车运营企业,单车数量超过2 000万辆,注册的单车用户超过4亿,高峰时使用人次达到7 000万/天[1]。然而,共享单车的无序发展和单车的乱停乱放也带来了一系列的问题:一方面,造成了道路资源的过度浪费,严重时甚至会侵占道路,引起交通中断等,给城市道路交通带来了诸多不便和严重的安全隐患;另一方面,也增加了自行车运营维护、调度和管理等费用,可能造成单车企业入不敷出、连年亏本,甚至倒闭。因此,对共享单车的需求尤其是停放需求进行预测,对于解决城市单车乱停乱放问题、优化单车调度和促进企业平稳、有序发展,具有非常重要的现实意义。
国内外有不少学者就共享单车的需求影响因素分析和需求预测等方面开展了研究。
Kaltenbrunner等[2]利用基于活动周期的技术和时间序列分析技术(ARMA),预测有桩公共自行车站点的可用自行车数量,但是未考虑天气条件和地理特征等因素。Labadi等[3]基于加权的Petri网,为公共自行车系统提出了模块化的动态租还需求预测模型,但是该方法过于复杂。何流等[4]通过构建公共自行车用户的租车、还车需求的等待、转移和消退的概率函数,预测租赁点短期、多时段的单车需求,但是该模型没有考虑天气等外部因素对需求的影响。吴满金等[5]建立了引入公共自行车出行效用叠加系数的Multi-logit改进模型,来估算租赁点的单车租还需求和公共自行车在居民出行总量中的分担率,但是该方法所用数据透明性和实时性差。钱进[6]对西安市公共自行车的使用特性进行问卷调查,在层次分析法筛选需求影响因素的基础上,建立了基于随机效用理论的单车需求预测模型,但是该方法的数据源存在片面性和局限性等缺点。解小平等[7]构建了基于改进Elman神经网络的租赁点单车需求量预测模型,该模型对于早高峰时段单车需求量的预测具有优势,但是建立的模型无法对一天中其他时段的单车需求量进行预测。孔静[8]从时间、空间、外部、用户四个方面,对无桩式共享单车的出行特征和影响因素进行了分析,然后建立了基于BP神经网络的单车租还需求预测模型,但是在建立预测模型时仅考虑了共享单车需求变化的时间周期性,而没有将前文分析的影响因素融入预测模型中。Guido等[9]提出了一种出行数据与天气数据相结合的低维模型,来预测共享单车系统(BSS)的日需求量,结果表明,这两种元素的联合作用可以显著提高预测模型的精度,但是该文献仅对日需求量的预测进行了研究,没有具体到不同时段的需求量。
上述文献存在考虑因素较为单一、不全面[2,4],所用数据样本量少且透明性差[5,6]和无法预测时段需求[7,9]等问题。因此本文以共享单车为研究对象,通过挖掘单车的骑行大数据,就区域共享单车不同时段的停放需求量展开了研究,对影响共享单车停放需求的诸多影响因素进行分析和筛选,并借助多项Logit模型构建分区域分时段的停放需求预测模型。
1 共享单车出行数据
1.1 数据来源及数据说明
数据来源于2017年5月北京市摩拜单车的出行数据,字段包括订单编号、用户ID、单车ID、租车时间、租车位置、还车位置等,其中租还车的地理位置信息采用Geohash编码,利用PyCharm中的Geohash库对其进行编译转换得到相应的经纬度。数据说明如表1所示。
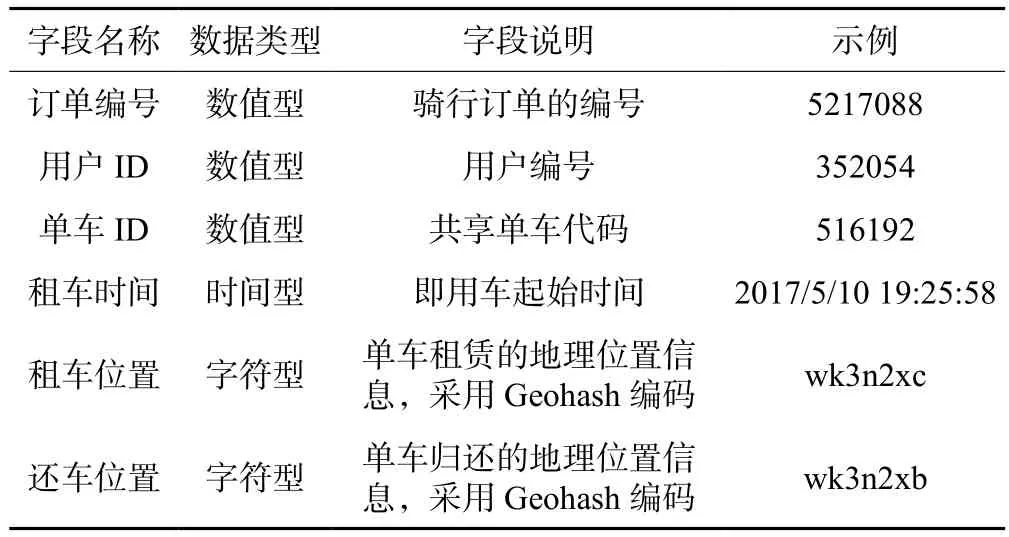
表1 共享单车出行数据说明Tab.1 Description of bike sharing trip data
1.2 数据预处理
由于信号屏蔽、信号不良、仪器故障和误操作等会导致共享单车数据出现异常[10],因此对原始采集的数据进行初步处理,可以提高数据分析的准确性。数据预处理包括:
(1)异常定位数据的剔除。当单车取用和停放的地理位置偏离北京市的地理坐标的经纬度值时,认为是异常定位数据,对其进行直接删除处理。
(2)异常骑行数据的剔除。数据的字段出现空缺、乱码或不匹配时,认为是异常的骑行数据,对整条数据予以剔除处理。
(3)冗余数据的剔除。为保证计算结果的准确性、并减少重复计算,对重复的冗余数据也进行剔除处理。
2 基于多项Logit模型的共享单车停放需求预测
2.1 模型变量的选取与量化
(1)因变量的选取与量化
首先,根据共享单车在不同时间段的需求分布情况,将一天划分为8个时段,分别是:0:00-7:00、7:00-9:00、9:00-12:00、12:00-14:00、14:00-17:00、17:00-20:00、20:00-22:00、22:00-24:00。据统计,不同小时停放量占比如表2所示。根据小时停放量将研究区域不同时间段的停放需求划分为:低停放需求、中停放需求和高停放需求三个类别,分别对应0~10辆,10~20辆和20辆以上停放需求量,用编码1、2和3表示,因变量编码如表2所示。
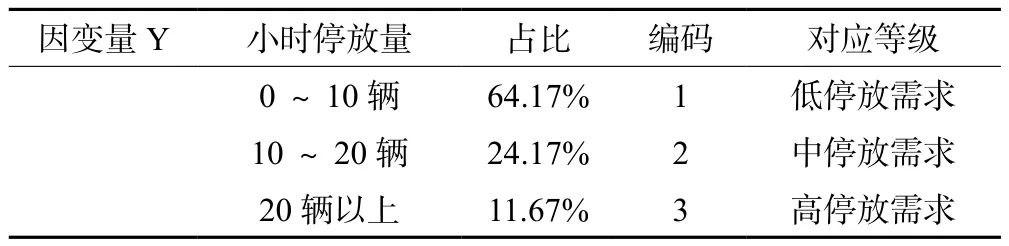
表2 因变量编码Tab.2 Dependent variable coding
(2)自变量的选取与量化
考虑时间、空间和天气因素的影响,选取12个因素作为初始的自变量,如表3所示,变量类型包括二分类变量、多分类变量和连续变量,多分类变量通过引入虚拟变量来表示。
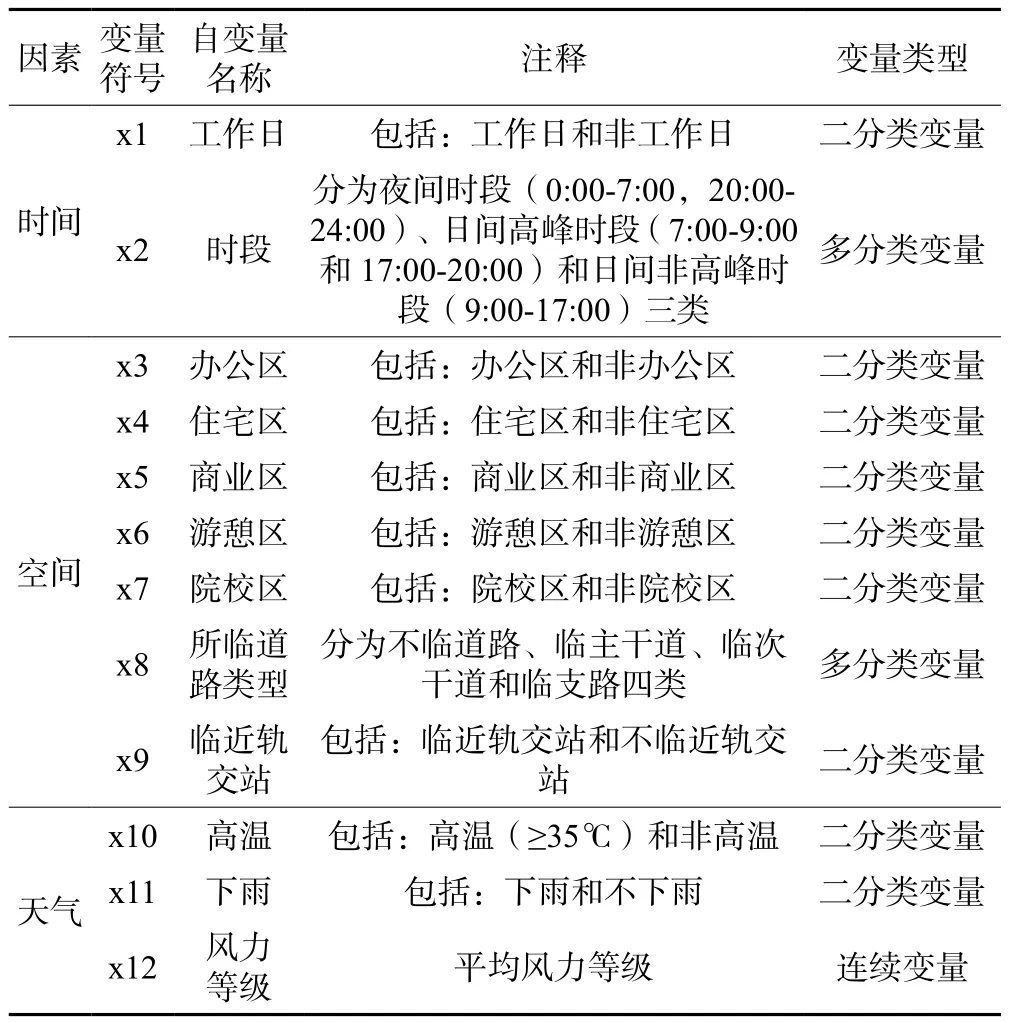
表3 自变量汇总表Tab.3 Summary of independent variables
2.2 模型的建立
Logit模型为概率型非线性回归模型,服从Logistic分布,是研究分类观察结果与多影响因素之间关系的分析方法,其基本形式为:
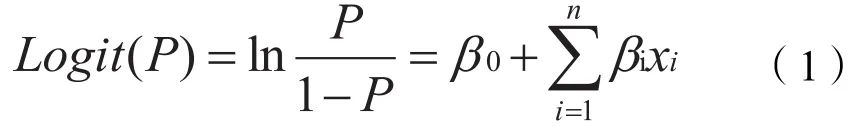
式中:P为某事件发生的概率;β0是截距;xi为第i个自变量;βi是xi对应的待估参数,表示在其他变量不变的情况下,第i个变量变动一个单位,Logit(P)值将变动βi个单位。
发生比(odds)为某事件发生的概率与不发生的概率的比值,对式(1)进行指数运算,得到观察值对应的发生比:
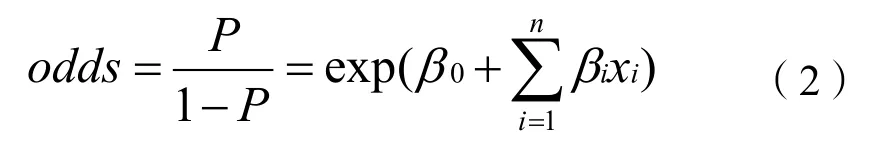
假设第i个变量变动1个单位后的发生比为odds*i,则有:
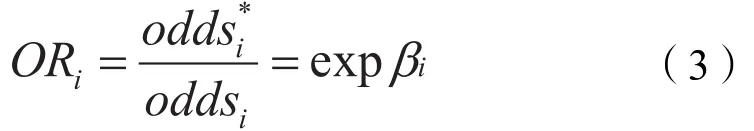
式中,ORi为发生比之比(odds ratio),此式表明,在其他变量不变的情况下,自变量xi变动一个单位,发生比之比ORi将变动expβi个单位。若ORi>1,则自变量xi对因变量有积极影响,且ORi值越大,该自变量对因变量的积极影响越大;若ORi<1,则自变量xi对因变量有消极影响,且ORi值越小,该自变量对因变量的消极影响越大。
2.3 模型的检验与预测准确率
(1)模型的检验
①Wald检验
Wald统计量可以对回归系数进行显著性检验,Wald检验的思想是:如果约束是有效的,那么在没有约束情况下估计出来的估计量应该渐进地满足约束条件,以无约束估计量为基础可以构造一个Wald统计量,这个统计量也服从(²分布,设定一个显著性水平α,根据Wald统计量判断自变量是否显著,如果显著性概率p值小于α,表明该自变量对因变量有显著性影响。
②类拟合优度指标(Pseudo R2)
也称为“似然比指数”(likelihood-ratio index),其基本思路类似于似然比检验,在于比较仅包含常数项的模型和包含所有解释变量的模型之间的似然值的相对大小,该值越小表明模型的拟合程度越低。其计算公式下:
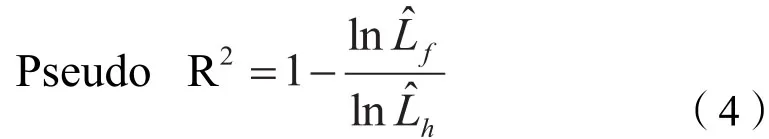
③AIC信息准则和BIC信息准则
AIC信息准则是衡量模型拟合优良性的一种标准,在回归分布建模过程中,AIC的值越小,说明模型拟合度越高。其计算公式如下:
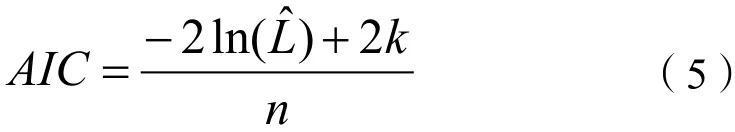
BIC信息准则:当采用AIC信息准则检验模型的拟合效果时,通常将BIC信息准则作为补充检验手段,同样,BIC的值越小,说明模型的拟合度越高。其计算公式如下:
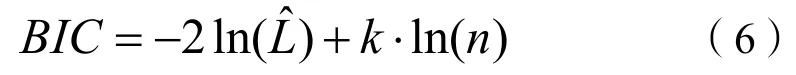
式中:为模型的对数似然值(likelihood);k是模型中参数的个数(包含常数项);n为模型中数据的数量。
(2)模型预测准确率
模型的预测准确率定义为被正确预测的数量与样本总量的比值,,该值越大表示模型预测越准确。其计算公式如下:

式中:Ⅴ为预测准确率;R为预测正确的样本量;S为样本总量。
3 实例分析
3.1 案例数据的采样
本文采用分层抽样的方法,即先将所有个体样本按照特征划分为几个类别,然后从每个类别中使用随机抽样的方法选择个体组成样本,由此得到600条样本数据,其中480条数据用来训练模型,120条数据用来验证模型。
3.2 因素显著性分析
利用Stata数据分析软件中的多项Logit模型对数据进行模型拟合和参数估计,设置低停放需求、夜间时段、不临道路为参照组。本文采用向后删除变量法筛选自变量,取显著性水平α为0.05。先将所有自变量纳入模型,然后对于在四种分类结果中显著性概率p值均大于0.05的自变量,每次剔除1个p值最大的自变量,直到模型中每个自变量的p值至少在一种分类结果中小于0.05,从而得到模型的参数估计结果,如表4所示。从中可以得出影响停放需求的显著性因素:
(1)以低停放需求为参照,中停放需求(Y=2)受到工作日、时段、商业区、临近轨交站、下雨和风力等级这6个变量的影响较大。
(2)与低停放需求相比较,高停放需求(Y=3)受到工作日、时段、商业区、所临道路类型、临近轨交站和高温这6个变量的影响较大。
以低停放需求为参照组,根据各显著变量的OR值,可以发现各影响因素对停放需求影响的程度:
(1)时间因素对共享单车停放需求的影响
工作日、日间高峰时段和日间非高峰时段对停放需求有积极影响。
与非工作日相比,在工作天出现中、高停放需求的概率分别上升257%-100% = 157%和701%。日间高峰时间出现中、高停放需求的概率,分别较夜间增加1 513%和14 204%;而日间非高峰时段出现中、高停放需求的概率分别较夜间增加1 005%和3 364%,说明日间高峰时段的影响更大。
(2)空间因素对共享单车停放需求的影响
空间因素中支路、临近轨交站会造成停放需求急剧上升:与不临道路相比,支路高停放需求出现的概率增加394%,而主干道高停放需求出现的概率减少83%。临近轨交站产生中、高停放需求的概率,较不临近轨交站分别上升292%及915%。商业区产生中、高停放需求的概率,较非商业区分别下降79%及86%。
(3)天气因素对共享单车停放需求的影响
下雨导致出现中停放需求的概率比不下雨低98.4%,说明下雨对停放需求有消极影响。随着风力等级的增大,中停放需求出现的概率增加24%,说明风力等级对停放需求的影响较小。高温对高停放需求有积极的影响,说明人们在炎热的天气仍然愿意选择共享单车作为出行工具。
综上,我们应该尤其关注工作日日间高峰时段轨交站和支路附近单车的停放状态,积极做好单车的调度和停放管理工作。
3.3 停放需求预测模型及检验
根据模型的参数估计结果建立回归方程如下:
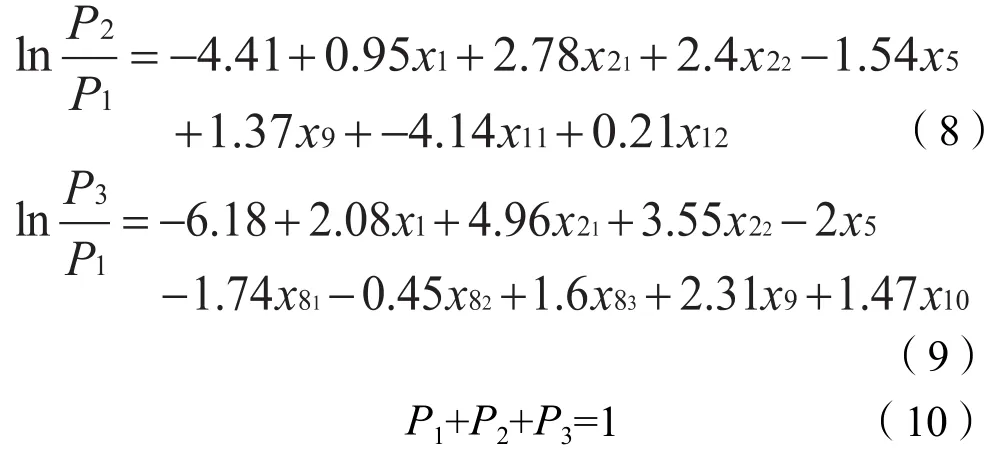
式中:P1、P2和P3分别为Y=1、Y=2和Y=3停放需求出现的概率。
利用Stata软件得到模型的拟合优度检验结果:Pseudo R2=0.317 6,可知拟合度良好。
初始拟合模型与剔除部分自变量后的最终拟合模型的AIC与BIC指标值对比:AIC值由621.834变为617.503 9,BIC值由747.047 6变为717.674 7,可知剔除不显著的自变量后,AIC和BIC指标值均有所减小,模型的拟合优度也更好。
对多项Logit共享单车停放需求预测模型进行实例验证,模型的预测结果如表5所示。多项Logit模型对类别1(低停放需求)的预测准确率最高,对类别2(中停放需求)的预测准确率最低。

表5 模型预测结果Tab.5 Prediction results of the model
4 结语
模型拟合结果表明:工作日、时段、商业区、所临道路类型、临近轨交站、高温、下雨、风力等级8个因素与共享单车停放需求相关,其中工作日、日间高峰时段、站点区域所临道路类型为支路、站点临轨交站会对共享单车的停放需求产生积极影响,而商业区、站点临主干道或次干道、下雨和大风会对共享单车的停放需求产生消极影响。
通过对模型预测准确率的计算发现建立的模型整体预测准确率达到77.5%,其中对类别1(低停放需求)的预测准确率最高,达到了86.49%。这对于根据共享单车的停放需求来规划不同区域共享单车站点的数量和规模以及系统调度有重要意义。
