基于新闻事件的科技情报逻辑依赖链生成方法
2022-03-11韩英昆曹建梅任金花邹立达
马 艳,韩英昆,曹建梅,任金花,刘 科,邹立达
(1.山东电力研究院,山东 济南 250003;2.国网山东省电力公司电力科学研究院,山东 济南 250003;3.山东财经大学,山东 济南 250014)
0 引言
科研选题预测与推荐是科技情报领域较新的应用需求。以往选题技术研究集中于图书行业,时间序列分析[1]、神经网络[2]、协同过滤[3]、个性化推荐[4]等方法得到应用。对于科研选题的研究,目前多针对文献检索工具[5]、选题案例分析[6]等展开。科技工作者选题目标的确定,常依赖于市场人员的反馈,二手信息导致科技与应用需求的脱节;又或者自己查阅科技文献,科技文献有一定的滞后性,无法给予科技人员最新的科技应用场景。
科研选题面临的数据具有维度高、数据量大的特点。科研选题过程中,科技工作者需要分析来自各个领域的数据,其常以浏览新闻的方式了解自身科技领域的需求与发展。较为先进的方法是通过主题的订阅,系统再基于推荐算法推送相关领域的文章给科技工作者。然而,这种被动接收信息的方式,使得科技人员不易洞察和分析应用市场与科学技术的联系及关联脉络;同时,也不易对热点事件的重要程度形成客观的认识。
比如,一位电网调度领域的科技工作者,需要了解自身领域的科技应用需求[7]。与此同时,以比特币为代表的虚拟货币的发展在国际社会成为重要的事件。“电网调度在比特币挖矿巨量耗电中有着重要的应用前景”,这句话有着如下的逻辑依赖链条“比特币——区块链—挖矿—显卡—功耗—用电量—电网调度”。如果没有前人总结,这种逻辑链条需要科技工作者阅读大量的比特币文章[8]才能够领悟。即使有人总结,科技工作者也会因为偶然阅读,不能了解其重要程度,从而错失了优先开展研究的机会。
因此,亟须设计一种科技情报逻辑依赖链生成方法,可以对当前的社会经济新闻收集、分析,形成热点新闻事件与科技人员领域的逻辑依赖链条,帮助科技工作者进行科研选题工作。
1 逻辑依赖链生成技术框架
提出一种基于新闻事件的科技情报逻辑依赖链生成方法,旨在自动化地筛选与跟踪社会热点事件,当热点事件涉及科技工作者的领域时,系统给出两者之间的逻辑依赖链条,以方便科技工作者及时了解与获取新的科研需求。
该系统框架的主要技术特征为:先模拟热量传导的现象找到热点事件的相关主题,再基于主题词热量极值出现先后时序及相关性确定主题词之间的逻辑依赖链。
图1 给出了基于新闻事件的科技情报逻辑依赖链生成技术框架,包括依赖热点事件获取模块、主题矩阵模块、逻辑依赖生成模块和科研方向推荐模块。

图1 科技情报逻辑依赖链生成技术框架
热点事件获取模块负责获得当前社会热点事件的热点主题词,以及以该热点主题词为主要主题的文章。主题矩阵模块负责生成与热点主题词相关的其他主题词,并将与热点事件的相关新闻加入主题文章库。逻辑依赖链生成模块负责生成从热点词到科技工作者关注领域的逻辑依赖链。形成“热点词—X1—X2—…—Xn”的逻辑依赖链,供科技工作者参考,其中X1…Xn表示技术领域词。科研方向推荐负责管理科技工作者的关注领域,并根据逻辑依赖链推荐科研方向文章。
2 逻辑依赖链生成方法
基于上述框架,图2 给出基于新闻事件的科技情报逻辑依赖链生成过程。

图2 科技情报逻辑依赖链生成流程
2.1 热点事件获取模块
热点事件获取模块用主题词代表热点事件,搜索下载以主题词ki为主要主题的文章,然后计算ki的热量,对于热量较大的ki才进行后续的挖掘;热量小的关键词说明其代表热点事件并不是一个具有广泛社会效应的事件,从而舍弃。
在搜索引擎网站,获取一个周期的关键词搜索排名。对排名前n的每个关键词做以下步骤:
1)设其中一个关键词为ki,利用爬虫工具搜索下载该周期内含有ki的新闻文章。
2)设h为一篇含有ki的新闻文章。基于隐含狄利克雷分布(Latent Dirichlet All·cation,LDA)[9]技术对h进行分析,若h中ki的权重最高,则认为h是ki的主题文章。
3)若h是ki的主题文章,将h标识为hki,并加入主题文章库。设ki的主题文章的集合为。
4)设主题词ki的热量为ei,则。其中,wh为ki在文章h中的LDA权重,ch为文章h的浏览量。
5)设γ为主题词最小热量阈值。若ei>γ,则认为ki是一个关注度较高事件的主题词,对ki的逻辑依赖链进行挖掘,将ki传递依次给主题矩阵模块;否则舍弃ki。
2.2 主题矩阵模块
主题矩阵模块接收热点事件获取模块的热点主题关键词,并模拟热量传导原理寻找与该热点主题关键词相关的其他主题词,模块实现步骤如下。
1)将接收的一个热点主题关键词kx加入待传导主题词库W。将kx加入事件主题词库Kx。
2)若W不为空,从W取出一个主题词,设为ki。将ki的热量传导到其他主题词。设kj为任意一个主题词,kj∈(K-ki),其中K为全部主题词库。kj被ki传导的热量设为ej,则,其中wi、wj为ki在文章h中ki、kj的LDA权重。
4)将kj加入W,返回2)继续执行。
步骤结束后得到的Kx即为kx相关的其他主题词,将Kx发送给逻辑依赖链生成模块生成kx的逻辑依赖链。
2.3 逻辑依赖链生成模块
逻辑依赖链生成模块首先计算各主题词热量最高的时刻,再根据时序及主题相关度形成kx与科技工作者关注主题的逻辑依赖链,模块实现步骤如下。
1)设科技工作者订阅的主题词集合为S。
2)若Kx∩S≠∅,则说明kx代表的新闻事件与科技工作者所涉及的领域相关。应挖掘Kx∩S中主题词与kx的逻辑依赖链。
3)若Kx∩S=∅,则说明kx代表的新闻事件与科技工作者所涉及的领域不相关。不再挖掘kx与科技工作者所涉及的领域的依赖关系。转到主题矩阵模块挖掘继续挖掘其他的kx。
4)对于所有的ks∈Kx∩S执行5)—8)步骤。
5)设kx为此次挖掘的热点事件的主题词,设H为kx以及kx相关主题词的主题文章集合,即H=。
6)计算所有Kx中主题词热量最高时刻,设kj|kj∈Kx热量最高的时刻为tj。把周期分为若干个时间段,在ty时间段内,kj的热量为是指在ty时间段内含主题kj的文章。热量最高时刻即为tj=ty|max(ey)。
7)设Ls为ks的依赖链,ks为Ls最后一个主题词,也即科技工作者订阅的主题词。基于直接依赖词查找方法(在步骤8说明)依次生成ks直接依赖词、第一间接依赖、第二间接依赖……,直到依赖词为kx,则Ls结束完成。Ls生成完毕后,其形式为Ls=kx≫…ki≫…≫ks。其中,ki是ki+1的直接依赖主题词。
8)ki的直接依赖词查找方法如下:
(a)Kx=Kx-ki。
(b)对于所有kj∈Kx且tj<ti,计算kj与时间ki关联度mi,j,。其中,Hi,j为H中在(tj-α,ti+α)时段同时含有ki与kj主题文章的集合,α是时间松弛系数。hi,j为Hi,j一篇文章,wi与wj为hi,j中ki与kj的LDA 权重。其中,Ti,j=tj-ti+2α,为hi,j的点击量。
(c)ki的直接依赖词为kd=kj|max(mi,j),kj∈Kx。
2.4 科研方向推荐模块
科研方向推荐模块向科技工作者推送基于前面介绍的3 个模块生成的逻辑依赖链。具体地,若ks为科技工作者订阅主题词,且Ls成功生成,则推送。在推送的时候,Ls上每个主题词可以附上点击量较大且与前后主题密切相关的文章超链接。
3 试验性能
本文提出的逻辑依赖科研方向推荐方法(Related Link of Logic Judgment,RLLJ)包括依赖热点事件获取、主题矩阵、逻辑依赖生成和科研方向推荐4 个模块。将主题矩阵和逻辑依赖生成模块分别简称为主题矩阵方法(Related Link,RL)和逻辑依赖链生成方法(Logic Judgment,LJ),其是提出方法RLLJ 的核心算法,决定了方法的有效性和准确率。为了验证基于热量传导方法的性能,首先给出两个直观方法的定义,使其与本文所提出的算法进行比较。
首先,定义一种直观相关主题生成方法(Intuitively Topic Gereration,ITG)。这种方法与模块二主题矩阵模块的功能相同,只不过模块二是通过模拟热传导方法生成相关主题。以下是用ITG方法搜索ki为主题词相关主题库的步骤:
1)对于∀kj∈K,K是全词库。
2)ki,kj的相关性用如下公式定义,

3)当ei,j大于一定的阈值时,则认为ki,kj相关。将kj加入主题库Ki。
4)对Ki所有主题词迭代地重复执行步骤1),直到所有kj∈Ki的相关主题词都搜索过。
其次,定义一种简单直观的逻辑依赖链生成算法(Intuitively Logic Dependency Generation,ILDG)。以下是用ILDG方法生成逻辑依赖链的步骤:
1)设ks为用户订阅主题词,设kx为热点主题词,目标是生成kx到ks的逻辑依赖链Ls。
2)令ki=ks。
3)在Kx中查询ki的直接依赖。
4)Kx=Kx-ki,对∀kj∈KX,计算
5)选择kj|max(mi,j),kj∈KX,为ki的直接依赖主题词。Ls=kj≫Ls
6)令ki=kj,重复执行步骤3)—6)直到kj=ks。
基于上述定义,我们通过仿真试验对比验证提出算法的性能。
首先,基于爬虫下载一个周期的文章库H,分别使用ITG 和RL方法生成相关主题。从图3可以看出,ITG挖掘的主题库非常大,当其与用户订阅主题集相交时,几乎需要对用户推荐所有订阅主题,即要对用户的所有订阅主题生成逻辑依赖链。ITG 方法冗余大,对用户推荐的信息过量,使用户不能聚焦有用的信息。而RL 挖掘出的主题库与用户订阅主题集重合的数量少,可以针对性生成逻辑依赖链,用户可专注于有用的信息。

图3 ITG与RL挖掘主题库对用户的影响
接着,试验分别基于LJ 与ILDG 生成Ls。如图4所示,横坐标是Kx初始数量;纵坐标为Ls的长度。可以看出,ILDG 没有考虑时序的因素,其长度几乎接近Kx规模,产生较多冗余信息,没有参考价值。LJ 同时考虑时序与相关性的因素,可将Ls长度控制在个位数,能准确高效表达主题之间的逻辑依赖关系。
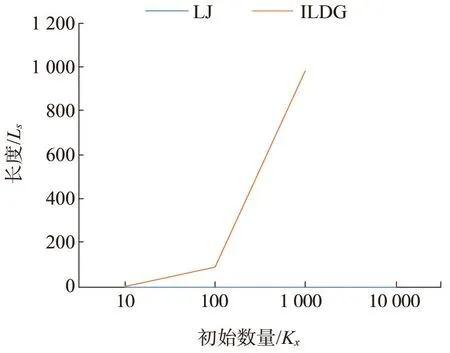
图4 LJ与ILDG生成逻辑依赖链有效性比较
最后,为验证提出算法RLLJ 的效果,试验给出人工生成Ls的方法,即给定kx与ks,根据领域专家的搜索,人工生成Ls。设人工生成的Ls为L′s。
定义重合率为:给定kx与ks,RLLJ 与人工生成Ls方法主题词相同的占比,即重合率表示逻辑依赖的链的长度。
定义优秀率:给定Kx、kx与ks,分别用RLLJ与人工的生成Ls,经用户盲选,用户认同RLLJ生成的Ls视为RLLJ优秀。进行多次试验,优秀的占比成为优秀率。
图5 给出了试验比较结果,横坐标为Kx初始数量;纵坐标为比率。可以看出,重合率随着Kx规模增加而减少,说明RLLJ与人工生成算法在Kx规模大时有较多的分歧。观察优秀率,可以发现随着Kx规模增加而增高,这是人工方法中由于人的精力限制在大量主题面前会出现较多失误。

图5 算法的重合率及优秀率
4 结语
提出一种基于新闻事件的科技情报逻辑依赖链生成方法,通过模拟热量传导现象找到热点事件相关主题,再基于主题词热量极值出现先后时序及相关性实现主题词逻辑依赖链的确定。该方法使科研工作人员更加容易地了解热点事件与自身关注技术的逻辑关系,更加容易总结热点事件在技术领域的应用需求,帮助科研工作人员实时快速地跟踪与自己研究领域相关的社会热点事件。试验验证了提出算法具有较高的针对性,专注于对用户有用的信息。算法还可准确高效表达主题之间的逻辑依赖关系,尤其在主题词规模较大时,具有高达70%的优秀率。
