融合半变异函数的空间随机森林插值方法*
2022-03-11王铭鑫高秉博任周鹏李发东
王铭鑫,范 超,高秉博**,任周鹏,李发东
(1.中国农业大学土地科学与技术学院 北京 100193;2.武汉大学遥感信息工程学院 武汉 430079;3.中国科学院地理科学与资源研究所 北京 100011)
土壤是农业生产的基础,土壤环境属性影响耕地的生产能力与粮食安全。土壤受到重金属污染后不仅会影响作物的产量和农产品的安全,危害人类健康,还会进入水体和空气,造成次生生态环境问题。我国由于近些年工业迅猛发展、农业化学水平提高、城镇快速扩张以及对环境保护的忽视,使得大量的有毒有害物质进入土壤,造成了严峻的污染形势。精确的环境污染空间分布图是开展各项污染风险管控和防治工作的基础。由于目前土壤环境污染以实地采样调查为主要手段,成本较高,样点分布相对稀疏。因此,需要采用空间插值方法基于样本数据完成区域土壤环境属性分布图。然而,由于土壤污染具有较强的空间异质性,为空间插值精度的提升带来较大的挑战。
目前,土壤环境属性空间插值方法主要分为基于空间位置关系信息的插值、基于属性相似信息的插值以及融合空间位置关系信息和属性相似信息的插值方法。基于空间位置关系信息的插值以描述空间自相关性的地理学第一定律和描述空间异质性的第二定律为基础。基于地理学第一定律包括最邻近点插值、反距离加权、径向基函数和局部多项式等确定性插值方法,以及普通克里金、简单克里金和指示克里金等地统计方法。与确定性插值方法相比,地统计方法能在给出无偏最优插值结果的同时,得到对插值结果的不确定性估计,因此应用较为广泛,但是难以解决土壤环境属性的空间异质性问题。各向异性半变异函数方法、三明治方法、空间分层异质性方法等空间插值方法在考虑空间自相关性的基础上,考虑到对空间异质性的处理,能一定程度上解决土壤环境属性空间异质性插值问题。
基于属性相似信息的插值方法以地理学第三定律为基础。地理学第三定律认为:具有相似地理环境的两个点(区域),其目标变量具有相似(近)的取值。包括相似度度量法、Soil-Land Inference Model(SoLIM,土壤-环境推理模型)、回归方法和可以处理多变量的岭回归、lasso 回归、随机森林、提升树和支持向量机等监督学习方法。基于属性相似信息的方法可以充分利用土壤污染来源及其影响因素等辅助变量数据,改善土壤环境属性的插值精度。但是由于土壤环境污染源及其影响因素数据难以全部精确获得,同时为了防止模型过拟合,因此模型会产生残差。由于污染物的扩散迁移特性,残差往往具有空间自相关性。因此在考虑属性相似性的基础上,综合应用空间位置关系信息能够提高空间插值精度。
融合空间位置关系信息和属性相似信息的插值方法包括空间滞后模型、空间误差模型、空间变系数回归和地理加权回归等空间回归方法,以及协克里金、回归克里金和因子克里金等地统计方法。其中回归克里金是数字土壤制图领域应用最为广泛的一种插值方法。但是当辅助变量较多且包含较多类型变量时,回归克里金处理多变量的能力不足,难以有效利用土壤环境属性空间插值所涉及的多维辅助变量信息。
机器学习方法在处理高维辅助变量方面具有独特的优势,但是主流的机器学习方法仅能利用多维辅助变量信息,并没有融合空间位置关系信息进一步改进插值精度。如何将空间位置关系信息融入机器学习方法改进土壤环境空间插值精度成为目前数字土壤制图领域最前沿的研究方向之一。Sekulić等提出了随机森林空间插值法(random forest spatial interpolation,RFSI)。该方法将邻近若干样点的空间横、纵坐标和目标变量作为单独的属性加入随机森林,以改进空间插值结果。但是该方法分离了样点位置与目标变量之间的关系,未能融合空间位置关系信息和属性相似信息。Hengl 等提出的随机森林空间预测框架(random forest for spatial predictions framework,RFsp),将到样点的距离作为预测属性加入随机森林方法,将位置关系信息有效反映在预测属性中,完成了空间位置信息和属性相似信息的融合,可用于改善土壤环境属性插值精度。但是土壤环境变量的空间变异并不一定与距离呈现线性关系。因此,为了进一步改进土壤环境属性插值精度,本文在随机森林空间预测框架的基础上,将空间距离替换为空间半变异值,融合随机森林与地统计中的空间半变异函数,提出了融合半变异函数的空间随机森林插值方法(spatial random forest with semi-variogram interpolation,SRFsei),以充分融合空间位置信息和属性相似信息,提高土壤环境属性的空间插值精度。并以湖南省湘潭县北部部分乡镇的土壤重金属数据作为案例,对比分析了该方法的空间插值效果。
1 面向土壤环境插值的空间随机森林方法
1.1 随机森林
随机森林是一种基于分类回归树的集成学习方法,由多个具有高预测精度和低相关性的分类回归树组成。该方法通过随机选取样点和特征的重采样训练多个分类回归树,在预测时综合多个分类回归树的结果,提高预测精度并解决过拟合问题。其基本流程如下:
1)从原始训练集中采用bootstrap 抽样抽取个样本和个属性;
2)将个样本分别建立个分类回归树,完成模型训练;
3)对于待预测点,将其带入个分类回归树,得到每个分类回归树的预测结果;
4)综合个分类回归树的预测结果,给出对待预测点的最终预测结果。
随机森林(RF)是一种集成学习方法,最终预测结果一般是个分类回归树结果的平均值,如公式(1):
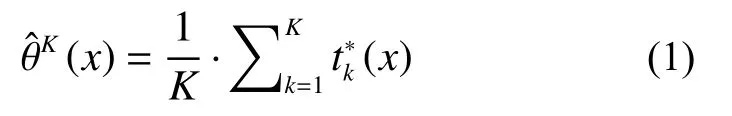
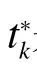
1.2 随机森林空间预测框架
RF 在建模的过程中忽略待估计点与样本点之间的空间自相关性,可能会导致预测结果不准确,出现过高估计和过低估计,尤其是在目标变量的具有较强的空间自相关性时。为了弥补这项不足,Hengl 等提出了随机森林空间预测框架(RFsp):

式中:()为空间点上的目标变量取值;为辅助变量;为遥感图像的光谱信息;为空间距离属性,即距离空间样点的距离。RFsp 将与样点的距离作为辅助变量加入预测变量,并利用随机森林方法处理多维预测变量,实现了辅助变量信息与位置关系信息的融合。Hengl 等已经证明,随机森林与线性地统计建模和克里金等技术相比,其优点在于不需要遵循平稳性假设,且当样点具有代表性,而目标变量、协变量和空间依赖结构之间的关系是复杂的、非线性的情况下,可以改进空间插值结果。
1.3 融合半变异函数的空间随机森林方法
随机森林空间预测框架(RFsp)采用空间距离关系反映样点之间的空间位置信息。但是由于模型构建的最终目标是实现土壤环境属性的精确插值,而空间位置信息并未直接与土壤环境属性的空间变异关联,同时土壤环境变量的空间变异并不一定和距离呈线性关系,因此本文提出结合地统计空间半变异函数的改进方法,即融合半变异函数插值的空间随机森林方法(spatial random forest with semi-variogram interpolation,SRFsei)。该方法的定义如公式(3):
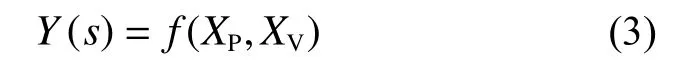
式中:是基于空间位置关系和空间半变异函数所得的变量组,其中每一个变量的取值为待估计点到单个样本点之间半方差的平方根,定义如公式(4):

式中:h为待估计点到样点的距离,γ()为空间半变异函数,定义如公式(5):

式中:()为一区域化随机变量,为两空间点之间的距离,(s)和(s+)分别是区域化变量()在空间位置s和s+处的值,()表示在空间上所有距离为的离散点对的数量。通过样本点计算半方差后,可以采用球状模型、高斯模型和指数模型等拟合,获得空间半变异模型的函数形式。空间半变异函数由模型类型、基台值(Sill)、变程(Range)和块金值(Nugget)唯一确定。“基台值”是半变异函数随着距离增加达到一个相对稳定的常数的值;“块金值”指的是间隔距离=0 时的半变异函数值,块金值是由于混合样的存在和测量误差造成的;“变程”指的是变异函数达到基台值时的间隔距离,当两点间的间距大于等于变程(range)时,区域化变量(s)的空间相关性消失。
2 案例研究
2.1 研究区描述
研究区为湖南省湘潭县北部5 个乡镇(112°57′E,27°46′N),如图1所示,总面积为522.46 km。研究区位于湘江东岸,主要地貌类型为低山、丘陵和平原,属亚热带季风湿润气候。2011年共采集688 个农田土壤样本点,并使用火焰原子吸收光谱法分析了土壤的Cr 含量。本研究以土壤Cr 含量为目标变量。
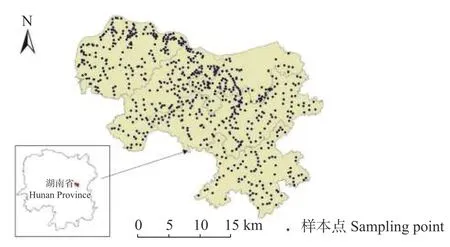
图1 研究区域及样点分布Fig.1 Study area and sampling point
目前已有多项研究证实地形(例如海拔高度、坡度等)、土壤类型、土地利用类型是Cr 分布的重要影响因子。海拔高度通过土壤侵蚀来影响重金属的迁移,土壤类型和土地利用类型影响重金属的累积状况。因此,本文选取土壤类型、土地利用类型、海拔高度、坡度等因素作为土壤重金属含量插值研究的辅助变量。各因子的空间分布情况如图2所示。
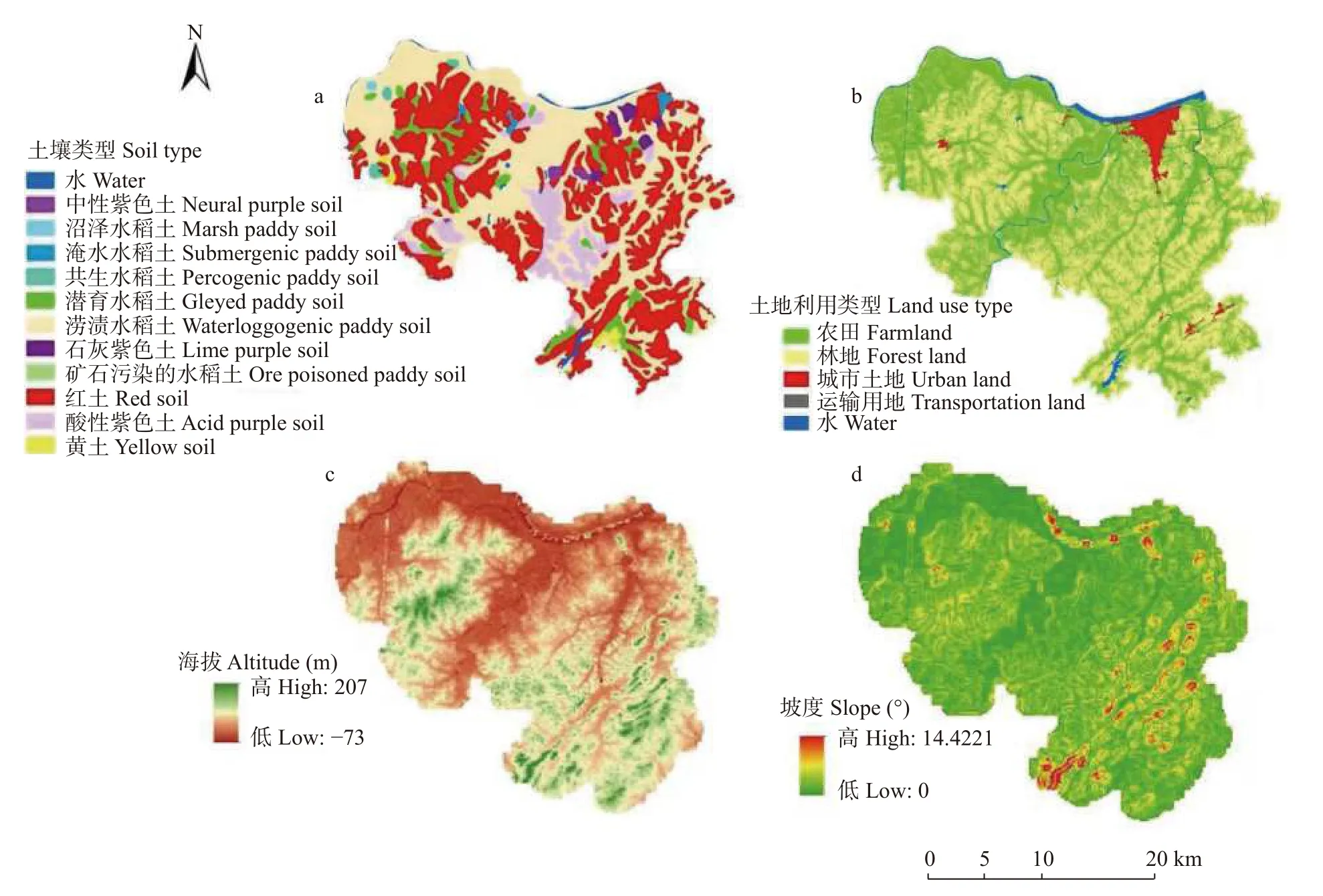
图2 研究区辅助变量土壤类型(a)、土地利用类型(b)、海拔(c)和坡度(d)的映射Fig.2 Mapping of auxiliary variables in the study area.a:soil type;b:land use type;c:altitude;d:slope.
2.2 试验方法
对于研究区采样数据,分别采用本文提出的SRFsei 方法、RF、RFsp、普通克里金(Ordinary Kriging,OK)和泛克里金(Universal Kriging,UK)方法进行插值,通过交叉检验对比不同方法的插值精度。所有对比试验均采用R 语言实现,空间半变异函数、OK和UK 使用gstat 实现,随机森林训练和预测基于ranger 包实现。为了比较不同插值方法的结果,采用平均绝对误差(MAE)和均方根误差(RMSE)表征插值精度,两个指标可以避免正负偏差互相抵消的情况,用来量化预测结果的平均误差。MAE 和RMSE的计算方法如下:
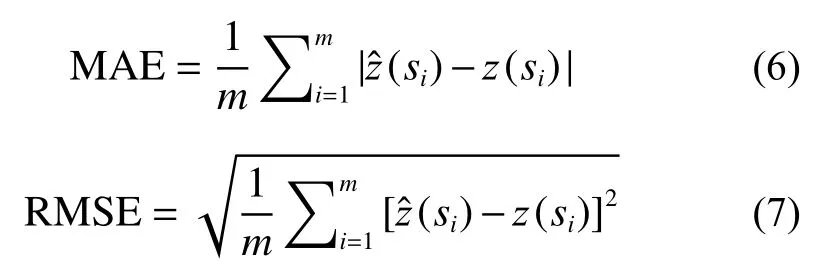
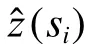
为了对比SRFsei 方法相比其他插值方差的插值精度改进程度,本文定义了改进程度指数,如公式(8):
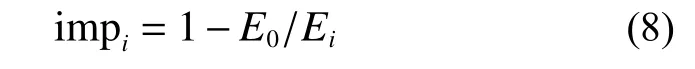
式中:imp为SRFsei 方法相比第种方法的插值精度改进程度指数;为SRFsei 方法的插值误差,可以是MAE或RMSE;E为作为对比的第种方法的插值误差,可以采用MAE或RMSE,但需要与 E对应一致。
处理覆盖整个研究区域的辅助变量数据,在此基础上,使用全部采样点,采用SRFsei 方法、RF、RFsp、普通克里金(Ordinary Kriging,OK)和泛克里金(Universal Kriging,UK)方法对整个研究区域的Cr 含量进行插值制图,获得插值制图结果和不确定性估计结果。
2.3 结果与分析
原始样本的Cr 含量的变异函数图如图3所示,利用研究区域数据和R 语言工具绘制出图。使用如公式(9)所示的球状模型拟合:

图3 研究区Cr 含量半变异函数Fig.3 Variation function of Cr content in the study area
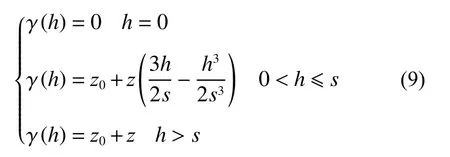
式中:为块金效应常数,为拱高,+为基台值,为空间依赖范围,即变程值。
其中,研究区域内土壤中Cr 含量的变差函数的变程值为6421.279,块金值为77.3,基台值为369.7。块金值与基台值之比(基底比)是表示空间自相关性程度的指标,一般认为该值为25%和75%是区分相关性程度等级的两个分界值,如果该比值小于25%,则空间相关性程度很高;如果比值在25%~75%,则空间相关性程度为中等;如果比值大于75%,则由随机变化引起的空间变异性程度较大。本文土壤中Cr含量的变差函数的块金值与基台值比率为20.9%,说明研究区域内土壤中Cr 含量存在着较强的空间自相关性。
本文提出的SRFsei 与RF、RFsp、OK 和UK 的插值交叉检验结果如图4所示。由图4 中MAE 结果可知,SRFsei 具有最小的空间插值误差,OK 具有最大的空间插值误差,UK 由于采用了辅助变量,插值精度较OK 有所改善。RF 和RFsp 比OK 和UK有更好的插值精度,在RF 和RFsp 中,RFsp 由于考虑了空间位置关系,插值精度更高。图4 中RMSE结果与MAE 基本一致,SRFsei 具有最优的插值精度,OK 具有最大的RMSE。与MAE 不同之处是RFsp方法的RMSE 大于RF 方法。

图4 不同插值方法交叉验证结果的平均绝对误差(MAE)和均方根误差(RMSE)Fig.4 Mean absolute error(MAE)and root mean square error(RMSE)of cross-validation results of different interpolation methods
SRFsei 相对传统的OK 和UK 方法在MAE 和RMSE 上的改进均大于10%。相比RF,SRFsei 在MAE上的改进为6.52%,在RMSE 上的改进为5.34%。而相比RFsp,在MAE 上的改进为5.97%,在RMSE 上的改进为6.49%。从交叉检验结果可知,SRFsei 相比传统的地统计方法有较大的插值精度提升,而相对于新型的机器学习方法精度提升有限。
采用全部688 个样点的数据基于SRFsei 方法对研究区空间插值制图如图5所示。其中图5a 为插值制图结果,图5b 为插值不确定性结果。由图5a 可知,研究区域中东部污染较为严重,西北部污染较轻。由图5b 可知,研究区域绝大部分的插值误差标准差小于5,误差较大的区域主要集中在污染较严重的中部区域。图中黑色方框所示部分与白色方框所示部分具有相同的污染浓度,但是从误差图中可以得出,黑色方框所示部分具有较小的插值误差,因此可以确定该部分污染较为严重,而白色方框部分误差较高,因此该部分的插值结果具有较大的不确定性。如需更精确地掌握污染情况,还需要进一步展开加密采样调查。
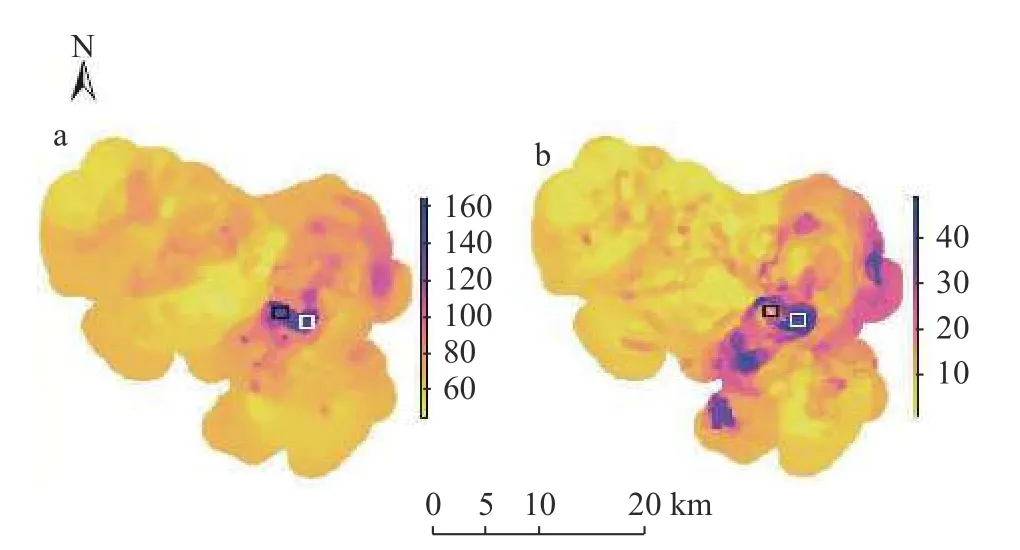
图5 融合半变异函数的空间随机森林插值法的插值结果图(a)与误差标准差图(b)Fig.5 Interpolation results(a)and standard deviation variance of error(b)of spatial random forest with semivariogram interpolation
RF、RFsp、UK 和OK 对研究区域的插值制图结果及其不确定性估计图如图6所示。土壤Cr 含量插值结果总体相似,但在局部上差异明显:其中OK和UK 的插值结果,东南部区域由于协方差矩阵是奇异矩阵,没有计算出插值结果。相比较OK 方法,其他方法由于使用了辅助数据,因此具有更丰富的细节信息。而RF 方法,由于没有利用空间自相关性,插值结果存在不自然的非平滑变化。RFsp 插值结果中,存在条带化现象。相比其他方法,SRFsei 插值结果包含了更丰富的细节信息,空间变化也更加合理。

图6 不同插值方法的插值结果图(a)及误差标准差图(b)Fig.6 Interpolation results(a)and standard deviation variance of error(b)of different interpolation methods
3 结论
本文基于随机森林空间预测框架,通过结合随机森林方法与空间变异函数,提出了融合半变异函数的空间随机森林方法(SRFsei)。该方法在空间插值建模和预测中能够将反映土壤环境污染源及影响因素的多维辅助变量信息与空间变异信息有效结合,同时考虑属性相似性信息和空间位置关系信息,因而可以有效提高插值进度,得到更为可靠的插值结果。湖南省湘潭县北部乡镇土壤重金属数据插值案例结果表明,本文所提出的方法相较于其他传统地统计的OK 和UK 方法插值精度提升10%以上,相较于新型的机器学习空间插值方法的插值精度提升5%以上。同时,其插值制图结果具有更丰富的细节信息和合理空间变化。因此,本文所提出方法较适用于具有复杂空间异质性的土壤环境变量下的空间插值。但是其插值效率还有待进一步在其他区域应用中检验。
