基于数据增强的领域知识图谱构建方法研究
2022-03-11钱玲飞崔晓蕾
钱玲飞 崔晓蕾






摘要:[目的/意义]探究使用大数据技术解决传统制造业知识管理问题的方法,实现对专利知识的自动抽取和结构化构建,提高信息检索效率和利用率。[方法/过程]结合深度学习技术,提出了一种面向非结构化专利信息的知识图谱自动构建方法,在BiLSTM-CRF的基础上引入预训练模型实现对实体和开放式关系的自动抽取,并基于迁移学习进行数据增强提升抽取效果;改进实体关系抽取模型提升三元组结构识别的准确率;最后将其存储到Neo4j图数据库中进行领域知识图谱的构建。[结果/结论]本文提出的方法解决了信息抽取在专业领域样本量少的问题,对专利三元组识别的准确率达到了94.71%,构建的知识图谱能够满足企业创新知识管理和竞争情报获取的需求,提升企业知识的可重用性。
关键词:专利;数据增强;信息抽取;三元组识别;新能源汽车电池技术领域
近来,企业知识产权保护意识和创新意识不断提升,专利文献的数量也随之不断增长,在信息化建设仍然未全面普及的传统制造业,难以对海量的文献数据进行科学的管理和利用。随着“中国制造2025”[1]“两化融合”[2]的提出,制造业向智能制造的转型升级是未来发展的必然趋势。然而,目前国内中小制造业企业正面临着信息化建设成本高,人才少,缺乏信息化建设具体实施方案等诸多问题[3]。专利文本作为制造业创新型文献,主要以非结构化或半结构化形式存储,对其挖掘领域知识并建立领域知识图谱能够提升知识的可重用性,帮助企业进行流程化的知识管理和存储。本研究将深度学习技术运用到领域知识图谱的自动构建,旨在融合大数据技术帮助传统制造业进行内部知识管理,整合技术资源,解决在无可用知识库情况下高质量领域知识抽取的问题,降低中小企业信息化建设成本。
1相关研究
1.1知识图谱发展研究现状
知识图谱的概念最早在2012年由谷歌公司提出[4],其本质上是一个语义网络知识库,主要分为知识抽取和图谱数据存储两个部分。知识抽取主要是从结构化、半结构化甚至非结构化的文本中挖掘有价值的信息[5],数据存储则是将抽取出的信息进行集成。知识图谱的存储表现形式由节点和边组成,节点即实体,边即实体间的关系,知识通过这种方式集成后可以表现为结构化形式,便于知识的结构化管理和检索。
国外知识图谱技术进展较为迅速,目前发展较为成熟的知识图谱有DBpedia[6]、YAGO[7]等。DB⁃pedia通过从维基百科抽取结构化结果,强化维基百科的检索功能,包含95亿事实三元组;YOGA包含1.2亿条三元组数据,相比DBpedia引入了时间、空间知识。国内知识图谱技术起步较晚,同样集中在百科知识图谱领域,百度知识图谱基于百度百科构建而成,不仅能够提升搜索效率,还可以为企业多领域业务提供知识基础。
当前发展较完善的知识图谱大多针对通用领域,但学术界已有部分学者开始进行关注专业领域知识图谱的构建,XuR等[8]基于半监督学习从生物医学文献中抽取疾病风险关系,建立生物医疗知识库;XuJ等[9]利用BioBERT模型从PubMed摘要中提取生物实体、作者、基金关系等数据,构建了PubMed知识图谱用于后续知识分析;廖开际等[10]针对在线医疗问答社区数据量大、规范性差、数据稀疏等问题,构建在线医疗社区问答知识图谱助力个性化医疗;杨波等[11]基于企业风险知识构建知识图谱,引入时间维度动态观测企业面临的风险因素。领域知识对于企业来说既是重要的竞争情报,又是企业创新的坚实基础,因此对领域知识进行有效的管理和存储是十分必要的。本文选取包含领域专业知识丰富的专利文本作为领域知识图谱构建的数据来源,专利文本作为工业界的重要技术资源,包含了最新的工艺技术信息及领域词汇,便于获知更多的领域技术信息。当前少有研究针对新能源汽车电池技术领域构建知识图谱,本文将选取新能源汽车电池技术领域为研究对象,进行领域知识图谱构建。
1.2实体关系抽取国内外研究现状
实体关系抽取作为知识图谱构建的基础,主要由实体识别和关系识别两部分构成。目前实体识别的研究已经取得了一定的进展,传统的机器学习模型有隐马尔可夫模型(HMM)[12]、条件随机场(CRF)[13]等。随着研究者对深度学习研究的不断深入,HammertonJ[14]首先将LSTM模型应用于实体抽取领域;此后,HuangZ等[15]提出在条件随机场模型的基础上加入双向长短时记忆神经网络(BiLSTM)来挖掘上下文信息,提高模型效果。ZhaiZ等[16]在BiLSTM-CRF模型的基础上引入EMLo预训练模型,增强数据的语义表示。目前在命名实体识别基础研究领域已有大量的高质量开源数据,但在特定领域,样本数据缺乏是信息自动抽取的难点之一。马建霞等[17]依托于文物资源数据库对训练样本进行规则映射,解决了文物领域数据标注的问题;彭博[18]基于规则库和知识库对生态治理技术领域文献进行实体标注。在没有可应用的领域本体及术语词典的情况下,人工标注的工作量繁重,需要耗费巨大的时间成本。因此,本文将在小样本标注的基础上,基于迁移学习思想进行数据增强,旨在获取精确度更高的领域知识用于领域知识图譜的构建。
关系识别可分为限定关系识别和开放关系识别。传统实体关系抽取研究大多基于限定关系,GiorgiJ等[19]基于BERT预训练模型提出了端对端的实体关系识别;ChenL等[20]对英文专利文本中的实体关系进行注释,提出了基于SAO法的实体关系抽取框架。限定关系抽取作为一个多分类问题,通常分类粒度较粗,包含的语义信息有限,为此,BankoM等[21]提出开放关系抽取的概念,即无需预先定义关系类型,从文本中提取所有能找到的语义关系。开放关系识别可以看作关系抽取和实体关系识别两部分,StanovskyG等[22]将开放信息抽取问题转化成序列标记问题,基于BiLSTM算法扩展了深层语义角色标记模型并取得了突破性的进展;罗耀东[23]利用基于语义角色标注的BiLSTM深度模型运用于湿地文献数据关系抽取,并对实体关系进行识别和匹配。现阶段开放关系识别的研究较少,本文将在实体识别阶段加入开放关系识别,并利用关系识别分类算法对抽取出的实体关系三元组进行识别,最终作为知识图谱构建的基础数据。
2基于深度学习的领域知识图谱构建模型
本文提出一种基于深度学习的领域知识图谱自动构建方法,实验流程主要分为数据预处理、领域知识抽取、三元组识别及知识图谱可视化4个部分。
2.1领域信息抽取模型构建
为解决领域内语料数据不足的问题,本文将对已标注的训练数据进行数据增强来提升信息抽取的效果。传统的数据增强方法包括同义词替换、随机插入、随机交换和随机删除[24],但领域知识往往包含大量专业词汇,结构固定,传统数据增强方法并不适用,因此,本文引入迁移学习思想进行数据增强的研究。
迁移学习[25]是指将从之前训练任务中学到的知识应用到新的训练任务中,主要分为样本迁移、特征迁移、模型迁移和关系迁移。其中,特征迁移[26]可以在文本特征分布相似的情况下,借助历史标记数据以解决目标项目训练实例过少的问题。本文选取的数据为新能源汽车电池技术领域的专利文本,具有领域分支少、文法结构相似等特点,通过特征迁移的方法对人工标注的少量样本数据进行数据增强,提升信息抽取模型訓练效果。
信息抽取模型主要分为文本的多维向量映射和语义特征提取两个方面。文本的多维向量映射即文本的语义表示,传统的语义表示方法,例如Onehot、Word2vec、Glove等,使用一个词向量对应一个词语,包含的语义信息有限;现阶段使用较多的是预训练模型,例如EMLo预训练模型和BERT预训练模型,能够表达出词语在不同语境下的语义信息。预训练模型通过对大量语料进行无监督学习来获取丰富的语义特征,相比于EMLo模型,BERT将模型结构由LSTM更改为Transformer,解决了长依赖的问题,并通过遮蔽语言模型(MaskedLan⁃guageModel,MLM)和下一句预测(NextSentencePrediction,NSP)两种预训练任务,分别从预测遮盖词和预测下一句两个方面学习文本的语法、语义及句间关系[27]。
文本的语义特征主要通过神经网络来进行提取,本文选取的基准模型为双向长短记忆神经网络模型[28](Bi-directionalLongShort-TermMemory,BiLSTM)和条件随机场模型[13](ConditionalRandomField,CRF)。在双向长短记忆神经网络中,前向的LSTM模型可以存储上文信息,后向的LSTM模型可以存储下文信息,因此,BiLSTM模型能利用上下文信息对文本数据进行特征提取,由于上下文的语义信息对实体词、关系词的序列标注具有重要意义,BiLSTM能够使得模型对当前位置的信息预测更加准确。传统的序列标注算法通常在BiLSTM层后直接接入Softmax函数进行文本标签值的输出,但BiLSTM模型无法处理相邻序列值之间关系,为了减小这一影响,本文在BiLSTM后接入CRF层来优化序列标注结果,输出字序列对应的概率值最大的标签值提高序列标注的准确率。
2.2三元组识别模型构建
本文选取新能源汽车电池技术领域为研究对象,基于专利文本构建领域知识图谱。本文在信息抽取阶段的数据标注中引入语义角色信息,对实体词进行主体词和客体词的区分,一方面可以提高信息抽取效率,另一方面可以减少候选三元组的噪声数据,提升三元组抽取的准确率和图谱构建效率。
信息抽取模型抽取出信息主要分为主体词集合、关系词集合以及客体词集合3类,分别映射到知识图谱(S,P,O)三元组的表示形式中,候选三元组由主体词、关系词及客体词的随机组合形成,三元组数据是图谱构建的基础。因此,图谱构建模型的关键在于去除候选三元组的噪声数据,识别语义正确的三元组,也可以看作对三元组和专利文本的语义匹配。本文将候选三元组和对应的专利文本语句组合成一个长句子,利用预训练模型和双向长短记忆神经网络模型进行语义解析,为减少长序列文本在解码过程中上下文信息、位置信息丢失问题的影响,本文加入注意力机制[27](Attention)来增强重要字词的权重,优化模型,提升模型的准确率。
2.3领域知识图谱构建及可视化
本文基于前两小节的工作,将抽取出的三元组结构导入到Neo4j图数据库中进行结构化的存储和展示。Neo4j数据库作为图数据库的一种,主要由节点、属性和关系3种模块构成,可以将知识进行结构化的可视化存储,同时,它支持遍历式的查询,通过查询语句获知专利实体之间的关系及专利间关系,对企业竞争情报便捷获取有极大帮助,提升大数据下的信息检索效率[29]。
3实验
3.1实验数据来源
本文利用关键词匹配的检索方式从CNKI中国专利数据库中获取新能源汽车电池技术领域专利文献,作为构建知识图谱的基础数据。由于专利摘要的高度概括性,本文将专利摘要作为领域知识抽取的来源,进行人工标注及数据预处理后获得8238句,共63228个字符的标注实验语料。
3.2基于数据增强的信息抽取实验
3.2.1数据预处理
本文采用BIO标注法分别对每个字符人工标注,B表示词的开始,I表示词的中间或结束,O表示不属于任何一个标签的部分。基于该体系标注后共得到9个标签类型,分别为“B-SUBJ”“ISUBJ”“B-OBJ”“I-OBJ”“B-PRE”“I-PRE”“B-CHAR”“I-CHAR”“O”。
3.2.2数据增强
本文把实验语料按8∶2划分为训练集和测试集,利用信息抽取领域的传统模型BiLSTM-CRF作为基准模型进行数据增强,具体方法为:将标注后的训练集数据作为基准模型训练的样本,对未标注的文本数据进行标签预测,获得数据1199句,共10503个字符,最后对人工标注的训练集数据和基于模型迁移标注的数据进行融合,作为最终模型的训练样本。
最终用于领域信息抽取模型的实验语料9437句,共73731个字符。
3.2.3实验设置
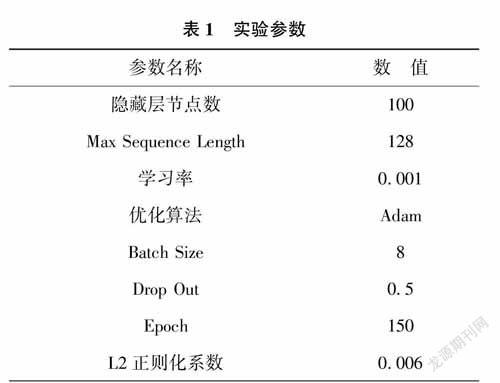
本文将实验文本以字符为单位作为模型的输入层,对比基准模型BiLSTM-CRF和加入BERT预训练的模型实验效果,验证预训练模型对于文本语料特征表示是否有增强。此外,本文通过设置数据增强对比实验来验证数据增强对于小样本量信息抽取模型的效果,数据增强用DATA(str)表示。本次实验基于TensorFlow框架,训练过程中的参数设置如表1所示。
3.2.4实验结果及分析
本次实验以精准率、召回率和F1值为评价指标,取5次结果的均值作为最终结果,实验结果如表2所示。
从实验结果上看,虽然进行数据增强后的训练语料中包含部分噪声数据,但对于模型训练效果影响不大,由于新能源汽车电池技术领域可复用的领域知识少,样本规模小,借助迁移学习思想对训练样本进行数据增强不仅能够极大地减少人工标注的压力,且对于模型效果的提升也十分显著。此外,预训练模型本质上也是迁移学习的应用,通过对大量开放性语料进行无监督学习,获取到更深层次的语义信息,对下游模型的训练起到辅助作用。对于小样本量的模型来说,借助预训练模型可以更進一步提升模型效果。
从信息抽取的角度看,模型对于客体词的抽取效果最好,主要原因是主体信息大多由名词和方向性名词组合构成,结构多变,而客体词相比于主体词及关系词更加标准,特征更明显。而开放式关系抽取使得关系词更加多样化。例如:连接关系包含连接、转动连接、固定连接、滑动连接等。这种非标准化的构成导致抽取模型效果降低,但开放式的信息抽取方式使得抽取出的信息语义更加多样,包含大量的专有名词、专业术语等,能够满足企业对于领域知识的需求。抽取出的部分主体词、关系词、客体词如图2所示。
3.3知识图谱构建
3.3.1三元组识别实验
知识图谱构建的基础是形如“实体—关系—实体”的三元组结构,本文对抽取出的实体词、关系词及客体词进行随机组合后,共获取到4512个候选三元组,三元组结构需要与专利摘要保持语义一致,将其看作语义匹配的过程,输入格式为三元组和专利句的结合,形成一个长句子作为模型的输入,本文在对比实验中引入预训练模型和注意力机制,通过预训练模型加强文本的语义特征,同时利用注意力机制可以对长文本中的重要信息进行加权,在进行三元组和文本句的语义匹配时,使得模型有更好的学习效果。
3.3.2实验结果分析
本文将候选三元组按8∶2的比例划分为训练集和测试集,由于正负样本较为均衡,本实验采用准确率(acc)作为评估标准,代表预测正确的样本数占总样本数的比例,实验结果如表3所示。
从模型的角度看,深度学习模型实验效果要明显优于传统机器学习模型(支持向量机,SVM),且加入注意力机制和预训练模型后,模型性能有显著提升。
同时,针对本文使用的数据集特征,在数据输入格式上进行创新,传统的语义匹配模型通常是在实体词、关系词及专利文本之间加入特殊分隔符,并在专利文本对应位置处用其他特殊符号分别替换实体词和关系词,标注位置信息。笔者认为,三元组实质上可看作包含语义信息的短文本,为增强三元组的语义表示,本文不对三元组进行分隔,“标注一”直接利用特殊分隔符将三元组与专利文本隔开,判断三元组与文本数据之间的语义匹配是否正确。“标注三”是“标注一”和“标注二”的结合,即加入三元组的位置信息。实验结果从数据标注方式的角度来看,本文所提出的数据输入格式有效,结合本文所用的模型后,模型准确率能够达到94.53%的最优值。
3.3.3专利图谱构建及可视化
本文将抽取出的实体关系三元组存储到Neo4j图数据库中,结合专利文本的公开号、申请方、作者等信息,构建的新能源汽车电池技术领域知识图谱共包含36635个实体节点和29488个关系边。
新能源汽车电池技术领域知识图谱由专利信息和领域关键词两部分构成,专利信息以专利公开号为唯一识别号,图谱所存储数据包括专利作者、申请方、专利名称及结构化专利领域知识,结果如图3和图4所示。由此可见,由专利信息建立的领域知识图谱,一方面可以较为明确地反映出专利之间以及专利作者、申请方之间的关系,帮助企业更为便利地获取行业内专利创新竞争情报;另一方面,将非结构化的专利信息以结构化的图谱形式进行展示,便于企业后续的创新知识管理,在企业进行技术革新、工艺创新时,可以重用领域知识,且在进行内部管理培训时,知识图谱能够较为快速地进行领域知识检索,发现知识间的关联关系。
领域关键词主要分为实体类关键词和关系类关键词,本文利用哈工大分词工具分别对抽取出的实体词和关系词进行分词处理,经过词频统计、数据去重、无效词清洗后,最终抽取出实体类关键词1379个,关系类关键词262个,部分领域关键词抽取结果如图5所示。
4结论和不足
为解决非结构化专利信息抽取和领域知识图谱构建问题,本文选取新能源汽车电池技术领域的专利文本为研究对象,综合深度学习算法BiLSTM、CRF、BERT预训练模型及注意力机制,提出了一种基于非结构化信息自动抽取的知识图谱构建方法,并验证了该方法的可行性和有效性。结果显示,通过本文提出方法能够极大程度减少数据量对于实体关系抽取模型的影响,取得较高的精准度和召回率,为构建高质量领域知识图谱提供数据和技术支撑,提升知识的可重用性。
本文的创新点主要体现在以下几个方面:第一,在没有可用领域知识词典和知识库的情况下,通过数据增强和增加预训练模型降低样本量小对领域知识抽取效果的影响,减少了人工标注成本,实现了领域知识的自动抽取,为小样本数据的实体抽取提供了一种方法;第二,本文旨在利用序列标注算法解决开放式关系的识别,最终提取出的关系相比于人工划分的限定关系具有更强的专业性,为新能源汽车电池技术领域的知识发现提供更丰富的数据支持;第三,在三元组识别实验模型BERT-BiL⁃STM的基础上加入注意力机制,结合文本匹配的特点,增强了长文本的重点信息的权重,提升了三元组识别实验的精确率。
未来研究中,本文将进一步探究扩大数据集规模的方法,验证方法的普适性,并引入领域术语、上下位关系等信息构建更全面的领域知识图谱,进行更广泛的应用研究。
3078500338287
