基于多属性学习的航拍视频理解
2022-03-09刘欣宜
刘欣宜
(武汉大学资源与环境科学学院,湖北 武汉 430079)
几十年前,无人机仅仅在科幻小说或有关未来的概念中出现。如今,无人机已经逐渐并迅速成为我们日常生活的一部分。根据美国联邦航空管理局的统计数据,仅在美国,已注册的民用无人机数量已从2015 年的14 万架攀升至2020 年的114 万架[1]。
毋庸置疑,与卫星相比,大批量无人机投入使用不仅可以促进实现低成本访问实时、高分辨率的视频,还可以辅助完成各类应用,例如灾后破坏程度估算、精准农业流程优化、野生动物保护监测等。也正因如此,如何更好地发展基于深度学习、卷积神经网络的自动化视频解译方法,现如今是遥感与计算机科学领域的研究热点之一。
1 航拍视频理解
广义的视频理解是一个综合性任务,它包含了场景或环境、物体、行为、事件及各种属性在内的多种语义识别。航拍视频理解通常可以通过执行各种计算机视觉任务来实现,比如视频分类、目标检测和目标跟踪等任务。
图像中包含的信息被称为空间信息。对于视频数据,除此之外,多个视频帧之间还存在时间信息。也就是说,视频可以提供时空信息。深度卷积神经网络(Convolutional Neural Networks, CNNs)具有从图像中学习有效视觉表征的超强能力。同样的,对于视频数据,深度卷积神经网络也能够通过其时空信息,来实现视频理解。
现有的视频理解CNNs 可以被分为两类,即主要使用三维卷积或二维卷积来学习全局时空表征。三维CNN 方法运用具有时间维度的三维卷积来提取全局时空特征,经典的网络包括C3D[2],I3D[3],P3D[4]等。对于二维CNN 方法,二维卷积被应用于每一帧视频以提取空间特征,而帧之间的时间信息通过一个附加模块来捕捉。代表性二维CNN 方法包括TRN[5]。
在深度学习中,卷积神经网络的训练离不开大量数据。对于航拍视频理解任务来说,实验数据的标注、描述方法对最终网络时空特征提取能力的提升至关重要。
当下,绝大多数航拍视频数据集都是单标签标注的,即通过给每个实例一个分类标签来描述视觉现象(活动、事件或动作等)。包括关于人- 人,人- 物体间关系的UCLA 空中事件数据集[6]、关于人类动作的Okutama-Action 数据集[7]、关于紧急事件响应的AIDER 数据集[8],和由2864 个时长5 秒、来源于YouTube 网站(https://www.youtube.com/)、分属于25个事件类别的无人机航拍视频数据集ERA Dataset[9]。注意到该ERA 数据集规模较广、视频内容多样化,可以作为航拍视频深度学习领域的一个基准,具有进一步标注、开发、丰富的潜力。
高级别的表达包括基于类别的表达和基于属性的表达,因此,对于视角广、信息量大的航拍视频而言,仅仅赋予视频一个类别单标签是远远不够的。为了更全面地描述、感知视频中关于地面物体、场景特征及人类观看感受的信息,基于属性的多标签标注和在此基础上开展多属性学习是不可忽视、亟待解决的一项研究任务。注意到当下基于多属性的航拍视频数据集还是一片空白,相关的基于CNN 的视频理解方法就更加有限,相关领域研究人员也因此还需要做出进一步的努力。
2 Multi-Attribute ERA 数据库
通过对现有无人机视频数据集进行调查,我们发现ERA 数据集[9]具有进一步被标注的潜力,因此我们采用对ERA 数据集进行标注的方式来用较低成本建立第一个高质量的多属性无人机视频数据库Multi-Attribute ERA 数据库。整个创建过程包括属性集合的确定、标注与质量检测。此外,本章还对Multi-Attribute ERA 数据库进行了包括数据统计、数据库特性与挑战在内的进一步介绍。
2.1 设计多属性标签集合
为了找到合适的多属性标签集合,我们遵循两个原则:原则一为场景分类法,意在找出每个场景对应的目标属性。首先,我们将ERA 数据集中的25 个事件类标签(震后、赛车、打篮球、洪水、山体滑坡、耕作等)归为如图1 所示的四大场景类,其中居民区场景可以细分为三个次类。每个类、次类对应的比较普适的目标属性包括:楼房、人、车辆、停车场、运动场、赛车道、山、泥石流、田地、自然水域和游泳池。然后,回归到ERA 数据集的25 个事件类中,我们找到对应事件类的特定目标属性:条幅/标语牌,旗帜,自行车,船,塔吊,耕作机,火焰/烟雾,收割机,舞台,水炮。
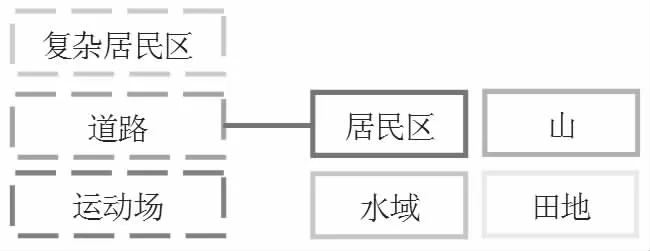
图1 将ERA 数据集[9]中的事件标签按场景归类
由于人工智能的目标是像人类一样感知视频内容,原则二为人类对视频的描述。当人类观看视频时,不可避免会产生对视频的情感,同时还会注意到视频中发生的活动、天气等属性。由于ERA 数据集本身已经有了活动标签,这里我们选择天气和情感两个属性类。结合ERA 数据集的内容,最后确定下来的对应属性有:天气:夜晚;情感:竞争性,拥挤,危险,快乐,压力,紧张。
至此,我们得到了涵盖地面目标、天气情况、人类情感在内的Multi-attribute ERA 数据集的全部属性标签,共有28个。
2.2 建立Multi-attribute ERA 数据库
Multi-attribute ERA 数据库的标注工作是在我们为其设计的MATLAB 视频数据多标签标注平台上完成的。为了保证数据集的完整性与准确性,我们还制定并施行了包括标注中准则、标注后检查在内的质量控制流程。
标注中准则包括参考人对视频内容的理解、参考视频片段的源视频和参考属性的字面定义三项。标注过程中,无法通过准则进行决策的数据记录在了标准日志上。整个标注阶段完成后,由4 名标注员对不明确的项目进行检查、讨论并调整。
2.3 数据库描述
Multi-attribute ERA 数据库非常适合多属性视频分类的任务。它包含28 个有代表性的属性,每个视频数据有0 到11 个属性标签。而对于每个标签,样本数从82 到1887 不等,总共有2864 个样本。我们给出一些典型示例及其多属性标签如图2。Multi-attribute ERA 数据库的数据分布非常不平衡(如图3 所示)、数据集规模不大、类间相似度大、类内差异大,为训练航拍视频理解算法带来了挑战。

图2 事件类视频示例的中间帧及其在Multi-Attribute ERA 数据库中对应的多属性标签
3 实验与分析
在创建Multi-attribute ERA 数据集的基础上,我们设计并完成了第一个多属性航拍视频理解的任务,即多标签食品分类。在这个实验中,4 个当下最有代表性的、先进的CNN视频分类模型在所提出的Multi-attribute ERA 数据集上进行了评估。
3.1 视频分类基线网络模型
本实验所选择的四个基线网络为C3D[2],I3D[3],P3D[4]和TRN[5]。由于是多标签分类任务,网络的分类层激活函数为Sigmoid 函数。
3.2 评价指标
对于视频多标签分类任务,我们将主要评价指标设定为平均F1值、平均F2值,此外,参考指标还有基于实例平均精度pe、召回率re、基于标签的平均精度pl、召回率rl。计算方法如下所示并取均值:
3.3 实验结果与分析
如表1 所示,就平均F1值、平均F2值来看,模型TRN-Inception-v3表现最好,分别为67.27%和67.57%。这可能是因为它的结构是一个带有时间推理模块的二维CNN,可以在捕捉时间信息的同时有效提取足够的空间特征。就平均精度而言,模型P3D-Resnet-199的表现最佳,基于实例、标签的平均精度分别为73.73%和67.88%。
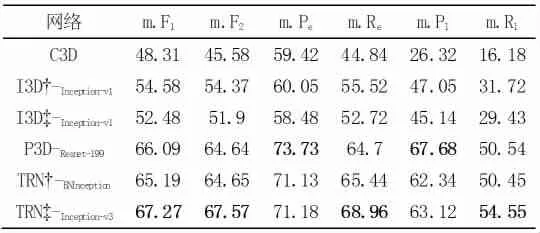
表1 在Multi-Attribute ERA 上进行基线实验的定量结果(\%)。最佳结果用粗体表示
图4 展示了以上两个网络的预测结果示例。很明显,大部分样本的主要属性被成功预测,模型TRN -Inception-v3和P3D-Resnet-199已经显示出它们在学习航拍视频的各种属性方面的出色能力。与此同时,注意到夜间场景视频的预测值假阴性比例较高,属于比较有挑战性的样本。

图4 TRN - Inception-v3 和P3D- Resnet-199 在多Multi Attribute ERA 数据库上的多属性视频分类实验结果(预测值)及真实值示例。图示为对应视频第一帧与最后一帧。[方括号]的预测值代表假阳性,而(圆括号)真实值代表两个模型结果的假阴性。
4 结论
我们提出了第一个多标签无人机视频数据库:Multi-attribute ERA 数据库。该数据库在原有最大事件识别航拍视频数据集ERA 数据集[9]的基础上,标注了28 个涵盖地面目标、天气和人类情绪的,有代表性的多属性标签,更好地对航拍视频进行了描述。它质量高、规模大、类内差异大、类间相似度高。此外,我们设计并完成了视频分类的多属性学习任务,即将4 个最先进的视频分类深度学习CNN 模型在Multi-attribute ERA 数据库上进行了评估。实验结果表明,这是一项可行且艰巨的任务,所提出的数据集是一个新的挑战,可以用来开发、优化更好的航拍视频理解模型。望眼未来,我们可以在此数据库基础上研发专注于视频属性识别的深度学习模型、探索属性和视频类别之间的相互作用、属性之间的相关性等,最大化本数据库在遥感与计算机视觉领域的应用与贡献。
