多源试验数据重构与融合存储技术研究
2022-03-09丁世来陈克澎葛智君李浩波舒宁
丁世来 , 陈克澎 , 葛智君 , 李浩波 , 舒宁
(1.工业和信息化部电子第五研究所, 广东 广州 511370;2.工业装备质量大数据工业和信息化部重点实验室, 广东 广州 511370)
0 引言
航空发动机因其高度复杂精密的特点, 被誉为“现代工业皇冠上的明珠”, 并且是飞机的“心脏”,直接影响着飞机的性能、 可靠性和经济性[1]。 航发产品的研制和生产是衡量一个国家综合科技水平、 科技工业基础实力和综合国力的重要标志。 而我国航空工业系统中各种试验场景下产生的大量试验数据, 普遍存在多源异构、 属性单一等特点, 同时试验数据处理工具或系统多是分散独立, 因数据割裂而造成的“数据孤岛” 现象较为严重。
通过研究多源数据重构与融合存储技术, 重点突破多维试验数据的模板化抽取、 数据升维、 数据重构和数据融合存储等技术, 着力解决航空发动机试验数据属性单一、 表达能力弱, 以及数据割裂、统一存储难等困难与问题, 进一步地为动态、 高效、 实时的发动机试验数据分析提供有力的支撑,有效地提升航空工业企业的生产效率与竞争力, 实现航空产品的生产过程智能化、 流程管理智能化和制造模式智能化, 实现我国航空发动机“弯道超车”, 打破欧美强国对航空发动机的垄断状态, 创造属于我国自主研发的航空发动机的独立领地[2]。
1 研究现状分析
美、 英、 法等航空大国一直特别重视航空发动机试验工作。美国普惠公司借助IBM 云管理,利用大数据技术对4 000 多台在役商用发动机的性能监控, 为客户提供更长的在翼时间、 更强大的发动机机队管理和健康解决方案。 英国罗罗公司较早采用大数据技术建立发动机健康管理系统(EHM), 实时地检测工作状态, 合理地安排使用和维修时间, 协助设计更加高效低耗的发动机, 因而其发动机被称为“大数据引擎”[3]。 欧洲空客公司利用大数据技术收集与分析试飞数据, 实时地监控飞行状态, 提供优化建议。 尽管这些公司利用大数据技术收集与分析试验数据, 使得设计的薄弱环节充分地暴露, 并予以改进。 但在多源数据重构、融合存储和存储关联等方面的技术研究和产业化应用, 尚未形成较为有效的局面。
国内南航、 海航和国航等大型航空公司逐步地开始重视利用大数据技术对试验数据进行管理分析。 南航建立飞机远程诊断实时跟踪平台, 利用大数据技术解决飞行大数据的存储问题, 并积极地开展工程应用研究[4]。 海航建立飞机健康管理大数据应用平台, 利用大数据技术实现实时监控、 健康管理和优化机队维修和工程管理水平, 为维修控制、工程管理和航线维护部门带来了极大的便利[5]。国航Ameco 工程部自主地建立飞机状态预测和维修作业管理平台, 利用大数据技术对数百架飞机累计完成500 多万飞行小时的试验验证, 将进一步地在国航全机队中逐步地推广和应用[6]。 尽管国内在航空大数据采集、 存储、 处理与分析等方面取得了一定的成效, 但是在多源数据重构、 多源数据融合存储、 多源多维数据存储关联等方面能力仍有不足。
2 总体技术路线
当前试验数据采集、 集成、 分析和应用已初具规模, 但仍存在着多源试验数据属性单一、 多源异构数据集成困难和数据重构能力不足等瓶颈, 已经严重地影响了工业多源数据的高效、 深度应用, 所以亟需研究多源试验数据重构与融合存储技术, 突破多源异构数据在清洗、 治理、 重构、 融合、 存储与关联等方面技术, 总体技术路线如图1 所示。
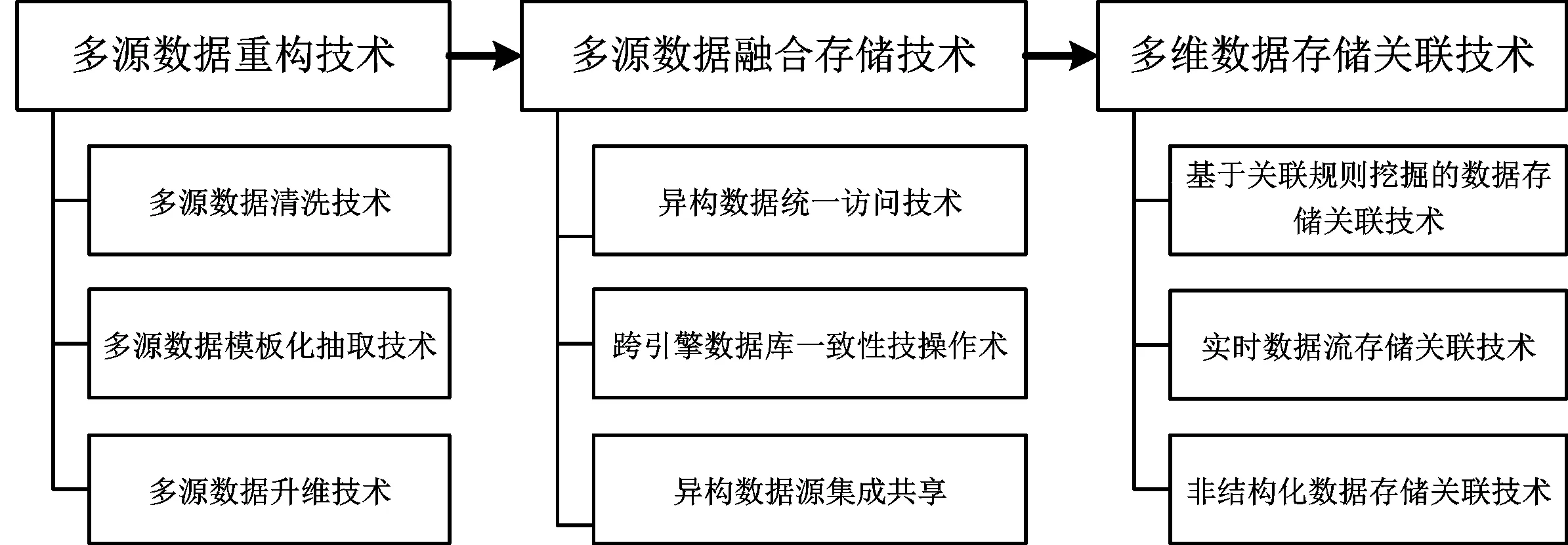
图1 总体技术路线
1) 针对航空发动机试验中文本类、 音视频类等非结构化数据, 采用多源数据模板化抽取技术提取航空发动机试验数据; 2) 针对属性单一、 字段缺失的试验数据, 采用多源数据升维技术做维度扩展处理, 高度聚合重要信息与特征, 重构形成一种多源多维数据; 3) 针对数据割裂、 分散存储的试验数据, 采用跨引擎数据库一致性操作、 异构数据源集成共享等技术, 将其统一融合存储到数据库中; 4) 针对表达力薄弱的试验数据, 采用多源数据维度关联、 多源异构数据引擎整合和多源数据存储管理等技术, 建立形成数据存储关联机制, 实现对工业多源、 多维数据在存储、 管理、 运行和传输等方面提供高效的支撑。
3 关键技术研究
3.1 工业多源数据重构方法与应用技术研究
首先, 梳理与分析用户的业务实际需求, 结合专家的领域知识, 构建出规则执行模块、 信息转换模块和规则库模块等3 个部分, 如图2 所示。 建立的规则库模块中包含各类基于机器学习的模板化抽取方法, 如基于规则的模板化抽取方法等[7]。 通过规则库, 建立数据抽取的模板规则或模型, 对规则执行模块提供自定义抽取、 清洗规则等支撑, 协助规则执行模块从多源异构、 属性单一的试验数据中抽取有效信息(如事件、 类型等), 并通过信息转换模块对不同数据库内的数据进行数据转换, 自动化根据用户自定义的转换规则将异构数据转换成特定的、 能被用于维度扩展处理的某种数据结构存储的数据, 并以转换规则的形式存放于数据库中,实现对测试数据的自动清洗。
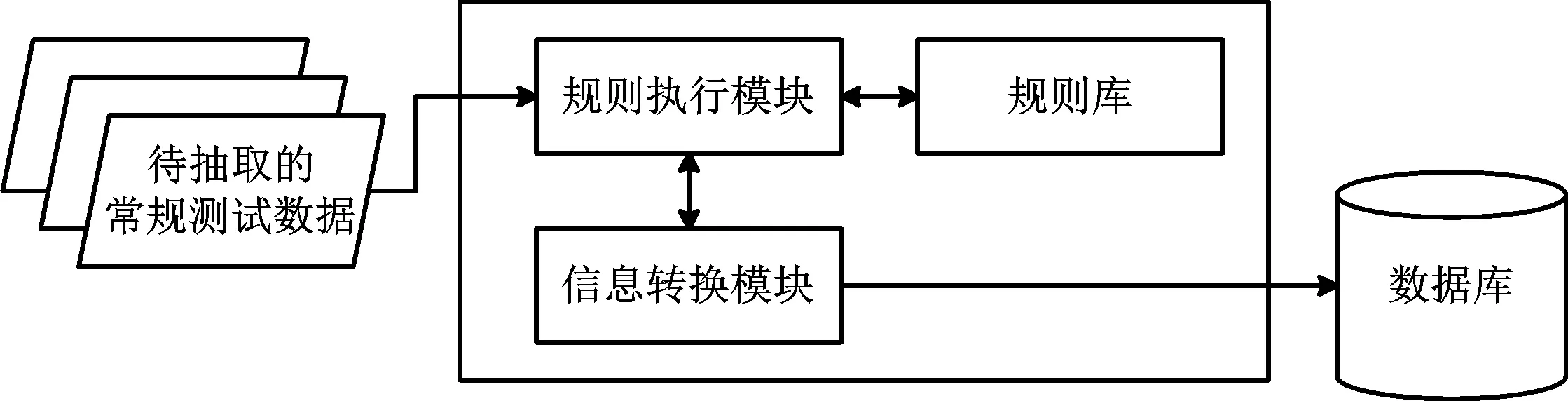
图2 基于规则的模板化抽取方法
其次, 对于抽取的试验数据, 普遍存在着数据属性单一、 分析维度不足等问题, 这既要从技术的角度考虑数据升维, 又不能完全依赖于技术, 要适当地从业务方面结合领域知识或实践经验去梳理与分析原始数据, 思索其升维后的潜在形式和数据结构, 从中挖掘出数据升维的部分特征, 最终满足用户的多维试验数据需求。 具体将从业务和技术两个方面对数据升维展开研究, 如图3 所示。
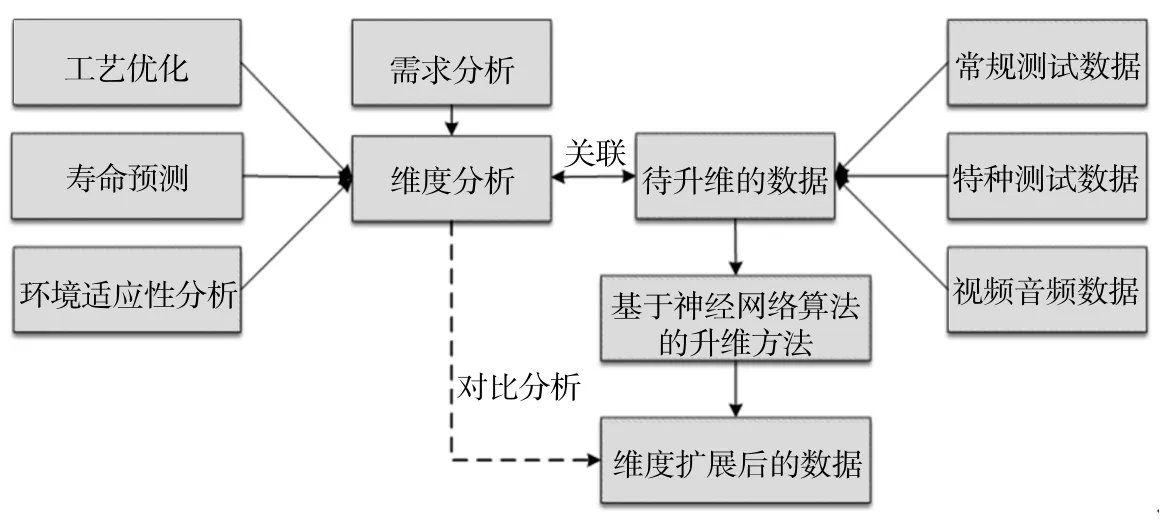
图3 面向工业多维数据的升维方法
在业务升维方面, 从单一试验数据的业务角度出发, 梳理与分析出工艺优化、 寿命预测和环境试验性等不同层面的业务维度扩展需求, 并利用逻辑关联等业务思维和统计方法提取这些数据维度扩展需求的关键特征, 例如: 利用基于时序逻辑的关联规则挖掘方法[8], 从业务逻辑思路里提取用户数据升维需求的新可用特征。
在技术升维方面, 基于业务升维需求分析的特征, 采用数据关联技术, 将抽取的单一试验数据与业务需求特征间建立关联映射规则, 以业务需求驱动单一试验数据智能化获取, 并采用基于神经网络算法的升维方法对数据进行升维处理, 将选取的单一试验数据按照升维规则进行某种组合以生成多维数据, 从而实现对工业多源数据的数据重构。
3.2 多源数据融合存储方法与应用技术研究
然后, 利用异构数据库统一访问、 跨引擎数据库一致性操作和异构数据源集成共享3 种技术手段, 实现对工业多源试验数据的融合存储。
a) 异构数据库统一访问方面, 异构数据库具有自身应用特性、 自治性、 完整性控制和安全性控制等特征, 是由多个数据库系统组成的, 例如: Oracle、 Sql Server、MySQL 或者达梦、 神通等数据库系统, 各数据库系统运行在大型机、 小型机、 工作站或嵌入式系统中, 涉及到的基础操作系统分别有Windows NT、 Unix/Linux 等。 通过整合与集成不同数据库间的连接访问使用的驱动包, 建立统一的数据访问入口, 统一数据库对各种数据展现方式、 不同数据语义等要素的解释方式, 屏蔽各不相同数据库的差异, 并构建统一的可视化操作界面, 促使应用系统与数据库系统间松耦合, 从而有利于数据集成、 共享与维护。
b) 跨引擎数据库一致性操作方面
在异构数据库系统环境下, 整合与统一不同数据库系统的管理维护规则, 构建统一的数据模型、数据操作定义和统一的可视化操作界面, 屏蔽各个数据库管理系统间的数据模型、 数据结构、 关系映射、 物理存储、 视图与物理存储映射关系、 SQL 语法规则、 事务支持和事务安全等级等差异性, 实现跨引擎数据库一致性操作, 将数据模型与数据操作转换成对应的数据库操作, 优化不同数据库系统的操作与维护管理工作。
c) 异构数据源集成与共享方面
综合地考虑不同数据源的异构性,通过数据抽取、 转换和装载等3 个步骤,将不同来源、 格式及特点性质的数据在逻辑上或物理上有机地集中, 促使业务系统能够更加充分地使用已有的数据资源, 减少资料获取、 数据采集等重复性
劳动和响应性费用, 实现较为全面的数据集成与共享。 在数据抽取方面, 结合业务需求, 确定需抽取的数据内容, 得到规范统一的数据; 在数据转换方面, 根据业务规则, 对异常数据进行清洗转换处理, 得到规则一致的数据; 在数据装载方面, 结合使用的数据库系统, 确定最优的数据加载方案, 将经过转换后的数据按照预定义的结构装入目标库中, 节约CPU、 硬盘IO 和网络传输资源。
通过研究多源数据融合存储方法与应用技术,统一数据内容、 数据格式和数据质量, 促进数据在不同系统间交流、 融合与共享, 进而打破“信息孤岛” 的瓶颈。
3.3 多源多维数据的数据存储关联技术研究
最后, 利用实时数据流存储关联技术、 非结构化数据存储关联技术和基于关联规则挖掘的数据存储关联技术, 对多源多维数据进行数据存储关联处理。
特别是对于实时的航发产品试验数据流获取,考虑到实时数据流不仅具有时序性、 海量性和多变性等特点, 而且数据流中元素出现的先后次序、 数据流速等因素, 均与数据源及数据采集设备相关,难以人为干预, 采用实时数据流存储关联技术, 利用Storm 实时计算系统, 监测数以万计的数据点实时采集到的试验数据, 并借助毫秒级响应, 进行持续不断的流计算, 弥补批处理难以达到的实时要求。 同时利用Storm 对每秒钟数万甚至数十万量级的数据进行实时在线分析、 持续分布式计算, 满足数据采集、 传输、 处理与存储等方面提出的高要求。
考虑到试验数据不仅包含结构化数据, 同时也包含非结构化数据, 例如: 试验过程中的音视频数据等。 对于非结构化数据而言, 当前的存储管理模式主要集中在基于文件系统、 数据库系统, 以及融合数据库和文件系统的管理模式, 如表1 所示。

表1 3 种非结构化数据存储管理模式
基于上述考虑, 采用非结构化数据存储关联技术, 利用HDFS 文件存储系统融合Cassandra 分布式数据库的管理模式, 对非结构化数据进行存储关联。
在实际应用中, 若访问包含多个字段的数据,例如: 图片、 文本和音频等数据, 则需要将该数据的所有字段均被访问。 而这些同一网页字段间是具有较强关联性的, 统一合并存储这些数据, 在提高存储效率的同时也提高访问效率。 进一步地利用关联规则算法[9], 如Apriori 算法, 主要分为查找频繁项集和产生强关联规则两个部分。 首先, 利用AprioriPMR 并行关联规则算法对数据库只需扫描2次后, 即可得到频繁项集; 然后, 利用关联规则挖掘航发产品试验数据中较强的关联性数据, 并将这些数据进行合并存储; 最后, 得到合并集合表、 高频访问表和预取机制表等结果[10]。
其中, 合并集合表是用于记录合并存储的文件名的记录表, 每项记录对应一个合并文件集。 高频访问表是用于记录数据表中被访问次数最多的文件, 按支持度对得到的频繁1-项集排序, 取出前N 项作为高频访问表。 预取机制表是用于强关联规则的记录表, 按置信度大小对筛选后的强关联规则排序, 从大于置信度的强关联规则中, 选择单个项集作为前提条件, 并将这些规则放入到预取机制表中。
4 结束语
通过梳理与分析航发产品的试验数据, 结合典型试验场景及业务实际需求, 首先, 构建多源数据模板化抽取的规则库, 并提出基于维度扩展的多源试验数据升维方法, 对抽取的多源试验数据进行数据升维重构, 解决航发产品试验数据字段的属性单一、 表达能力弱、 无法充分利用的问题; 然后, 提出异构数据库统一访问、 跨引擎数据库一致性操作和异构数据源集成共享等方法对数据融合存储, 解决航发产品试验数据中结构化与非结构化数据间的管理混乱, 无法统一存储的问题; 最后, 突破多源数据存储管理、 多源数据维度关联和异构数据引擎整合等技术, 对融合存储后的多源多维数据进行存储关联, 解决航发产品试验数据割裂, 表结构不合理, 独立存储的问题。
