一种改进精简的语音识别模型
2022-03-07刘鑫罗幼喜
刘鑫,罗幼喜
(湖北工业大学理学院,湖北武汉,430068)
0 引言
在深度学习应用到语音识别领域之前,声学模型也有属于自己的一套体系,像高斯混合模型和隐马尔可夫模型在语音识别的领域上都取得了不错的效果,但是传统的语音识别模型存在上下文割裂的情况。
因此,研究人员注意到具有自注意力机制的深度神经网络模型Transformer,在机器翻译、计算机视觉等领域中展现出强劲识别性能。于是,Dong等人首次将Transformer模型引入语音识别领域,提出Speech-Transformer模型,使得Transformer能够完成语音识别任务;然后Bie等人又将Speech-Transformer模型规模进行缩减,使其应用到低存储设备,但是在传统的端对端的模型当中Transformer模型存在参数量大,识别准确率低,训练时间长等种种问题,无法很好地移植到硬件设备上,因此研究模型参数的影响因素和缩减模型的参数量以及加快模型的训练速度成了一个亟待解决的问题。
1 相关工作
本文在Speech-Transformer语音识别系统的基础上进行一定的探索研究,对模型中的参数进行一定的探索和量化工作,并且对模型结构进行一定的修改以求达到一个更优的模型。通过研究Transformer不同参数对其模型性能的影响,此外本文在对模型进行参数调整的过程中还对Transformer模型结构中残差连接和归一化层(add&norm)这一结构结合残差神经网络相应地改进施进行修改,在保证词错率下降的同时,加快模型的收敛速度和训练速度,修改结构之后的模型在词错率上相比原有模型词错率更低,并且收敛速度也比未修改结构的模型收敛速度更快。在最后训练出来的所有模型当中,挑选出参数量小准确率高解码速度快的模型进行识别任务。
2 Transformer的语音识别系统
2.1 卷积神经网络压缩语音数据的长度和信息密度
在语音识别中,考虑到语音数据在一段时间内会有重复的片段在里面,句子的特征向量会比较冗长,这里采用卷积层在进行特征提取的同时对语音序列的长度进行裁剪使输入语音特征序列的长度得到缩减和信息密度得到增强。
2.2 对Transformer模型训练进行加速
2.2.1 残差神经网络
在Transformer的结构中本身自带了残差连接的结构,残差连接的结构如图1所示,残差连接的结构主要是为了解决深度学习模型在模型网络结构过深的问题中,在面对梯度消失和梯度爆炸的问题上,残差连接的结构能够很好地保存数据特征的梯度。

图1 残差连接结构图
2.2.2 ReZero:加速深度模型收敛
在此之前来自加州大学圣迭戈分校(UCSD)的研究者提出一种神经网络结构改进方法「ReZero」,他对残差连接的修改如公式(1)所示:
在模型训练开始之前将α的默认值设定为零。改进后的网络结构如图2所示。
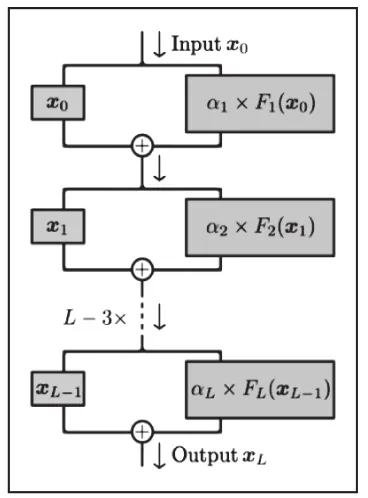
图2 更改的残差连接结构示意图
2.2.3 对残差连接部分的优化改进
基于上述对残差连接结构进行的一系列优化,本文选取将残差连接的优化应用在Transformer的结构当中,通过修改对比之前的改进措施进行一系列的综合实验,以求取得一个优异的语音识别系统模型。修改的部分如图3和图4所示。

图3 原始模型当中的残差连接示意图

图4 修改模型当中的残差连接示意图
2.2.4 残差连接中的系数修改(加入约束因子)
注意力机制的本质就是在特征的前面加上一个权重,在模型的解码过程中根据各个神经网络层的结构不断地去调整各个特征的权重,加入约束因子的目的旨在,随着神经网络的深度叠加,因为在Transformer的结构中所有的encoder层和decoder层中都有残差连接这一结构,训练出的强特征信息会不断地放大这一特征的权重系数,与此同时,如果模型当中不存在这样的强特征,那么我们对残差连接的系数进行缩小,将残差连接的权重设置为小于1的数,特征信息更加强调原始特征里面包含的信息,与此同时扩大原始信息,减弱深层次的特征信息,能够很好地加强模型的泛化能力。
2.2.5 最终模型选择固定的约束(扩大)因子
通过对各种修改残差连接的思路对比综合实验,得出了固定约束(扩大)的因子会在模型当中取得最佳的效果,固定权重的实验表现在对比其他策略之下的在词错率这一指标上,对比其他的策略平均提升1%,相比于原始的最初模型提升了3%,在模型的收敛速度上的提升是大幅度且显而易见的。
3 实验
在修改模型的残差连接系数的过程中我们尝试了可调节系数和固定配比系数,单可调节系数和双可调节系数,扩大残差系数和扩大X的系数等等一系列的方法,发现残差连接中使用固定配比系数的效果是最好的,在模型的修改过程中改变了Encoder中残差链接的系数权重。
4 实验结果
4.1 Transformer超参数的影响因素
对于Transformer模型结构会受到哪些因素的影响,本文首先做了以下工作:以初始参数化的Transformer结构作为基础结构,采用控制变量法对比不同参数取值对准确率和解码速度的影响。其中,不同参数取值的Transformer结构如表1所示,与此同时表中还记录了不同模型的参数量和对应的训练时长,以及模型对应的词错率。
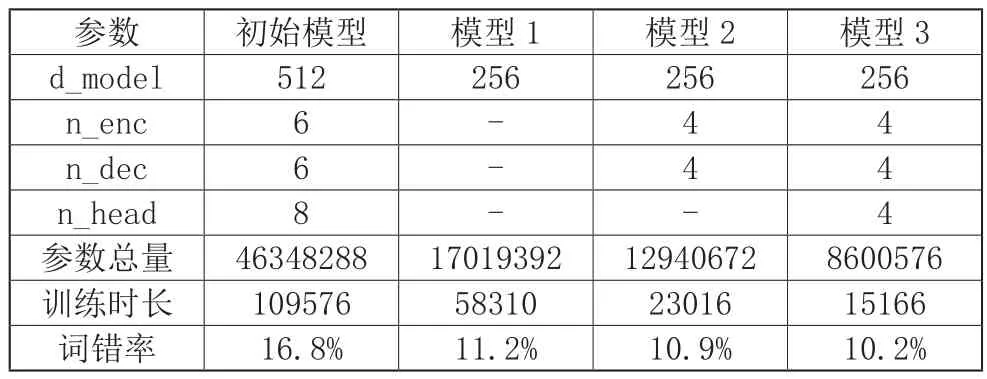
表1 不同模型参数优化表
4.1.1 词向量空间的影响
这里我们选用的最佳词向量维度为256,对比模型1和初始模型我们能直观地看到训练时长大大缩短,且将词向量空间减少到原来的1/2,模型的准确率也得到极大提高。词向量空间的大小对该模型参数的影响是千万级别的。
4.1.2 编码层和解码层对参数的影响
我们选取了最后的模型encoder=decoder=4这一参数,取得了比较好的效果。对比模型1和模型2的参数设置我们可以直观地看到模型的训练速度的提升效果要明显的大于其他的指标,这一参数的设置对训练速度的提升效果是显而易见的。
4.2 模型结构修改实验结果
每个模型训练200轮,每40轮保存一次实验模型记录结果见表2:

表2 实验模型与相对应的词错率表
4.2.1 动态残差加快模型收敛效果显著
对比40轮的模型,模型收敛速度相较于原始模型和修改超参数之后的模型,动态残差权重模型在40轮的时候已经收敛,实验数据表明其收敛速度确实得到了提高。
4.2.2 固定权重配比的模型效果更好
在固定配比的实验中,首先选取的是1*F(X)+2*X,即扩大原始X(数据特征)在模型训练中的权重,强调在模型的训练当中原始X(数据特征)在模型训练当中的重要性要比残差连接中的残差部分的更大,此处用加权的权重来衡量数据在模型当中的重要性,然而事实却与我们的预期相反,扩大原始特征x的权重(2x)使得每一轮的模型相比于原来的模型在词错率的表现上都有所上升,因此我们在接下来的模型中放弃这一改动选择在原始模型的基础上扩大残差项的系数(2F(x))来观测模型最终的表现。
4.2.3 确定合适的固定配比的比例
扩大残差项的系数(2F(x))模型观察其在每一个轮次上的表现,发现无论是在收敛速度还是在准确率上,都比修改了超参数之后的模型表现更加优异,继续扩大残差项的系数(3F(x))其表现差异变化和2F(x)不存在显著性的差异,继续扩大残差项的系数(4F(x)),发现此时的词错率开始上升,本实验中的最优模型的残差连接系数调节的最佳配比应该锁定在1:2到1:3之间,即2*F(X)+1*X或者3*F(X)+1*X,模型的表现最佳。
在对比所有的模型实验结果后,在本实验中固定配比的模型显然要优于调节系数的模型,而在固定配比的模型当中,残差连接系数调节的最佳配比应该锁定在1:2到1:3之间,即2*F(X)+1*X或者3*F(X)+1*X,模型的表现最佳,此时的模型收敛速度较原有模型得到提升的同时,词错率降到最低,相对应的最低词错率分别为7.92%和7.956%。
5 结束语
本文设计了一种基于精简修改的Transformer模型的语音识别方法,所做的一切修改都是在保证词错率下降这一大前提的条件下进行的,针对现有Transformer模型进行修改设计,通过对原有模型的Encoder部分中残差连接的系数进行修改,在保证词错率下降的同时,使得原始模型的收敛速度得到提升。
此外对模型的一些超参数进行合理的调整,使得Transformer的参数量大大减少,在网络的训练阶段,由于参数的减少,提高了训练的速度;在网络的解码验证阶段,运算量的减少,使得模型更加精简,模型训练时间和验证时间的缩短,使得研究人员能够更加方便地进行调参和模型修改等工作,方便了模型从软件到硬件上的移植。
