多尺度地图空间居民地语义相似度计算方法
2022-03-07高晓蓉闫浩文禄小敏
高晓蓉,闫浩文,禄小敏
1. 兰州交通大学测绘与地理信息学院,甘肃 兰州 730070; 2. 地理国情监测技术应用国家地方联合工程研究中心,甘肃 兰州 730070; 3. 甘肃省地理国情监测工程实验室,甘肃 兰州 730070
相似是一种组织原则,人们在该原则指导下分类对象、形成概念、实施概括[1],相似也是地图综合的本质特征:无论从地理空间到地图空间,或从大比例尺地图空间到小比例尺地图空间,正确的地图综合须突出表现地理事物的规律性,在保证清晰易读的前提下将尽量丰富的内容容纳在有限地图空间内[2],其中包含的创造性分类、分级,抽象概括即为对相似关系的保持。因此,制图者无法脱离相似实施地图综合,读图者无法从缺少相似性的地图形成心象地图、重构现实世界。地图综合这一复杂的智能化过程[3],其本质是一种空间相似变换[4],空间相似关系是地图学领域至关重要且值得深入探讨的课题。
然而,地图综合中空间相似关系的研究在2000年前后时仍相对较少,这是由于空间相似关系可计算性差,且其计算的目的在于揭示更深层次的信息[5]。自彼时至今,随着理论、技术的发展及数据获取手段的扩展,地图学与地理信息科学领域空间相似关系已有一些研究,包括拓扑[6-7]、方向[8-9]、距离[10]、位置[11-12]、语义[13]、形状[14-15]等的某一方面或几方面[16-17],以及场景相似[18-19]、总体相似[20-21]等。与其他几种相似关系相比,语义相似关系的研究仍相对较少。以大比例尺图街区式居民地合并为例,已有算法全面考虑城市形态学、格式塔原则[22]等几何因素,相对较少涉及语义相似。但读图者在阅读地图时,先找到地标建筑物,再以之为参考定位感兴趣的地物,形成心象地图。该认知过程本能地使地图上建筑物在定位、导航中发挥最大的作用。分析该读图过程不难发现,虽然读图者没有专业的制图知识,但他们更习惯于将地图上表示的几何图形与“商场”、“体育馆”等语义信息联系起来,认知地图表达的世界。专业制图者对语义信息的考虑隐含于人工综合过程中:语义相同或相近,才考虑几个几何图形的合并。因此,语义相似的量化及形式化描述对实现全自动地图综合非常重要[23],符合“相似感既是与生俱来的,又是后天累积的,二者共同发挥作用[24]”的哲学观点——传统情形下,地图的用户和制作者都是人,他们认为的相似分别是与生俱来、直觉的相似和后天积累的专业知识,二者均应融入自动地图综合中,形成计算机可识别的知识。因此,为建筑物地图综合增加语义约束,并分析语义相似度随比例尺变化的规律,具有重要的理论意义和实际应用价值。
建筑物语义信息的获取近年多利用POI(points of interest)、出租车轨迹数据[25-26],为街区式居民地语义信息的获取提供了有效思路。而国家自然资源部门举全国之力获取的地理国情普查数据,可为建筑物增加可靠的细粒度语义信息,较POI、轨迹数据更具权威、准确等优势。因此本文采用地理国情普查地理单元数据作为语义划分的依据,重点研究多尺度地图空间(1∶1750至1∶14 000)建筑物合并、取舍中语义相似度的变化,对比有/无功能区约束下的合并的语义相似度大小,分析多尺度地图空间语义相似度反映的深层次信息。图1为本文的主要工作和研究方法。

图1 本文的主要工作及研究方法Fig.1 The main work and strategy for building aggregation and its semantic similarity quantification and analyses
1 语义功能区约束下的街区式居民地合并
1.1 居民地的语义信息
图2为同一建筑物在3个不同比例尺图上的表达,虽然详细程度不同,但制图者始终用紫色表示其性质(大型购物场所),即为该建筑物的语义特征。建筑物的语义信息可通过属性表中的属性项获得。但实际生产的建筑物数据大都存在功能语义信息不完整的缺点[25],本文利用地理国情普查数据中的重要地理国情要素数据,在建筑物层与街区层间加入语义功能区层,根据语义功能区与建筑物的包含关系,为建筑物面赋予语义信息。
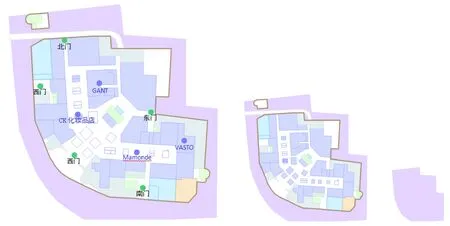
图2 不同比例尺地图上同一建筑物的语义信息Fig.2 Semantic information of the same building on different scale maps
1.2 大比例尺街区式居民地合并
本文以街区为基本研究单元,最大比例尺(例如图3(a))下,试验数据为兰州市基础地理信息数据集中的建筑物层和根据地理国情要素标准人工采集的功能区(定义见2.2节),即:图3(a)功能区的几何数据和语义信息均来自地理国情普查数据(对应图4蓝色部分),其余几何数据和语义信息来自基础地理信息数据(对应图4黑色部分)。在图3(b)至图3(e)的综合过程中,各比例尺节点及功能区的取舍参考大众广泛认可的在线地图如百度地图的比例尺而确定,建筑物间距在目标比例尺下小于0.2 mm时实施合并。图3为某街区局部的基于功能区的地图综合,包括学校、小区及不属于任何功能区的一般建筑物。图3(a)为原始比例尺(1∶1750)图,可清晰分辨出建筑物的排列模式及其语义。当比例尺缩小至小于1/4比例尺时,读图者不再关注建筑物的排列模式,过多细节反倒会扰乱读者,读者将注意力集中于整个街区语义功能区的划分(图3(d))。比例尺缩小至原图的1/8时(图3(e)),整个街区综合为一个整体,将功能区抽象为点表示(文中所有图不表示点和标注)。

图3 语义功能区约束下的街区综合(试验区1)Fig. 3 City block generalization under the constraint of semantic function regions
2 基于匹配距离模型的语义相似度计算方法
2.1 MD(matching-distance)模型的原理
所谓本体,是对客观存在现象、事物的系统描述,在计算机和信息领域是指共享概念模型的明确的形式化规范说明[27]。MD模型基于本体论,它使用实体类(以下简称类)之间的语义关系和实体类的可区分特征两个组成部分来代表实体类,基于实体类语义间的相互关系组织实体类,并将实体类的集合及其语义关系描述为本体[11]。MD模型采用式(1)—式(3)计算语义相似度[13,28-30]。
S(c1,c2)=ωp·Sp(c1,c2)+ωf·Sf(c1,c2)+ωa·Sa(c1,c2)
(1)
(2)
(3)
式中,S(c1,c2)为类c1和c2的语义相似度;Sp、Sf和Sa分别为c1和c2的组成部分相似度、功能相似度和属性相似度;ωp、ωf和ωa分别为Sp、Sf和Sa的权重,本文采用平均赋权,即ωp=ωa=0.33,ωf=0.34。权值的确定取决于特定应用对语义关注的侧重点,需进一步探讨,不在本文的研究范围内。
之所以采用组成部分、功能和属性3个方面相似度,是因为实体类表示的目的在于获取关于类的足够知识,以便对它们进行区分[13],功能如教育(大学)、医疗(医院),组成部分和其他属性可以进一步提供类别间区别的细节。
使用Tversky基于特征的语义评价模型计算Sp、Sf和Sa(式(2))[1,29]。t为类的某一特征(组成部分/功能/属性),C1和C2分别为类c1和c2的特征集,| |运算符用于计算集合的基数。
式(2)中函数α由式(3)计算。d(·)函数用于计算两个实体类在本体语义网中的距离,l.u.b.是类c1和c2的最小上界(least upper bound)对应的超类。参数α(c1,c2)的确定不仅使用上位/下位关系,还使用组成关系[29]。落入功能区(定义见2.2节)的居民地属于该功能区的组成部分(图5),但具有整体、部分关系的类的属性间不存在继承性。
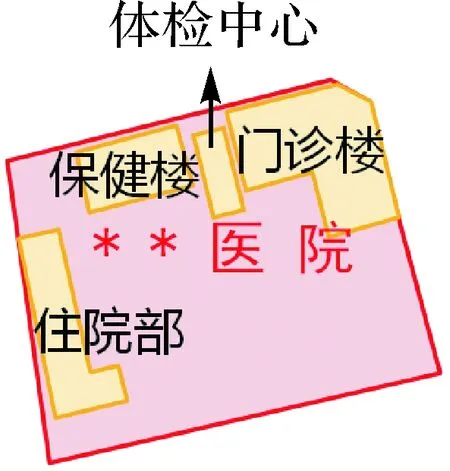
图5 语义功能区内的建筑物Fig.5 Buildings in a semantic function region
2.2 本体及模型参数的赋值方法
图4为本文采用的语义网络层次结构,由基于基础地理信息分类标准[31-32]和地理国情要素数据规定(GDPJ 03—2013地理国情普查数据规定与采集要求)共同确定。图中黑色部分由基础地理信息分类得到,蓝色部分是将地理国情要素数据“城镇综合功能单元”(面状,简称功能区)加入得到。将功能区加入层次结构,对应于在地图表示中加入功能区(图3所示)。考虑到功能区如居住小区、单位院落等是由单幢房屋或多幢房屋及院落构成,因此,功能区与基础地理信息“街区”类同属居民地的一种。标准中“街区”的含义是:两个以上的单幢房屋综合后按街区表示[31]。
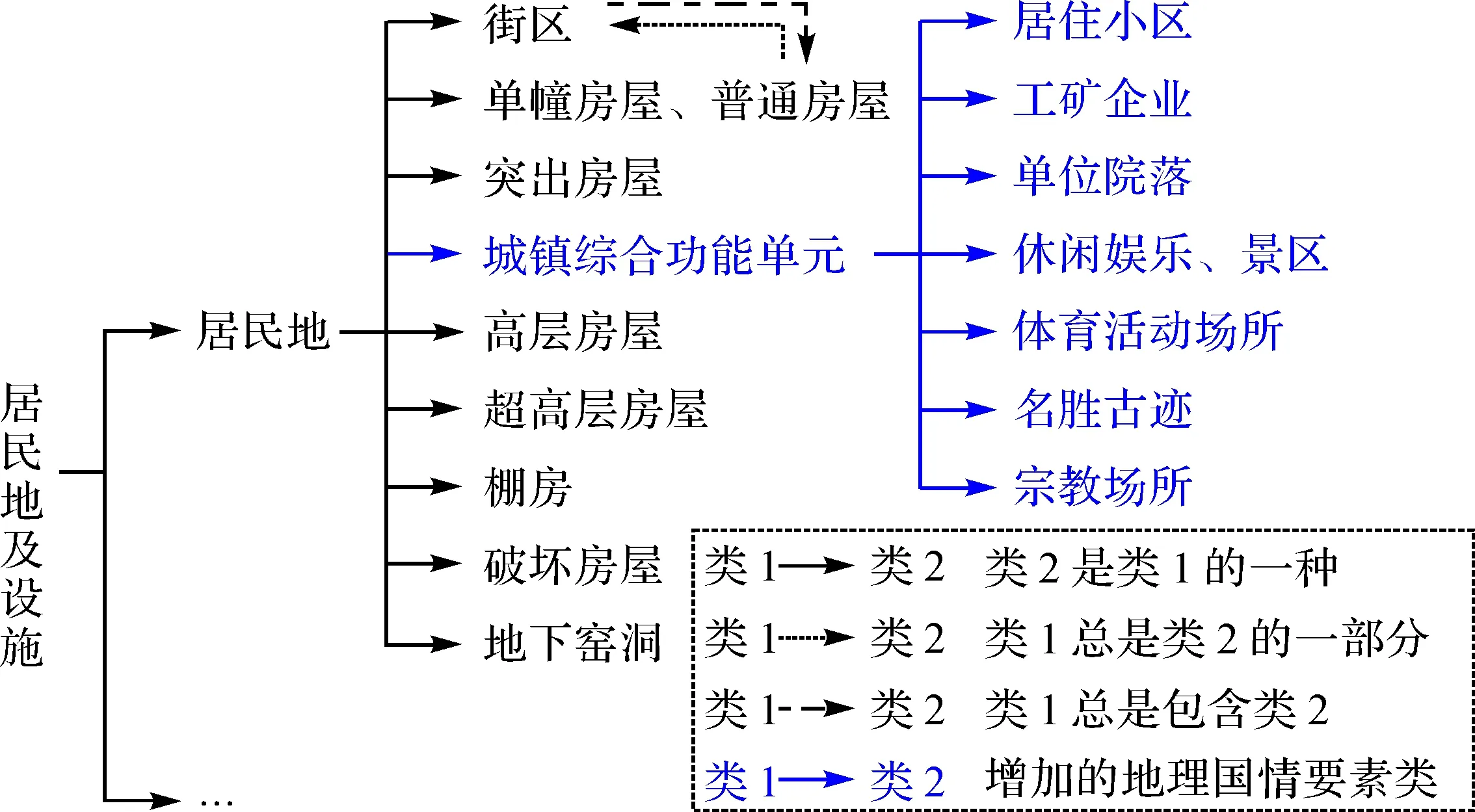
图4 基于基础地理信息分类标准和地理国情要素数据规定的语义层次结构Fig.4 Hierarchical structure based on topographic maps classification and national geographical survey specifications
确定组成部分、功能、属性的依据如下。
(1) 组成部分:组成部分由WordNet或其他来源如百科全书、字典等确定[28],WordNet是一个由普林斯顿大学认知科学实验室在心理学教授乔治·A·米勒的指导下建立和维护的英语字典(http:∥wordnet.princeton.edu)。所有建筑物的组成部分都是Cp={地基,屋顶,墙},是WordNet中组成部分的固有部分,不包括扩展部分[29]。
(2) 功能:功能区为位于面内的居民地赋予功能属性。如图5所示,功能区内的所有建筑物,即使其功能有差别,但从地图综合抽象的角度,均为其赋予医院的功能。该功能区“**医院”的建筑物包括门诊楼、保健楼、体检中心、住院部,功能属性集Cf=functionhospital={医疗,教学,科学研究,预防和社区卫生服务}。
(3) 属性:子类继承父类所有属性,并增加其特有的属性。父类“居民地”属性采用1∶5000基础地理信息数据RESA(面状居民地)的属性,子类“单幢房屋”采用1∶500—1∶2000基础地理要素数据字典属性,见表1。图5所示医院的属性采用地理国情要素城镇综合功能区属性项,Ca={名称,等级,类型,归属,建筑年代},增加其父类所有属性及合并时的有关属性。
2.3 功能区约束下合并过程语义相似度计算
地图综合中,语义相似关系的比较具有不对称性,即以综合后图上某个居民地i为目标(记为ci_smallScale),以最原始比例尺图上的对应居民地为参照(记为ci_largeScale)计算。合并过程中,综合后与综合前居民地数目比为1∶mi(mi≥1),二者的相似度为si(ci_smallScale,ci_largeScale)。包含了n个居民地的原始街区,综合后街区与原街区的语义相似度S(csmallScale,clargeScale)采用式(4)计算
(4)
3 试验与分析
为验证本文所述方法的有效性,选择兰州市3个街区(图3、图6、图7)计算综合中的语义相似度并进行分析。3个试验区中,试验区1的功能区面积相对较小,在1/8比例尺时完全综合为居民地,试验区2的建筑物间距相对较大,且3个试验区中,位于功能区内的建筑物数占比不相同,因此,3个街区各有特点,通过本文方法计算得到的折线图也各有特点(图9),3.3节将进行详细分析。
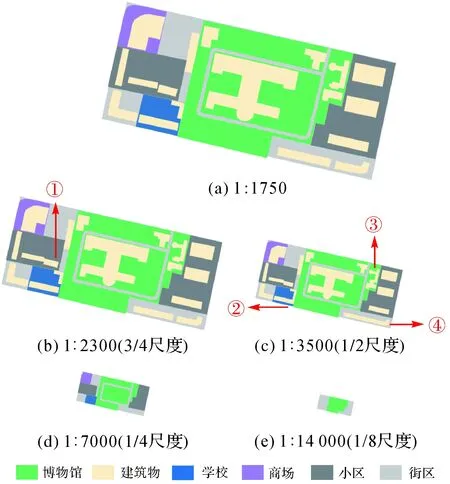
图6 试验区2地图综合中的语义变化Fig.6 Semantic changes of experimental city block 2 in map generalization
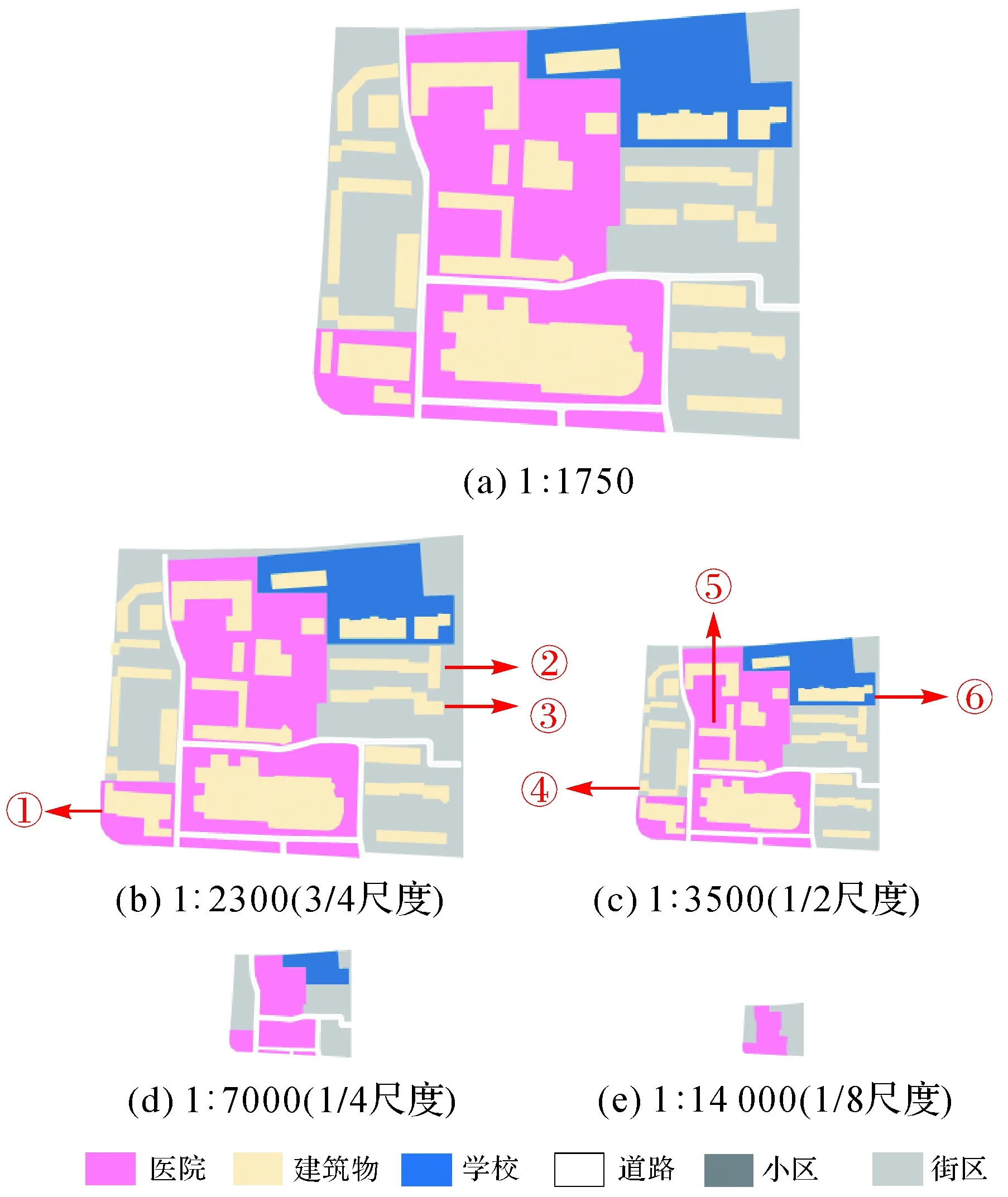
图7 试验区3地图综合中的语义变化Fig.7 Semantic changes of experimental city block 3 in map generalization
3.1 实体类相似度
表1、表2分别为实体类3个相似度分量赋值及各类之间的相似度。

表1 实体类组成部分、功能、属性各分量构成Tab.1 Similarity values for parts, functions and attributes of the class two or more buildings and class single building
3.2 综合前后街区相似度

表2 街区与单幢房屋相似度计算分量Tab.2 Similarity values for two or more buildings and single building in Fundamental geographic information features-General survey of geographical condition data ontology
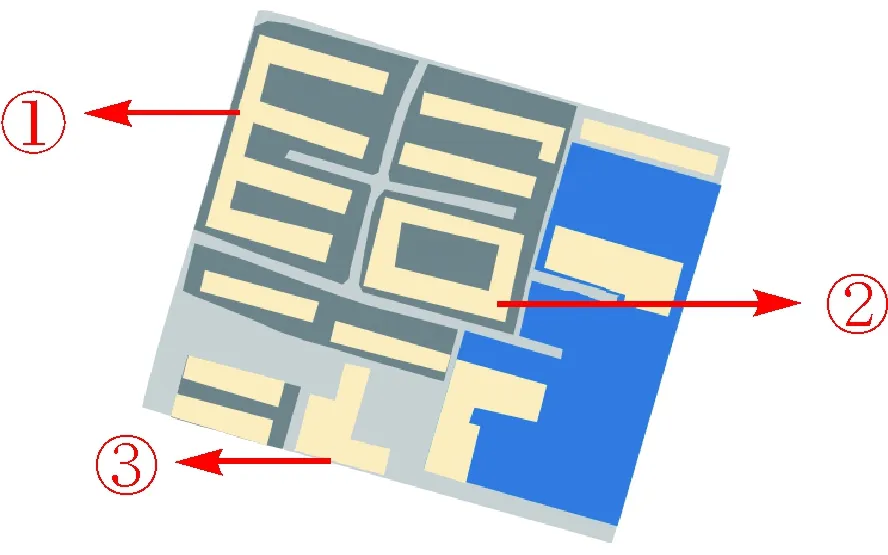
图8 图3(a)—图3(b)综合后语义变化Fig. 8 Semantic changes of buildings in Fig.3(b) compared with buildings in Fig.3(a)
3.3 试验结果分析
表3为3个街区的语义相似度计算结果,图9为折线图。由表3、图9可知:

图9 3个试验区不同比例尺节点的语义相似度Fig. 9 Semantic similarities of the three experimental city blocks at different scales
(1) 比例尺从原始(横轴值1)缩小至原始的1/2(含1/2,横轴值1/2)时,3个街区相似度的变化率都是各自变化率(表3中各街区的列方向)中最小的,分别为20.87%、11.69%和15.94%。因为在该比例尺范围,合并引起的语义变化主要是“单幢房屋/高层房屋/……”至“街区”,即两幢或两幢以上独立房屋合并为多幢房屋,建筑物间距是主要影响因素。3/4和1/2比例尺下,3个街区语义相似度:街区2>街区3>街区1,相似度变化率:街区2<街区3<街区1。度量结果与人的直观感受一致:街区2的建筑物间距较大,街区3次之,街区1的建筑物间距相对最小。

表3 试验街区语义相似度计算结果及变化率统计Tab.3 Semantic similarity values for experiment blocks at different scales and change ratio statistics
(2) 比例尺缩小至1/4(横轴值1/4)时,不再表示建筑物/街区,而表示出全部的功能区(图3、图6、图7)。1/4比例尺下,3个街区语义相似度:街区1>街区2>街区3,相似度变化率:街区1<街区2<街区3。与原始比例尺相比发生的语义变化是“单幢房屋/高层房屋/……”至“小区/医院/……”或“单幢房屋/高层房屋/……”至“居民地”,功能区内的建筑物数占比是主要影响因素,如表4所示,与3个街区语义相似度大小一致,符合人的直观感受:不再表示具体的建筑物形状时,将整个街区表示为“居民地”的地图表达,不如小区、学校、博物馆等功能区表达清晰,前提是在合适的尺度范围内。

表4 试验街区功能区内建筑物数占比Tab.4 The proportion of building numbers in function units of whole experimental blocks
(3) 比例尺缩小至1/8(横轴值1/8)时,用选取算子对功能区实施取舍。保留该比例尺下面积大于图解尺寸的功能区,舍去其他较小的功能区,语义变化是“单幢房屋/高层房屋/……”至“小区/医院/……”或“单幢房屋/高层房屋/……”至“居民地”。此时,保留的功能区内的建筑物数占比是主要的影响因素,如表5所示,3个街区语义相似度与占比呈正相关:街区2>街区3>街区1。又由于取舍主要取决于功能区的面积,因此街区内功能区的面积也间接影响了相似度的变化。街区1的功能区全部舍去(图3(e)),与原始比例尺(图3(a))相比,无法获得该处存在学校、小区这一信息,此时语义信息主要通过POI点、注记获得。

表5 试验街区保留的功能区内建筑物数占比Tab.5 The proportion of building numbers in function units reserved in experimental blocks
(4) 最小相似度和最大相似度。图9中,灰色、绿色虚线为各比例尺下相似度均最小、最大时的折线,对应街区不存在功能区及所有建筑物都在功能区内两种情况,两条折线构成的灰色范围是所有街区语义相似度的可能分布范围。可以看出,试验中3个街区各比例尺的相似度都大于等于最小相似度,是因为各街区都存在功能区,相比最小相似度的情形,即不以语义功能区为约束合并、选取的情况,提供了更多的语义信息。
3.4 从地图信息论的角度评价本文方法
由3.3节的分析可知,语义功能区约束下的建筑物合并、取舍提高了综合后地图与综合前地图的语义相似度。从信息传输的角度考虑,地图符号的信息熵度量也是一种量化地图有效性的工具。本文使用文献[33—34]提出的方法计算图10(图6,试验街区2东北侧小区及位于其中的建筑物)地图符号的专题信息熵(式(5)),式中符号的含义见文献[32]。
在未加入功能区时,图10中3个建筑物的邻居都是建筑物,此时专题信息熵为0(不考虑几何信息熵和拓扑信息熵)。加入功能区后(图10),功能区中建筑物的直接Voronoi邻居包括了建筑物和功能区两个类型,各建筑物符号的专题信息熵如图所示,整个街区的专题信息熵是街区内所有建筑物符号及功能区符号专题信息熵的总和,大于未加入功能区的信息熵。这符合文献[33]的结论:如果某符号的邻居符号(由直接邻近Voronio区定义)都具有与该符号相同的专题类型,那么,从专题信息的角度看,该符号的重要性非常低;相反,如果一个符号具有不同专题类型的邻居符号,则该符号具有较高的专题信息量。

图10 试验街区符号的专题信息熵计算示例Fig.10 Examples for the calcuation of thematic information
(5)
4 结 语
本文提出一种语义功能区约束下的街区式居民地综合的质量评价方法,并基于匹配距离模型计算该综合过程中试验街区在某些大比例尺节点的语义相似度,进而得到相似度随比例尺缩小而变化的折线图及最小相似度、最大相似度的范围。通过对计算结果的分析表明,本文方法与人的视觉感受效果一致,语义相似度在各比例尺节点的相对大小反映了街区内建筑物、功能区的特点,语义相似度的绝对大小说明本文所述综合方法比完全基于建筑物间距实施合并、取舍更能保留原图语义信息。最后,通过计算地图符号的专题信息熵,说明本文方法提高了地图符号的专题信息熵。本文是对多尺度地图空间居民地语义相似关系量化计算的一种探索,但方法仅适合约1∶1750至1∶14 000的大比例尺地图空间,且试验选择了个别街区,更小比例尺或大比例尺范围内整幅地图语义相似度的研究将是今后的研究方向。
