基于“企业+农户”模式的肉鸡养殖精准化管理平台
2022-03-04付金禄李丽华贾宇琛邸梦醉周子轩
付金禄,李丽华,2,3*,贾宇琛,邸梦醉,周子轩
(1.河北农业大学 机电工程学院,河北 保定 071000;2.农业农村部肉蛋鸡养殖设施工程重点实验室,河北 保定 071000;3.河北省畜禽养殖智能装备与新能源利用重点实验室,河北 保定 071000;4.河北农业大学 信息科学与技术学院,河北 保定 071000;)
十三届全国人大第二十八次会议通过的《中华人民共和国乡村振兴促进法》中强调培育新产业、新业态、新模式和新型农业经营主体,促进小农户和现代农业发展有机衔接[1]。“企业+农户”养殖模式的稳定发展成为了保持乡村振兴活力不可忽略的因素,是实现农业现代化的必由之路[2]。该模式由企业向农户提供生产资料和技术服务,农户负责生产管理。肉鸡养殖周期短、养殖规模和出栏量大,养殖数据更新迭代迅速,产生海量数据。在该生产模式的实际运行中,如何对养殖过程中长期积累的环境数据、生产数据及视频数据进行实时监测、采集和高效存储成了亟待解决的关键问题。
目前,随着物联网技术[3-4]、射频识别技术[5]、云技术[6]和区块链技术[7]的发展与成熟,养殖系统的研究中大多偏重于使用传统的数据模型管理禽舍环境信息。李国强等[8]采用超高频射频识别技术RFID,以Android Studio为开发平台,使用SQLite轻型数据库构建了手持式牛场管理系统。Zheng[9]等以阿里巴巴云数据库为核心,结合关系型数据库MySQL5.7及Qt5框架设计出基于云数据家禽养殖信息管理系统。Choukidar等[10]将无线传感器与GPRS相结合,使用MySQL作为数据库,Apache搭建Web服务器构建了智能家禽管理系统。魏圆圆等[11]针对“农场+生产队”管理模式的大中型农场农业的生产管理需求,采用MySQL作为数据库,设计了基于WebGIS的农场生产管理信息系统。上述研究中大都基于传统的数据模型对养殖个体信息及环境数据进行存储和查询[12-18]。但随着数据规模的增大,常见的关系型数据库难以存储,数据的读写吞吐量受限,响应延迟,无法满足大数据的存储及高并发的访问需求。而对于海量非结构化音、视频数据的查询及存储,分布式系统平台和NoSQL非关系型数据库在扩展性、容错性和可用性方面具有巨大优势[19-23]。陈红茜等[24]研发了基于分布式流式计算框架Data-Canal的蛋鸡养殖实时监测与预警系统,用于实现蛋鸡养殖生产过程参数实时监测与预警。邹远炳等[25]基于分布式流式计算框架Storm的生猪养殖实时监控系统,实现集群中各计算节点负载均衡、多种编码格式的视频数据无缝解析、生猪视频流数据的高效实时处理。与传统单体架构相比分布式框架计算能力更强,灵活性更高,更具开放性。但分布式系统架构的设计较为复杂,学习周期较长。故目前分布式框架在畜禽养殖系统开发研究较少,且多局限于对养殖场所及动物个体状态进行监督所形成非结构化音、视频数据的处理及存储。而面向养殖全过程中产生的结构化数据及非结构化数据的整合服务的研究较为鲜见。
本文基于“企业+农户”养殖模式,选用高性能、易扩展、安全可靠的Hadoop生态系统,搭建肉鸡养殖精准化信息管理系统。将结构化环境数据适配解析为统一格式,存入HBase与MySQL的混合存储模式中,以提高数据查询效率。运用Ha⁃doop的两大核心HDFS分布式文件系统及Ma⁃pReduce计算模型结合FFmpeg视频处理工具解决海量非结构化视频数据格式的转码问题。实现对家禽养殖企业日常办公和生产任务进行管理,构建整个养殖过程中产生的生产过程数据、环境数据及监控视频构建数据的存储标准,从而进行实时监测和统一管理且为后续预警、分析提供数据支撑。
1 材料与方法
1.1 系统业务流程设计
系统业务包含肉鸡养殖过程中的数据操作和信息展示,其中结构化数据和非结构化数据的读写任务需不同的流程来处理,分别为数据采集、处理、分类、存储。
数据采集。系统的数据来源有2类,一类是由人工录入的数据,这类数据的数据量少,易存储且数据格式单一;第二类为自动采集的数据,包含传感器数据和视频监控数据,由多源异构的终端设备实时采集鸡舍内的环境数据和视频数据,经不同类型的传输网络接入数据处理终端。其中传感器包含温湿度、CO2浓度、NH3浓度、风速、光照强度、H2S浓度、PM2.5和PM10浓度等。
数据处理。由于传感器类型多样、传感器节点因不同生产商制造存在差异性,导致数据传输协议和数据结构存在差异。为解决此难题,设计适配中心模块,将异构数据标准化,实现数据统一管理。目前大多摄像设备的编码格式对电脑系统或浏览器的版本要求很高,故将视频数据进行分布式转码和封装,能够与常用浏览器更兼容。
数据分类。Kafka集群接收到数据后,启动程序获取元数据信息,Producer从Broker-List节点中获取生产(Production)、环境(Environment)、图像(Video)、视频(Image)4个主题 的 分 区中的Leader,并将元数据消息写入其中,follower则主动同步Leader中的数据消息,进行备份。数据写入后,存储到Partition文件夹下的segment文件中,以.log文件形式存储,从而被消费者进行分发处理,达到数据分类的目的。
数据存储。数据处理终端接收到不同主题的数据后,根据不同的存储方案进行存储。将日常生产数据存入MySQL数据库;环境数据存入MySQL+HBase的混合模式中;图片及视频数据存入HDFS文件系统当中。
信息展示。系统设计web及手机移动终端,更直观的向用户展示各项养殖数据,实现数字化养殖。系统业务流程见图1。

图1 系统业务流程图Fig.1 System business flow chart
1.2 系统功能模块设计
系统划分为4个功能模块:基础信息管理模块、环境管理模块、库存管理模块、设备管理模块。具体功能模块见图2。
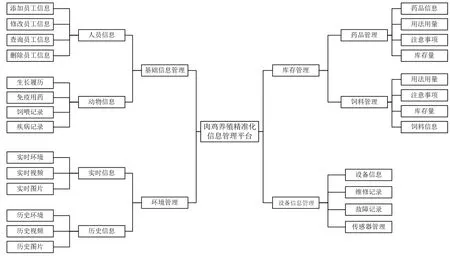
图2 系统功能设计Fig.2 System functional design
(1)基础信息管理模块:包含人员信息管理和动物基本信息管理。企业可对各养殖基地员工注册的个人信息进行增、删、改、查操作。同时管理由养殖员工上传的日生产数据,即每批次鸡只各阶段的个体信息、饲养管理、疾病记录、免疫药的使用情况等。由企业管理人员审核,为后续分析鸡只最佳饲养方式提供数据基础。
(2)环境管理模块:主要负责向用户展示鸡舍内的实时环境信息和历史环境信息。应用温湿度、有害气体、光照等环境传感器和摄像头,采集大量环境和生产信息,对接显示模块查看实时信息,数据处理后存入系统成为历史数据,以备用户下载查看。
(3)库存管理模块:负责记录由企业向基地定时输送鸡苗、饲料、兽药、养殖设备及养殖技术培训服务等,便于监督各基地是否按照养殖流程进行饲养。
(4)设备管理模块:由于各基地使用的设备型号不尽相同,设置该模块,记录设备基本信息、维修次数及故障信息。同时设计出适配器模块解决由多源异构的终端设备及传输协议多样造成的数据格式差异性问题,将数据解析成为通用的数据交互格式,便于后期存储。
1.3 异构感知数据的处理与存储
1.3.1 环境监测数据的处理
目前对于异构感知数据接入的研究中大多通过创建映射规则进行协议转换,将底层协议转换成适配框架内的协议,但此方法依赖固定的映射模板,数据源发生改变时,将不再适用。为实现物联网传感器数据的统一接入、存储和共享管理,本文构建了异构感知数据接入框架提出异构感知数据的动态适配方法,解决因传感器种类、数据传输协议和采样频率多样性造成的数据格式不一致的问题,使得异构数据标准化。该框架包含传感器信息接入模块和传感器适配模块。
传感器信息接入模块。该模块需要上传传感器基本信息注册。传感器基本信息见图3,其中通信能力指明传感器传输协议和通信接口方式,用于与上层结构建立通信连接;处理方法记录输出数据的来源;参数信息则详细描述输出数据的结构。根据以上信息及其相关性,与方法库中的适配解析方法进行匹配从而动态生成适配器,实现异构传感器数据的动态适配接入。

图3 传感器基本信息类的UML图Fig.3 UML diagram of the basic sensor information class
传感器适配模块。该模块是将传感器采集数据解析封装成标准数据格式供上层应用使用,包含传感器连接功能、解析方法适配功能及动态生成适配器功能。传感器采集数据由各传感器的网络模块上传并暂存于本地服务器,通过TCP、UDP、HTTP等不同协议向数据处理终端传输数据,系统根据不同传输协议及传感器注册信息自动生成适配器。适配器模块分为连接层、解析层和数据发布层,其结构见图4,适配器自动生成步骤见图5。连接层负责选择合适的连接器与传感器建立通信连接;解析层负责选择解析方法进行组合完成解析,解析方法由传感器注册信息提供的接口与数据封装协议编码而成,由Java的动态加载机制加载生成最终的解析方法;数据发布层是将解析后的感知数据由Kafka的产者发布到消息队列Kafka服务器中。
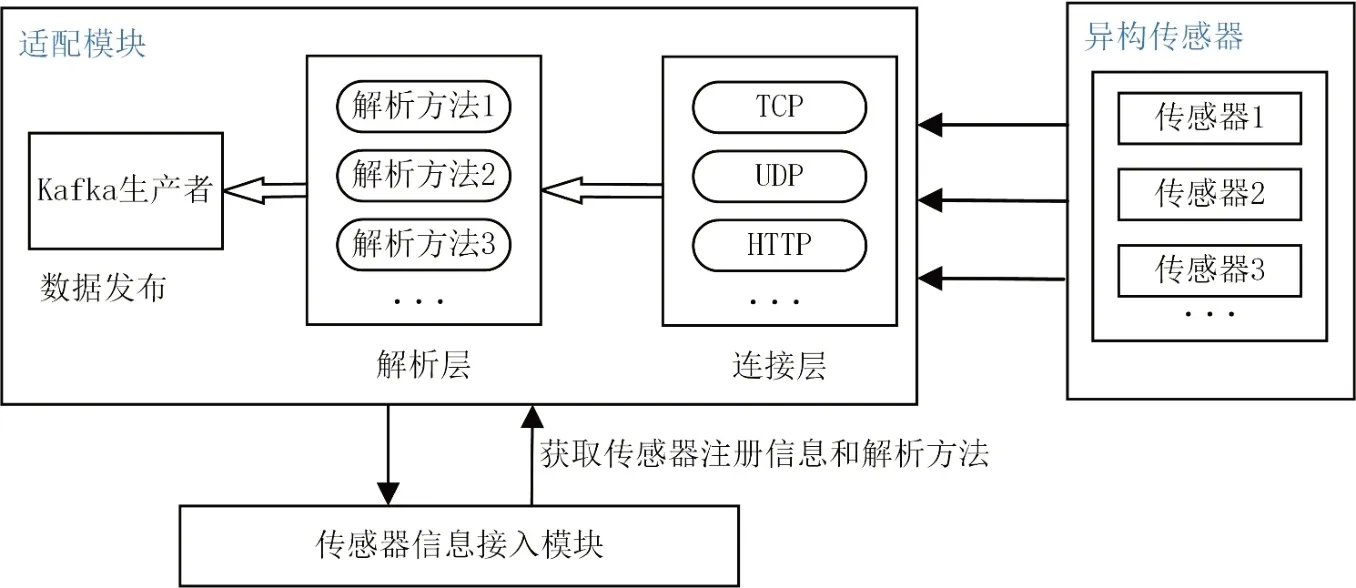
图4 传感器适配模块结构图Fig.4 Structure of sensor adaptation module

图5 适配器自动生成步骤Fig.5 Steps of automatic adapter generation
1.3.2 环境监测数据的存储设计
系统选择MySQL与HBase的混合模式存储环境数据。当数据处理终端集群收到Kafka集群传来的主题为环境(Environment)的消息后,同时插入MySQL和HBase数据库中。MySQL对较小数据量实时查询的能力较强,负责存储近30 d的数据,而对于较大数据量或历史数据进行查询时选择HBase数据库。用户查询时输入起止时间,系统自动辨别是否属于近30 d的数据,进行查询。
创建高效的数据库,其不可忽略的因素即为预分区及行键的设计。HBase默认建表时会创建一个没有边界的Region。存储大量数据时,若在建表前不针对HBase表进行预分区,数据将批量存入到这个Region区域中,当数据量达到分区阈值时会频繁进行分裂(Region-split)操作,造成写热点问题,同时Region-split会消耗较多时间和集群的I/O资源,影响集群的稳定性。设计符合数据特征的行键能够使数据均匀分布于所有的Region中,防止数据倾斜。基于此调用HBase提供的API中 的HBaseAdmin.createTable(tableDescriptor,splitKeys)进行预分区建表,创建多个空Region,设计Rowkey,确定每个Region的起始和终止,减少Region-split,从而降低资源消耗。由此RowKey的格式设计为“基地号+鸡舍号_采集时间”,共占19字节。基地号采用字母+数字的格式,以避免写入数据时按字典顺序递增问题。查询数据时,若查询基地号为YX01,鸡舍号为01,采集时间为2022年6月27日,则Rowkey的设计为YX0101_202206271512。根据鸡舍内结构化数据的特点,将其分为2个列族,分别为气象列族、气体列族,包含温度、湿度、光照强度、CO2浓度、NH3浓度、粉尘浓度等,HBase结构及数据样表如表1所示。
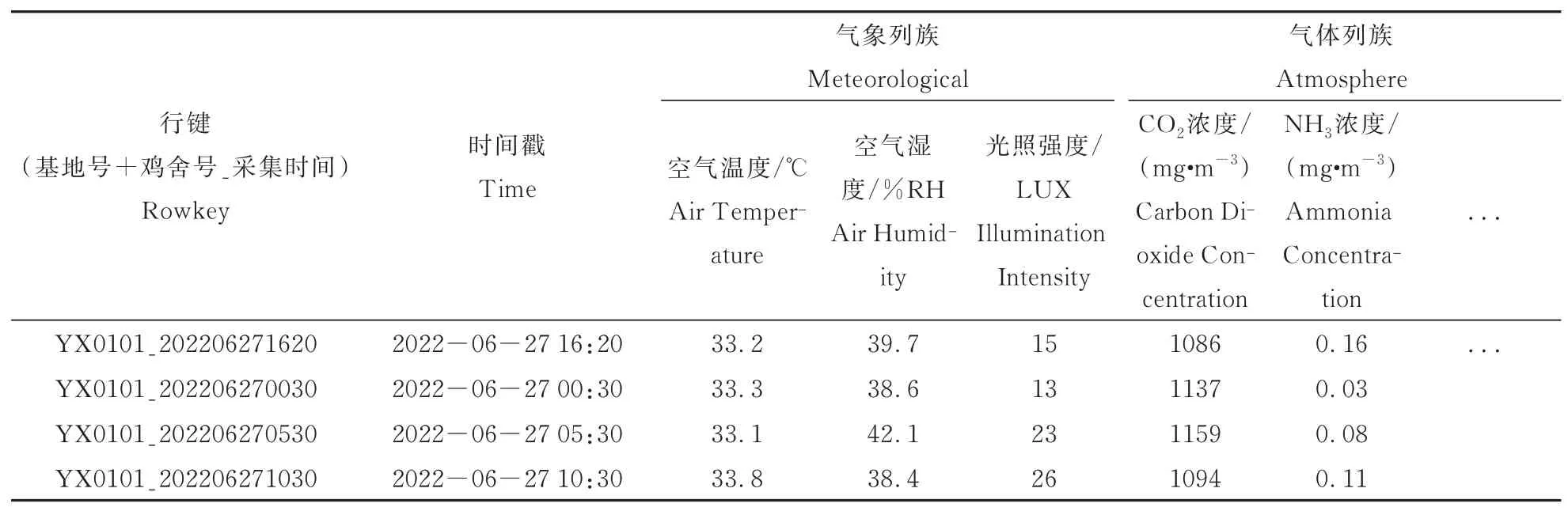
表1 HBase环境数据存储表结构Table 1 HBase environment data storage table structure
1.4 视频数据的分布式转码与封装
市面上的摄像头,主要以h.265为编码格式,部分编码格式为h.265兼h.264格式,封装格式多样。2种编码格式的视频均需专用的播放器,不利于集中展示。另一方面,视频数据封装格式多样,无法直接实现视频数据的分析,增加数据处理难度。为了使采集的数据流与常用的浏览器更兼容,同时支持绝大多数多媒体设备,采用更高效的分布式转码技术对视频数据进行处理,并封装成MP4格式。常用浏览器,如:Chrome谷歌浏览器、Firefox火狐浏览器、IE浏览器及Edge微软浏览器均支持播放由h.264编码格式封装而成的MP4格式的视频。
1.4.1 基于MapReduce视频分布式转码设计
本文采用Hadoop的另一核心Mapreduce计算模型实现大规模数据集的并行运算。其具有良好的扩展性、使用简单灵活、高效且稳定,转码后不损失视频质量。
视频数据以block的形式存储在HDFS中,一个视频文件可由一个或多个block组成,且block的大小可调。视频由帧组成,帧与帧之间有较强关联性。若直接由Map()函数操作视频帧来处理block中的视频块,可能会造成帧的缺失而出现跳帧,甚至导致转码后视频文件的不可播放。因此,通过视频处理工具FFmpeg提前对视频数据进行分割,充分发挥Mapreduce的并行处理能力。视频分割完成后调用Hadoop shell上传到HDFS文件系统中。同时生成record.txt文本文档来保存HDFS上的原始文件和目标文件的路径。存储完成后启动MapReduce分布式计算模型,Map()函数和Reduce()函数的定义如下:

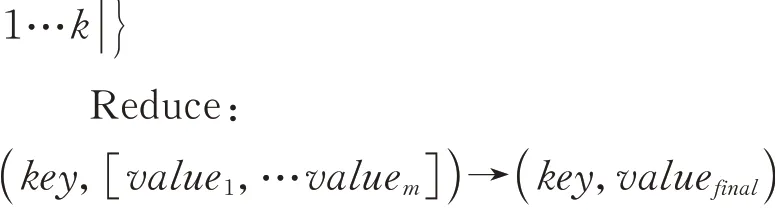
用户发出指令,由Job Tracker进行任务调度,Map()函数接收到任务后,以<文件名,文件路径>键值对形式作为输入,解析视频文件路径,在HDFS文件系统中下载相应视频数据,调用FFm⁃peg命令进行转码,视频经转码完成后存入HDFS中。Map()函数和Reducce()函数结构类似,Map()函数将输出结果传递给Reducce()函数,即Re⁃duce()函数的输入为<转码后视频片段的文件,转码后视频片段的文件路径>,Reduce()函数通过键值对解析转码成功后的视频文件路径并下载,调用FFmpeg将视频片段合并,合并好后上传至HDFS文件系统中。Map及Reduce函数流程图见图6。
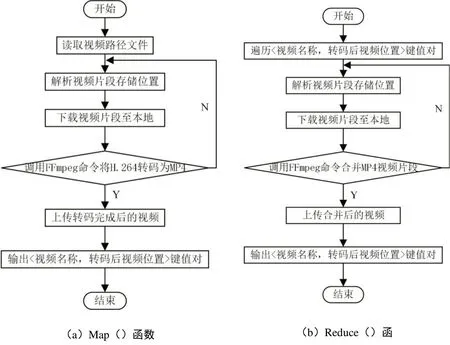
图6 Map函数、Reduce函数流程图Fig.6 Map function、Reduce function flow chart
1.4.2 视频数据的存储设计
接收到Kafka集群分发的视频数据后检查视频的格式,若为MP4封装格式则直接存储于HDFS文件系统中,同时将视频编码和存储路径等详细信息写入MySQL数据库的视频表中。若为h.264编码格式则将视频分割为视频段并存储于HDFS中。由Hadoop集群中的NameNode负责调度,执行Map()函数及Reduce()函数进行转码及合并,完成后再将视频上传至HDFS文件系统中,并将视频信息写入MySQL数据库中。用户可点击视频列表中的视频名获取视频位置,进行播放或下载。
2 结果与分析
2.1 Hadoop平台环境
系统由3台相同配置的服务器组成Hadoop集群进行试验分析,处理器为Intel(R) Core(TM)i5-10210U,最高主频为2.11 GHz,内存为16 G,硬盘大小是4 T。操作系统为Centos7,Hadoop版本是Hadoop 3.1.4,HBase版本为HBase 1.4.13,FFmpeg版本为FFmpeg 2.8.15。集群中有一台为主节点NameNode,2台从节点DataNode。
2.2 试验数据和结果
环境数据于河北玖兴农牧肉鸡养殖有限公司旗下的保定市西山北村养殖基地采集。基地内共有10栋鸡舍,每栋鸡舍内设置温湿度、光照强度、风速、H2S、NH3、CO2、PM2.5、PM10等传感器,基地内栋舍及设备的布局见图7。各传感器设置3 min采集1次,数据月产量为2 016 000条。系统搭建完成后在企业及农户养殖场投入试运行,经3个月采集积累了包含上述各环境参数在内的500万条数据,运用此数据进行了以下试验。

图7 基地内栋舍及设备的布局图Fig.7 Layout of buildings and equipment in the base
2.2.1 异构感知数据处理试验结果
环境数据处理试验数据,随机抽取环境数据并分为5组,数据量级别分别为5万条,50万条,150万条,300万条,500万条,将数据写入3台相同硬件配置的集群节点中,分别对MySQL集群与本文设计的Hadoop存储系统进行5次查询操作,对5次查询时间取平均值(图8)。
从图8可以看出,当数据查询规模较小时,传统的MySQL数据库表现出了良好的查询性能。HBase查询时需要先将数据载入内存当中,耗费时间。当存储规模为216万条时,MySQL集群与Hadoop集群的查询效率基本持平。随着数据量规模逐渐增多,HBase的查询耗时趋于平稳,相比MySQL集群,数据总量为500万条时,数据查询效率提升了31%。

图8 不同存储规模MySQL及HBase查询耗时对比Fig.8 Comparison of MySQL and HBase query time consumption for different storage sizes
因此,MySQL在存储查询小规模数据时性能高于HBase的性能,所以使用MySQL存储近30天的环境数据。但在高并发、高吞吐量的情况下,Hadoop集群处理大量数据的优势充分显现,故将HBase用于存储历史环境数据。
2.2.2 视频分布式转码性能测试
本试验在搭建好的Hadoop集群上运行。待转码视频文件大小为1 GB,试验分析不同整体大小、不同分割大小的视频转码所需时间及单机转码与分布式转码的效率。分析如下:
(1)将1 GB的视频分别分割为32、48、64、80、96、112、128、144、160 MB的片段进行分布式运行,分别运行3次,将3次运行耗时结果取均值,结果见图9。

图9 1 GB视频不同分片大小分布式转码耗时Fig.9 Distributed transcoding time for 1 GB video with different slice sizes
从图9可以看出,随着分段大小的依次递增,分布式转码消耗的时间呈现先减少后增大的趋势,直到分割为128 MB时,所需转码时间最少为92.65 s。而在分割片段大于128 MB后,转码时间开始增加。故当视频文件为1 GB时,128 MB为最佳分片大小。
(2)为比较分布式转码与传统单机转码的效率,选择不同大小的视频以最佳的128 MB作为分片大小,对转码时间进行比较(图10)。
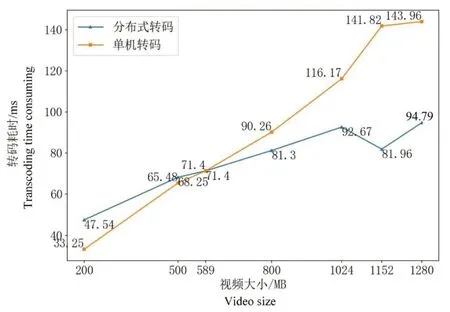
图10 单机转码与分布式转码耗时对比Fig.10 Comparison of time consumption between stand-alone transcoding and distributed transcoding
由图10可见,单机转码时,转码耗时随视频大小增加而增加。执行分布式转码时,文件需经过上传,下载并在集群之间进行网络通信,故在转码较小视频文件时耗时较多。当视频文件大于589 MB后,分布式转码时间与传统单机转码相比优势显现,当视频大小为1.1 GB时,转码耗时最少为81.96 s。选取128 MB作为分片大小,当视频文件大小为1 GB时,分布式转码耗时与单机转码相比提升了54%。因此可以适当增加视频时长,将文件大小增至1.1 GB在进行存储,转码时可达到最佳转码速度。
2.2.3 管理信息平台的可视化
根据使用场景不同,系统基于Java Web技术,将CSS、Jsp、Spring框架等技术进行整合,设计出web使用终端,企业可进入web端首页登录系统进行访问,查看养殖场内各项基本信息,包括鸡只基本信息、环境信息、视频等(图11)。通过Wxml+Wxss+js技术制作手机移动终端的应用程序,便于用户及时发现问题并解决,降低养殖风险。农户可通过手机端登录系统,查看信息,并上传日常饲喂、设备维修、饲料入库、防疫记录等信息(图12)。

图11 web端系统界面Fig.11 web-side system interface

图12 手机端界面Fig.12 Mobile interface
3 讨论
本系统在开发完成后,部署在河北玖兴农牧肉鸡养殖有限公司和保定市西山北村养殖基地投入实际应用,为企业管理员和养殖农户提供服务。系统对文本数据、传感器数据和视频数据3类数据源进行分析处理,实现实时监测鸡场内生产、环境、监控数据。
然而在畜禽养殖环境监测中多采用传统关系型数据库进行存储,本系统采用了HBase+MySQL的混合存储模式。在查询速度方面,非关系型数据库将数据存储于缓存之中,关系型数据库将数据存储在硬盘中,在高并发用户访问时,关系型数据库的查询速度远不及非关系型数据库,本系统针对养殖数据的特点设计了行键,进一步提高了数据查询效率。在扩展方式方面,关系型数据库是纵向扩展,为了支持更高并发量,需要提高计算机性能来确保处理相同数据集时处理速度更快。虽然关系型数据库有很大扩展空间,但最终肯定会达到纵向扩展的上限。而非关系型数据库是横向扩展,非关系型数据库采用分布式存储,其扩展可以通过给集群添加更多普通的数据库服务器来分担负载。结合本系统测试结果,并从上述两方面进行考虑,选择使用MySQL存储近30天数据;当数据量和用户访问量大增时,采用HBase数据库进行存储。本文试验所得结果与王新阳[26]、苑严伟等[27]将HBase应用于森林生态大数据及农田大数据从而提升查询效率所得结果较为一致。应用混合模式的存储方式将两类数据库的性能发挥的更极致,使得查询速度达到最佳。本系统采用基于Hadoop的分布式转码方案,在视频上传完成时即可实现转码,将转码时间缩短至一半,研究结果与邢艳芳等[28]的研究结果较为一致。本系统在MapReduce计算模型的基础上结合FFmpeg对视频数据提前分片并处理进行编解码,确保了数据的完整性,同时充分发挥了集群的并行处理能力,突破了单机转码技术的瓶颈。
然而,经本系统构建的数据存储标准能否充分利用到分析鸡只最佳生长环境、疾病预警等的实际研究中仍需进一步探讨和验证。除此之外,为进一步完善系统,应纳入鸡只声音数据丰富养殖数据源,为后续搭建鸡只健康养殖评价模块提供强有力的数据支撑,进而优化平台功能提高肉鸡精准化养殖程度。
4 结论
本系统基于Hadoop框架设计了肉鸡养殖精准化管理信息平台。平台通过人工输入和传感器自动化收集整个养殖周期内的环境数据和生产数据,并采用动态适配方法将异构数据标准化,应用MySQL+HBase的混合存储模式进行数据存储。试验数据表明,数据总量为500万条时,数据查询效率可提升31%。对实时视频采用MapReduce与FFmpeg相结合的方法进行分布式转码与封装,在保证视频数据完整性的基础上,使视频兼容大部分浏览器,便于可视化设计。平台设计了web和手机两种终端的信息展示和用户交互方式,便于企业和基地人员实时掌握鸡舍内设备运行状况及鸡只生长情况。
