煤矿井下无人驾驶无轨胶轮车目标3D检测研究
2022-03-04秦沛霖张传伟周李兵王健龙
秦沛霖, 张传伟, 周李兵, 王健龙
(1.西安科技大学 机械工程学院, 陕西 西安 710054; 2.中煤科工集团常州研究院有限公司, 江苏 常州 213015; 2.天地(常州)自动化股份有限公司, 江苏 常州 213015)
0 引言
煤矿辅助运输在生产过程中具有举足轻重的作用,但其智能化水平亟待提升。无轨胶轮车作为重要的煤矿辅助运输手段之一,实现其无人化可有效降低人身安全事故率和信息管理难度[1]。
环境感知是实现无人驾驶的基础,主要为无人驾驶车辆决策和规划提供有效信息。常用的环境感知手段包括2D平面检测和3D立体空间检测。2D检测仅能输出目标在2D图像中的检测锚框,对于无人驾驶车辆应用场景,无法完全提供环境感知任务所需的平面坐标及立体姿态、实际尺寸等信息,因此需进行3D检测。
常用的3D检测方法包括:① 基于图像检测法。具有代表性的是YOLO3D[2],其网络主体为YOLO系列使用的Darknet,在此基础上加深了网络层,并采用反卷积手段,使得网络在获取更深层特征信息的同时保留位置信息。A. Mousavian等[3]、F. Chabot等[4]采用单目相机图像生成了高精度3D锚框。Chen Xiaozhi等[5]采用深度相机实现了高质量3D检测。基于图像检测法在常规环境下表现良好且成本低,但煤矿井下视觉条件恶劣,该方法无法满足检测准确性要求。② 基于雷达点云检测法。具有代表性的是体素网络,其将雷达点云数据划分为体素,通过体素特征编码层转换为统一格式的表达,采用RPN(Region Proposal Network,区域生成网络)对物体进行分类回归。Li Bo等[6]通过将雷达点云数据转换为前视图和俯视图进行3D检测。基于雷达点云检测法可有效应对井下复杂工况,但缺乏环境语义理解,不利于无人驾驶后续处理流程。③ 融合图像和雷达点云检测法。具有代表性的是AVOD(Autonomous Vehicle Oriented Development,以自动驾驶汽车为导向的开发模式)[7],其输入雷达点云数据和RGB图像,利用特征金字塔网络对二者进行特征融合,挑选出合适的3D候选框进行检测。Chen Xiaozhi等[8]采用点云转换的俯视图、前视图与相机图像融合,实现对物体的检测。C. R. Qi等[9]采用视锥法,将图像检测结果的先验投影到点云的视锥范围内求解3D锚框,从而实现目标检测。融合图像和雷达点云检测法准确性高,但在有效融合基础上进一步提升处理速度,保证无人驾驶情况下的实时检测,还有待进一步研究。
目前无人驾驶技术在露天矿卡车中已有一定的研究成果[10]。但在煤矿井下环境中,因光照不足,导致RGB图像信息缺失,且巷道空间狭小,导致激光雷达采集的点云数据存在较多噪声,影响目标检测精度。因此,现有方法应用于井下无人驾驶无轨胶轮车目标3D检测时难以取得较好效果[11]。针对该问题,本文结合井下环境及无轨胶轮车低速行驶特点,提出了一种融合图像和雷达点云的无人驾驶无轨胶轮车目标3D检测方法,通过对RGB图像和雷达点云数据进行预处理及特征融合,实现了无轨胶轮车运行环境中目标实时、精确检测。
1 环境信息获取及预处理
采用Livox Horizon三维固态激光雷达及D1300-IR-90单目相机分别获取无人驾驶无轨胶轮车行驶环境的点云数据及RGB图像数据,安装方式如图1所示。Livox Horizon的水平视场角为87.1°,安装后可实现360°视场全覆盖。

图1 激光雷达与相机安装方式Fig.1 Setting mode of laser radar and camera
1.1 图像数据增强
由单目相机获取的RGB图像在室外光照良好的环境中可满足目标检测任务要求,但在煤矿井下表现欠佳。因此,本文对RGB图像进行全局直方图均衡处理,调整图像亮度及饱和度,以降低井下光照不均影响。
将图像从RGB模式转换为HSL模式,以便在L空间内对图像进行亮度调整。转换方法为分离出R,G,B通道像素值并对其进行线性运算,即
(1)
式中:D为图像亮度;fjmax,fjmin分别为j通道的最大、最小像素值,j=R,G,B。
令Dk(k为图像亮度级数)为D的离散形式,则经全局直方图均衡处理的图像亮度为
(2)
式中:T(Dk)为全局直方图均衡转换函数[12];ni为图像亮度级i对应的图像像素数;N为图像像素总数。
将全局直方图均衡处理后的HSL图像还原为RGB图像,如图2所示。可看出经全局直方图均衡处理的RGB图像(增强图像)在视觉上更加柔和,各通道亮度分布更加均匀,待测目标与背景区分更加明显,有利于后续目标检测。

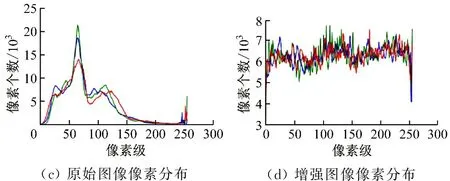
图2 图像经全局直方图均衡处理前后对比Fig.2 Image comparison before and after being processed by global histogram equalization
1.2 点云数据滤波及降维
对点云数据进行滤波,以减小噪声。常用的滤波算法见表1。

表1 常用的滤波算法对比Table 1 Comparison among common filtering algorithms
对于无人驾驶无轨胶轮车目标检测任务,其最重要的是保存目标边缘信息。从表2可看出,双边滤波算法可保留原数据的边缘信息[13],同时只造成背景环境信息丢失,满足实际需求。经双边滤波后的点云数据为
(3)
式中:Pe为第e个原始点云数据;β为双边滤波因子;γe为第e个点云的法向量。
滤波前后的点云数据如图3所示。
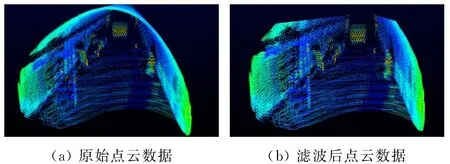
图3 点云数据滤波前后对比Fig.3 Point cloud data comparison before and after filtering
点云数据经双边滤波处理后,采用PCA (Principal Component Analysis,主成分分析) 提取其主成分,实现数据降维,以减少数据存储空间,提升目标检测速度。经PCA降维后的点云数据矩阵为
Zm×r=Rm×rWt×r
(4)
式中:m为空间中点云个数;r,t为点云数据降维前后数据维度;Rm×t为原始点云数据矩阵;Wt×r为映射矩阵。
PCA降维前后的点云数据如图4所示。可看出经PCA处理后的点云数据在实现降维的基础上,极大地保留了数据原有特征。

图4 点云数据经PCA处理前后对比Fig.4 Point cloud data comparison before and after being processed by PCA
2 融合图像与雷达点云检测模型
由于单目相机和激光雷达采集的数据格式不同,且表示形式存在差异,所以直接融合数据十分困难。对此,本文设计了一种融合图像与雷达点云检测模型,通过对RGB图像与点云数据进行特征级融合及区域级融合,实现目标3D检测。本文重点介绍模型结构及损失函数设计。
2.1 检测模型结构
对预处理的图像及点云数据做进一步处理,以获取检测模型输入数据。采用RPN提取增强图像的候选区域,得到待测目标的2D锚框[14],如图5所示。

图5 检测模型输入图像Fig.5 Input image of the detection model
对图5中图像的同一帧点云数据进行双边滤波及PCA处理,提取其2D主成分,结果如图6所示。

图6 检测模型输入点云数据Fig.6 Input point cloud data of the detection model
融合图像与雷达点云检测模型结构如图7所示。采用point-wise(点方式)排序学习方法对RPN提取特征后的图像与点云数据2D主成分进行早期特征级融合,即将点云数据2D主成分和图像做投影映射,为点云数据赋予图像上每一像素点的RGB值。映射关系为
(5)
式中:(x,y)为点云数据坐标(X,Y,Z)在像平面坐标系中对应的坐标;(x0,y0)为图像像素点坐标;F为图像的像素分布函数;as,bs,cs分别为相机在X,Y,Z轴方向的姿态角,s=1,2,3分别表示雷达坐标系、相机坐标系、世界坐标系;(X′,Y′,Z′)为(x0,y0)根据相机内参矩阵解算的实际3D坐标。
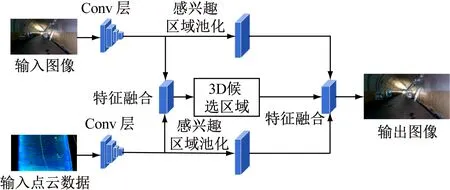
图7 融合图像与雷达点云检测模型结构Fig.7 Structure of detection model based on image and radar point cloud fusion
采用早期融合后的特征生成一系列3D候选区域,同时分别对卷积后的图像特征和点云数据特征进行感兴趣区域池化,使其维度相同,并与3D候选区域进行后期区域级融合,生成待测目标3D锚框,完成目标检测。
区域级融合流程如图8所示。图像通道采用ImageNet预训练的ResNet50作为骨干网,并提取1×1 024维度特征。点云通道采用PointNet提取点特征和全局特征,具体过程:原始点云(ω×3)(ω为点云数据个数)PointNet依次提取高维度信息(ω×64),(ω×1 024),然后采用MaxPooling(最大池化)将高维度信息(ω×1 024)压缩至(1×1 024),并将其作为全局特征。融合初期将点云维度信息(每一点维度为1×2 048)与图像维度信息做整体拼接,融合结果包含了PointNet和ResNet50的深层信息。融合后期将初期融合结果进行MaxPooling处理,所得结果与点云数据的全局特征进行融合,进一步提升全局信息质量。
2.2 损失函数
设计损失函数时需考虑待测目标锚框的各个变量。理论上,1个3D锚框有9个自由度,包括3个位置、3个旋转、3个维度自由度。对于无人驾驶无轨胶轮车,因大多数情况下与地面保持水平,所以可设置滚动和倾斜角度相对于水平面为零,且底面为水平面的一部分,由此省略3个旋转自由度,只需考虑其实际空间位置坐标及所占空间大小即可完成目标检测,因此参考YOLOv3网络的损失函数并进行改进,设计检测模型损失函数:
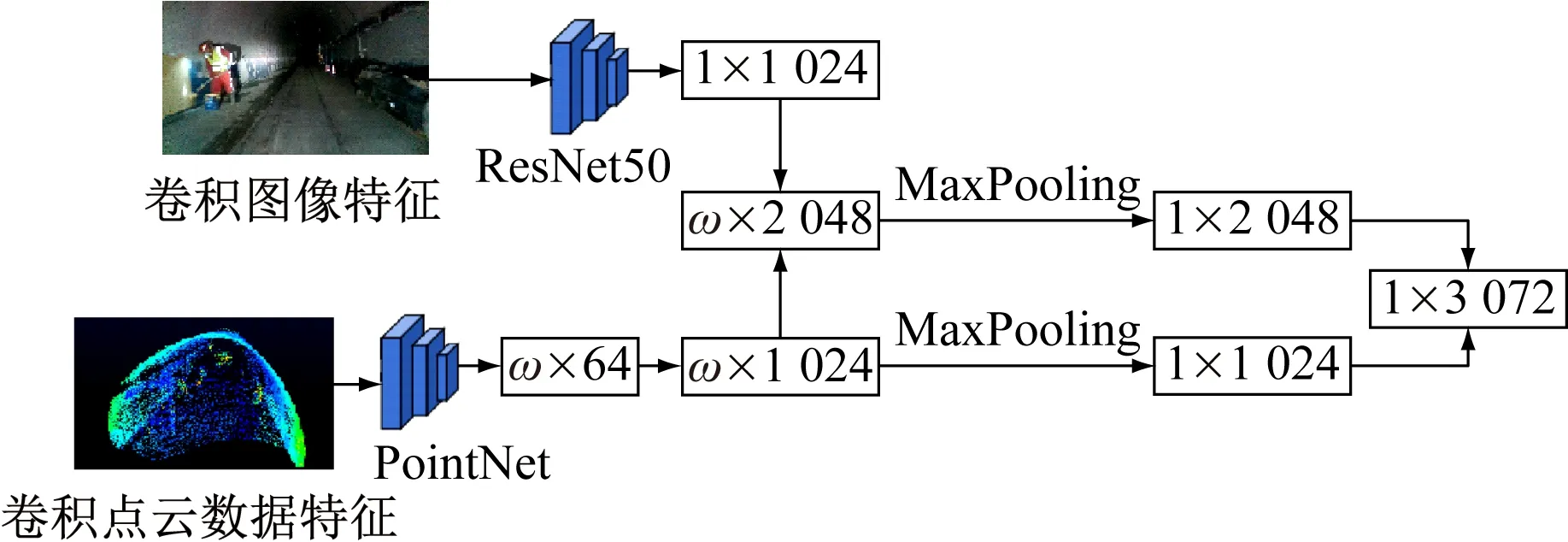
图8 区域级融合流程Fig.8 Region level fusion flow
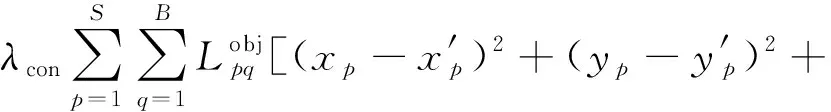
(6)
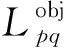
3 检测性能验证
检测模型训练和测试均基于笔者所在课题组制作的井下环境数据集,其包括图像数据、点云数据及相机-雷达标定参数。数据集中共9 176组数据,7 659组数据组成训练集,1 517组数据组成测试集。
模型训练参数见表2。初始学习率设置为10-5,以防止模型在训练初期因梯度不稳定而发生偏移。在完成50次训练后将学习率调整至10-4,以加快学习进程。完成80次训练后将学习率调整为5×10-5直至训练结束。训练图像数据前,参考SSD[15]的随机亮度抖动对数据进行随机增强。针对煤矿井下应用环境,将图像随机变换概率设为0.7,亮度变换范围为(-48,48)。

表2 模型训练参数Table 2 Model training parameters
实验硬件平台为RTX3090及AMD 3950X,开发环境为Pytorch1.7,在Ubuntu18.04下运行。设计消融实验,对比输入不同数据情况下检测模型的性能,评价指标采用不同IoU(Intersection-over-Union,交并比)下检测模型的AP(Average Precision,平均精度)及mAP(Mean Average Precision,平均精度均值),结果见表3。可看出采用本文方法对采集的环境图像及雷达点云进行处理后,检测模型的AP和mAP均得到明显提升,表明本文数据处理方法能够提高3D锚框的定位性能。
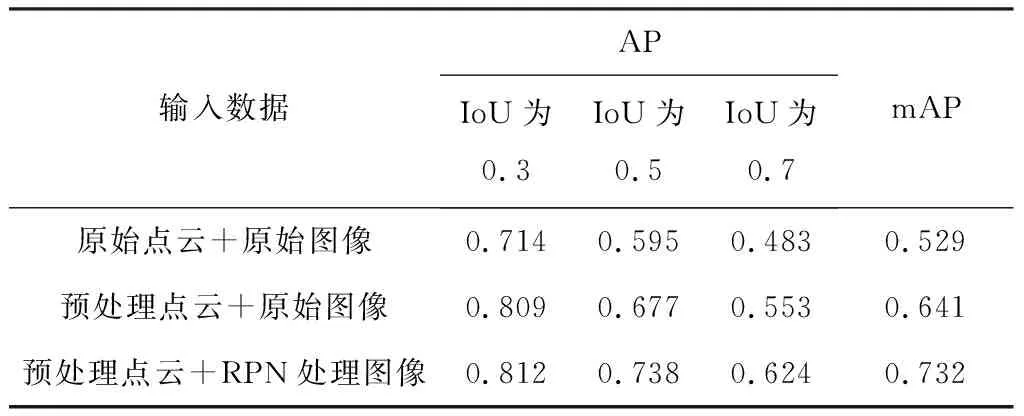
表3 消融实验结果Table 3 Melting experiment results
基于本文数据集,在不同IoU下分别测试YOLO3D,MV3D(Multi-View 3D)和本文检测模型的性能,结果见表4。可看出IoU不超过0.5时,MV3D模型的AP最大;IoU为0.7时,检测任务对目标位置有更精确要求,此时本文模型的AP最大;本文模型的mAP较YOLO3D提高0.106,较MV3D模型低0.019,但检测速度较MV3D模型提升了84.6%,达24 帧/s,实现了检测精度和速度的良好平衡。
3种检测模型的实时检测精度对比如图9所示。针对煤矿无轨胶轮车低速行驶特点,检测速度在15~30帧/s即可满足目标检测要求。从图9可看出,本文模型在15~30帧/s检测速度下的AP整体上优于其他2种模型,可更好地实现井下目标3D检测。
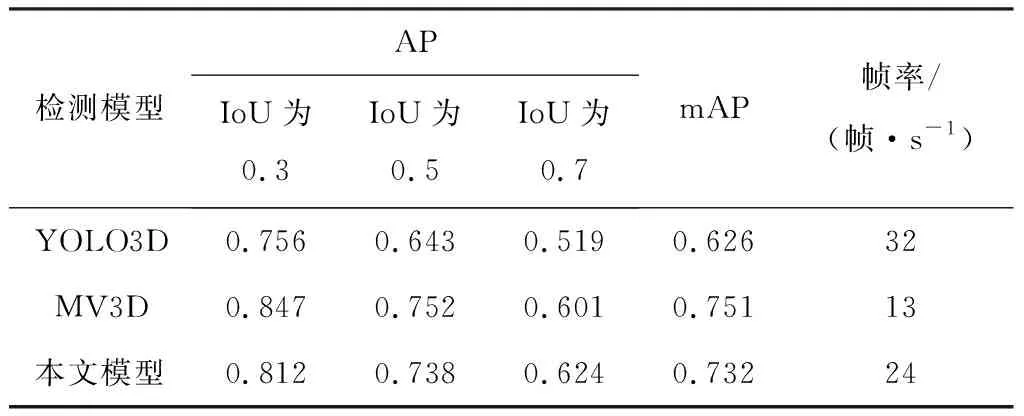
表4 不同检测模型性能对比Table 4 Performance comparison among different detection models
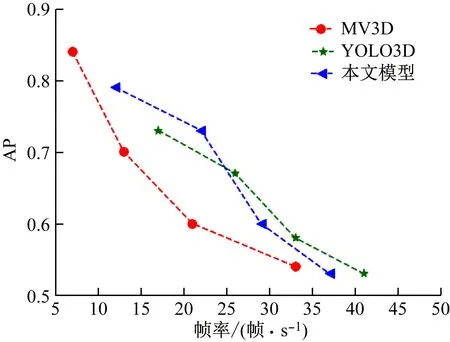
图9 不同检测模型实时检测精度对比Fig.9 Comparison of real-time detection precision among different detection models
在陕西陕煤曹家滩矿业有限公司副井大巷对本文模型进行测试,部分检测效果如图10所示。可看出本文方法对于井下车辆或行人均能准确检测出3D位置信息,且未出现漏检现象,表明该方法能较好地适应井下环境。






图10 井下检测效果Fig.10 Underground detection results
4 结论
(1) 对煤矿井下无人驾驶无轨胶轮车行驶环境中获取的RGB图像和点云数据进行预处理:通过全局直方图均衡化提升图像亮度,降低井下光照不均影响;通过双边滤波去噪及PCA降维,提升点云数据质量,减少运算时间。
(2) 提出一种融合图像与雷达点云检测模型,引入RPN生成2D图像候选区域,对其与点云数据进行早期特征级融合生成3D候选区域,在3D候选区域基础上进行后期区域级融合,输出3D锚框,实现目标检测。
(3) 通过消融实验及与YOLO3D,MV3D模型的对比实验,验证了提出的融合图像与雷达点云检测模型的目标检测精度较高,且较好地实现了精度与检测速度的平衡。测试结果表明该模型能够准确检测无轨胶轮车行驶环境中的目标,具有良好的井下适应性。
