深度学习框架下混合协同过滤算法研究
2022-03-04古险峰白林锋
古险峰, 白林锋
(河南科技学院 信息工程学院,河南 新乡 453003)
随着互联网技术的飞速发展以及大数据、云计算的兴起,大量的数据在给人们日常生活带来便捷的同时,也带来了信息超载、维数灾难的问题.如何在有限的时间内精准的找到符合自己期望的数据,提高信息的使用率,个性化推荐系统应运而生[1].已有的推荐系统难以适应复杂的场景,单纯依靠用户浏览的历史数据和特征分析,忽略了项目属性信息和项目间的关联性,使得在面对新用户、新项目时存在冷启动、数据稀疏性和推荐精度不高的问题[2].基于深度学习的混合协同过滤,利用深度神经网络模型对已知数据进行特征提取解决用户信息不对称带来的数据稀疏问题,混合协同过滤则将评分矩阵与项目属性信息融合应用得到项目间的映射关系并进行聚类分析,解决面对新系统未知信息时数据库中相关信息不足,推荐精度不高的问题,从而提高推荐精度提升用户的黏连度,优化推荐系统固有的问题[3].
1 理论研究相关知识
1.1 推荐系统
在海量数据背景下如何有效的挖掘用户的潜在信息,进而在推销商品的同时提升客户的黏连度,是推荐系统的主要目的[4].推荐系统作为信息过滤的一种是人工智能的具体应用,通过对已知行为数据进行分析构建模型,继而对新系统、新项目和新用户进行预测[5].其数学表示为:如果存在用户集I,项目集U,评价函数S代表把u推荐给i的准确率,推荐系统即为找到准确率最大的推荐物品r,使s取得极大值,∀i∈I,r=arg max(s(i,u)),u∈U.已知的推荐算法根据评价对象不同可以分为三种,分别为基于协同过滤、基于内容和混合推荐等.评价对象为项目内容的推荐算法依据用户兴趣和项目本身的内容进行推荐,不需要依赖其他数据,精度较高,但特征提取比较困难,在面对新项目、新用户时存在冷启动问题;根据项目和用户的交互信息进行推荐的协同过滤推荐算法有模型和邻域之分,其中基于近邻的又可以分为根据当前用户兴趣相似度推知未知用户兴趣的评分,即用户型和利用已知用户的浏览历史和项目属性的关联规则,生成推荐表格的项目型.为了取长补短更好的实现个性化推荐,通过对多种推荐算法进行融合生成混合推荐系统,提升推荐准确性,可以分为特征层、模型层和决策层融合[6].推荐系统主要算法如图1所示.
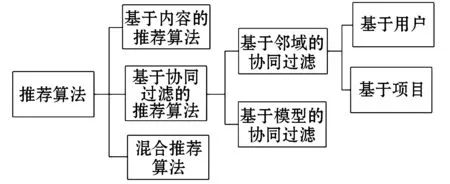
图1 推荐系统主要算法Figure 1 Main algorithm of recommendation system
1.2 深度神经网络
协同过滤算法针对评分矩阵在面对新用户、新项目和新系统时,由于没有大量的已知数据进行样本训练,进而导致特征提取比较困难,出现推荐精度不高的现象即冷启动问题的出现[7].深度卷积神经网络卷积层和池化层具有局部连接、权值共享和特征自适应的优点,可以利用给定的样本模型进行反复训练,从而得到鲁棒性强的数据参数,进而在面对复杂的、动态的输入输出关系时进行关联建模,得到接近真实值的预测结果,从而解决冷启动问题;同时,针对用户浏览历史有限、信息不对称和关联性不高出现的数据稀疏性问题,卷积神经网络利用卷积核具有参数同一层共享,池化层不产生新的模型参数的特点,使得模型复杂的大大降低、识别精度得到了提高,优化了计算能力,提升了评分预测精度解决了数据稀疏性问题[8].
1.3 基于深度学习的混合推荐
传统的协同过滤系统依赖已知用户的评价矩阵,忽略了项目属性和用户兴趣间的关联性,仅仅通过用户的评分准则对新用户进行推荐,在面对稀疏数据时无法精确的实现个性化推荐;而基于内容的推荐算法在面对新用户和新内容时,可以基于已知内容进行推荐冷启动问题不明显,但是在进行特征提取时,需要人工进行,进而无法面对种类繁多的大量数据,应用场景有限[9].基于深度学习的混合推荐模型,利用深度卷积神经网络从已知辅助信息中提取数据的特征值,同时将项目属性和用户兴趣间的融合,并利用神经网络协同过滤进行相似度计算,进而弥补相关信息不足带来的冷启动问题以及用户评价有限造成的数据稀疏和可扩展性有限的问题,从而提高推荐的准确性[10].基于深度学习的混合推荐系统架构如图2所示.

图2 基于深度学习的混合推荐系统架构Figure 2 Hybrid recommendation system architecture based on deep learning
2 混合协同过滤
2.1 协同过滤算法
协同过滤认为不同用户间存在相似性即“物以类聚、人以群分”属性,通过分析已知用户的隐式或显式数据,根据关联特征进而得到不同用户间的兴趣点,进行个性化推荐[11].利用已知用户的浏览数据进行评分是基于用户的协同过滤算法的主要特征,根据关联特征找到相似用户,并把已知用户的兴趣点推荐给未知用户[12],具体步骤为:首先根据已知数据创建用户和项目间的评分矩阵,即对兴趣点打分并对缺失值进行填充处理;根据用户和项目间的评分矩阵计算相似度,得到最相似的目标人群,相似度计算可以通过余弦相似度得到:
(1)
其中:两个用户分别用i和j表示,对不同n个项目的评分用n维向量I和J表示.余弦相似度取值为[0,1],越接近1说明两个用户间的相似度越高[13].虽然余弦相似度可以得到目标用户与已知用户的相似度,但却没有考虑评分均值对矩阵的影响,对于数值不敏感,导致精确度不高[14].基于此在余弦相似度的基础上提出了修正余弦相似度的概念即皮尔逊系数,利用评分数值具体的不同,通过计算协方差和标准差的比值,将数据做中心化处理,进而得到较为精确的相似度计算:
(2)

(3)
2.2 基于用户聚类研究
为了缓解传统协同过滤算法对冷启动、数据稀疏性以及可扩展性等问题的不足,提高个性化系统推荐的准确度,利用聚类分析的优势将协同过滤算法和聚类分析相融合,根据皮尔逊系数得到相同爱好的目标客户,使其聚集为一个簇,进而对簇进行处理,而不需要对每一个相似目标用户进行分析,进而大大减少计算复杂度以及系统运行时间,解决在面对新系统时出现的可扩展性不足以及数据稀疏性问题[15].其数学表示为:假设存在n个目标相似用户{x1,x2,…,xn},相似度表示为{Dx1,Dx2,…,Dxn},选取类间距离大的点作为阈值点进行分类,当聚集簇满足数量要求时,开始进行聚类研究,得到聚类结果即用户群,同时为了避免K均值带来的聚类偏差和时间损失,需要对聚类进行最优化处理,具体方法为:
(4)
其中:相似用户i和j聚类的距离用dij表示,C为聚类的簇,r表示簇第r类.Dr表示第r类中任意相似用户的距离之和.对Dr进行标准化处理:
(5)
为了得到精确的簇组,使样本的损失最小,充分考虑评分均值对矩阵的影响,需要对数据集进行进一步处理:
(6)

3 基于用户的卷积协同推荐算法
3.1 评价指标
为了验证系统性能的优劣,需要不同的评测指标在具有代表性的数据集上对不同算法进行比较,进而得出系统设计模型的准确性.本文设计算法通过使用绝对值预测误差MAE以及均方根误差RMSE来验证模型性能;
(7)
(8)

3.2 深度学习下基于卷积的协同推荐模型
传统的推荐系统仅仅利用用户和项目间的评分情况即相似度矩阵进行推荐,忽略了项目的属性信息且没有充分利用用户兴趣点,对于大量非线性数据很难进行追踪和表达.深度学习独特的延展性和网络结构以及强大的学习能力,针对数据的潜在特征可以利用激活函数进行非线性建模,准确的反映用户的兴趣点,提高模型可解释性的同时避免人工特征提取在应对大数据时的弊端,同时对混合协同过滤不同的数据特征可以分别提取,提高模型的准确率和效率.本文提出深度学习框架下基于用户的混合协同过滤算法,将评分矩阵与项目属性信息融合利用用户聚类进行分析,拟合出最佳分类,提高个性化推荐精度.
具体算法流程为:
1)根据已知用户兴趣点以及项目属性,对数据进行分类处理,得到用户特征矩阵;
2)对用户特征矩阵进行预处理,并进行全连接聚类分析;
3)将用户特征矩阵输入卷积神经网络,利用卷积神经网络独特的延展性和网络结构以及强大的学习能力,对样本进行训练并得出预测矩阵;
4)根据预测矩阵以及相似度,对评分进行排序生成推荐列表.
3.3 实验与仿真
为了验证本文算法的准确性和有效性,需要利用评测指标在具有代表性的数据集上对不同算法进行比较.本文通过均方根误差RMSE来验证模型性能,系统硬件参数为Core i7处理器,16G内存、Nvidia GPU、1T固态硬盘、显存为11.00GB GDDR5X,软件环境为Ubuntu 18.04操作系统、python3.5编程环境、基于深度学习框架采用TensorFlow模型,同时为了验证算法的普遍适用性,数据集采用三个不同的规模和稀疏性.推荐准确度如表1所示.
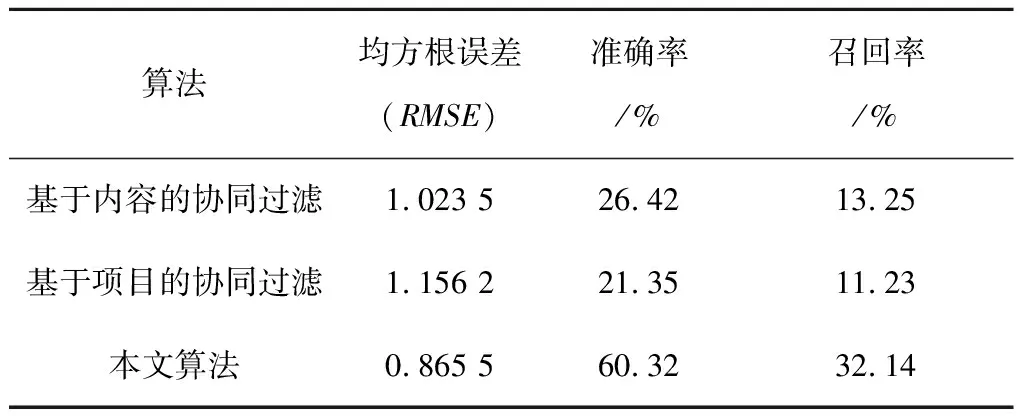
表1 不同算法推荐准确度
通过表1可知,深度学习框架下基于用户的混合协同过滤算法,均方根误差(RMSE)明显优于传统协同过滤算法,在召回率和准确率上也具有一定的优势.同时,为了验证算法的普遍适用性在不同数据量上均方根误差(RMSE)进行对比,结果如图3所示.
通过图3可以看出,随着训练样本数据量的不断上升,不同算法的均方根误差(RMSE)在不断减小,直到趋于稳定,且本文算法优于其他算法,推荐准确性上具有一定优势.

图3 不同算法在不同数据量上均方根误差Figure 3 The root mean square error of different algorithms on different amounts of data
4 结 语
本文通过对推荐系统相关理论知识进行研究,分析了传统协同滤波算法的优缺点,在面对新用户、新数据以及新系统时没有大量的已知数据进行样本训练,进而导致特征提取比较困难,出现推荐精度不高、数据稀疏性和可扩展性不足的问题,针对这一情况提出将评分矩阵与项目属性信息融合利用用户聚类进行分析,拟合出最佳分类.同时,利用深度学习独特的延展性和网络结构以及强大的学习能力,建立模型提高个性化推荐精度.经过实验可知本文算法相较于传统算法具有一定的精度和普遍适应性.
