基于MapReduce的支持向量机参数选择研究
2022-03-04刘黎志
刘黎志,杨 敏
智能机器人湖北省重点实验室(武汉工程大学),湖北 武汉430205
支持向量机(support vector machine,SVM)分类模型的建立需要经过大量的计算,随着训练样本集规模的增长,不仅会大量消耗主机的CPU及内存资源,而且训练模型所需要时间也会急剧增加,从而使得在单机环境下得到模型变得十分困难,因此如何针对大规模数据集,使用并行化方式获得最优支持向量机分类模型,一直是研究的热点问题[1-3]。基于Hadoop平台的分布式计算框架MapReduce及Spark为并行化训练大规模数据集提供了新的方法和手段[4-7],在分布式计算框架的支持下,SVM分类模型的训练过程可以并行化,从而显著缩短了得到模型所需要的时间[8-10],层叠化SVM就是基于MapReduce框架并行获取支持向量的典型应用[11-12]。为了让SVM分类模型能够更鲁棒地用于实际数据的预测及解决线性不可分问题,在模型的训练过程中,需要对模型的参数进行选择,从而得到最优的模型[13-14]。相关研究运用MapReduce框架建立分布式参数寻优模型,完成了模型训练、预测和参数选择优化。吴云蔚等[15]针对使用网格搜索对SVM参数进行全局寻优时存在的寻优时间长的问题,提出了一种基于Hadoop分布式文件系统(hadoop distributed file system,HDFS)平台的分布式参数寻优方法,提高了寻优效率。白玉辛[16]基于Flink并行网格搜索算法对SVM参数进行寻优,将全局参数对文件切分成若干小块交给各个计算节点并行寻优,最后汇总寻优结果,减少了寻优时间。李坤等[17]基于Spark集群实现了libsvm参数优选的并行化,提出了并行粗粒度网格搜索参数优选算法,相比传统算法运行速度提升了近7倍,且随着集群规模的扩大而进一步加大。
但当前的这些研究都缺少在训练过程对集群内存资源消耗情况的论述。因此本文提出一种在MapReduce框架下进行最优模型参数选择的新算法,该算法能够在合理利用集群内存资源及保证进行交叉验证的Reduce任务充分并行执行的前提下,显著减少最优模型参数的获取时间。
1 SVM分类最优模型参数选择
对于给定的训练数据集:D={(xi,yi)|xi∈Rn,yi∈(-1,1)}mi=1,求解SVM最优超平面的对偶问题描述为:

其中m为支持向量的个数,ɑi为支持向量对应的拉格朗日算子。
c为惩罚参数,控制SVM模型如何处理错误,对于线性可分问题,合适的c值可以使得超平面间距最大,同时出现的分类错误最少。没有一个特定的c值可以解决所有的线性可分问题,对于具体的问题,最优的c值只能通过实验的方法得到。
对于线性不可分问题,可以通过核函数将数据映射到多维空间,使其线性可分。核函数K的返回值是数据点在转换为多维空间向量后的内积值,核函数K的形式化定义为:给定一个映射函数φ:x→ν,函数K:x→R,定义为:

其中,<φ(x),φ(x')>ν表示x,x'在转换为φ(x),φ(x')后在ν中的内积。核函数的类型有线性核函数、多项式核函数、高斯核函数等。实践证明,使用高斯核函数对线性不可分问题进行分类,一般可以取得较好的效果,故在选择核函数时,高斯核函数一般是首选。高斯核函数的描述为:

γ和c值一样需要通过实验得到其最优值,取得最优值的实验为采用交叉验证的网格搜索方法(grid search)。对于第i组给定的(ci,γi),交叉验证的过程为将训练集划分为大小相同的n个等份,依次取其中的第j份为测试集Tj,j=(1,2,…,n),剩下的n-1份为训练集,使用根据训练集得到的分类模型预测Pj,得到预测准确率Aj,整个交叉验证的准确率Ai为:

上述的过程称为n重交叉验证(n-fold cross validation)。n重交叉验证使得整个训练集中的数据均被预测,其准确率为整个训练集中的数据被正确分类的百分比,故n重交叉验证能有效的避免模型的过拟合问题。最优模型参数的选择就是在集合p={(ci,γi)|ci,γi∈R}mi=1中,使用交叉验证得到每组参数的Ai,取准确率最高的参数(ci,γi)为最优模型参数。使用网格搜索得到最优模型是个非常耗时的过程,假设参数集合p的参数组数为m,每组参数进行n重交叉验证,每一次交叉验证的平均时间为w,若为串行执行,网格搜索的总时间t为:

由此可见网格搜索的时间随着参数组数m及交叉验证的重数n而线性增长。在网格搜索的过程中,由于对某组参数进行交叉验证的过程与其它参数组无关,故多组参数的交叉验证过程可以并行执行,从而缩短网格搜索得到最优模型所需要的时间。
2 分布式集群环境下的最优模型参数选择
2.1 最优模型参数的选择过程
在分布式集群环境下,MapReduce框架负责处理并行计算中的分布式存储、工作调度、负载均衡、容错均衡、容错处理以及网络通信等复杂问题。MapReduce框架采用“分而治之”的策略,其核心步骤主要分两部分:Map和Reduce。在向MapReduce框架提交一个计算作业后,MapReduce会首先把作业拆分成若干个Map任务,然后这些Map任务被分配到不同的机器上执行,这些Map任务完成后会产生一些键值对构成的中间文件,它们将会作为Reduce任务的输入数据。Reduce任务的主要目标就是把前面若干个Map的输出进行处理并给出结果。MapReduce框架的作业配置非常灵活,可以指定只单独运行Map或者Reduce任务;指定完成具体任务的Reduce的个数;通过key值指定Map任务与Reduce任务的对应关系等。本文提出的最优模型参数选择方法首先在Map任务中读取存储在HDFS文件系统中的参数文件,然后在Reduce任务中进行模型的训练及交叉验证,得到模型的准确率。基于MapReduce的SVM最优分类模型参数选择的过程如图1所示。
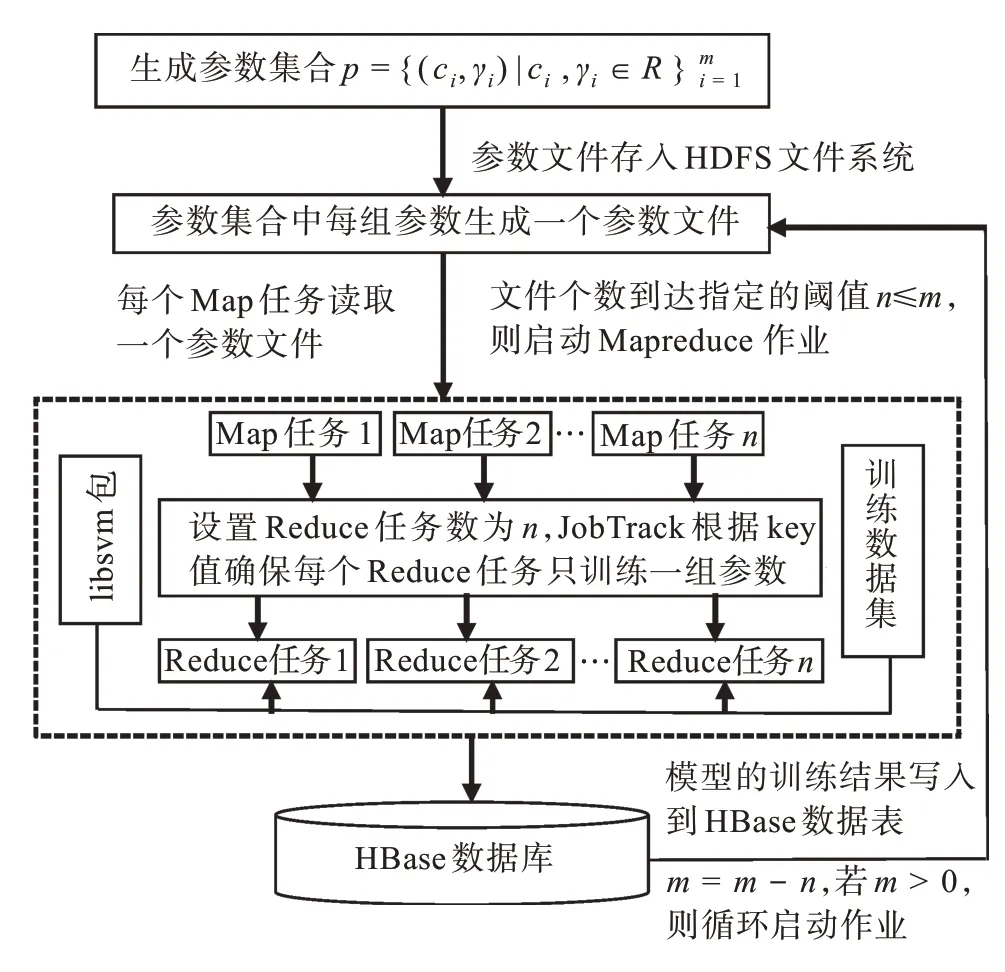
图1 基于MapReduce的最优模型参数选择过程Fig.1 Optimal model parameter selection processbased on MapReduce
分布式集群环境下的最优模型选择的核心思想就是让多组参数可以同时训练,以缩短得到最优模型参数的时间。将需要训练的参数集合参数p={(c i,γi)|c i,γi∈R}m i=1中的每组参数(c i,γi)以一个文件的方式写入到HDFS文件系统,当文件的个数达到指定的阈值n(n≤m)时,启动MapReduce作业,通过重载Map任务读取文件的模式,使得每个Map任务读取输入参数文件的所有内容,在确保key唯一后,将<key,参数>写入到中间结果。由于每组参数的key值不同,且Reduce的个数设置为n,所以JobTrack可以保证每个Reduce任务只训练一组参数。每个Reduce任务读取缓存在集群内存中的训练数据集文件及调用缓存在集群中的libsvm包中的方法训练模型并进行交叉验证,模型训练的结果写入HBase数据库,以便对训练过程进行统计分析。
2.2 最优模型选择算法设计
由于每组参数的交叉验证过程要在Reduce任务中完成,增加Reduce的任务并发数显然可以加快获得最优模型参数的速度。但是,当并发执行的Reduce任务个数到达一定阈值后,集群的内存资源将被全部占用,从而导致其它的MapReduce作业由于缺少内存资源而无法执行。因此,必须限制并发执行的Reduce的任务个数。一种限制Reduce任务个数的方式为:将需要选择的m个参数划分为n个MapReduce作业(J1,J2,…,Jn-1,Jn),n≥1,其中(J1,J2,…,Jn-1)执行mn个参数的验证,Jn执行m%n个参数的验证,(J1,J2,…,Jn-1)在JobTrack的控制下串行执行,执行过程如图2所示。
图2(a)中的每个Ji中并行执行m n个或者m%n个Reduce任务,矩形条表示每个Reduce任务的完成时间。对于第i个作业Ji,执行交叉验证耗时最长的Reduce任务完成时间为Ri,由于Ji为串行执行方式,所以使用该方式进行最优参数选择的总时间G为:

另一种方式为单个MapReduce作业方式,即只启动MapReduce作业一次,让m个Reduce任务全部处于就绪状态,但限制能获得资源并行执行的Reduce的任务个数为k,k≤m。当某个Reduce任务执行完成后,处于就绪等待队列中的某个Reduce任务获得资源开始执行,直到就绪队列中的所有Reduce任务执行完成。单个MapReduce作业方式的执行过程如图2(b)所示。
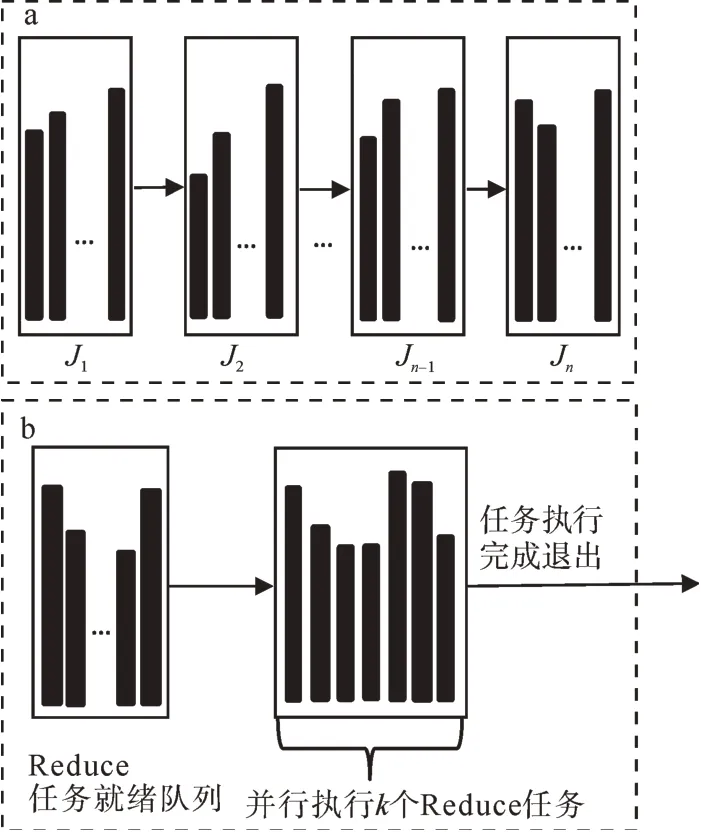
图2 (a)串行MapReduce作业方式;(b)单个MapReduce作业方式Fig.2(a)Serial MapReduce job mode;(b)Single MapReduce job mode
单个MapReduce作业方式只在执行最后一批k个Reduce任务时,需要等待耗时其中最长的任务执行完成,其它情况下,耗时长的任务将和其它任务一起并行执行。
通过比较两种MapReduce作业方式可以发现,串行MapReduce作业方式调度简单,不需要维护额外的Reduce任务就绪队列或者等待任务执行,但当作业中存在耗时的Reduce任务时,会显著增加整个作业的完成时间,因此串行MapReduce作业方式适合并行执行的各个Reduce任务的完成时间差距不大的细粒度最优参数搜索。单个MapReduce作业方式只向集群提交一次作业,如果运行失败,整个参数选择的过程必须重做。但当作业中包括耗时的Reduce任务时,该作业方式可以使得耗时的任务和其它任务同时执行,从而加快最优参数的获取速度,因此单个MapReduce作业方式适合Reduce任务的完成时间差距较大的粗粒度最优参数搜索。
SVM最优模型参数选择的算法流程如图3所示,其中reduceNums参数用于控制作业中并发执行的Reduce任务的个数,reduceNumsAllowed参数用于控制集群中允许执行的Reduce任务的个数。当reduceNums<=cnum*gnum,reduceNums-Allowed<=reduceNums时为串行MapReduce作业方式。当reduceNums<=cnum*gnum,reduceNums-Allowed<=reduceNums时为单个MapReduce作业方式。

图3 SVM最优模型参数选择算法流程图Fig.3 Flow chart of SVM optimal model parameter selection algorithm
MapReduce作业中的Map任务读取存储在HDFS文件系统中的参数文件,并以<key,value>的形式写成,交给Reduce处理,其算法描述如图4和图5所示,其中paramFile表示当前参数文件,context表示MapReduce作业上下文。

图4 MapReduce作业中的Map任务流程图Fig.4 Flow chart of Map task in MapReducejob

图5 MapReduce作业中的Reduce任务流程图Fig.5 Flow chart of Reduce task in MapReduce job
存储在HDFS文件系统中的参数文件经过Map任务处理后,由于各自的key值不同,所以MapReduce框架的JobTrack把每组参数交给一个Reduce任务来处理,从而使得模型的选择过程并行化,在Reduce任务的算法描述中,paramStr表示参数字符串,context表示MapReduce作业上下文。
Reduce任务中的交叉验证过程直接调用libsvm包中的方法完成,训练数据集中的输入特征需要按libsvm规定的稀疏矩阵格式进行压缩,输入特征值一般需要进行归一化处理,避免特征值之间的数量级差距过大对训练算法的影响。在每组参数对应的Reduce任务完成后,将其交叉验证的结果写入HBase表,以便对数据进行统计分析,得到最优模型的参数及其它性能指标。HBase的表结构如图6所示。

图6 实验结果存储HBase表结构Fig.6 Structure of HBase table of storing experiment results
3 实验部分
实验用服务器为DELL PowerEdge R720,其配置为2个物理CPU(Intel Xeon E5-2620 V2 2.10 GHz,每个CPU含6个内核,共12个内核),32 GB内存,8 TB硬盘,4个物理网卡。服务器安装VMWare esxi6.0.0操作系统,虚拟化整个服务器环境。客户端使用VMWare VSphere client 6.0.0将服务器划分为4个虚拟机,每个虚拟机的配置为3内核CPU,8 GB内存,2 TB硬盘,1个物理网卡。每个虚拟机安装ubuntu-16.04.1-server-amd64操作系统,Hadoop 2.7.3分布式计算平台,组成含1个主节点,4个数据节点(主节点也是数据节点)的集群。实验选用https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/中的a8a二分类训练数据集,a8a共包含22 696条数据,大小在1.6 MB左右。
进行粗粒度参数选择,比较在Reduce任务完成时间差距较大时,串行MapReduce作业方式和单个MapReduce作业方式在最优模型参数选择时的时间性能和集群内存消耗上的差别。设置参数nrFold=4,cnum=8,c初始值为0,递增步长为1,搜索范围为0~7。参数gnum=8,γ的初始值为0,递增步长为10-1,搜索范围为0~10-7。ci和γi的笛卡尔积为64,在这64组参数中进行粗粒度搜索。设置reduceNums/reduceNumsAllowed参数分别为4/4,8/8,16/16,32/32,64/64,即reduceNums<=cnum*gnum,reduceNums=reduceNumsAllowed,进行串行MapReduce作业方式实验,得到的实验数据如表1所示。
表1中的Reduce任务的最快、最慢及平均完成时间,均通过查询统计BMSResult表得到,具体过程在此不详细描述。分析表1可以发现,1)集群内存资源的消耗随着并行执行的Reduce的任务个数的增加而增加,当Reduce的任务数量达到32个时,内存被100%全部占用,无法得到内存资源的Reduce任务只能等待正在执行的任务完成后,再由JobTrack调度执行。2)Reduce任务的平均完成时间,随着并行执行的任务数的增加而增加,说明当集群并发任务数多时,CPU的调度和内存资源的分配紧张,Reduce完成任务的时间增加。3)获取最优参数的总训练时间,随着并行执行的Reduce的任务的个数的增加,MapReduce作业启动的次数的减少而下降,说明虽然任务并发个数多时,完成每个Reduce任务的平均时间虽然增加,但由于Reduce任务的并发度增加,获得最优参数的总时间相反会下降。
设置reduceNums/reduceNumsAllowed参数分别为64/4,64/8,64/16,即reduceNums=cnum*gnum,reduceNumsAllowed<reduceNums,进 行 单 个MapReduce作业方式实验,得到的实验数据如表2所示。
比较表1中的实验1-实验3及表2中的实验1-实验3,可发现在内存消耗相等时,粗粒度参数选择单个MapReduce作业方式获取最优参数的总时间均优于串行MapReduce作业方式。比较表2中的实验3和表1中的实验3,在内存消耗相等时,获取最优模型的时间性能提高(4 559-3 506)/3 506≈30%;比较表2中的实验3和表1中的实验4-实验5,可以发现单个MapReduce作业方式在仅消耗集群56%的内存时,获取最优参数的时间与串行MapReduce作业方式消耗100%内存时相近;比较表2中的实验3和表1中的实验1,可以发现通过合理的选择获取最优参数的方式及设置reduceNums/reduceNumsAllowed参数,在保证集群内存的合理消耗下,获取最优参数的时间性能提高了(9 599-3 506)/3 506≈174%。

表1 粗粒度参数选择串行MapReduce作业方式实验数据表Tab.1 Experimental results of serial MapReduce job mode for coarse-grained parameter selection

表2 粗粒度参数选择单个MapReduce作业方式实验数据表Tab.2 Experimental results of single MapReduce job mode for coarse-grained parameter selection
其次,进行细粒度粒度参数选择,比较在Reduce任务完成时间差距不大时,串行MapReduce作业方式和单个MapReduce作业方式在最优模型参数选择时的时间性能和集群内存消耗上的差别。设置参数nrFold=4,cnum=8,c初始值为0.5,递增步长为0.25,搜索范围为0.5~2.25。参数gnum=8,γ的初始值为0.05,递增步长为0.012 5,搜索范围为0.05~0.137 5。设置reduceNums/reduce-NumsAllowed参数分别为4/4,8/8,16/16,64/4,64/8,64/16,得到的实验结果如表3所示。
比较表3中的实验1-实验3和实验4-实验6,可以发现在进行细粒度参数选择时,当Reduce任务的完成时间差距不大时,在同等内存消耗的情况下,两种MapReduce作业方式在获取最优模型参数的时间性能上差距不大。

表3 细粒度参数选择串行/单个MapReduce作业方式对比实验数据表Tab.3 Comparison of experimental results between serial and single MapReduce job mode for fine-grained parameter selection
4 结 论
SVM分类模型最优参数的选择是一个非常耗时的过程,本文提出的基于MapReduce框架的最优分类模型参数选择的算法,能够在分布式集群环境下,让模型参数的交叉验证过程并行执行,并通过选择不同的MapReduce作业方式,配置集群中的并发任务数,可以在合理的集群内存消耗的情况下,显著缩短获取最优参数的时间。后续的研究方向设想为:(1)对于大规模的训练数据集,可否首先按并行层叠的方式获取支持向量集合,然后仅根据获取到的支持向量集合进行最优模型参数选择,从而减少进行交叉验证的数据规模,提高获取最优参数的速度。(2)研究在Spark分布式计算框架进行SVM最优模型参数的选择的具体方式。
