基于混合遗传算法-支持向量机的中小型企业信用评估模型
2022-03-04张雷
张雷
(重庆交通大学 经济与管理学院,重庆 400074)
近年来,随着国家政策的大力扶持,中小型企业迎来了蓬勃的发展,在国民经济中的支撑作用越来越大,在创新成果产出、解决劳动力就业等方面做出了巨大贡献.然而,目前中小型企业融资、贷款难的问题尤为突出,面临严峻复杂的风险挑战.所以,探索中小型企业的发展现状,筛选合理评估指标,建立一套科学有效的信用评估体系,对于中小型企业的融资、风险管理以及金融服务监管有着重要的意义.
在信用评估问题和风险预测需求日益剧增的背景下,越来越多的机器学习和大数据分析挖掘方法被应用于信用评估及风险预测中,文献[1]基于支持向量机建立了一套个人信用评估模型,引入了遗传算法进行参数优化,有效地解决了P2P网贷平台中的个人信用评估问题;文献[2]提出了一种改进的IGWO算法,构建了IGWO-LSSVM的信用评估模型,相较于K近邻、朴素贝叶斯、决策树以及SVM等方法的信用评估,效果有着明显的改善;文献[3]以科技型中小企业的信用风险评估为研究对象,运用带有非凸惩罚函数的SVM模型构建了SCAD-SVM信用风险评估体系,取得了不错的评估精度;文献[4]根据我国中小型企业的经营特点和信用风险特征,分别构建了适用于中小型企业贷款信用风险评估的概率评估模型和违约损失率评估模型.
本文为了提升对中小型企业信用风险评估精度以及评估效率,基于SVM构建了一套中小型企业信用评估模型,提出了一种改进遗传算法对SVM进行参数优化.主要贡献有3个方面:
1)在算法初期引入了网格搜索算子对遗传算法的搜索空间范围进行了优化,提升了算法的迭代效率;
2)在选择策略中引入了Metropolis接受准则,与精英保留策略相结合,构造了退火选择算子,提升了算法的局部搜索能力;
3)根据Sigmoid函数和粒子飞行迭代公式构建了多模式交叉变异算子,平衡了算法前期的全局搜索能力和后期的局部搜索能力;仿真实验验证了HGA-SVM信用评估模型在评估准确性、评估效率等方面的优越性,在测试集中HGA-SVM模型取得了91.75%的评估准确率,与其他算法相比有更优越的性能.
1 支持向量机
基于统计学习理论的SVM已被广泛地应用于图像处理、模式识别、回归分析等领域[5].作为一种机器学习方法,支持向量机能在极其有限的信息条件下学习到最优的预测结果,较好地解决了非线性、过学习、高纬度等分类问题,为解决小样本学习提供了统一的框架.
随着人工智能算法的兴起,许多学者将多种元启发式算法应用于支持向量机的参数优化问题,取得了不错的效果,但是在这些优化方法中也存在着许多不足.文献[6]将遗传算法应用于SVM参数优化问题,但是收敛速度较慢且求解结果不稳定;文献[7]使用粒子群算法对SVM的参数进行优化,克服了遗传算法求解速度慢的缺陷,但是算法在迭代后期难以保证种群的多样性,易陷入局部最优;文献[8]使用人工鱼群算法对SVM参数进行优化,在选取较大拥挤度因子的前提下可以克服PSO算法易陷入局部最优的缺陷,但是较大的拥挤度因子导致了最优解精准度不够且影响了算法收敛速度.文献[9-10]在上述算法的基础上进行了改进,在求解精准度和收敛速度方面取得了一定的效果,但是仍然存在着收敛速度慢、易陷入局部最优、求解精准度不够等缺陷,限制了支持向量机的参数优化进而影响了其分类性能.
2 混合遗传算法
遗传算法(GA)是一种模拟自然进化过程的全局优化方法,具有较强的全局搜索能力.由于标准遗传算法在参数优化时存在收敛较慢、易陷入局部最优等缺陷,目前已有多种改进遗传算法,如遗传退火算法、自适应遗传算法等,但仍存在着部分缺陷.本文从提升算法运算效率、最优解精度以及算法稳定性3个角度结合模拟退火算法、粒子群算法等智能算法对遗传算法进行了改进.
2.1 搜索空间的优化
为了保证在最优解存在的前提下尽可能地缩小搜索空间以提升算法的搜索效率,本文使用网格搜索法对遗传算法的搜索空间范围进行优化,减少了遗传算法不必要的迭代计算.在遗传算法初代种群生成前,首先通过较大步长的网格搜索法粗寻最优值范围,确定一个相对较小的搜索空间,然后使用遗传算法在此空间内生成初始种群,进而迭代寻找高精度的最优解.将网格搜索法与遗传算法相结合,优化了遗传算法的寻优空间,提升了算法的寻优速度,也弥补了较大步长网格搜索法在求解精度上的不足.
2.2 遗传操作
2.2.1退火选择算子
融合遗传算法和模拟退火算法可以兼顾全局和局部搜索能力,弥补遗传算法局部搜索能力差的缺点.本文在遗传算法的选择策略中引入了模拟退火算法中的Metropolis接受准则,与精英保留策略相结合,构造了退火选择算子,对新个体的接受进行退火选择以提升算法的局部搜索能力.算子具体步骤如下:
步骤1 设置初始温度,此算子通过模拟金属降温过程的原理来对新个体进行选择;
步骤2 个体接受概率,遗传操作产生新个体的适应度为f(x′),若f(x′)≥f(x)则接受新个体;反之则以概率P接受该进化个体,概率计算公式如下:
(1)
(2)
步骤3 降温操作,执行:
Ti+1=γ·Ti,
(3)
其中0<γ<1.
2.2.2多模式交叉和变异算子
本文采用OX顺序交叉算子和OBM逆转变异算子,交叉过程中父代个体的部分编码不改变顺序的随机继承到子代编码中;变异过程中父代个体编码的前后元素随机交换位置.交叉概率Pc和变异概率Pm的取值会直接影响到遗传算法的收敛效果,Pc取值过大会破坏精英个体自身结构,影响算法的进化方向,取值过小会导致种群迭代速度过慢进而影响算法寻优速度;Pm取值过大会产生大量随机解,反之则导致局部搜索能力差.针对两种算子概率取值问题,本文在标准遗传算法的基础上进行了如下改进.
2.2.2.1基于函数的自适应交叉算子
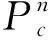
(4)
E=1+exp(α·Φ(f′)),
(5)
(6)
(7)
基于Sigmoid曲线构建的概率调整算子不仅可以在算法初期种群适应度较小时,提高交叉概率Pc来产生新个体,加快算法前期迭代中的种群更新,而且可以在算法后期适应度接近最大适应度时,降低交叉概率Pc来保护种群优秀个体的染色体结构不被破坏.
2.2.2.2基于粒子飞行速度的惯性变异算子
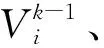
个体最优差异值计算公式:
Sibest=|Si-b|,
(8)
其中Si为个体i的适应度,b为S1,S2,S3,…,Sn的最优解.
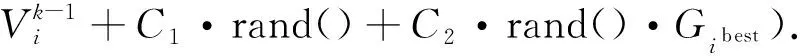
3 基于混合遗传算法的SVM参数优化模型
染色体编码:由于核函数参数C的设定和误差惩罚参数σ的选择均为连续实数,本文采用实数编码的方式构成pop_size个染色体.


改进后的混合遗传算法对支持向量机的参数优化流程如图1所示,HGA的迭代过程中会使用不同的超参数对SVM进行预训练,并计算超参数取值下的适应度,然后根据适应度的状况进行超参数的迭代和选择,最后根据最优超参数训练SVM模型.

4 实验结果与分析
4.1 实验环境
本文实验使用MATLAB完成,所使用的支持向量机分类模型基于LibSVM软件包搭建.实验环境为Windows10家庭中文版,MATLAB R2018b,Intel(R)Core(TM)i7-7700HQ @2.80 GHz,内存16 GB.本文实验的主要目标是通过仿真实例,检验分类模型和算法的有效性.
4.2 不同评估模型的性能比较
为比较HGA-SVM评估模型与其他模型在信用风险评估问题中的评估效果,本实验中分别选取了网格搜索法、人工鱼群算法、爬山算法、粒子群算法、模拟退火算法以及标准遗传算法对SVM进行参数优化,分别构建了基于SVM的信用风险评估模型.GS算法的参数搜寻范围为,C∈[0,100],σ=[0.001,1];AF算法的拥挤因子α=0.57,视野范围γ=17;PSO算法的粒子数S=100,惯性因子ω=0.69,加速常数C1=C2=2.49,最大飞行速度Vmax=4;SA算法的初始温度T0=2 000,降温系数γ=0.75,中止温度Tfinal=1e-2;GA的交叉概率Pc=0.7,变异概率Pm=0.35,种群大小S=100.结果如表1所示.

表1 仿真实验结果统计
通过实验可以发现,在支持向量机的优化问题中,C和σ参数优化的精准度对SVM的分类成功率有着决定性的影响,参数的选取在精准到4位小数后依然可以在分类成功率上有着较为可观的体现.
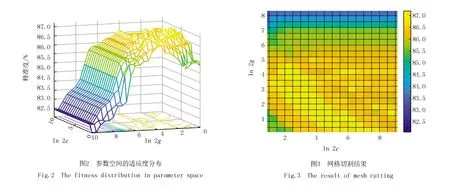
HGA算法前期网格切割结果如图2、3所示,在图2中本文模拟出了参数空间中的适应度分布情况,为了优化初代种群的分布进而提升算法的迭代速度,HGA算法的初代种群基于图3的切割结果生成,在图4(a)算法的适应度迭代情况中可以发现,种群平均适应度明显优于未经优化的随机生成种群.

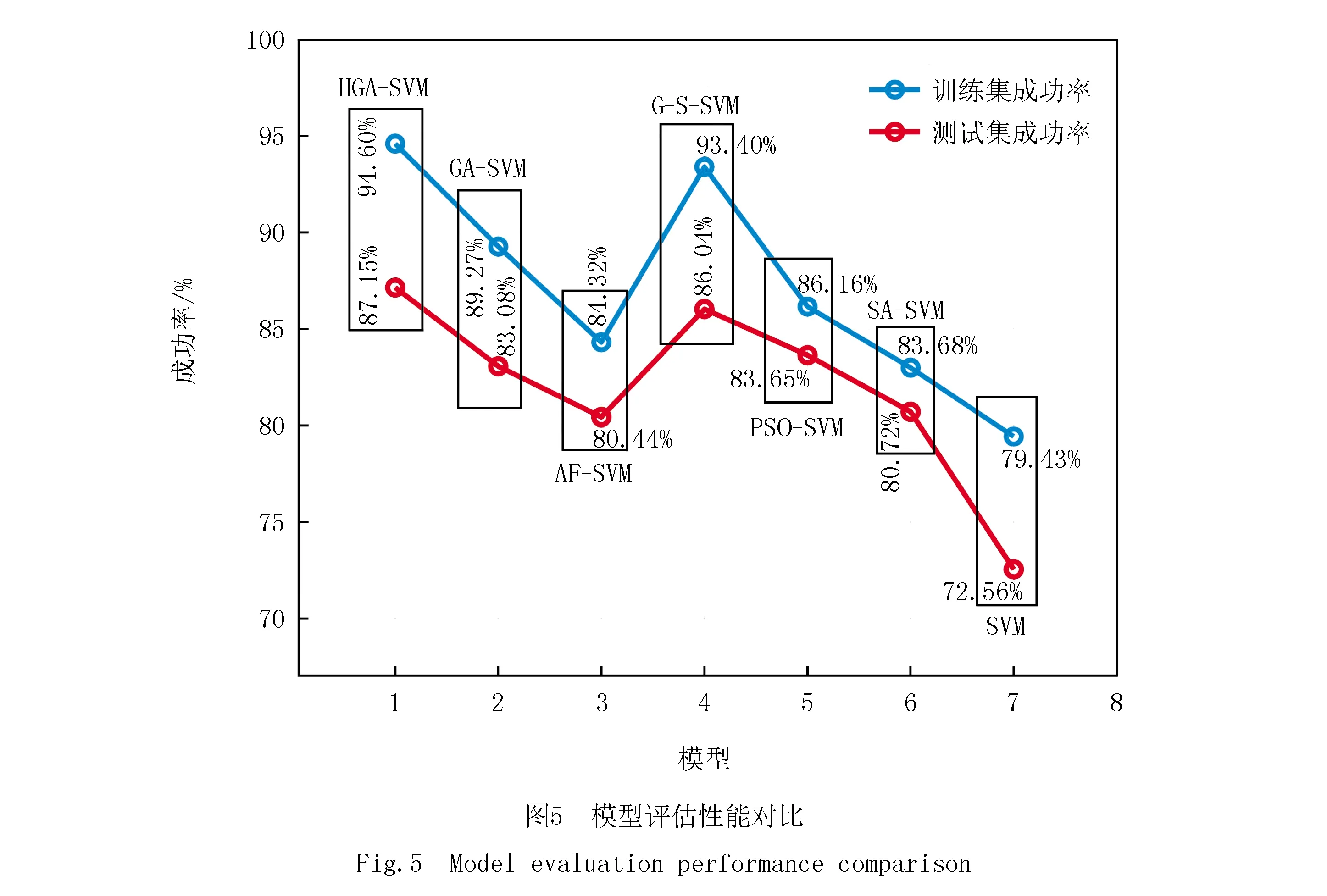
如图5所示,在信用风险评估精度方面,与SVM,GA,PSO,G-S,AF,SA算法相比,HGA-SVM评估模型在训练集以及测试集的分类成功率均为最高,其他算法优化的SVM评估模型测试集分类成功率均在80%~85%,HGA-SVM风险评估模型在测试集中成功率达到了87.153 8%,搜索精准度优于其他模型;在收敛速度方面PSO-SVM模型收敛速度最快,在第47代收敛,但是从求解精准度方面显然陷入了局部最优,未寻得全局最优值;HGA-SVM评估模型的收敛速度仅次于PSO-SVM,算法在第56代收敛,迭代曲线如图4(a)所示,大幅度提升了算法的收敛速度,模型的评估结果如图6所示,GA-SVM模型在78代收敛,成功率为83.075 5%,迭代曲线如图4(b)所示;求解速度最慢的算法是较为基础的网格搜索法,但从分类成功率方面取得了不错的效果,达到了86%,仅次于HGA-SVM评估模型.综上所述,在综合考虑求解速度和求解精准度的情况下,HGA-SVM信用风险评估模型是上述模型中性能最为优越的评估方法,显著提升了评估的效率及精准度.
考虑到模型的时间复杂度,网格搜索法等传统方法构建的评估模型已无法满足对精准度的要求,标准的智能算法如PSO算法、AF算法、SA算法等构建的评估模型也因为收敛速度慢、易陷入局部最优等因素不再适用.综合考虑模型的评估精度及收敛速度,HGA-SVM信用风险评估模型整体上优于实验中所参照的其他几种评估模型,有较大幅度的提升.
5 结 论
本文为了提高对中小型企业信用风险的评估精度和评估效率,在标准遗传算法的基础上引入了退火选择、多模式交叉变异等改进遗传算子,构建了HGA-SVM信用风险评估模型,仿真实验结果表明模型在中小型企业信用风险评估问题上取得了不错的效果,提高了评估的效率及准确性,可以在中小型企业融资、贷款等场景下做出准确可靠的评估.对于中小型企业的融资、风险管理以及金融服务监管有着重要的意义,其应用前景十分广阔,具有一定的实际应用意义和理论研究价值.

