视差注意力的立体图像颜色校正方法
2022-03-03郑愈明范媛媛牛玉贞
郑愈明,范媛媛,牛玉贞,2
1(福州大学 计算机与大数据学院,福州 350105) 2(空间数据挖掘与信息共享省部共建教育部重点实验室,福州 350105)
1 引 言
随着科学技术不断发展,双目立体视觉研究日趋成熟.利用双目摄像技术可以从不同视角拍摄被测物体的左右视图,获取立体图像对.但由于摄像机机位设置、环境亮度变化以及物体表面对光的漫反射等差异,摄像机在不同视角对同一物体捕获到的图像会存在一定的亮度和颜色差异.这将影响立体图像颜色校正[1-5]、多视点视频颜色校正[6-9]、遥感图像融合[10-12]、全景图像拼接[13-15]等与颜色一致性相关的立体视觉任务,也会影响任务中的深度信息重建[16]效果.因此,需要对立体图像对进行预处理,消除图像组间颜色差异.颜色校正算法针对图像组间颜色差异问题,建立参考图像和目标图像间的颜色映射,校正失真目标图像的颜色,使图像对具有相同的颜色风格.图1给出了一个例子,(a)为参考图像(立体图像对的左视图),(b)为目标图像(存在颜色失真的右视图),(c)为经本文方法校正颜色后的结果图像.

图1 立体图像颜色校正结果Fig.1 Stereoscopic image color correction result
目前,根据颜色映射函数数量来划分,颜色校正算法可以分为两类,即全局颜色校正算法和局部颜色校正算法.全局颜色校正算法计算从参考图像到目标图像的全局颜色映射函数,根据同一映射函数校正目标图像中所有像素的颜色.例如,Reinhard提出的全局颜色迁移方法[17],将颜色空间转换到Lab颜色空间内进行颜色转换;Xiao等人在Reinhard方法基础上,消除空间转换的额外开销,在RGB颜色空间下使用协方差矩阵转换实现全局颜色迁移[18];Pitie等人提出使用累积概率密度函数进行颜色校正的算法[19],以及改进后的用于平滑结果图像迭代的非线性的算法[20].另外还有基于直方图或累积直方图的颜色迁移算法[21-23].全局颜色校正方法效率较高,对纹理简单色彩单一的图像校正效果较好,但由于使用单一映射函数,对局部纹理信息关注较少,当目标图像存在复杂纹理时,就会产生校正结果局部颜色不一致的问题.并且,全局颜色校正方法无法提供像素级别对应关系,不适用于立体图像颜色校正和全景图像拼接等存在视差的视觉任务.
针对全局颜色校正算法的缺点,研究者们提出了对不同区域像素计算不同的颜色映射函数并用于颜色校正的局部颜色校正算法.例如,Zhang等人提出的主区域映射方法[24],使用配准算法匹配图像重叠区域,根据匹配度选择主区域并计算对应独立映射函数.Park等人提出的基于矩阵分解的颜色迁移算法[2]以及基于矩阵因式分解的颜色迁移方法[25].Zheng和Niu等人提出的基于匹配和优化的颜色校正方法[3],该方法使用基于SIFT Flow[26]的密集立体匹配图来初始化全局颜色校正结果图的颜色值,再结合优化颜色校正这一二次能量最小化问题,来提高结果的局部颜色平滑度和全局颜色一致性.但SIFT Flow的计算和二次能量最小化优化过程耗时较长,对于视差较大的立体图像对,该方法生成的初始图与目标图存在结构变形.于是Niu等人提出了改进结构一致性的视觉一致性立体3D图像颜色校正方法[4],该方法改进了二次能量最小化函数并加入引导滤波,使得校正结果结构一致性较好,但引导滤波的使用降低了图像清晰度.之后,为了改善图像清晰度.Niu等人提出了提高图像清晰度的基于抠图的结构一致图像颜色校正残差优化方法[5],该方法计算初始化图像与目标图像的初始化结果的残差图像,并通过软抠图方法优化残差图像,减小局部颜色差异,使得结果图像保持了与参考图像一致的图像结构与清晰度.Fan等人提出基于深度残差优化的立体图像颜色校正方法[1],在初始结果生成阶段引用MO初始化方法,后处理优化步骤使用深度神经网络方法.然而,MO算法的初始化步骤使用传统的SIFT Flow图像配准算法和ACG-CDT全局颜色校正方法,初始阶段耗时长,时间复杂度较高,整体效率没有得到提升.局部颜色校正算法对参考图像与目标图像进行区域划分并匹配对应关系,对不同区域计算单独映射函数,对图像局部信息的关注度提升.但受到多个映射函数的作用以及不同匹配方法稳定性的影响,局部校正算法特征关系匹配的稳定性和准确性波动较大,在无匹配或误匹配区域存在校正结果与目标图像结构不一致以及结果图像内部区域间颜色不一致的现象,需要对其进行后续优化.因而局部颜色校正算法虽然能够得到较好的颜色校正效果,但要花费更多的处理时间,效率较低.
针对以上问题,为了在保持高时间效率的同时获得更高质量的颜色校正结果,本文提出一种端到端的视差注意力的立体图像颜色校正方法(Parallax Attention based Stereoscopic image Color Correction,PASCC),引入基于卷积神经网络的视差注意力机制[27]来替代传统预处理方法中左右视图的稠密匹配,将复杂的初始化与优化步骤结合的旧架构修改为新架构:在一个卷积神经网络内同时进行立体图像对应关系学习与目标图像颜色校正.本方法先使用参数共享的多尺度特征提取模块分别提取参考图像和目标图像的多尺度层次特征,再使用视差注意力模块对特征图进行匹配融合.视差注意力模块中的双向匹配策略能够得到参考图像和目标图像之间较为准确的像素对应关系,并依据对应关系进行立体图像间的特征融合,最后重建融合特征得到校正目标图像.视差注意力机制仅在立体图像的视差方向进行相似像素搜索和匹配,无视差大小限制,因此模型具有更好的灵活性和更强的泛化能力.与主流颜色校正算法的客观评估指标对比和主观质量分析实验结果也证明了该方法在立体图像颜色校正中的有效性和稳定性.
2 本文方法
本文提出的视差注意力的立体图像颜色校正方法的模型架构如图2所示,模型分为多尺度特征提取模块、视差注意力模块和图像重建模块3个部分.网络模型将参考图像(立体图像对的左视图)与待校正的目标图像(存在颜色失真的右视图)作为输入.颜色校正的方法步骤如下:
1)首先通过参数共享的多尺度特征提取模块分别提取参考图像与目标图像的多尺度层次特征,接着在残差块进行多尺度特征融合,最后得到具有密集像素采样率的多尺度特征表示;
2)将提取出的立体图像对的多尺度特征同时输入视差注意力模块(Parallax Attention Module,PAM).PAM首先对立体图像对的视差信息进行编码,生成能够反映参考图像与目标图像像素对应关系的视差注意力图.再利用视差注意力图和生成的有效掩膜对立体图像对的信息融合进行指导,使校正结果在保留目标图像原始结构的同时具有与参考图像对应位置一致的像素颜色,并生成融合特征;
3)根据融合后的特征进行图像重建得到最终的颜色校正结果.

图2 视差注意力的立体图像颜色校正方法模型架构Fig.2 Model architecture of parallax attention based stereoscopic image color correction
2.1 多尺度特征提取
为了估计立体图像的像素对应关系,需要获取具有丰富上下文信息和强判别力的特征表示[27],为了获得这样的特征表示,需要用于捕获图像特征的特征学习具有多尺度与较大感受野(receptive field).在卷积神经网络中,当前特征图上的点对应到原始图像上的区域大小即为感受野的大小.因此,为了扩大模型感受野,获取像素采样率更密集的多尺度特征,模型引入了残差空洞空间金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)模块.多尺度特征提取模块由残差空洞空间金字塔模块[52]与残差块[28]交替级联构成,如图2左半两个虚线框所示.由卷积层和残差块(ResBlock0)对特征进行初步提取,先通过残差ASPP块(ResASPPBlock1)获得多尺度特征,接着进入残差块(ResBlock1)对多尺度特征进行融合,重复两次特征提取与融合步骤,最终得到具有丰富上下文信息和强判别力的特征表示.
每个残差ASPP块首先由3个扩张率(dilation rate)分别为1、4、8的空洞卷积(dilated convolutions)级联形成ASPP组,接着3个ASPP组以残差形式连接.残差ASPP块不仅扩大了感受野,而且得到具有不同扩张率的卷积集合,能够获得更具判别力的特征表示.残差ASPP模块学习到的高度鉴别性特征有利于提高立体图像对应关系估计的准确率,提升颜色校正性能.
2.2 视差注意力模块
视差注意力机制[27]是受自注意力机制启发提出的用于捕获双目立体图像全局对应关系的一种注意力机制.该机制根据双目立体视觉对极几何[29](Epipolar Geometry)关系原理,当摄像机从不同视点对同一个3D场景进行拍摄时,获得的2D图像与3D点之间存在几何相关性,对极几何能够描述两个结果视点间的关系,对图像点产生约束作用.从而将搜索空间限制在极线上(理想情况下极线即所搜索像素点所在的水平线),只在极线方向上搜索像素的相似点.视差注意力机制针对参考图像中的每一个像素点,计算其与目标图像中对应水平极线上的所有像素点的相似性,对全部点进行计算后得到视差注意力图.视差注意力图上的权值大小体现对应点与搜索点的相似程度,因此根据权值分布即可获得立体图像间的对应关系.视差注意力机制大大缩小了对应关系的搜索空间,提升了对应关系的获取效率.同时,该机制不需要考虑所有相似特征点的信息,只专注于相似度最高的特征点,因此,大大提升了获得可靠的对应关系的速度.
图3展示了视差注意力模块的具体结构.输入为参考图像与目标图像从特征提取模块获得的多尺度特征图A,B∈RH×W×C(其中H为图像高度,W为图像宽度,C为图像通道数),首先通过权值共享的过渡残差块(Transition Residual Block)得到A0,B0∈RH×W×C.视差注意力模块可以认为是一个学习立体图像对应关系并利用参考图像颜色信息校正目标图像的多任务网络模块,使用过渡残差块可以缓解共享特征用于不同任务而产生训练冲突的问题.接着,A0通过一个1×1的卷积层conv2_a得到查询特征图Q∈RH×W×C,同时,B0通过另一个1×1卷积层conv2_b并将结果进行矩阵维数调整得到S∈RH×W×C.对Q与S进行批次化矩阵乘法(batch-wise matrix multiplication),并通过一个SoftMax层,得到从特征图B到特征图A的视差注意力图MB→A∈RH×W×W.批次化矩阵乘法过程说明如图4所示,图中,MB→A(i,:,:)∈RW×W表示MB→A∈RH×W×W的第i个切片,它由Q(i,:,:)∈RW×C与S(i,:,:)∈RC×W相乘计算得到,将所有切片相连得到MB→A∈RH×W×W.之后,令B通过一个1×1卷积层conv2_c得到特征R∈RH×W×C,将视差注意力图MB→A与R进行批次化矩阵乘法得到特征图0∈RH×W×C,特征图O表示视差加权和.结合特征图O和与其相对应的特征图A,PAM就可根据特征相似性,集中在具有准确视差的特征上,捕获A与B的对应关系.

图3 视差注意力模块的结构Fig.3 Structure of the parallax attention module
完成MB→A的计算后,交换A和B并重复上述计算过程,得到特征图A到特征图B的视差注意力图MA→B,用以计算生成有效掩膜(valid mask)VA→B,排除遮挡区域的影响.最后,将特征图O、A与有效掩模三者进行矩阵连接,并输入1×1卷积进行信息融合.
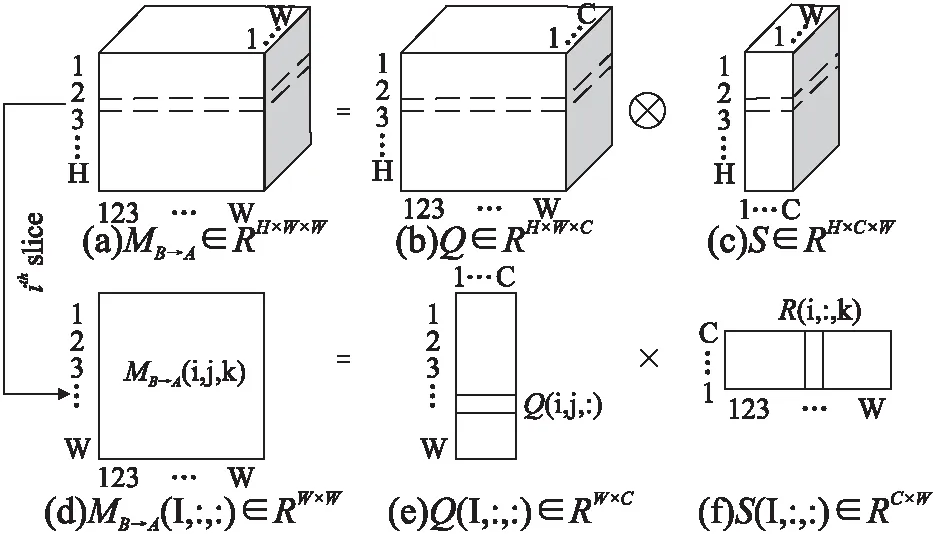
图4 批次化矩阵乘法的说明Fig.4 Illustration of batch-wise matrix multiplication
PAM根据立体图像对左右视图Ileft和Iright(Ileft为参考图像,Iright为目标图像)分别提取得到的多尺度特征,生成两个视差注意图Mleft→right和Mright→left.理想情况下,假设PAM得到了立体图像对准确的像素对应关系,则可以获得如下左右一致性约束:
(1)
其中,⊗符号表示批次化矩阵乘法运算,基于公式(1)可以进一步推导出循环一致性约束:
(2)
其中,Mleft→right→left和Mright→left→right为循环注意图,是视差注意图Mleft→right和Mright→left批次化矩阵乘法运算的结果,公式如下:
(3)
左右一致性约束和循环一致性约束用于辅助训练PAM模型,以产生可靠稳定性更强的、保持一致性的对应关系.详细的应用在2.3节损失函数中介绍.在PAM生成的视差注意图中,遮挡区域的像素通常权重较小,因此,以立体图像右视图Iright到左视图Ileft的有效掩膜Vright→left为例,其计算公式如下:
(4)
其中,τ是阈值(实验中设置为0.1),W是立体图像的宽.
根据视差注意力机制,视差注意图上的值Mright→left(i,k,j)表示左视图中位置(i,j)对右视图中位置(i,k)的贡献,由于左视图中被遮挡的像素无法在右视图中找到具有对应关系的像素,因此这些像素的有效掩膜Vright→left(i,j)的值通常较低,将这类像素认定为遮挡像素.由于左视图中的遮挡区域在右视图中没有对应的像素,无法从右视图中获得额外信息,因此有效掩膜可以进一步用于指导特征融合.
2.3 损失函数
由于视差注意力的立体图像颜色校正模型是一个学习立体图像对对应关系并利用参考图像颜色信息对目标图像进行颜色校正的多任务网络,因此模型的损失函数分为两个部分,一部分损失用于辅助捕获立体图像对之间的对应关系,另一部分损失用于辅助完成颜色校正任务.由于带有真实视差图的大型立体图像数据集难以获取,因此对于PAM捕获对应关系的任务,本文采用无监督方式进行训练,而颜色校正任务中存在理想目标图像,采用有监督的方式进行网络训练.注意,如果数据集包含真实视差图,可以使用网络生成对应的视差注意力图并以有监督的方式对PAM进行训练.
PAM模块用于捕获立体图像间对应关系的损失主要包括光度损失Lphotometric、平滑损失Lsmooth和循环损失Lcycle.

Lphotometric=∑p∈Vleft→right‖Ileft(p)-(Mleft→right⊗Iright)(p)‖1
+∑p∈Vright→left‖Iright(p)-(Mleft→right⊗Ileft)(p)‖1
(5)
其中,p表示一个具有有效掩码值的像素(即非遮挡区域的像素).上式第1项针对左视图到右视图的对应关系,第2项针对右视图到左视图的对应关系.
为了使图像中纹理结构不清晰、存在差异的区域产生准确一致的视差注意力,在视差注意力图Mleft→right和Mright→left上定义平滑损失:
Lsmooth=∑M∑i,j,k(‖M(i,j,k)-M(i+1,j,k)‖1+
‖M(i,j,k)-M(i,j+1,k+1)‖1)
(6)
其中,M∈{mleft→right,Mright→left},上式中的第1项和第2项分别用于实现垂直注意一致性和水平注意一致性.
除了光度损失和平滑损失,PAM模块进一步引入循环损失,以实现周期一致性.由于公式(2)中的循环注意力图Mleft→right→left∈RH×W×W和Mright→left→right∈RH×W×W是单位矩阵,循环损失为:
Lcycle=∑p∈Vleft→right‖Mleft→right→left(p)-I(p)‖1+
∑p∈Vright→left‖Mright→left→right(p)-I(p)‖1
(7)
其中,I∈RH×W×W由H个单位矩阵堆叠而成.

(8)
其中,W和H分别为图像的宽和高,I(i,j)表示图像上坐标为(i,j)的像素点的值.

(9)
结合上述损失,本模型总损失函数如下:
L=Lper-pixel+λ1Lperceptual+λ2(Lphotometric+Lsmooth+Lcycle)
(10)
其中,λ1表示感知损失的权重,λ2用于调节代表对应关系获取的3种损失的权重.实验中,设置权重参数λ1=λ2=0.005.
3 实验结果与分析
本小节介绍基于视差注意力的立体图像颜色校正模型的实验设置与细节,通过对比实验来测试验证模型的有效性.
3.1 数据集
为了训练所提出的颜色校正模型并验证其有效性,本节选取3个图像数据集,ICCD2015数据集[30]、Middlebury数据集[31-35]和Flickr1024数据集[36].后两个数据集只包含无失真的原始立体图像对,因此使用Adobe Photoshop CS6对原始目标图像(无失真右视图)进行颜色修改.失真处理包括6种类型[30],每种类型包括3种修改粒度:亮度(+30,+60,+90)、对比度(+20,+40,+60)、曝光度(+1,+2,+3)、RG颜色通道(+30,+60,+90)、色度(+20,+40,+60)和饱和度(+20,+40,+60),经失真处理后的每对原始无失真立体图像可得到18张失真目标图像用于颜色校正.
模型训练集为经过处理的Flickr1024数据集[36]的训练集,包含14400张待校正目标图像,并使用数据增强策略对数据进行预处理,先将所有图像对按短边缩放到400像素,长边进行等比缩放,再将图像对的左右视图进行随机数相同的裁剪方法裁剪成128×128大小作为网络模型的输入.实验发现训练约130个epoch之后模型损失不再减小,更多的训练也无法提供进一步的改进效果,此时训练停止.
模型有效性验证使用经过处理的Middlebury数据集和Flickr1024[36]的测试集.其中Middlebury数据集包含1224张待校正目标图像,Flickr1024测试集包含2016张待校正目标图像.进行模型测试时,将用于测试的数据集图像都将进行缩放,将图像的长边缩放到512像素,图像短边依据长边缩放比例进行等比缩放.
3.2 实验细节
本文所提出的PASCC模型使用Python语言和Pytorch深度学习框架实现,实验环境如下:操作系统为Ubuntu16.04,处理器为Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz×6,显卡为Nvidia Tesla P100 16G×2,Python版本为3.6.2,Pytorch版本为0.4.0,CUDA版本为8.0.61.PASCC模型的详细架构如表1所示,表中,LReLU表示泄漏因子为0.1的LeackyReLU,dila表示扩张率,⊗表示批次化矩阵乘法.实验中采用参数β1=0.9,β2=0.999的Adam方法进行优化,batchsize设置为8.初始学习率为2×10-4,学习率每隔20epoch减半.

表1 PASCC模型的详细架构Table 1 Detailed architecture of PASCC model
3.3 评价指标
为了评估本文方法的有效性,本文使用18种图像质量评估指标用于评估颜色校正结果,分别为UQI[37]、PSNR[30]、SSIM[38]、MSE[39]、MAD[40]、CSSS[41]、FSIM[42]、FSIMc[42]、GSM[43]、VSI[44]、iCID[45]、DSCSI[46]、OSS[47]、IFS[48]、DSS[49]、GSIM[50]、PSIM[51]、CSVD[30],其中,MSE、MAD、iCID 3种指标为越小越好,其余指标为越大越好.
3.4 对比实验
3.4.1 客观质量评价
为了验证本文方法的颜色校正性能,本小节使用18种不同的图像质量评估指标将PASCC方法和11种先进颜色校正算法进行客观校正效果对比,包含GCT[17]、GCT-CCS[18]、ACG-CDT[20]、GPCT[22]、CHM[23]、PRM[24]、GC[10]、ICDT[19]、MO[3]、VC-ICC[4]、MROC[5].正如文献[30]中提到的,理想目标图像(即无颜色失真的目标图像)与目标图像具有完全一致的纹理结构,因此将颜色校正结果与理想目标图像进行对比,可以作为评估颜色校正效果的依据.质量评估结果如表2和表3所示,平均得分最高的方法分数使用黑体及下划线字体组合显示标出,平均得分次高的方法分数使用黑体显示标出.

表2 Middlebury数据集中与11种颜色校正算法的对比结果Table 2 Comparison results of 11 color correction algorithms in Middlebury dataset

表3 Flickr1024测试集中与11种颜色校正算法的对比结果Table 3 Comparison results of 11 color correction algorithms in Flickr1024 test set
分析表2给出的Middlebury数据集校正结果质量评估结果可以看出,在所选的18个质量评估指标中,PASCC方法颜色校正结果在16个指标上都排名第1,仅在MAD和IFS两个指标上排名第2.分析表3所示的Flickr1024数据集的校正结果质量评估对比结果可以看出,PASCC方法颜色校正结果在15个指标上都排名第1,在PSNR和GSIM两个指标上排名第2,仅有MAD评价指标的分数不是前3.
综合分析,在Middlebury数据集的质量评估对比中PASCC方法获得了最好的校正评估指标结果,VC-ICC方法次之.而在Flickr1024数据集中,PASCC方法同样获得了最好的校正评估效果,ICDT方法次之.可见,VC-ICC和ICDT算法在不同数据集上校正效果不一致.究其原因,不同数据集包含的图像特点不同,Middlebury数据集图像内容复杂、纹理多样、包含更多的颜色信息;Flickr1024数据集的图像风格更加真实日常,整体色调平和统一.而本文所提出的视差注意力的立体颜色校正方法不管是在纹理复杂、色彩多样的Middlebury数据集上,还是在画面更加简单自然的Flickr1024数据集上,都得到在客观质量评估数据对比上最好的颜色校正效果,证明了PASCC方法的有效性,体现了模型在不同立体图像数据集中的泛化能力.
由于ICCD2015数据集[30]中的参考-目标图像对不是标准的双目立体图像.数据集从视频的前后帧选取图像对,获得的图像对不具有固定的视差方向,且存在部分图像前景变化较大的问题.因此ICCD2015数据集不适合作为验证集来评估本文所提出的PASCC模型.PASCC模型在该数据集中的效果较为普通,但为了进行更全面的实验分析,本节也设计了在该数据集上的对比实验,对ICCD2015数据集共324张失真图像对进行颜色校正质量评估,实验结果如表4所示,平均得分最高的方法分数使用黑体及下划线字体组合显示标出,平均得分次高的方法分数使用黑体显示标出.
分析表4给出的实验结果可以得到,PASCC模型在ICCD2015数据集上颜色校正效果表现较为普通,只获得了PSIM指标上的第2名与GSM指标上的第3名,整体评估结果与GCT、ACG-CDT相近.而MO、VC-ICC以及MROC这3种使用SIFT Flow传统初始化方法进行像素匹配的算法效果在该数据集上表现更好.MO算法在4个指标上排名第1,VC-ICC算法在8个指标上排名第1,MROC算法在9个指标上排名第1.究其原因,这3种方法都是基于ICCD2015数据集来设置实验中的初始化阈值参数,因此在该数据集上适应性良好,而在其他数据集上适用性降低.另外,ICCD2015数据集的图像对并不是标准的双目立体图像,图像对的视差方向不固定,而PASCC模型的视差注意力模块仅对立体图像视差方向相似度最高的像素进行匹配,因此影响了像素匹配精度,使得颜色校正的准确性大幅下降.

表4 ICCD2015数据集中与11种颜色校正算法的对比结果Table 4 Comparison results between ICCD2015 data set and 11 color correction algorithms
3.4.2 主观视觉效果对比
上一节通过客观评价指标对PACSS模型进行了颜色校正性能验证,本节将从主观视觉效果对比角度,对比包含PASCC方法在内的12种方法的颜色校正结果.
图5为Flickr1024数据集下的颜色校正结果对比实例.分析图5可以发现,GPCT、CHM以及ICDT算法校正结果的背景天空存在错误伪影;GCT、GCT-CCS和ACG-CDT、PRM、GC以及MROC算法的校正结果存在明显的亮度偏差,并且未校正白色框标出的窗户颜色;MO模型校正了窗户颜色,但存在纹理结构变形.VC-ICC模型整体校正效果较好,但亮度仍存在一定偏差;而PASCC模型的校正结果在校正白色框标出的窗户颜色同时,还保持与理想结果相符的图片纹理结构和整体亮度,与理想结果是最相似、最接近的.

图5 不同方法在Flickr1024测试集的颜色校正视觉效果对比(目标图像失真类型为曝光度+3)Fig.5 Comparison of color correction visual effects of different methods in Flickr1024 test set(target image distortion type is exposure+3)
图6为Middlebury数据集下的颜色校正结果对比实例.观察图6可以发现,GPCT、CHM和ICDT 3种算法校正结果中的背景均存在错误光斑;PRM算法的校正结果整体颜色与理想结果不一致,并且左下角的花朵颜色错误;MO算法校正结果在黑色框标出的花朵部分存在错误伪影;GCT、GCT-CCS、ACG-CDT、GC、VC-ICC以及MROC方法整体校正效果较好,但均未能很好地校正黑色框标出的墙上影子细节,且亮度与理想结果存在一定差距.本文所提出的PASCC方法的结果不仅校正了颜色,还复原了图像的纹理细节.

图6 不同方法在Middlebury数据集的颜色校正视觉效果对比(目标图像失真类型为RG+30)Fig.6 Comparison of color correction visual effects of different methods in Middlebury dataset(the target image distortion type is RG+30)
PASCC模型的更多颜色校正效果如图7所示,图7(a)表示参考图像,图7(b)表示目标图像,图7(c)表示理想目标图像,图7(d)为MO算法结果,图7(e)为VC-ICC算法结果,图7(f)为MROC算法结果,图7(g)为PASCC模型结果.图中选择MO、VC-ICC、MROC与PASCC模型进行比较.前3列的图像来自Middlebury数据集,后3列图像来自Flickr1024数据集.目标图像从左到右的颜色失真类型分别为:RG通道+30,色度+40,饱和度+60,亮度+90,对比度+60,曝光度+2.分析图6的颜色校正结果对比可以观察到本文方法具有更好的颜色校正性能,在颜色变化较大或存在轻微曝光的情况下,都能够在保持图像纹理信息的同时很好地恢复出图像的颜色信息.

图7 不同算法的颜色校正结果对比Fig.7 Comparison of color correction results of different algorithms
3.4.3 时间复杂度
在本小节,我们讨论所提出的算法的时间复杂度.如表5显示了所提出的PASCC方法和其他被比较的颜色校正算法校正单张图像(512×320)的平均执行时间.CPU实验均在3.00GHzntel(R) Core(TM) i5-9500F CPU and 8.00 GB存储器的PC机上运行.本文方法使用深度学习框架实现,实验环境:操作系统为Ubuntu16.04,处理器为Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz×6,显卡为Nvidia Tesla P100 16G×2,Python版本为3.6.2,Pytorch版本为0.4.0,CUDA版本为8.0.61.分析表5数据可知,本文提出的PASCC方法不仅在局部颜色校正算法中获得了最优的时间效率,也比大部分全局颜色校正算法拥有更优的时间效率,能够在保持高时间效率的同时获得更高质量的颜色校正结果.

表5 平均运行时间(图像大小为512×320)Table 5 Average run time(image size 512×320)
4 结 论
本文提出一种端到端的视差注意力的立体图像颜色校正方法.使用基于卷积神经网络的视差注意力机制替代了传统预处理方法中左右视图的稠密匹配.先用一个共享参数的多尺度特征提取模块分别提取待校正立体图像左右视图的特征,再通过视差注意力模块进行特征的对应匹配,视差注意力模块中的双向匹配策略能够得到立体图像左右视图间比较准确的对应关系,融合左右视图特征并重建图像得到校正后的目标图像.在Flickr1024数据集和Middlebury数据集上与11种先进颜色校正算法进行对比实验,实验结果表明,本文提出的PASCC方法得到了最好的性能,证明了该方法的有效性.
