自注意力机制和随机森林回归的视频摘要生成
2022-03-02李雷霆武光利郭振洲
李雷霆,武光利,2,郭振洲
1.甘肃政法大学 网络空间安全学院,兰州730070
2.西北民族大学 中国民族语言文字信息技术教育部重点实验室,兰州730030
近年来,随着科技的不断进步,人们拍摄各种高质量的视频变得越来越方便,一部手机就可以满足日常的视频拍摄需求,人们也可以在网络上找到各种各样的视频资源。由于视频包含着复杂的图像和音频信息,它们常常数据量巨大,结构复杂。面对大量的视频数据,快速知晓视频的主要内容成为当下的一个热门问题。因此,分析和理解视频内容的自动工具必不可少,视频摘要便是帮助人们浏览视频数据的关键工具[1-2]。
视频摘要,就是以视频的结构和内容为主要分析目标,获取其中有意义的片段,然后用特定的方法将片段拼接成能概括视频内容的视频概要。视频摘要根据不同的获取方式可以分为两类:静态视频摘要和动态视频摘要[3-4]。
静态摘要是从视频中抽取出若干帧组成帧集合,这些帧称为关键帧,主要分为以下几类:
(1)基于视频聚类的关键帧提取方法。镜头聚类以聚类的方法为基础,对每个镜头进行分析,然后将特征相近的帧划分为一类,最后从每一类中按照一定方法选取关键帧。
(2)基于视频帧信息的关键帧提取方法。这一类方法主要考虑视频帧包含的特征信息,例如颜色、形状、纹理等,通过特征信息的变化来选取关键帧。
(3)基于运动分析的关键帧提取方法。该类方法一般是计算光流得到运动量,然后选取运动量最小处作为关键帧。
动态视频摘要主要包括视频镜头分割、视频镜头评价、视频镜头选择。视频镜头分割是将一个完整视频切分成若干个短视频,是动态摘要的基础。视频镜头评价则是根据不同的方法计算出每个镜头的重要性。视频镜头选择需要根据具体的需求选择合适的镜头组合成视频摘要[5]。
对于视频镜头的分割最初是通过图像的视觉特征进行分割,如根据像素值变化判断边界。
传统基于视觉特征的镜头划分方法对于非结构化的视频效果并不理想,因此涌现了许多基于视频内容的分割方法。Gygli等人[6]通过超帧来进行视频分割,并通过能量函数对视频段进行评价。Ngo等人[7]对结构化视频用谱聚类和时间图分析来进行场景建模,然后通过动作注意建模来进行重要视频段的检测。Potapov 等人[8]提出一种内核时间分割算法,采用核变化点来检测视频帧的变化情况,在视频帧突变的地方定义为镜头边界。上述方法能较好地完成镜头划分任务。
镜头划分完成后,需要选择出合适的镜头组合成摘要。目前较为先进的方法是基于编码器-解码器架构,将输入编码为中间向量,然后解码器根据中间向量解码为需要的输出序列。其中门限循环单元(gated recurrent unit,GRU)和长短期记忆网络(long short-term memory,LSTM)经常用于解决循环神经网络(recurrent neural network,RNN)无法进行远程依赖的问题,广泛应用于各领域。Zhang 等人[9]利用LSTM 和行列式点过程(determinantal point process,DPP)选择视频帧的子集,有效提高了摘要的多样性。Zhao 等人[10]用分层的LSTM来应对长的视频序列。Huang等人[11]将LSTM与一维卷积和二维卷积结合进行视频摘要建模。Ji等人[12]将注意力机制与LSTM结合,通过注意力机制为不同帧分配权重。Vaswani 等人[13]使用注意力机制代替RNN,减少了模型复杂度,取得较好的效果。Zhou等人[14]首次提出用强化学习实现视频摘要技术,同时设计了用于评估摘要多样性和代表性的奖励函数,使得模型能够自主学习并选择合适的摘要。李依依等人[15]将自注意力与强化学习结合,通过自注意力机制建模视频帧的重要程度,提高了模型的学习效率。
为了提高预测的准确性,同时考虑到视频是具有连续的图像这一特性,提出了一种包含编码器-解码器结构的注意力机制和随机森林回归视频摘要网络(attention random forest summarization network,ARFSN)。编码器采用预训练的GoogLeNet提取视频帧的深度特征,同时对编码器的输出添加注意力机制,而解码器部分则由LSTM 和随机森林共同组成,LSTM 输出视频帧是否是重要帧的概率,考虑到输出结果产生的损失值波动对模型影响较大,因此将LSTM输出结果映射为重要性分数输入到随机森林进行回归预测,最后将LSTM损失和随机森林损失通过权重融合为最终损失进行网络训练。通过注意力机制加大对关键帧的权重,使得生成的摘要具有代表性,此外随机森林的引入,能够有效降低波动带来的影响,同时提升模型的预测准确率,使得生成的摘要能更好地概括原视频的内容。
1 相关工作
目前视频摘要主要分为静态视频摘要和动态视频摘要,而动态摘要主要基于关键镜头的选择,此生成结果更具连贯性,因此本文重点讨论动态视频摘要生成。
当用户想要快速了解视频的内容时,注意力往往集中在那些令用户感兴趣、印象深刻的镜头或者视频帧,这些镜头或者视频帧极有可能被选为摘要,因此将注意力机制应用到视频摘要生成的任务中具有一定的可行性。
正如名字那样,注意力机制模仿人类观察时目光的注意力分布是不均匀的,因此在处理序列任务时通过注意力调整序列的权重,让某些无关紧要的信息被过滤,突出关键信息,使得模型能够更好地学习到重要的部分。
按照注意力的可微性,注意力机制可以分为硬注意力和软注意力。硬注意力机制可以看作0/1 问题,即某个区域要么重要,要么不重要,是不可微的,通常利用强化学习进行模型优化;软注意力则是一个[0,1]区间的连续问题,通过分配0 到1 之间的不同值来表示关注度的高低,是可微问题,通常用反向传播进行模型优化。对于视频摘要生成任务,本文将重点放在软注意力上。
注意力机制最初在自然语言处理(natural language processing,NLP)领域大放异彩,如今越来越多的研究人员将其应用到图像和视频领域。例如视频摘要领域,在编码解码框架中运用注意力机制完成视频摘要任务。编码部分通过LSTM实现,解码部分是基于注意力机制的LSTM网络,通过注意力机制不断调整序列的权重,帮助模型更准确选出摘要。Fajtl等人[16]用注意力机制替代循环神经网络。他们认为在进行人工标注时,标注的重点是存在视觉注意力的,因此可以使用注意力来捕获视频帧序列之间的远程依赖关系,并调整序列的权重。
2 模型
本文使用有监督的学习来完成视频摘要生成任务,并设计了一个基于注意力机制和随机森林回归的视频摘要网络,如图1所示。该网络通过GoogLeNet获取视频帧的特征,然后利用自注意力机制调整帧特征的权重并输入到双向LSTM预测帧的重要性得分,同时得到相应的损失(记为loss1),然后将预测到的重要性分数传给随机森林得到另一损失(记为loss2),最后通过权重将两个损失融合得到最终的损失值(记为Loss)。本文模型最终实现的是动态视频摘要,即基于镜头的摘要,因此需要将预测的帧级重要性分数转换为镜头分数,通过镜头分数按照一定的准则选择合适镜头并组合成为视频摘要。本文将视频摘要任务看作是序列到序列的预测问题,同时将自注意力机制与双向LSTM 结合,并引入了随机森林降低波动,提升稳定性,使得本文方法预测效果更准确,更容易完成对关键镜头的选取。

图1 ARFSN模型结构图Fig.1 ARFSN model structure
2.1 图像特征提取
图像特征提取使用预训练的GoogLeNet模型,网络深度共22 层,使用9 个Inception 结构,最终每帧图像输出1 024维特征。
2.2 自注意力机制
前面提到将视频摘要任务看作是序列到序列的过程。序列编码是模型学习序列信息最常用的方式,序列编码在建立长距离依赖关系时经常会出现梯度消失问题,使用全连接网络可以进行远距离依赖关系的建模,但是无法处理变长的序列,而自注意力机制能够获取全局信息,同时能够动态地为变长序列分配不同的权重,因此在处理序列任务方面效果良好。
注意力机制,其实是通过一个和目标相关的查询向量q,计算与Key的注意力分布,然后添加到Value上,最后计算出注意力值。
假设一个视频有N帧,由2.1节可知,[N,1 024]为视频的维度大小,用x表示视频的特征序列为x=x1,x2,…,xN。
对于注意力机制,令Key=Value=X,那么注意力分布的计算如下:
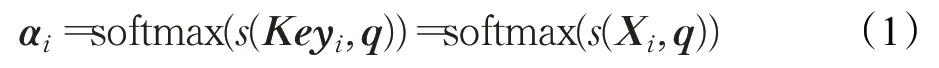
其中,s(Xi,q)为注意力打分函数。式(2)为加性模型,式(3)为点积模型,式(4)为缩放点积模型。
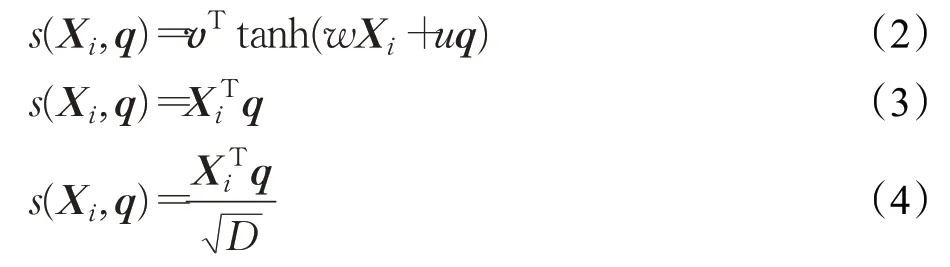
其中,v、w、u是可学习的网络参数,D是输入向量的维度。文献[12]分别采用了式(2)和式(3),实验结果表明点积模型效果优于加性模型。
得到注意力分布后,便可以计算注意力值:

对于自注意力机制,令Key=Value=Query=X,计算过程如图2所示,其中深色字母表示矩阵的维度。
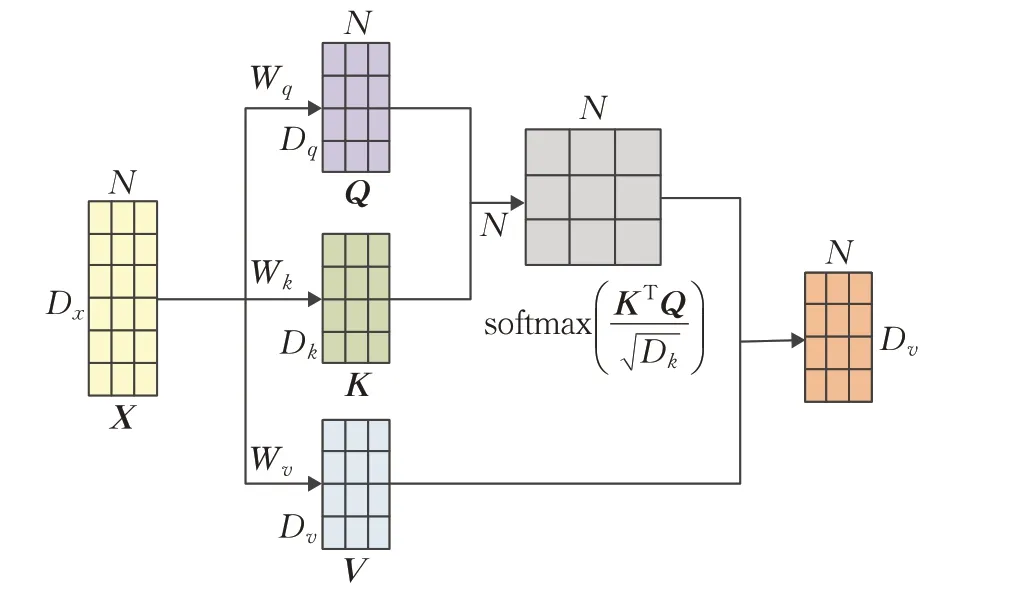
图2 自注意力模型的计算过程图Fig.2 Self-attention model calculation process
对于序列输入xi,通过线性关系进行映射,得到3 个向量,分别是查询向量qi,键向量ki,值向量vi。对于整个输入序列X,线性映射可以写为:
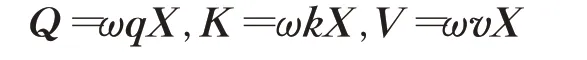
其中,ωq、ωk、ωv分别为线性映射的参数矩阵,Q、K、V分别是查询向量、键向量和值向量构成的矩阵。
根据键值注意力机制公式可得:
其中,n,i∈[1,N]为输出和输入向量序列的位置,αnj表示第n个输出关注到第j个输入的权重,s(k,q)为注意力打分函数,选用式(4)。
加性注意力和点积注意力复杂度相近,但加性注意力仅考虑将输入序列相连,没有考虑到输入序列之间的内部关系。而点积注意力能够很好地利用矩阵乘法探索自注意力的内在联系,当输入向量的维度较高时,点积模型会有较大的方差,缩放点积能够较好地解决这个问题。因此本文采用缩放点积模型来实现自注意力。
2.3 损失合并
卷积神经网络输出的深度特征经过自注意力机制调整序列权重后输入到双向LSTM网络中,双向LSTM分别从正向和反向进行计算,能够充分获取上下文信息。最后将模型预测重要性分数与人工标注通过均方误差(mean squared error,MSE)损失函数计算损失:
其中,M为数据个数,为模型预测值。
为了让模型能进一步减小预测值与期望值的差距,通过引入随机森林来降低损失值优化模型。具体来说,将LSTM 输出结果经由神经网络完成对视频帧得分的回归预测同时得到损失lossLSTM,之后将预测得分传入随机森林进行回归预测。随机森林的一个优点是:不需要进行交叉验证或独立测试集就能获得误差的无偏估计。因为随机森林在构建树时对训练数据采用bootstrap sample,对于每棵树而言,大约有1/3的数据没有参与到构建树的过程,这部分数据为袋外数据(out of band,OOB),然后每棵树利用袋外数据进行预测,每棵树损失计算如式(8)所示,最终将预测结果求和取均值作为最终结果,如式(9)。

其中,k为树的个数。
模型最终的损失Loss 由双向LSTM 损失lossLSTM和随机森林损失lossRF共同构成,用于指导模型学习。通过简单的运算将两个损失进行融合,尽可能最小化该损失值,使模型能够更准确地预测帧级重要性分数,合成更具代表性的视频摘要。
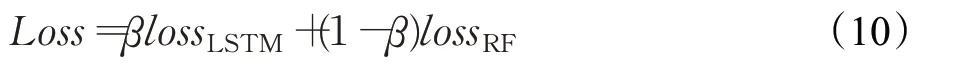
其中,β是一个超参数,训练过程中通过不断调整β的大小来优化模型。后续实验部分对此进行了验证。
2.4 帧级分数转换
本文的研究内容是基于动态视频摘要技术,而最终合成的摘要应当是视频镜头的合集,模型输出结果是帧级别重要性得分,因此需要将帧级分数转化为镜头分数。首先需要对视频进行镜头划分,使用在镜头分割方面效果优异的内核时间分割算法(kernel temporal segmentation,KTS)[8]对视频执行变点检测,并将视频进行镜头分段。由每帧重要性分数得到镜头重要性分数ci(式(11))。此外,根据Fajtl 等人[16]的建议,生成摘要的长度限制为原始视频长度的15%,需要选择最大化分数的镜头,选择满足条件的镜头等价于NP(non-deterministic polynomial)难问题,因此使用0/1 背包问题中的动态规划算法来选择合适镜头组成摘要(式(12))。

其中,ci为第i个镜头,Ni为第i个镜头包含的帧数,si,j为第i个镜头中第j帧的分数。ui∈{0,1}表示是否被选为关键镜头,K表示镜头的数量,L表示视频的总帧数。
3 实验结果与分析
前面几章已经介绍了相关工作和本文模型的结构,本章将重点介绍实验过程的细节,包括数据集、评价指标、实验参数和对比分析。
3.1 实验设计
3.1.1 数据集
本次实验主要在TvSum[17]和SumMe[6]两个数据集上进行,表1展示了它们的具体信息。

表1 两个标准数据集详细信息Table 1 Details of two standard datasets
TvSum 数据集是验证视频摘要技术的一个基准。它包含了50 个来自YouTube 的视频,这些视频涉及到10个主题,每个主题包含5个视频。Song等人[17]按照一定标准,使用亚马逊机器对视频进行标注,标注人员观看完视频后,对视频帧进行标注得分,标注得分从1(不重要)到5(重要)进行选择,图3展示了数据集的部分图像。

图3 TvSum视频图像示例Fig.3 Sample of TvSum video image
SumMe 数据集也是视频摘要技术研究常用的基准,它由25个视频组成,视频包含航飞、节假日、运动挑战等多个主题。每个视频由15~18个人进行标注,标注结果分为重要(1)和不重要(0)。每个视频的长度为1~6 min,标注是在可控环境下进行的,适用于实验评估。图4展示了数据集部分图像。

图4 SumMe视频图像示例Fig.4 Sample of SumMe video image
3.1.2 评价指标
为了与其他方法进行比较,按照文献[9]中的评价方法,即通过对比模型生成的视频摘要和人工选择的视频摘要的一致性来评估模型的性能,衡量指标采用Fscore 值。假设S为模型生成的摘要,G为人工选择的摘要,精准率和召回率计算如下:
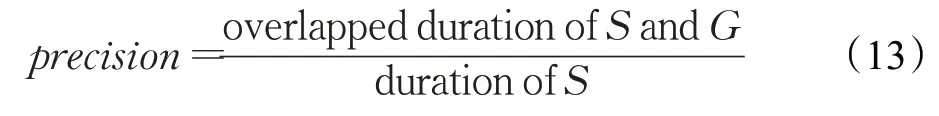

由式(13)、(14)可以计算出用于评估视频摘要的Fscore。

3.1.3 实验设置
实验时对数据集进行划分,其中80%用于训练,余下20%用于测试。考虑到实验使用的两个基准数据集数据量较小,同时为了减少过拟合现象的出现和提升模型泛化能力,对数据集使用5 折交叉验证。此外,对于TvSum数据集,每一帧由20个人标注,且该数据集中的视频存在较多的镜头切换,标注得分有差异明显,因此对于TvSum数据集计算F-score时,取20个人的平均值作为最终结果;而SumMe 数据集由15~18 个人进行标注,数据集中的视频多为一镜到底的,因此标注得分近似,从而计算F-score时选取最大值作为最终结果。
3.2 实验比较和分析
3.2.1 消融实验
为了验证注意力机制和随机森林回归对算法的影响,本文在TvSum 和SumMe 数据集上进行了消融实验。其中A为注意力机制模块,L为长短期记忆网络模块,R为随机森林回归模块。
由表2数据可以看出,使用不同模块时得到的F-score明显不同,当注意力模块A和随机森林回归模块R同时使用时,实验达到最优效果。这表明本文提出的基于注意力机制和随机森林回归的方法确实能够更准确地预测视频帧分数,从而精准得到关键镜头,生成更具代表性的视频摘要。
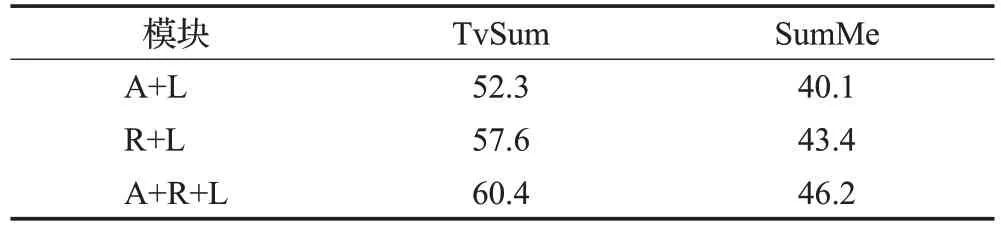
表2 两个数据集上消融实验结果Table 2 Results of ablation experiment on two datasets %
3.2.2 对比实验
本文选择了七种最新的基于监督学习的视频摘要模型进行对比,如表3所示,对比数据均来自原始论文。
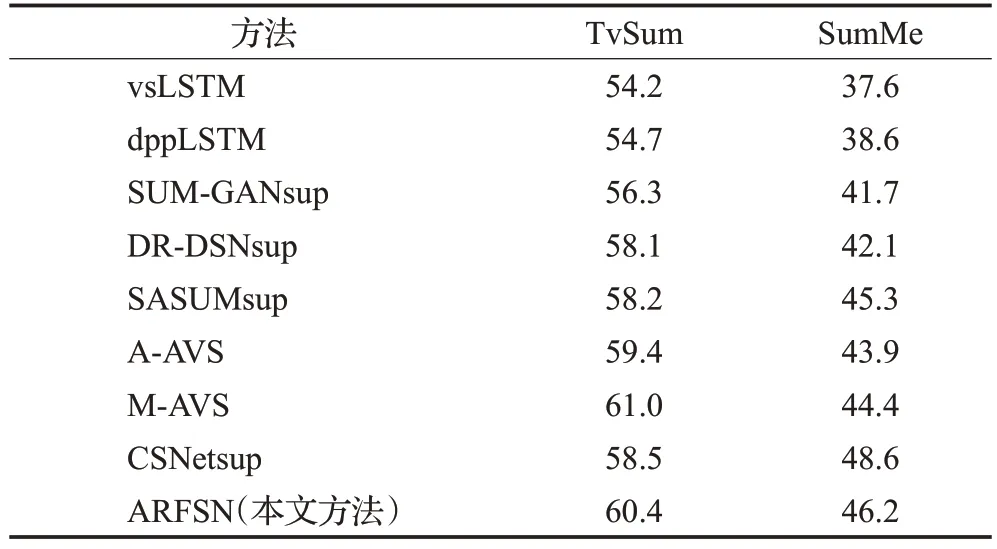
表3 实验结果对比Table 3 Comparison of experimental results %
(1)vsLSTM[9]使用双向LSTM 为基础,建立过去和将来方向上的远程依赖,最后与多层感知器相结合。(2)dppLSTM[9]是在vsLSTM 的基础上新增了行列式点过程,能够增加生成摘要的多样性。(3)SUM-GANsup[5]将变分自动编码器(variational auto-encoder,VAE)与生成对抗网络(generative adversarial networks,GAN)相结合,使鉴别器能够获得更多的语义信息。(4)DR-DSNsup[14]以强化学习为基础,代表性和丰富性作为奖励函数的限制条件。(5)SASUMsup[18]是融合语义信息的视频摘要方法,通过将摘要转换为文本信息,让模型选择具有丰富语音信息的摘要片段。(6)A-AVS[12]和M-AVS[12]是以编码解码为基础,将注意力机制与解码器结合的视频摘要方法,编码部分由双向LSTM 构成,解码部分由引入注意力的双向LSTM构成,其中A-AVS的注意力打分函数为加性模型,M-AVS 的注意力打分函数为点积模型。(7)CSNetsup[19]通过分块跨步网络将输入特征分为两个流(分块和跨步),分块能够更好地考虑到局部信息,跨步则充分考虑全局的时序信息。
根据表3数据可知,本文方法在两个基准数据集上都取得了较好的效果。在TvSum 数据集上,本文方法F-score 值虽略低于基于注意力的方法M-AVS,但在SumMe数据集上,相比于M-AVS有着较大提升,实验结果表明了本文方法的可行性。由于SumMe数据集中的视频多为结构化视频,即一个视频由一个镜头完整记录,场景变化小;而TvSum数据集中镜头多为用户自主拍摄,有明显的场景变换。由此可见,本文模型ARFSN有较好的适用性,在处理结构化和非结构化数据时都能取得不错的效果。
3.2.3 定性结果与分析
为了更好地直观展示本文方法生成的视频摘要质量,以数据集TvSum中的视频17为例,绘制它们真实分数与预测分数如图5所示,图中虚线表示人工选择的真实分数,实线表示模型预测分数。从图5 可以看到,本文方法预测得分与人工打分变化趋势基本一致,同时关键帧(高分帧)的预测更为准确,且本文方法预测的关键帧得分更高,说明模型更加关注了关键帧。总结来说,本文方法与人工摘要之间具有明确的关联性,证明了本文方法的有效性。

图5 分数对比图Fig.5 Score comparison chart
视频17是TvSum数据集中关于“三明治制作”的一个视频,如图6所示。将模型得到视频17的摘要与人工标注得到的摘要进行对比。图7 展示了本文模型选择的关键镜头的分布情况,浅色的柱状条表示人工标注的帧的重要性分数,深色柱状条表示模型选择的关键镜头,同时镜头的分布如图中虚线所指。可以看到选择的关键镜头基本涵盖了视频的开头、中部和结尾部分,选择的镜头分数也较高,表明本文方法选出的摘要具有一定的多样性和代表性。

图6 原始视频片段Fig.6 Original video clip
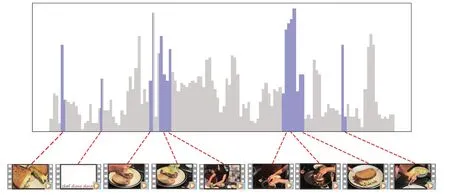
图7 本文方法选择摘要结果分布图Fig.7 Summary result distribution diagram of this paper method
3.3 参数选择
2.3 节介绍了损失函数的融合,损失函数的好坏对模型能否准确预测有着重要影响。在模型介绍时,本文方法引入了随机森林,将双向LSTM和随机森林融合使用的关键便是权重β,选择合适的β便是本节重点讨论的内容。
图8展示了不同权重对模型的影响程度。由图(a)可知当β=0.7 时,模型在TvSum 数据集上达到最佳Fscore。由图(b)可知当β=0.6 时,模型在SumMe 数据集上达到最佳F-score。整体来看,随着β增加,F-score基本呈上升趋势,但达到0.6~0.7附近时,β的增加会使得F-score 减小,因此对于LSTM 和随机森林损失的占比,不宜过小也不宜过大。最终分别确定了两个数据集上的最优β为0.7 和0.6。由于TvSum 数据集多为经过编辑的结构化视频,场景变换更丰富,增加随机森林占比能够较容易预测分数,因此对随机森林的依赖较大即β较小。而SumMe 数据集多为未经编辑的视频,镜头变化少,随机森林对其影响力较弱,因此β值较大。

图8 权重β 对两个数据集性能影响Fig.8 Influence of weight β on two datasets
4 结束语
在视频摘要生成任务中,本文提出了一个基于自注意力机制和随机森林的视频摘要网络。以现有的LSTM 模型为基础,通过注意力调整对关键帧的关注度,用随机森林来提高模型预测重要性分数的准确度。同时基于编码解码器的框架,能够很好地对输入序列进行转换(尤其是基于时间序列的数据),让模型可以计算出更有意义的结果。实验证明了本文方法的可行性,但这是仅在两个标准数据集下的结果,因此希望在未来的研究中,能够扩大视频摘要的影响领域。目前来说,对于监控视频和网络直播这两方面,视频摘要的研究相对较少,同时这两方面也是当下的热门话题,未来将更深一步研究视频摘要在监控视频和网络直播中的应用。
