结合Bi-LSTM-CNN的语音文本双模态情感识别模型
2022-03-02王兰馨王卫亚
王兰馨,王卫亚,程 鑫
长安大学 信息工程学院,西安710064
语音所表达的情感由语义信息和声学特征信息[1]确定。如图1 所示,语义信息即说话者要表达的内容,声学特征则是说话者表达语义信息时,由发音系统产生的物理变化。
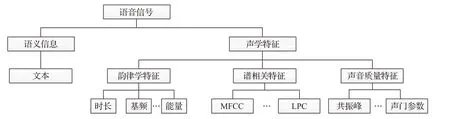
图1 语音信号传递的不同层面信息Fig.1 Speech conveys different levels information
单一模式中包含的情感信息有限。由于技术受限,语音情感识别任务前期研究主要利用声学特征来构建情感识别模型[2-5],却没有考虑到语音中所包含的具体语义信息,将人语音信号中密切相关的声音信息与文本信息内容分离并忽略文本信息的重要性[6]。近年来,随着机器学习算法的发展,越来越多的学者考虑到语义信息与声学特征内在的关联性和互补性,开始将二者结合用于情感识别的研究中[7-8]。
人在执行说话行为时,仅依靠声学特征信息来判断其情感状态可能会存在混淆。陈鹏展等人[9]利用序列浮动前向选择算法(sequential forward selection,SFS),提取了短时能量、过零率、基频等74个语音特征参数。对文本信息使用高斯混合模型(Gaussian mixture model,GMM)进行特征学习。对两个单模态识别器的判别结果进行加权融合,获得最终识别结果。实验证明双模态情感识别比单一模态识别效果更好。胡婷婷等人[10]提取语音数据中的声学特征,使用卷积神经网络与支持向量机(support vector machine,SVM)训练分类器训练模型。在声学模型基础上,加入了文本信息的相关特征,有效解决了愤怒与开心的误判情况。
由于深度学习算法表现效果优秀,当前很多的情感识别研究都使用了深度学习相关算法来进行模型构建,但是仍存在一些问题。大多数语音文本双模态情感识别的研究中,仅使用某一种卷积神经网络(convolutional neural network,CNN)或循环神经网络(recurrent neural network,RNN)结构来进行模态信息特征的提取,没有充分考虑其上下文信息和局部信息,忽略了模态数据中蕴含的与时间相关的特征信息,没有解决有效信息丢失的问题,部分模型中未考虑过模型拟合问题。
本文在语音文本双模态情感识别研究优势的基础上,采用深度神经网络进行特征学习,搭建Bi-LSTMCNN模型用于文本特征的学习,使用OpenSmile提取声学特征,并在特征层对两种模态数据进行融合,在决策层对分类结果进行融合,采用L2正则化和early stop技术防止模型的过拟合问题,最终搭建了Bi-LSTM-CNN+CNN 的混合网络结构,提出一种单一模态模型与联合模态模型相结合的语句级双模态情感识别模型。
1 基于Bi-LSTM-CNN的语音文本双模态情感识别模型
语音文本双模态情感识别流程通常如图2 所示。对语音信号和转录文本进行预处理,通过机器学习方法对文本、音频进行特征提取和学习。将提取后的特征在特征层进行融合后送入分类器进行分类。另一种常见流程是直接将提取的各模态特征直接送入分类器,再对分类结果进行决策层融合得出最终情感归类。
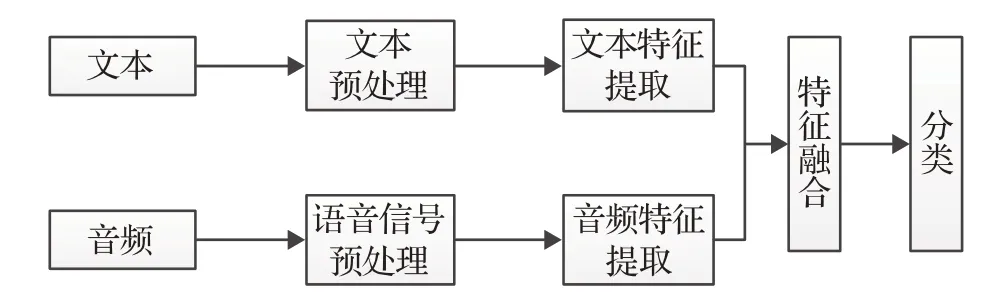
图2 语音文本双模态情感识别框图Fig.2 Speech-text-bimodal emotion recognition framework
长短时记忆网络(long short-term memory network,LSTM)是一种改进的RNN,具有强大的计算能力和存储能力,可以有效地解决梯度爆炸或消失的问题。语音是一种非线性时间序列转换信号,文字信息也与时间背景密切相关。因此,LSTM网络适用于声学和文本特征的提取和学习。然而,在LSTM 中没有非线性隐藏层,这会导致隐藏状态因子的变化增加[11]。
相反,CNN网络可以减少输入频率的差异,并捕捉局部信息,但不考虑全局特征和背景。简而言之,CNN和LSTM的建模能力都是有限的[12]。在此基础上,结合CNN和LSTM搭建网络进行语音情感识别,以学会对信息的最佳描述。
基于Bi-LSTM-CNN的语音文本双模态情感识别模型网络如图3 所示。双模态数据融合采用了特征层融合和决策层融合两种方式。特征层融合是在输入层面的可用特征传递给模型之前,先将不同模态数据的信息进行串联,可以更好地利用模态信息的互补性。而决策级融合是为每个模态建立独立的模型,模态间的信息互不影响,最终结果由独立模型共同决定,可以有效地捕捉各模型间的动态变化。

图3 语音文本双模态情感识别模型网络搭建Fig.3 Speech-text-bimodal emotion recognition model
2 文本特征学习
2.1 词向量预训练
在Word2vec[13]提供的Skip-Gram[14]模型训练中,设词典大小为V,给定中心词生成背景词的条件概率为:
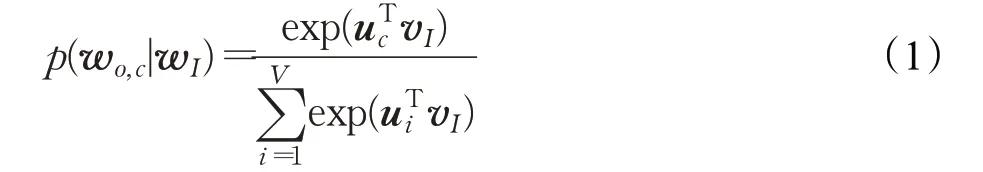
其中,wo,c表示第c个背景词;wI表示输入的中心词;uc表示索引为c的背景词向量,vI(vI∈V)表示索引为I的中心词向量。训练目标是,给定一个中心词wI,使模型输出C个背景词的概率最大,最大化条件概率为:

定义损失函数:
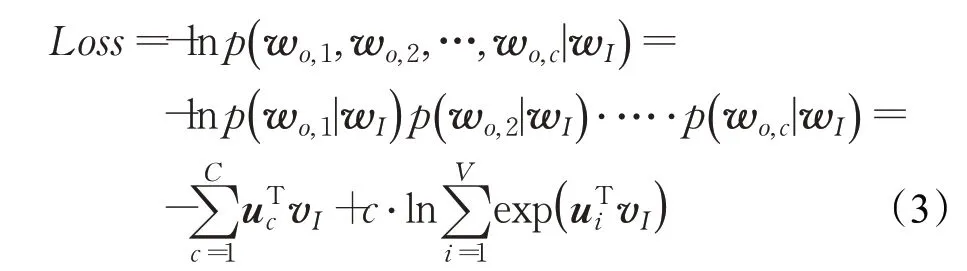
在维基百科提供的语料数据上,根据损失函数,利用反向传播,采取随机梯度下降策略更新权重,随着Skip-Gram模型不断训练,损失函数逐渐减小直至稳定,此时的vI即为所求向量,最终得到了维度为300的预训练词向量。
2.2 基于文本的Bi-LSTM-CNN模型
长短时记忆网络(LSTM)依靠其三门结构,有效地解决了神经网络中的长期依赖性问题。
门结构如图4所示,在t时刻,将当前隐层状态记为ht,各门状态更新如下:

图4 LSTM“门”结构Fig.4 LSTM“gate”structure
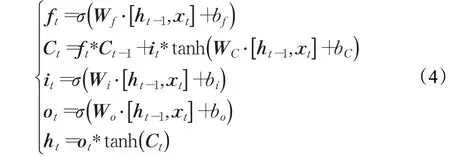
其中,xt表示当前输入单元状态,ft、Ct、it、ot分别表示当前遗忘门、存储单元、输入门、输出门。W*表示权重矩阵,b*表示偏置项,σ是激活函数。
Bi-LSTM由两个单向LSTM组成,一个是计算正序上下文信息的正向LSTM,另一个是计算逆序上文信息的反向LSTM。通过这种方式,为每个时刻单词提供了完整的上下文状态信息。
图5中,在RCNN[15]结构基础之上进行改进,利用双向长短时记忆网络(Bi-LSTM)代替RNN,搭建Bi-LSTM-CNN网络结构。

图5 Bi-LSTM-CNN 网络Fig.5 Bi-LSTM-CNN network
使用双向长短时记忆网络后接一个卷积层和最大池化层,构成的Bi-LSTM-CNN网络结构,既解决了梯度消失或者梯度爆炸的问题,又能充分考虑当前词的上下文语义,信息得到的文本特征具有全局性,最后输入全连接层,通过softmax输出分类结果。
3 声学特征学习
3.1 语音信号预处理
语音信号的预处理分为三部分:语音采样与量化,语音分帧,信号加窗。
通过采样与量化将语音信号转化为计算机可以识别的数字信号,使用22.05 kHz 的采样频率对语音信号进行采样,采样结果如图6所示。
图6 数字化语音信号Fig.6 Digital voice signal
语音信号在短时范围内特征变化较小时可以认为是稳态信号,对语音信号进行分帧处理,帧长一般取10~30 ms。语音信号分帧通常需要加窗操作,窗函数可以减少因为截断带来的频域能量泄漏的影响。一帧语音信号经过汉明(Hanmming)窗处理前后的语音信号波形图变化如图7所示。汉明窗公式如下所示:

图7(a) 一帧语音信号加窗前波形图Fig.7(a) Waveform before speech signal transformation

图7(b) 一帧语音信号加窗后波形图Fig.7(b) Waveform after speech signal transformation
3.2 帧级低层次声学特征提取
使用开源软件openSMILE[16]工具包对音频进行帧级的低层次声学特征(low level descriptors,LLDs)提取,语音特征集配置文件由“IS10_paraling.conf”提供,共1 582个维度特征。其中包括34个低级描述符(LLDs),34 个相应的一阶delta 系数和21 个全局统计函数,具体参数如表1所示。

表1 openSMILE配置文件参数Table 1 openSMILE configuration file parameters
3.3 联合CNN模型
openSMILE工具提取的1 582维语音特征向量reshape为(1,1 582),经基于Bi-LSTM-CNN的语音文本双模态情感识别模型网络中卷积层_2 提取语音特征,与Bi-LSTM网络结构提取的文本特征进行特征层融合,结果输入CNN模型。该模型采用具有卷积层和最大池化层的简单CNN 作为特征提取器,输入的数据被放在一个密集层中。经过密集层的非线性变化,这些特征之间的关联性被提取并最终映射到输出空间。引入Dropout机制,每次迭代放弃部分参数,使训练过程不依赖部分固有特征,防止过拟合。通过约束添加的指标L2范数,可以适当地改善网络训练过程中出现的过拟合现象。具体计算公式如下:

其中,w表示模型权重。
4 数据融合与测试
4.1 数据融合
(1)特征级融合
组合文本和语音的特征信息[17],将文本特征提取的输出和音频特征提取的输出进行特征级融合。融合结果作为联合CNN模型的输入UD,UD的表达式如式(1)所示:

(2)决策级融合
本文提出的基于文本的Bi-LSTM-CNN模型和联合CNN 模型作为独立模型,将单个结果融合成最终的公共决策。决策级融合不会影响到各个模型之间的效果,并且有助于捕捉模型间的动态过程。
对不同模型赋予不同的权重值。给定语句在加权平均融合中输出的得分为:
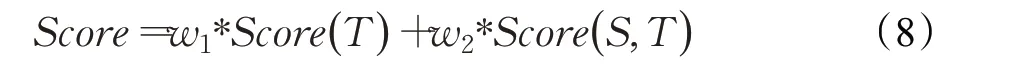
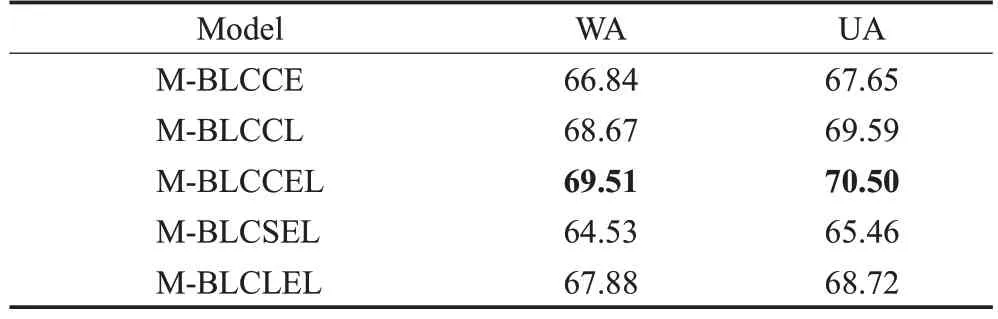
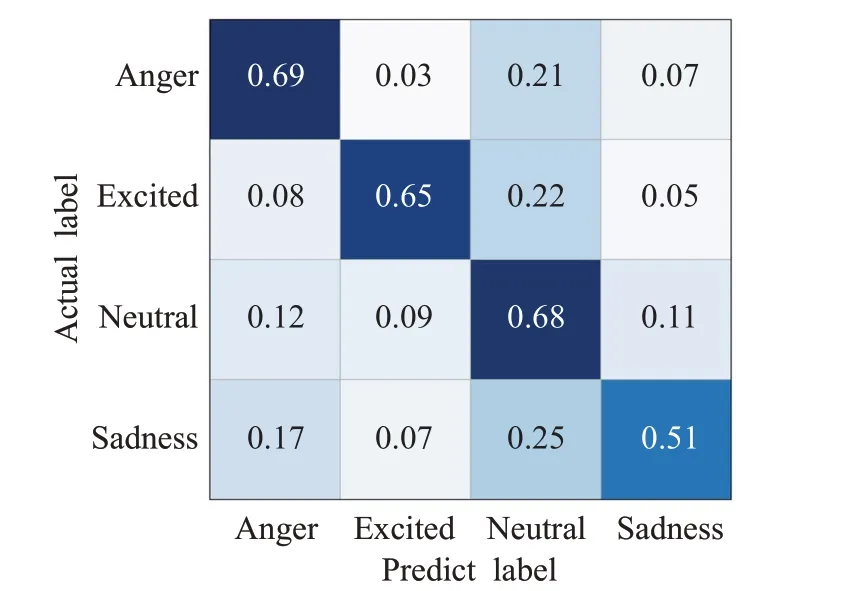
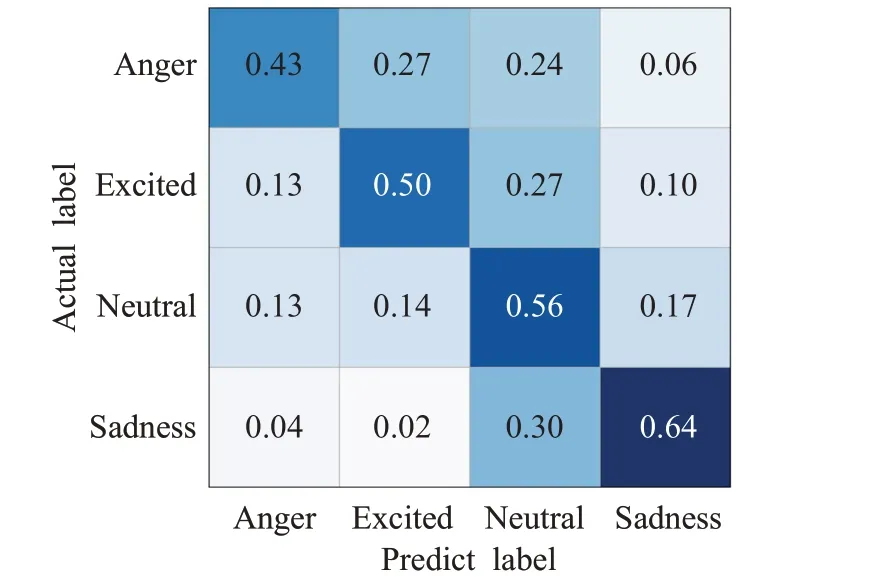
其中,0 实验验证的数据集选用IEMOCAP[18]数据集,数据集由5男5女两两分组进行录制。考虑到即兴型数据比表演型数据更具有实用价值,本文选择IEMOCAP数据集中的即兴数据作为实验数据集,使用四组数据作为训练集,一组作为测试集,对“高兴”“悲伤”“生气”和“中性”四类情感进行识别。 模型的评估指标采用加权精确率(weight accuracy,WA)和未加权精确率(unweight accuracy,UA)。WA是将每条语句赋予相同权重,直接计算其正确率,计算公式如下所示: 其中,N表示情感类别,TPi表示第i类情感分类正确的样本数,FPi表示第i类情感分类错误的样本数。 由于数据集情感类别的样本的分布不均衡,仅使用WA评价指标太过单一,样本数量较多的类别占据效果评价主导地位。因此,提出UA指标来综合平衡各个情感类别的识别性能,如式(10)(11)所示,先计算每个情感类别单独的准确率Acci,再取平均数得到UA。 基于文本特征的单模态情感识别模型,本文对比了Bi-LSTM、LSTM+CNN、Bi-LSTM+CNN 三种网络的情感识别效果;基于声学特征的单模态情感识别模型,比较了SVM、LSTM、CNN 的情感识别效果,其性能效果如表2所示。SVM核函数采用径向基函数(RBF),损失函数使用Hinge Loss,其惩罚项为L2正则化函数,误差项的惩罚因子C设为1,停止标准为0.000 1。LSTM网络主要结构包括LSTM 层、Dropout 层、全连接层,每个LSTM层有128个神经元节点,Dropout率设为0.5,激活函数使用softmax,优化器为Adam,损失函数采用交叉熵。CNN 网络由两层卷积层、池化层、两个全连接层、Dropout层及输出层组成,其中Dropout率设为0.5,网络的学习率设为0.001,中间层的激活函数为Relu函数,输出层的激活函数为softmax。 表2 单模态情感识别模型结果比较Table 2 Comparison of single model recognition accuracy results % 本文利用Bi-LSTM-CNN(BLC)网络进行文本特征学习,CNN进行声学特征学习,采用特征层融合构建双模态情感识别模型“M-BLCCE”(Bi-LSTM-CNN+CNN+early fusion,无图3中基于文本的CNN特征提取和决策层融合结构);使用决策层融合构建双模态情感识别模型“M-BLCCL”(Bi-LSTM-CNN+CNN+late fusion,无图3 中特征层融合结构);组合决策层和特征层融合的数据融合方式构成双模态情感模型“M-BLCCEL”(Bi-LSTM-CNN+CNN+early fusion+late fusion)。将“M-BLCCEL”模型中对声学特征学习的CNN网络替换为SVM、LSTM 网络,得到“M-BLCSEL”“M-BLCLEL”双模态情感模型。五种模型的识别结果如表3所示。 表3 语音文本双模态情感识别模型结果比较Table 3 Comparison of speech-text-bimodal model recognition accuracy results % 从表2 中可以看出,在单模态模型中,使用不同模型训练得出的识别率相差较大。对基于音频的情感识别来看,效果最好的是CNN 模型,其WA、UA 分别达到了52.77%、53.25%。对基于文本的情感识别来看,效果最好的是Bi-LSTM+CNN 模型,其WA、UA 分别达到了63.72%、63.25%。结合表2、表3,相比于单模态模型,混合模型的效果更好,本文所建立的双模态情感识别模型最终效果好于任意一种单模态模型,最终WA为69.51%,UA为70.50%。 Text-Bi-LSTM-CNN、Speech-CNN 和M-BLCCEL模型的混淆矩阵如图8~图10 所示。其中,横轴表示预测情感类别,纵轴表示真实情感类别。每一个彩格表示某情感语句级数据被预测为各类情感的概率,准确率越高,彩格颜色越深。 图8 Text-Bi-LSTM-CNN情感识别模型混淆矩阵Fig.8 Text-Bi-LSTM-CNN emotion recognition model confusion matrix 图9 Speech-CNN情感识别模型混淆矩阵Fig.9 Speech-CNN emotion recognition model confusion matrix 图10 语音文本双模态情感识别模型混淆矩阵Fig.10 Speech-text-bimodal emotion recognition model confusion matrix 如图8 所示,从Bi-LSTM-CNN 文本情感识别模型的混淆矩阵中得到,将“生气”“激动”“中性”“悲伤”标签语句预测正确对应的概率为0.69、0.65、0.68、0.51。将“悲伤”标签语句预测为“中性”类别的概率为0.25。可以看出文本情感识别模型对于“生气”情感的识别率最高,对“兴奋”“中性”的识别较高,易将“悲伤”情感识别为“中性”。 从图9中可以看出,语音情感识别模型得到的结果与文本情感识别模型正好相反,“生气”“激动”“中性”“悲伤”标签语句预测正确对应的概率为0.43、0.50、0.56、0.64。CNN语音情感识别模型对于“悲伤”情感识别更为准确,而对于其他情感类别的识别准确度较低,同时各类情感之间的混淆情况较为严重。 图10 为M-BLCCEL 模型的混淆矩阵,可以看出通过对语音、文本两个模态情感特征进行融合,提高了大多数情感类型的识别准确度,情感之间的混淆也得到了有效降低。根据图8~图10 三张图的对比,可以发现文本信息和语音信息之间的特征是互补的,表明了模态融合的有效性。 本文对IEMOCAP数据集中的文本、语音单模态信息建立了不同的训练网络进行情感识别分类,从中挑选基于文本的Bi-LSTM-CNN 网络和基于语音的CNN 网络进行双模态情感识别模型的搭建,在特征层和决策层对模态数据进行融合,利用L2 正则化约束防止网络过拟合,最终搭建出效果较好的双模态情感识别模型。实验效果证明,双模态情感识别模型的性能要远好于任意单模态情感识别模型。本实验提出的双模态情感识别模型侧重于文本模态的处理,对于语音模态特征信息的使用还不够充分。下一步可以从声学特征入手,更加充分地利用语音特征信息,提高双模态情感识别模型的准确率。4.2 实验结果与评价




5 结束语
