生成对抗网络在数据异常检测中的研究
2022-03-02庄跃生林珊玲林志贤张永爱郭太良
庄跃生,林珊玲,林志贤,张永爱,郭太良
1.福州大学 物理与信息工程学院,福州350116
2.中国福建光电信息科学与技术创新实验室,福州350116
3.福州大学 先进制造学院,福建 晋江362200
随着数据分析和数据挖掘领域的科学家对机器学习领域不断深入研究,异常检测逐渐成为当前研究热门问题。异常检测本质上是数据不平衡的分类问题,在信用卡的反欺诈、网络入侵检测、工业设备故障检测等生产生活领域应用广泛[1-3]。相比于大量存在的正常数据,异常数据的数据量少,并且和正常数据表达方式差异较大。由于数据极度不平衡,加上正常数据的特征和异常的数据特征差异较大,常用的方法训练难度大,往往无法对异常数据进行有效检测[4-5]。
1 相关工作
传统的异常检测法如重采样对数据不平衡样本进行预处理,通过下采样或者上采样的方式,使得数据达到平衡再输入分类器中训练,从而检测出异常数据[6]。但重采样会引入噪声,容易产生过拟合现象,对数据采样造成数据缺失而丢失有价值的特征信息,会对异常检测的分类效果造成极大影响。吴磊等人提出结合数据重采样方法,组合过采样和欠采样,通过对BSM 和CBOS进行数据清洗使数据平衡,实验结果比大多数据集和不同分类器不做数据清洗效果好,但无法捕获原始少数异常数据特征的复杂性[7]。
机器学习模型逐渐成为基准检测方法,在低维数据中,衡量相似度方法的模型性能突出。任家东等人提出结合使用K近邻(K-nearest neighbor,KNN)离群点检测算法检测并隔离离群数据,利用网络流量相似度原理,使用类比划分消除异常行为的干扰,再用多层次随机森林(random forest,RF)对网络入侵进行有效检测[8]。高维数据主要是控制数据维度,利用孤立森林(isolation forest,IF)或者主成分分析(principal component analysis,PCA)方法寻找好的空间表示,降低数据维度。徐东等人提出改进IF算法,用模拟退火算法选择精度高的隔离树优化森林,从而改进IF构建进行异常数据检测[9]。但这些方法的预测能力有限而且运算开销较大,无法在数据规模和维度比较大的数据集上进行有效检测。
近年来,深度学习在各个领域的研究都取得很好的进展,许多研究者将神经网络组合而成的生成对抗网络(generative adversarial network,GAN)模型应用到异常检测任务中。基于GAN的异常检测方法使用数据中大量的正常样本训练整个模型,生成足够多正常样本,同时输入少量异常样本训练生成对应的正常样本,通过比较GAN生成正常样本与异常样本对应生成的样本进行异常检测。因此基于GAN的检测方法无需收集大量异常数据,而使用正常数据训练就可以达到异常检测目的。此外,在医学图像处理中常用GAN进行数据补充,生成高质量图片辅助判别以解决数据稀缺和数据不平衡问题,从而达到异常图像准确分类效果。Schlegel 等人提出使用GAN进行医学图像异常检测,利用GAN的生成器从噪声输入中训练生成足够逼真图像,根据异常图像和生成图像间的差异训练判别器以更新输入噪声,最终生成一批和异常图像相似的正常图像,通过大量的图片对比进行医学影像异常检测[10]。Frid-Adar 等人使用DCGAN(deep convolutional GAN)合成肝脏CT 不同类别的病变样本,对于每个类别样本,训练独立的生成模型,对比传统的数据扩充方法如数据反转、裁剪等,其两个分类性能指标灵敏度和特异性分别提高7.1%与4.0%,因此通过GAN 进行医学图像数据扩充能够改善分类效果[11]。然而,使用GAN 无法控制生成样本的类型,同时利用GAN 进行图像异常检测需要一定人为经验做筛选比对,在图像研究领域成本极大[12]。GAN的许多变种如InfoGAN 通过使用连续隐编码能够捕获数据特征发生的细微变化,但其仍旧无法保证生成所需类别的样本,因此在高度数据不平衡的异常检测任务中,利用GAN做数据补充可能会产生极大的误差。
针对目前异常检测方法中存在的各种问题,在生成对抗网络基础上提出一种生成对抗网络组合随机森林(generative adversarial network-random forest,GAN-RF)的新模型,结合InfoGAN和推理神经网络分别生成数据平衡样本和样本所对应的标签,再使用第二个GAN 对推理神经网络进行标签生成优化,最后利用随机森林算法对整个模型进行优化,从而提高推理神经网络输出准确性。在多个数据集上实验表明,GAN-RF可以在异常数据量较少情况下进行数据扩充,并且针对GAN 及其变种InfoGAN 无法控制生成样本类别问题进行优化。相比于传统的数据补充方法,使用生成数据和真实数据直接训练分类器达到异常样本分类效果,GAN-RF使用生成数据辅助训练整个模型,利用推理网络对真实数据进行标签输出预测,以达到更高的推理准确率。同时克服高维、大规模异常数据检测的不稳定性,保留原始数据中的重要特征信息,对各个领域大规模数据中存在的少量异常数据的检测具有很好的应用价值。
2 GAN-RF的技术原理
2.1 生成对抗网络
GAN 的核心思想是一个“博弈过程”,主要包括训练两个模型,即一个能捕获数据分布的生成器和一个输出样本来源于真实数据或者生成数据概率的判别器。生成器的训练目的是学习生成数据分布以匹配真实数据的分布,而判别器的训练目的则是最大化正确分配真实样本和生成样本的概率[13]。整个网络的目标函数如式(1)所示。
其中,Pdata(x)和Pz(z)分别代表真实样本和生成样本的分布,z是输入噪声变量,G(z)是生成样本。同时训练生成器和判别器,在理想情况下,模型的目标函数收敛,生成样本的分布Pz(z)趋近于真实样本分布Pdata(x),判别器无法区分输入样本的来源。
2.2 InfoGAN
GAN 输入连续随机噪声z,无法通过控制z的某些维度与其数据语义特征相对应,即无法学到可解释性的特征。InfoGAN 在此基础上将原始输入噪声z分解为具有解释性的隐编码c与随机性噪声n,其中c还可分为控制生成样本标签的离散编码和控制数据维度特征的连续编码,生成样本表示为G(n,c);结合互信息论知识,令c与G(n,c)关联性最大,即两者互信息最大[14-15]。整个模型目标函数如式(2)所示。

其中,V(D,G)是GAN 的损失函数,如式(1)所示,I(c;G(n,c))是互信息项。Q是隐编码神经网络,通过使用变分分布Q(c|x)逼近互信息项中的后验分布P(c|x)计算得到互信息下界,互信息项改写成如式(3)所示。

此时互信息项就可由蒙特卡洛计算,或者使用重参数技巧计算G并通过Q预测出离散编码和连续编码的均值与方差,设定H(c)为常数项,从而实现最大化互信息项lgQ(c|x)。
由此整个模型目标函数可以改写成如式(4)所示。

2.3 随机森林与Hyperband算法
随机森林是最常用的分类模型。首先通过自助采样方法随机对原始样本进行抽样作为决策树根节点处的样本;之后对样本属性特征采用决策树信息增益计算方法作为分裂指标,并划分根节点直到叶子节点;重复以上步骤后完成所有决策树构建,组成完整的随机森林,并且决策树间互不关联;最后基于不同决策树的预测,使用投票法则获得最终得分并输出分类结果[16]。
传统的随机搜索(random search)、网格搜索(grid search)和基于贝叶斯优化(Hyperopt)的参数调整方法都存在某些弊端,如花费时间长,错失参数空间重要信息等;而Hyperband 算法搜索最优超参数速度快。Hyperband使用早停策略,输入每个超参数组所能分配最大计算资源和每次训练淘汰超参数组比例,在每次训练Hyperband丢弃部分参数组过程中,使用学习曲线拟合每组超参数组在验证集上的误差并计算对应概率值,当某一超参数组对应概率在特定阈值下达到最佳,则Hyperband停止最佳超参数组搜索,并以此概率作为该超参数组验证误差输出,因此能够极大提升搜索效率。实际上该算法是根据时间和数据特征、迭代次数等资源预算因素,选取合适的超参数组合数目与每个组所对应的分配资源间做优化权衡,在可行的超参数组合数量范围内,为每组超参数分配足够多预算资源以进行验证评估,根据评估结果淘汰特定比值参数组,剩下超参数组可分配的资源变大,之后反复迭代训练得到一组能够分配最大预算的超参数[17]。
3 模型构造
数据异常检测任务中对数据预处理通常分为下采样多数正常样本或者上采样少数异常样本,经过分类器训练,进而分离出正常样本和异常样本。然而,采样过程会引入噪声造成过拟合,无法捕获数据特征重要信息,而基准机器学习分类模型的性能指标往往会受到自身超参数影响。InfoGAN 网络训练生成样本也会产生一定的错误率,即无法完全控制生成样本所属的类别,如在Mnist 手写数字识别实验中InfoGAN 存在5%误差率。本文在此基础上进行改进,提出GAN-RF,避免数据重采样带来的各种风险,并且通过优化数据与标签的一致性来增强模型分类效果。模型整体结构如图1所示。

图1 GAN-RF模型结构示意图Fig.1 Architecture of GAN-RF model
第一部分为InfoGAN 网络数据平衡样本的生成过程。首先将输入噪声z分成连续随机噪声变量n与隐编码变量c,经过生成器G训练生成样本x′,将真实样本x和生成样本x′分别输入D中训练以区分样本来源;如此交替迭代训练使得x与x′足够相似,而D无法区分真假样本,即对任何输入,输出的概率都为0.5。通过神经网络Q约束c与x′关系,即最大化式(3)来控制生成样本特征和类别。为提高训练效率,Q和D除最后一层全连接层外,而其余网络层结构相同,模型训练的目标函数如式(4)所示。
第二部分为推理神经网络I,输入真实数据不平衡样本x,输出对应其标签的预测概率。令I和D共用除最后全连接层外的所有网络层。本质上将x送入推理网络训练是标签生成过程;采用交叉验证方法在训练集上训练,并在验证集上生成每个样本x对应的异常样本标签y′及其概率。该部分网络损失采用交叉熵函数,如式(5)所示。

其中,y是真实样本的标签,D(x)对应推理网络异常样本预测的概率输出。
第三部分是生成对抗网络结构的模型,主要优化推理网络的标签输出及其概率预测的准确性。具体来讲,将推理神经网络作为标签生成器,输入数据平衡样本x′并生成对应的数据标签y′,此后将生成数据标签组(x′,y′)和真实数据标签组(x,y)送入判别网络D2进行训练,该部分模型训练的过程和普通的GAN 网络一样。训练达到一定次数后,生成的数据标签组(x′,y′)和真实数据标签组(x,y)足够相似,而推理神经网络作为标签生成器对标签和概率输出更加准确。该生成对抗网络模型的目标损失函数如式(6)所示。
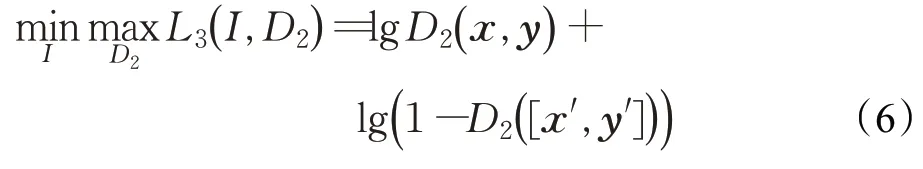
同时训练三个组合网络达到一定次数,推理网络输出样本预测的概率值,结合原始标签数据计算整个模型AUC(area under curve)值。
加入随机森林算法优化GAN组合网络。输入生成数据标签组(x′,y′)至随机森林,使用分层采样交叉验证训练模型,随机选取超参数组并通过Hyperband算法对模型进行调参,使用最优超参数组重复训练输出对应的分类结果,并同样结合原始数据标签计算模型的AUC值。对比两者AUC 值,如随机森林分类性能优于上述步骤模型,则重新同时训练三个网络模型直到优于随机森林。
其中对于随机森林的数据输入,利用树系模型特性计算对应数据的特征重要性,筛选掉相关性低的信息,结合分析数据中值得重点关注的特征,对GAN-RF的异常检测提供参考。
4 算法实现
4.1 GAN组合网络算法
GAN 组合网络算法如算法1 所示。首先输入真实数据标签组,并根据batch大小划分数据标签组,设置控制各个不同损失函数的权值参数λ,使模型在训练时不易产生过拟合;步骤1是对网络参数进行初始化;步骤4通过选取服从[0,1]均匀分布的隐编码向量c和噪声变量n输入到InfoGAN 模型,控制生成类别均衡样本;步骤5设置模型训练方式,采用EarlyStopping监控各个网络验证损失函数,经过一定的训练周期后,如果验证集误差不再下降,则该网络提前停止训练,进一步优化整个模型训练,避免网络训练过拟合;步骤6 至步骤10 主要采用随机梯度下降法去训练每个网络的损失函数,更新网络权重参数θ并得到最优解,使得损失函数收敛达到最小值;步骤11 至步骤12 验证EarlyStopping 并输出各模型网络权重参数θ;反之训练所有模型直至达到收敛,输出网络参数。整个过程为一个batch,根据数据量重复训练一定数量batch。
算法1GAN组合网络

4.2 随机森林与Hyperband算法
算法2在总预算资源B已知条件下,首先输入一个超参数组合,实际分配最大预算的参数R和每次迭代淘汰超参数比例参数η;步骤2按照batch大小随机抽取生成数据标签组(′,)训练Hyperband;步骤4是初始化控制总预算资源大小参数smax;步骤5 至步骤6 主要通过循环迭代选取smax范围内不同s值,根据得到的s值计算出在当前总预算资源下可选取最优的超参数组数目n和一个超参数组合实际所分配的预算r;步骤8是根据s大小做循环迭代,通过上述过程计算的r和n,以η为基准淘汰部分超参数组,r和n分别更新为ri和ni;步骤9返回每组超参数在对应验证集上的验证误差L;步骤10利用上述计算的L,选取误差最小的一组超参数;循环迭代训练步骤5至步骤12,根据不同smax、n、r计算每个循环中最小L的超参数组,并将得到的所有L进行整合;步骤13 选取整个循环验证误差L最小超参数组,在B不变条件下,该超参数组所能分配的实际预算ri也达到最大;步骤14 到步骤16 是更新随机森林参数,并通过5折交叉验证法训练得到整个模型的AUC。
算法2随机森林与Hyperband算法


5 实验和结果分析
5.1 实验准备工作
实验利用Pyod 异常检测工具库所集成的4 个标准数据集作为模型的训练验证数据,结合该工具库所包含的基准模型和本文模型进行实验对比。具体信息如表1所示。

表1 数据集参数信息Table 1 Details of datasets
为防止过拟合问题,对所有实验的数据采用分层采样(StraifieldKfold),即原始数据按标签比例拆分为5组,其中1组子集数据作为模型验证集,其余4组子集数据作为模型训练集数据,并且重复以上步骤5 次,在所有验证集上评估结果,有效利用数据集。
5.2 实验数据处理和评估指标
模型的评估采用AUC 值、精确率(precision),各个指标的计算涉及到混淆矩阵相关概念,其组成部分如表2所示。

表2 混淆矩阵Table 2 Confusion matrix
表2 中,TP代表真实类别为正样本而预测类别为正样本数量;FP代表真实类别为负样本而预测类别为正样本数量;FN代表真实类别为正样本而预测类别为负样本数量;TN代表真正类别为负样本而预测类别为负样本的数量[18]。可通过混淆矩阵计算得精确率Precision=TP/(TP+FN);而AUC值是接收者工作特性曲线(receiver operating characteristic,ROC)下的面积,ROC 曲线的横轴为假正率FPR=FP/(FP+TN),纵轴为真正率TPR=TP/(TP+FN),AUC 相比精确率更加考虑分类器对于正样本和负样本的分类能力,在数据不平衡条件下依然能够对分类器合理预测。
通过5折分层采样将数据划分,利用随机采样将训练集中两个类别数据对应的索引分别可重复抽取相同大小数据;令生成器G生成的数据与抽样的数据维度相同,将两者输入到D中训练;而推理网络I输入数据保持与G生成数据的维度一致;数据标签组的维度是对应输入数据与其标签的维度拼接,输入数据标签组到D2训练以优化推理网络的输出;整个过程重复5次,每次将验证集输入推理网络中输出概率和标签。将模型生成的数据平衡样本经过数据清洗和5 折分层采样后输入随机森林训练,输出结果和经过Hyperband优化后比较确定推理网络的最优输出。
5.3 网络结构设计
组成模型的网络结构均采用全连接层。以Mnist数据集为例,InfoGAN 的生成器组成包含4 层网络层;其中输入层有64个神经元,后3层隐藏层分别含128、512、1 024 个神经元,输出层神经元个数为100;神经网络Q与判别网络D共用前4 层网络层;同样推理网络与D共用全连接层便于模型训练;而判别网络D2输入数据标签组需要进行维度拼接;整个模型的输入是服从[0,1]均匀分布的63维的噪声向量z和1维的编码向量c。具体信息如表3所示。
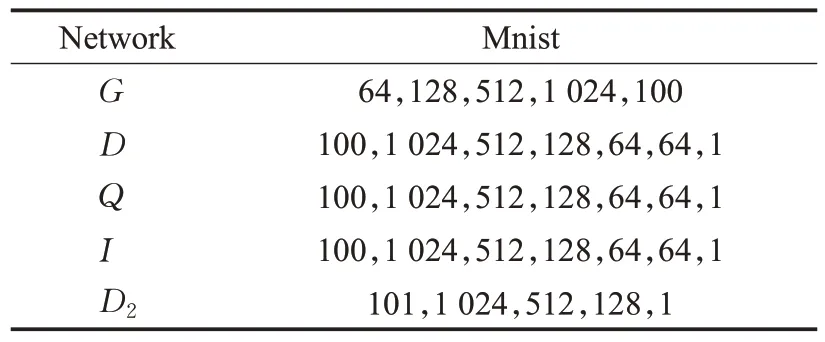
表3 模型的网络结构Table 3 Network structures of model
5.4 实验结果与分析
在Mnist数据集下,随机森林的输入为G生成的样本x′与经过推理网络I生成的标签y′;之后使用3 个常用超参数搜索法与Hyperband对随机森林进行调参,各个方法所耗费的时间成本和更新参数后的AUC输出如表4所示。

表4 Mnist数据集随机森林调参Table 4 Random forest tuning in Mnist dataset
表4中选择的参数分别是最小样本叶片大小(min_samples_leaf)和决策树数目(n_estimators)。由表中数据可得,Hyperband 训练迭代得到的最优超参数经过训练后输出的AUC为0.939,相比于次优的贝叶斯优化提高了0.01,而随机搜索的结果最差。计算耗费成本方面,网格搜索耗时最长达到184.33 s,并且该时间随着候选参数的增多而变大;随机搜索虽然耗时短,但容易忽略掉参数空间中的重要信息特征;Hyperband 算法同等条件下训练耗时42.11 s,比贝叶斯优化短,因此其所消耗的成本与计算资源最低;其中训练耗时也与计算机硬件条件相关。综上比较可得出Hyperband 综合表现优于传统方法。
分别使用5 个基准模型:基于统计概率的KNN、基于线性模型的PCA、基于半监督的OCSVM、基于相似度衡量的LOF以及基于集成算法的IF,对GAN-RF的异常检测效果进行评估。利用精确率分析预测为正常样本中实际为正常的概率,并用ROC曲线下面积AUC 综合评估模型的分类效果。
表5和表6是5个基准模型和GAN-RF在不同数据集中训练得到精确率和AUC 值信息,其中加粗的值为当前数据集中最优指标。在精确率方面,GAN-RF 在cardio 和Mnist 数据集上达到的最佳精确率分别为0.59和0.83;在wbc 数据集中表现接近最优,达到0.46;而在letter数据中精确率排名也相对靠前;由此说明GAN-RF对于正常样本预测相对于其他模型效果也有一定提升。在AUC 方面,GAN-RF 在cardio、Mnist 和wbc 数据集上都排名第一,分别为0.98、0.99、0.92,其中在Mnist数据集上比次优模型提高了0.14,在letter 数据集中该模型表现也相对出色。
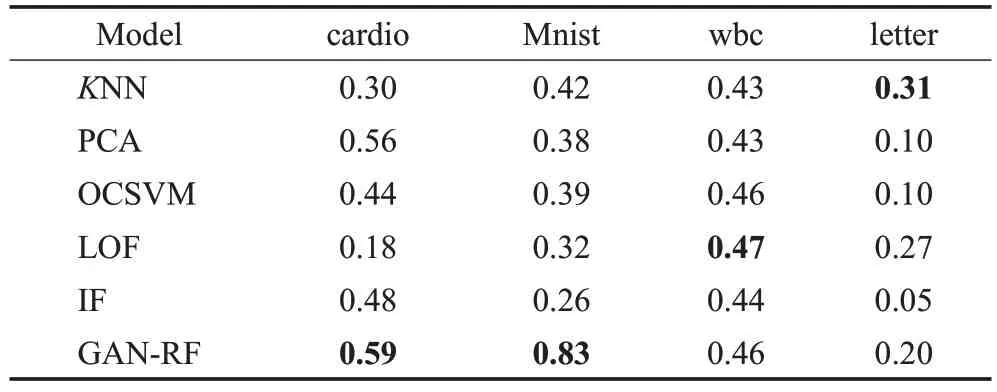
表5 各个模型的Precision值Table 5 Precision value of different models

表6 各个模型的AUC值Table 6 AUC value of different models
图2 是各个模型在Mnist 数据集中的ROC 曲线图,可以看出GAN-RF的ROC曲线最靠近左上角。当ROC曲线靠近左上角时,FPR=0,TPR=1,根据TPR 和FPR 计算公式可知,此时FN=0,FP=0,即模型对所有样本分类正确。综上可得,GAN-RF对异常样本和正常样本的分类比其余任何基准模型较为出色。
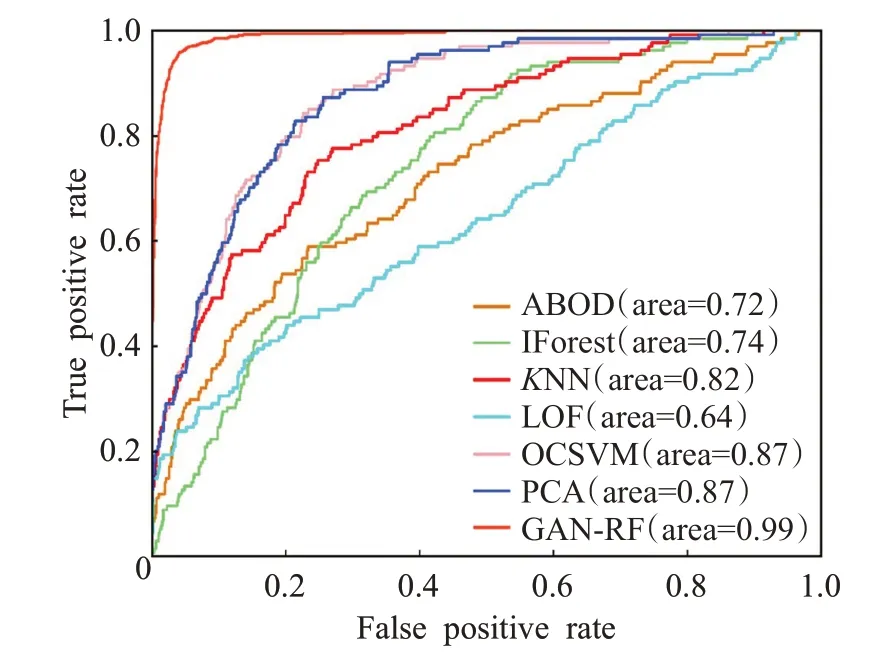
图2 Mnist数据集中各模型的ROC曲线图Fig.2 ROC curve of different models in Mnist dataset
图3是GAN-RF在Mnist数据集下对异常数据的概率预测折线图。其中横坐标代表样本所在位置索引,纵坐标代表预测概率值,红色直线代表实际异常样本所在的位置,蓝色折线是GAN-RF模型异常样本预测概率输出的折线。从图2可以看出,异常样本密集分布位置为7 000 的两侧,而GAN-RF 模型对于异常值区间预测的准确率普遍较高,从而连接成密集的折线段。综上进一步证明了GAN-RF对于异常样本有很好的区分能力。
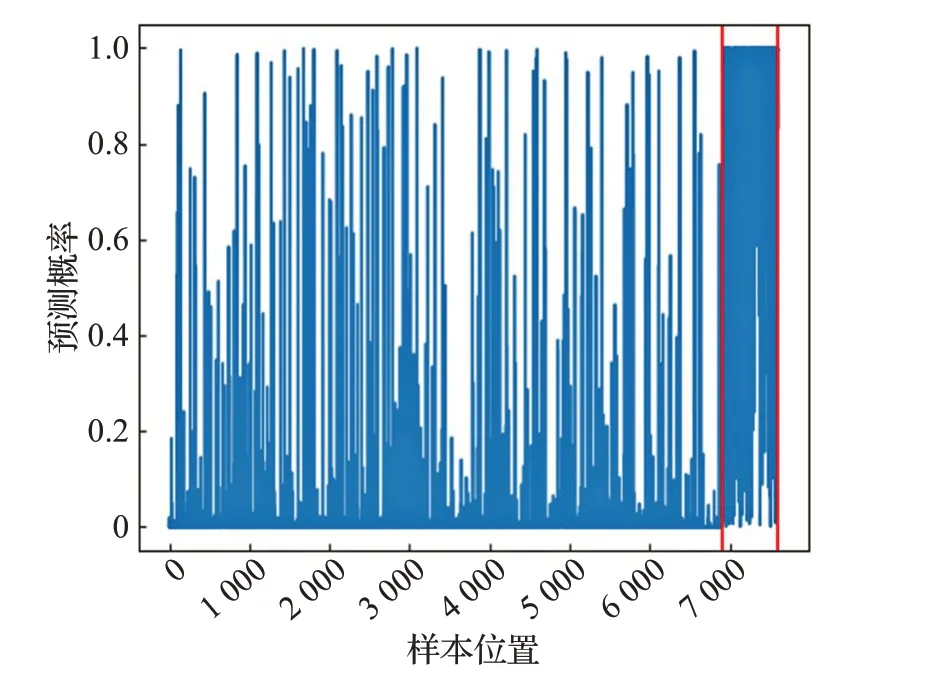
图3 Mnist数据集中异常值预测区间折线图Fig.3 Line chart of outlier prediction value in Mnist dataset
6 结束语
本文提出了一种基于生成对抗网络的异常检测模型。首先使用InfoGAN模型生成数据平衡样本;接着构造一个推理神经网络进行样本标签的生成及其概率输出;之后将推理网络作为生成样本的标签生成器,将真实样本标签组和生成样本标签组输入一个判别器反复迭代训练,优化推理网络标签生成及其概率输出的准确率;最后将生成样本及标签送入随机森林做分类,结合Hyperband 算法对模型进行调参,并将输出结果与推理网络输出进行比较,不断迭代优化推理网络,使得模型对于异常样本能够有效预测。实验将Hyperband 算法的调参与其他3个方法进行比较。在4个标准数据集上和5 个基准模型做比较,实验结果表明,本文提出的GAN-RF 在3 个数据中都取得最佳的AUC 值,其中在Mnist 数据集上相比于次优的模型KNN 提高了0.14。因此本文提出的模型的综合性能高于常用的基准机器学习模型,并且将图像处理中应用广泛的生成对抗网络移植到异常检测中,对于该领域具有一定参考价值和经济效益。
