DB2容灾技术探讨
2022-03-02徐霞婷
徐霞婷
(苏州旅游与财经高等职业技术学校,江苏 苏州 215104)
信息化时代下,数据成为继化石能源之后的重要的资源。当今社会,很多东西都可以数据化,比如存在银行里面的钱,在银行卡上体现的就是一组数据;又比如某宝上的交易订单,提交到商户那边的也是一组数据。在我们日常生活、生产过程中,很多传统的东西渐渐被机械化、电子化取代,数据成为其中重要的凭证,一旦丢失,后果不堪设想。因此,在面对自然、人为的破坏,我们要对数据做好备份。而数据库作为数据的重要存储仓库,很多数据库系统软件为防止数据丢失也提供了相应的容灾技术。本文将介绍IBM DB2数据库的容灾技术——HADR和DPROP。
1 DB2数据库简介
市面上的数据库产品有很多,有传统的关系型数据库,如Oracle、DB2、SQL Server等,还有近年来兴起的非关系型数据库,如Redis、MongoDB、Neo4j等。而DB2作为经典的主流数据库,广泛应用于金融、通信、烟草等领域[1]。
一个版本的DB2软件(DB2 Copy)下可以创建多个DB2实例(Instance),一个DB2 实例可以创建多个数据库(Database),但是一个DB2数据库只能属于一个实例,它们之间的关系如图1所示。在安装完DB2软件之后,必须先创建DB2实例,然后才能在实例下创建数据库。DB2实例又叫数据库管理器(Database Management Application),是管理数据的DB2代码[2]。而DB2数据库同其他关系型数据库一样使用表来管理和存储数据。DB2实例和数据库的关系,好比锁和柜子的关系,数据库好比柜子,实例好比锁,有了锁才能打开柜子,没有锁,柜子还在却没法打开;所以说,只有DB2实例运行时才能访问数据库;DB2实例如果挂起或者停止了,数据库还在,但是不能访问[1];DB2实例如果被删除了,数据库并不会被一起删除。
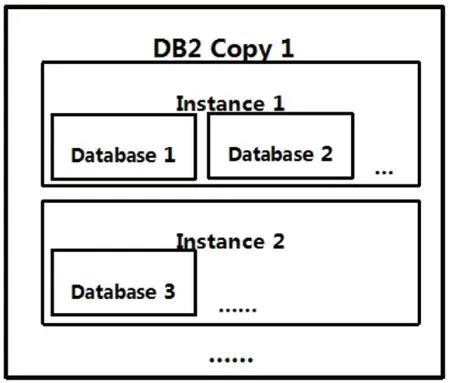
图1 DB2软件、实例和数据库关系图
2 HADR
DB2 HADR是数据库级别的灾备,需要2个数据库,一个是主库,一个是备库,主库同标准数据库一样可以进行增删改查操作,而备库只能进行查询操作(前提是需开启读功能,通过db2set DB2_HADR_ROS=ON进行设置,重启实例生效)。在创建之初,备库是主库的一个克隆,两库完全相同;在数据库运行之后,主库通过将自己的日志传送给备库,备库接受主库的日志后再应用相关事务的方式来保证与主库的一致性,主备之间通过TCP/IP进行通行,如图2所示。主备之间有三种同步模式,分别是SYNC、Near SYNC、ASYNC。SYNC同步模式是,当主库的事务提交,表示主备库都完成相关事务,这种模式性能影响较大,生产环境中较少使用;Near SYNC同步模式是,当主库的事务提交,表示备库已收到主库发来的日志,这种模式备库可能会出现数据丢失的情况;ASYNC同步模式是,当主库的事务提交,表示主库已将日志发给备库,这种模式没法保证备库一定收到日志。
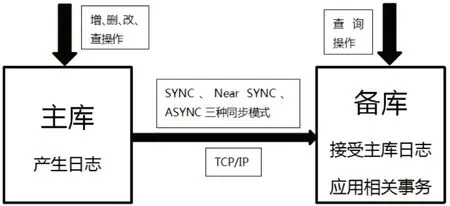
图 2 HADR架构图
HADR对环境有一些要求,它需要主备库拥有相同的操作系统版本和DB2软件版本。备库没法进行备份操作,而日志归档也只能发生在主库上。
搭建HADR,首先需要在主机上做一个全备份,然后把这个备份文件在备机上做恢复,最好保持主备的数据库名字一致,另外,备库恢复后,让它处于rollward状态。然后,配置HADR,主备机IP地址信息、专门HADR端口号、实例名、同步模式等信息。需要设置专门HADR端口号,主备库日志传输是通过这个专门的HADR端口进行的。主备库之间的同步模式,即用SYNC、Near SYNC、ASYNC三种中的一种进行数据的同步。最后,在备机上启动HADR,如db2 start hadr on db dbname as standby;再在主机上启动HADR,如db2 start hadr on db dbname as primary。至此,HADR在主备机上完成搭建。
HADR主备库之间的角色可以进行切换,即让主库成为新的备库,让备库成为新的主库。当需要切换主备库时,在当前备库上使用db2 takeover hadr on database dbname这条命令即可。切换之后,原先主库成为新的备库,由于在备库上最多只能进行读操作,连接在上面的应用就会被中断,这个时候,需要把应用的连接切换到新的主库上,可以选择手动重新连接,也可以启动客户机自动重新路由的方式。当设置好自动重新路由之后,应用所在的客户机也与主机连接成功过并获得备用服务器信息了,那么,如果客户机和主机上的数据库之间发生通信错误,客户机在尝试重新连接失败之后会尝试与主机上的备用数据库建立连接。
在HADR环境下DB2的启停也有讲究。如果需要停止DB2,比较推荐的方式是先停主机上的DB2,再停备机上的DB2;如果需要启动DB2,先启备机上的DB2,再启主机上的DB2。如果需要去除HADR,在主备机上分别执行db2 stop hadr on db dbname即可,原先建立HADR关系的2个数据库也就成为标准数据库。
3 DPROP
DPROP又叫SQL Replication,也是基于日志进行数据复制备份的。它通过Capture和Apply程序实现从源端到目标端的复制。源端和目标端,可以是数据库之间,也可以是表之间,或者是表的某几个字段之间进行SQL复制,并且源端和目标端数据库不一定是DB2数据库,其他数据库也能使用DPROP技术。Capture程序运行在源系统中,它通过读取数据库的日志文件来发现数据库中发生变化的数据,并把这些变化的数据保存到中间表(CD表,即change-data table)中。Apply程序一般运行在目标系统中,但也可能出现在源系统中,它从中间表中获取数据并把数据保存到目标表中;在这个过程中,如果Apply和CD表不在同一个系统中,Apply就通过一个设置在密码文件中的ID和密码连接到CD表所在系统,该ID是Apply获取CD表中数据的方式。DPROP可以是单向的也可以是双向的。单向DPROP架构图如图3所示。在双向DPROP中,复制的两端(记为A端和B端)都需要Capture来获取变化数据,而Apply程序既负责把A端变化的数据复制到B端,也负责把B端变化的数据复制到A端。
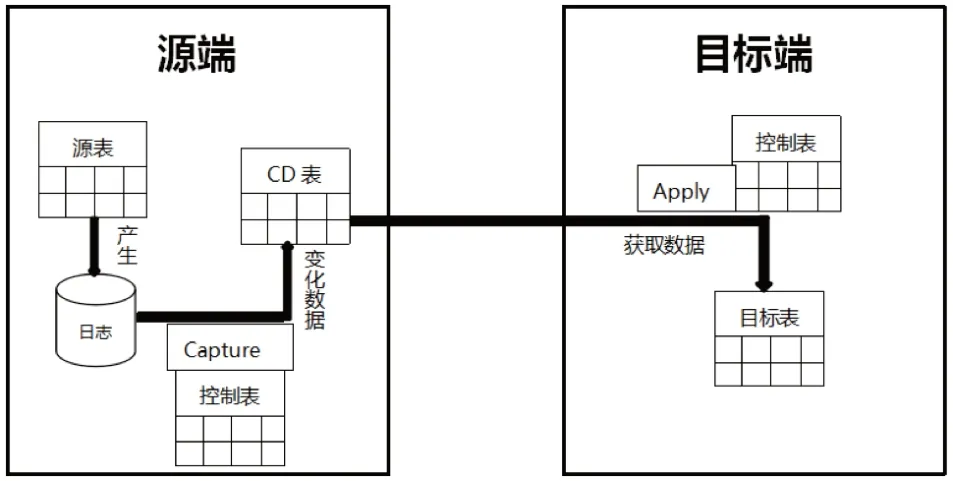
图3 单向DPROP构架图
双向DPROP存在数据改动冲突,DPROP在创建时就会设定好主表和复制表,当主表和复制表发生变动冲突时,以主表的变动为准。双向DPROP设定了相关的冲突检测机制,Apply程序会将主表的CD表中的键列值和复制表的CD表中的键列值进行比对,假如两边的CD表存在相同的键列值,将被视为冲突;为防止这类数据冲突的发生,Apply程序在复制表的CD表中读取到这类数据时,会撤销先前事务对复制表提交的修改,并只保留来自主表的修改。
搭建完DPROP之后,第一次启动需要进行一次全刷,Capture冷启动,将源表中的数据全部复制到目标表中。全刷成功之后,Capture转冷启动为热启动,这时DPROP只将源表中变化的数据复制至目标表中。DPROP的启停类似于HADR,比较推荐的方式是,先停Capture再停Apply,先启Apply再起Capture。
4 HADR和DPROP的对比
HADR和DPROP作为DB2数据库中搭建灾备系统可选方案,技术上都较为成熟,两者也存在着不同。
(1)HADR是数据库级别的灾备,没法实现单独表之间的复制。而DPROP既能实现两个数据库之间的复制,也能实现单独两表、表中某几个字段之间的复制备份。
(2)拥有HADR特性的两数据库,在备库上最多只能进行读操作。而拥有DPROP特性的两数据库都能像标准数据库一样正常使用。
(3)拥有HADR特性的两数据库,主备库之间可以切换角色。而拥有DPROP特性的两数据库,源端和目标端没法自由切换角色,除非重新构建两者之间的关系。
(4)拥有HADR特性的数据库之间需要配置专门的HADR端口号供两边通信使用,没有专门的连接ID,主库是主动将日志推送到HADR专用端口的。而拥有DPROP特性的数据库之间,需要有专门的ID用于两者的数据传输,Apply程序主动获取CD表中的数据。
(5)HADR搭建较为简单,DPROP搭建较为复杂。
5 结束语
数据作为信息化时代下重要的资源,日常需要做好备份,重要数据在数据库级别要搭建灾备环境。IBM DB2作为经典老牌数据库,容灾技术较为成熟,本文所介绍的HADR和DPROP就是DB2中成熟的容灾技术,是搭建数据库级别灾备环境的不错选择。■
