基于FPGA深度学习的行人重识别研究
2022-03-02李王辉白钢华李素娟
李王辉,白钢华,李素娟
(鹤壁职业技术学院,河南 鹤壁 458030)
0 引言
近几年,随着生活水平的提高和科技的进步以及众多公共场所的人流量的持续增加,公共场所的安全防控和犯罪调查应用也越来越广泛,但是在多个摄像头搜集到目标人物信息后还需要进行重新匹配和识别,当前受拍摄角度、光照强度等因素的影响,大多采用人工的方式对信息进行提取,这不仅会消耗大量的人力物力,而且还无法保证其准确率,基于FPGA深度学习的行人重识别的研究应运而生[1]。
基于FPGA深度学习的行人重识别是在深度学习的技术下利用计算机视觉技术对特定图像中行人目标进行判定的研究,能够通过已知的所监控行人的图像,来实现对行人图像的搜索,这极大地提高了视频监控的自动化、智能化水平,为日后更进一步研究打下良好的基础,提高解决失踪儿童的寻找、公共事件的解决等问题的效率,推动城市建设朝着智能化方向发展。本设计采用深度学习的卷积神经网络方法,在FPGA硬件上实现对行人重识别技术的研究,提高对行人的检测和识别能力。
1 概述
1.1 深度学习概述
深度学习是指计算机模拟人脑对图像数据分析的方式而设计出来的神经网络模型。它并不是人们认为的一种仅仅只是相比较传统学习算法更深层次的机器算法,这里的深度是指相较之前的更深更广的神经网络。这种深度学习减少了人们在设计上的工作量,极大地提高了计算机视觉自动学习针对特征提取的方法,同时将这一方法应用到模型训练上。目前,图像识别与检测的算法大多基于深度学习中的卷积网络[2]。
1.2 Improved DL网络结构
Improved DL网络是使用暹罗结构的卷积神经网络来进行图像特征提取的。在使用该网络的过程中根据每个图像之间的不同点,利用柔性函数来对两者之间的相同之处进行比对,利用softmax公式的概率计算方法来判别相似度。
2 基于FPGA深度学习的行人重识别算法
2.1 行人重识别基本框架
本研究主要是研究行人重识别的相关问题,利用相关的图像识别模型,从已建立的图像数据库找出相似度最高的图像。如图1所示。从图1可知,针对行人重识别的步骤主要由两部分组成:一是针对待查询图像的特征进行提取,然后根据特定的网络将提取的特征进行处理,输出符合距离度量要求的图像特征。二是距离度量,将第一步得到的图像特征与从数据库提出的相对比,识别两者之间的相似度,从而判别所查询的图像是否与候选库中的行人是否为同一人。
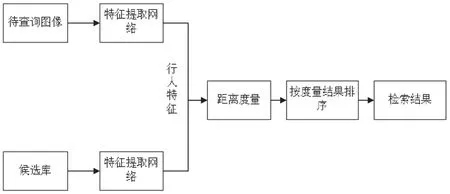
图1 行人重识别流程图
2.2 损失函数
本文利用改进后的Improved DL网络结构,通过利用所输入的160×60的行人图像,通过对网络结构的流程设计,最后用softmax公式来预测输入图像与模型的相似度。softmax损失函数多被用于解决多分类问题。行人重识别问题也被视为多分类问题。目前,softmax损失函数被广泛用于各种基于深度学习的行人重识别方法中。本章也将softmax函数作为损失函数来完成分类任务。
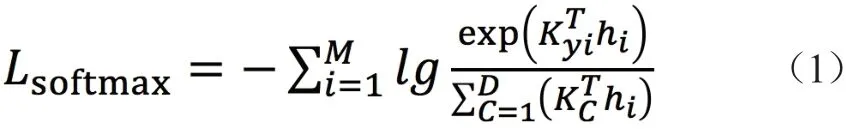
在网络结构中,行人重识别问题被视为多分类问题,对于第i个学习到的特征,softmax损失函数如下:式中,KC是类c的权重;D是在训练集中包含的行人身份类的数量;M是在训练进程中的一个批量图像集的大小。在Improved DL网络模型中,提取出来的特征皆在softmax损失函数中被使用。Improved DL的总损失函数则是所有损失函数的总和。
2.3 行人数据准备
本研究是利用Market-1501数据库来对本次网络结构进行测试,部分示例如图2所示。

图2 Market-1501数据库部分示例图
为防止在比对样本时出现过拟合现象,本研究需要对简单图像的选取范围扩大,同时利用平移变化技术,提高数据识别的准确度。
2.4 行人重识别评价标准
在行人重识别中,测试阶段将待查询目标行人图像与候选图像集中的每一个图像进行相似性比较并排序。若在相似性序列中存在与待查询目标行人身份相同的图像,则表示匹配成功,其匹配成功的行人图像在相似性序列位置的越前端网络模型性能越好。因此,在相似性序列中前n范围内匹配成功的图像数量与序列中行人图像总数的比值大小被称为累积匹配率Rank-n或Top-n。在这里n通常取值为1,5,10,20。例如,Rank-5代表相似性序列的前5中有待查询目标行人的概率。本文中所运用的行人重识别评价标准是利用最常用的rank-1和CMC曲线来对比本文所涉及的改进后的Improved DL网络结构的性能,以此对行人识别的准确率进行评价[3]。
(1)rank-1是第一匹配率,是指第一张图像的平均正确率,它是按照相似度对查询到的匹配图像进行计算,这是评价所识别模型的性能最直观的指标之一,其数值越高表示该模型识别能力越强。
(2)CMC曲线是对整个行人图像识别的横向比较,表示的是从第一张到第n张的识别准确率的概率,从而也证明了此识别模型的检索能力,也验证了所使用模型的优越性[4]。
2.5 FPGA实现
以往利用通用处理器或图像处理器来对深度学习方式进行实现,但是这种方式虽然能够满足一般性能,但是CPU计算能力有限,很难满足更高效更快速的运算能力,而GPU的灵活性差,只能进行单一的调用,无法实现多个数据平行调用的处理。FPGA的出现能够很好的解决上述问题,其独特的优势有效地实现了算法的硬件加速。
本研究通过对硬件电路的设计,在经过软件模型训练后转化到硬件电路上,利用FPGA硬件加速,实现对行人重识别的目的。如图3所示。
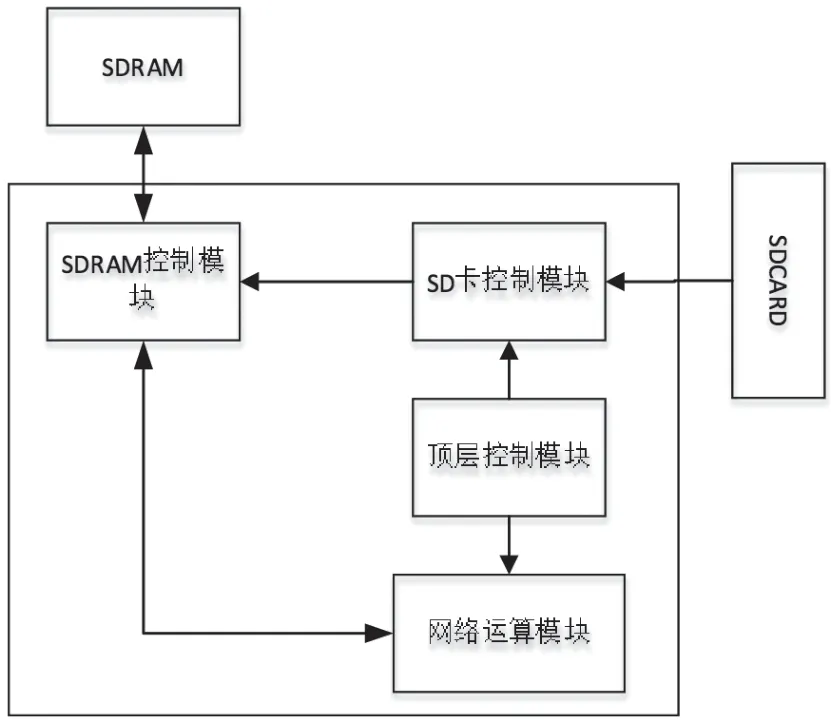
图3 FPGA硬件结构图
其研究主要分为三个模块:
(1)SD卡控制模块。本模块主要包含两个功能模块:初始化和读取。SD卡控制模块与SD卡之间通过SPI通信接口连接,首先是发布初始化命令对SD卡进行初始化,完成后,执行读取操作读取SD卡中的存储的网络参数和行人图像。
(2)网络运算模块。网络运算模块是FPGA硬件的重要运算核心,它内部的各个模块彼此之间相互配合相互独立,共同实现运算功能。
(3)顶层控制模块。顶层控制模块将网络运算模块与SD卡模块相连接,控制两者间的数据传输和控制。处理好各个网络运算模块的数据传输才能实现顶层控制模块的逻辑功能的更优化设计,才能实现整个FPGA硬件的功能。
3 算法分析及结果分析
3.1 实验参数配置
实验之前首先要对参数进行配置。首先优化网络输出的平均损失,反向计算mini-batch上的梯度,同时更新网络参数,在训练过程中不断改进,直至所得数据曲线收敛为止;然后用正负样本的方式进行对比,同时按照1∶1的比例进行100 000次迭代;最后采用单例查询设置进行测试。
3.2 实验结果分析
本研究选择rank-1匹配率及CMC曲线对所得的实验结果进行分析,得出此次测试的有效数据指标。利用改进后的网络与原来的Improved DL网络的对比,取Rank-n的最大值为20,而后继续进行试验。将所得的所有的试验结果绘制成CMC曲线图。如图4所示。

图4 CMC曲线对比图
由图4可知,本文选用的网络的rank-1的数值略低于原有Improved DL网络,但是对于rank-n的数值增加,两者的数值趋于一致,由此可得,改进后的网络对rank-1的影响较小,重合度高,其性能基本一致,也证明了本研究的必要性。将本次结果与LMNN, MCML,ITML, KISSME, XQDA的网络进行对比。
通过实验对比可知,本文所选用的网络匹配率为55%,相比较其他网络都有较高的优势,这就证明了本次所选网络的优越性,同时从数据上也显示出了本次所选FPGA与深度学习技术在行人重识别中发挥的重要作用。
4 结束语
本文是以FPGA为核心硬件,通过深度学习的Improved DL网络来对行人重识别算法进行改进研究,通过数据证明了本研究的必要性。基于FPGA深度学习的行人重识别研究还需要进一步去研究,不仅是要提高深度学习技术能力,还要对FPGA进一步优化,以求设计出功能更为强大、性能更为优越的行人重识别算法,推动行人重识别的发展,为保障公共安全、寻找失踪儿童等做出更大的贡献。相信随着FPGA加速深度学习技术研究的成熟,FPGA硬件加速器将被应用到更多的领域中■
