基于孪生神经网络的小样本人脸识别
2022-03-02万立志张运楚葛浙东王超
万立志张运楚葛浙东王超
(1.山东建筑大学 信息与电气工程学院,山东 济南 250101;2.山东省智能建筑技术重点实验室,山东 济南 250101)
0 引言
快速人员身份鉴别已成为当下社会安全和日常业务流程的重要技术手段,生物特征识别成为研究热点,其中人脸识别因其准确度高、非侵入性和低成本等优点,得到充分关注和广泛应用[1]。人脸识别需要大量人脸数据作为训练样本,然而在很多应用场景中获得的人脸数据有限,且存在各种剧烈的脸部变化,如光照、表情和遮挡等[2]。若训练样本缺少,识别准确率会有很大降低[3]。因此,学者们提出研究小样本人脸识别方法,在人脸训练样本较少的情况下,可以归类人脸身份[4]。
基于深度学习的卷积神经网络(Convolutional Neural Networks,CNN)能从特征图的低层到高层逐步提取代表人脸的高级语义化特征,已广泛应用于人脸识别。SUN等[5]采用卷积神经网络提取人脸深层次特征,构造DeepID算法进行人脸验证。SCHROFF等[6]提出了Facenet模型,将人脸图像映射为一个128维的特征向量,并使用三元组损失Triplet loss增大类间差距、缩小类内差距,以提高模型性能。TAIGMAN等[7]提出了DeepFace算法,通过引入了三维人脸模型对有姿态的人脸仿射对齐,提高了识别精度。由于存储容量的限制以及采用全局平均池化会使精度下降,移动设备较多地采用MobileNet或者ShuffleNet等模型进行人脸识别。张子昊等[8]改进了MoblieFaceNet网络,考虑到人脸图像中心和边缘区域应具有不同的权重,故将全局深度卷积替代全局平均池化,让网络自主学习不同点的权重值,从而提高人脸识别精度。在孪生神经网络应用于手写笔迹识别后,张国云等[9]将其应用于人脸识别领域,通过比较两张人脸图像映射的特征向量之间的欧氏距离,从而完成人脸比对相似度。利用对比损失函数组合原始数据,创造了指数级别的数据量,解决了小样本的数据量问题。但是,由于采用黑白图像训练,并且采用传统的卷积神经网络模型,因此准确率不高。
在损失函数设计方面,由于传统的交叉熵损失函数(Cross Entropy Loss Function,CELF)仅关注于类间特征可分,不能很好地表示最小化类内距离,因此王灵珍等[10]在交叉熵损失函数的基础上联合中心损失函数(Center Loss Function,CLF)作为联合损失函数进行模型优化。为了让特征学习到更可分的角度特性,LIU等[11]利用角度距离在交叉熵损失函数的基础上提出了角度损失函数(Angular Softmax Loss,A-Softmax),利用大角度间隔将类别分开。WANG等[12]利用余弦距离在A-Softmax损失函数的基础上提出了加性间隔损失函数(Additive Margin Softmax Function,AMSoftmax)。DENG等[13]考虑到角度距离比余弦距离对角度的影响更加直接,在AMSoftmax损失函数的基础上进行改进并提出了加性角度间隔损失函数(Additive Angular Margin Loss Function,Arcface),将特征向量归一化到超球面上,使模型在角度空间对分类的边界进行最大化,用以解决不同特征向量大小对分类效果的影响。
综上所述,人脸识别领域中,利用深度学习模型进行的人脸识别在准确率上较高,但是模型的训练过程需要大量的图像数据作为训练样本,需要很高的硬件和时间需求。在没有足够样本进行训练的情况下,CNN模型不能够很好地收敛运行,或者出现过拟合现象。文章在深度学习理论的基础上,提出了一种引入混合域注意力机制(Convolutional Block Attention Module,CBAM)的孪生神经网络模型,在预训练Inception-Resnet V1的模型中选择卷积层作为特征提取网络,根据实验测试将输出映射至特定维度的特征向量空间中;通过度量学习的损失函数来优化模型,最终模型在小样本的情况下使得同一人脸图像距离减小,不同人脸图像距离增大。文章以准确率为指标,与传统模型进行对比实验,以期验证所提出的模型比起传统方法有较好地提升。
1 神经网络知识概述
1.1 多任务卷积神经网络
多任务卷积神经网络(Multi-task Cascaded Convolutional Networks,MTCNN)是一个基于深度学习的人脸识别方法,将人脸区域检测和人脸关键点检测联合实现,采用3个串行连接的卷积神经网络,每个卷积神经网络均完成人脸检测、人脸对齐和检测框回归3个任务[14]。
MTCNN的3个卷积网络分别为建议网络(Proposal Network,P-Net)、调整网络(Refine Network,R-Net)和输出网络(Output Network,ONet)。为了适应不同尺寸图片的输入,建议网络设置为全卷积神经网络,同时使用卷积运算代替滑动窗口运算,减小了计算负担,快速过滤>90%的背景目标,实现对人脸图像的粗筛取;将建议网络生成的人脸候选框输入调整网络中,调整网络取消置信度判决为False的人脸候选框,并对其向量继续回归合并;输出网络输出最终合并后的人脸框和人脸关键点位置。MTCNN框架图如图1所示。
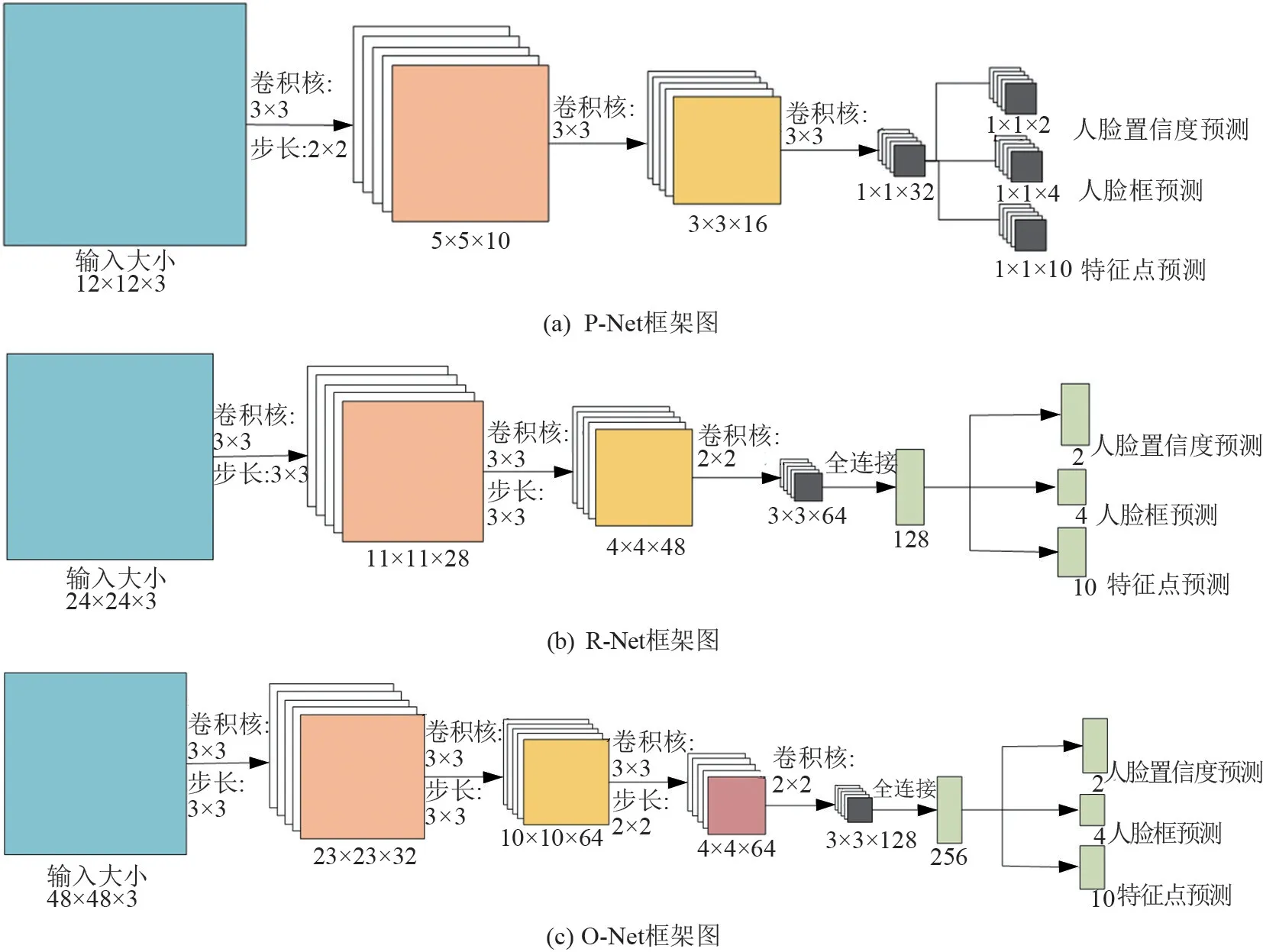
图1 MTCNN框架图
MTCNN引用多种损失函数实现多任务学习,人脸检测任务时可采用交叉损失函数Ldet;而人脸框向量回归任务时,采用的是平方和损失函数Lbox;同时采用了实际数据与标定数据差值的平方和作为人脸特征点回归任务的损失函数Llandmark,O-Net最终输出的人脸特征点实际为标定后的人脸特征点,即人脸关键点己经被对准到规范坐标,该标定过程被称为人脸对齐。因此,MTCNN实际上完成了人脸检测与人脸对齐两个功能。
在判断图像是否包括人脸时采用交叉熵损失函数,数学表达式由式(1)表示为

式中y为对应的标签值,在二分类情况时,即为0或1;pi为对应标签的概率值。
在确定人脸边界框和人脸特征点回归时,采用欧氏距离损失函数,数学表达式分别由式(2)和(3)表示为
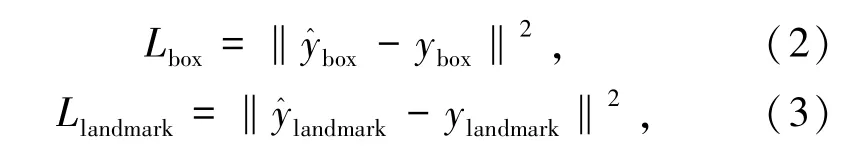
式中和为模型输出的人脸框和人脸特征点的预测值;ybox和ylandmark为原始数据中人脸框和人脸特征点的实际值。
1.2 孪生神经网络
孪生神经网络由一对相同结构、共享权值w和偏置值b的网络模型组成[15]。每次输入2个样本后,通过共享权值的模型将输入图像的特征映射至指定维度的特征向量空间中,比较特征向量的欧氏距离以判定2张图像的相似程度。孪生神经网络结构如图2所示。
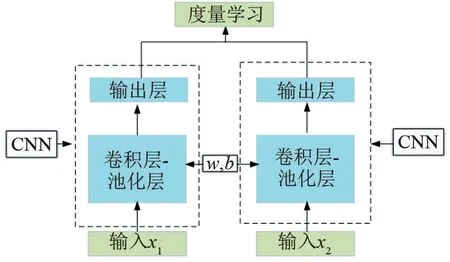
图2 孪生神经网络图
1.3 损失函数
使用对比损失函数作为模型的优化函数[16],数学表达式由式(4)表示为
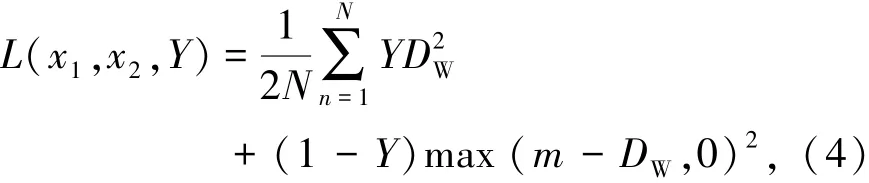
式中D2W=‖x1-x2‖2为2个样本通过模型后输出的特征向量之间的欧氏距离,即二范数;x1和x2为2个样本在通过模型后映射至特征向量空间的坐标值;m为设定的阈值,表示只考虑在0~m之间的不相似特征欧氏距离,当距离超过m时,则损失视为0,在模型训练中,阈值通常设定为1;Y为2个样本是否匹配的标签。
Y=1时代表2个样本相似或者匹配,此时的损失函数由式(5)表示为
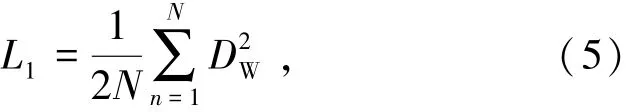
即原本相似的样本,如果在特征空间的欧氏距离较大,则说明当前的模型参数设置不合理,因此损失增大,需要继续迭代修改参数。
Y=0时则代表2个样本不匹配,此时的损失函数由式(6)表示为

即当样本不相似时,两者之间特征空间的欧氏距离反而小的情况下,损失函数的值会变大。
由于孪生神经网络一次性输入2张样本,同时使用对比损失函数进行网络优化,使得每张样本不仅只是使用一次,而是利用每1张样本与其他同类或非同类样本通过网络映射的特定维度向量空间后产生的特征向量进行距离比较,扩大单张样本的训练次数,从而使得人脸识别网络训练数据以指数级别的增加,同时将人脸分类问题转换为2张图像相似度比较的问题。
使用孪生网络训练时,由于其逐对训练的原理,可以在小样本的情况下创造平方级别数量级的数据来训练模型,弥补了在小样本情况下的过拟合缺陷。假设原始样本有A类,每类有B个样本,如果利用传统的分类模型进行训练,则原始样本提供的可训练数据量为N=A×B。但是在使用了孪生神经网络和对比损失函数的情况下,原始样本可以提供的训练数据量N由式(7)表示为
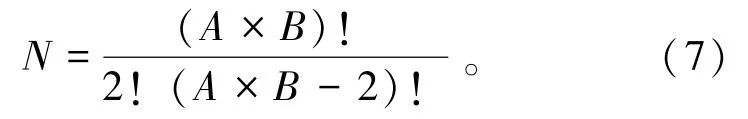
基于度量学习的损失函数能够有效地减少复杂干扰造成的相同身份人脸特征向量之间的差异,并增大不同身份人脸特征向量间差异。从大量的训练人脸特征向量中学习该特征空间更具有稳定性、可区分的距离度量,将原本在原始空间中分辨困难的数据进行维度变换,可降低干扰影响,提升识别精度。
2 孪生神经网络设计
利用MTCNN检测图像中的人脸区域并将人脸部分进行截取,从而减少计算量和无关的图像信息,将所有人脸图像进行标准化来减小光照、噪声等外来干扰。将经过预处理的图像进行孪生神经网络计算后,通过比较输出的特征向量在特征向量空间之间的欧氏距离比较2张人脸的相似度。孪生神经网络算法流程如图3所示。
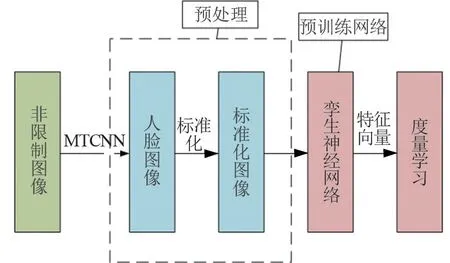
图3 孪生神经网络算法流程图
2.1 改进的网络模型
采用迁移学习来减小运算时间并在小样本的数据集上进行实验,具体操作为:(1)将Inception-ResNet-v1利用交叉熵损失函数和中心损失函数的联合损失函数在大型数据集的基础上进行训练后,将模型的卷积层作为特征提取部分;(2)添加注意力机制模块CBAM,为不同的通道和特征图区域设置权重值;(3)利用全局平均池化层(Global Average Pooling 2D)取代压平层(Flatten)后,添加随机断开层(Dropout)和全连接层(Dense)将输出映射至128维的向量空间中,网络结构见表1。通过比较特征向量之间的欧氏距离大小来判断2张人脸的相似程度。

表1 网络结构表
预训练模型是利用Inception-Resnet-v1模型在大型数据集上进行训练分类;截取模型的卷积层,作为预训练的特征提取网络,使得网络模型的参数在预训练的基础上进行迭代优化,从而减小模型运算时间。
CBAM层是基于混合域注意力机制思想设计的注意力机制模块。引入注意力机制模块可以微调原始模型参数,使得网络能够给予更重要的图像区域和通道更大的权重,从而提高了整个模型的准确度。通过对比实验证明,引入基于CBAM模块注意力机制模块比不添加注意力机制模型有一定的提升。
Global Average Pooling 2D层是代替Flatten层和全连接层的全局平均池化层,将输入的(3,3,1 792)维度的特征值压缩至(1,1,1 792),选择3×3矩阵中的平均值作为特征输出,最终全局平均池化层的输出为一维的特征向量值,特征向量值的长度为输入特征向量的通道数1 792。利用全局平均池化层取代Flatten层和全连接层可以减少模型的计算量,提高运算效率,同时可以抑制过拟合,保证模型的泛化能力。
Dropout层是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中断开。对于随机梯度下降来说,由于是随机丢弃,因此在每一轮的训练中都在训练不同结构的网络,从而提高了网络的泛化能力,减小了模型的过拟合情况。文章按照0.5的比率,每轮训练时随机断开一半的神经元,所以输出为896。
Dense层是全连接层,其输出是1个一维向量,向量的长度取决于全连接层的输出。对于孪生神经网络模型,Dense层的输出代表了孪生神经网络输出的向量空间维度。通过对比实验证明,选择128维的特征向量输出有利于提高模型的准确度,在一定程度上避免了过拟合的情况。
2.2 注意力机制
注意力机制的本质是定位到感兴趣的信息,抑制无用信息,给予不同位置的像素以不同的权重值,其核心思想是在训练过程中更多地关注于需要被关注的区域,使得模型性能受到值得重视的部分更多影响。对于应用于单张图像的注意力机制通常分为通道域注意力机制(Channel Domain)、空间域注意力机制(Spatial Domain)以及混合注意力模型(Mixed Domain)3种类型。通道域注意力机制是指为不同的通道设置权重值,并纳入到模型的学习中,使得最后的结果受到权重大的通道更多影响,从而改善模型效果。空间注意力机制指为特征图不同位置设置权重值,并纳入到模型的学习中,使得最后的结果受到权重大的特征图区域更多影响,从而提高模型性能。文章采用基于CBAM作为网络模型的注意力机制模型,其结构如图4所示,是通过串联通道域注意力机制(Channel Attention)和空间域注意力机制(Spatial Attention)来组成混合注意力机制[17]。相比于网络结构SENet(Squeeze and Excitation Network)只关注通道域的注意力机制,CBAM混合域注意力模型可以取得更好的效果。
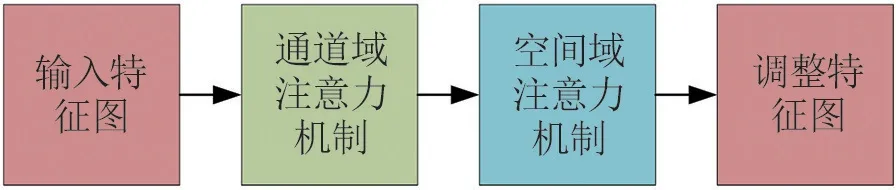
图4 CBAM注意力模块图
CBAM中通道域注意力模块如图5所示,原特征图通过全局最大池化和全局平均池化;再分别通过一个共享权值的多层感知器,将输出特征图全局同位相加;采用Sigmoid函数激活,将权重限制在0~1之间;将权重矩阵和原始输入特征图通道相乘,使得不同通道的特征图在整体模型的训练中起到不同的作用。

图5 通道域注意力模块结构图
通道域注意力机制的数学表达式由式(8)表示为
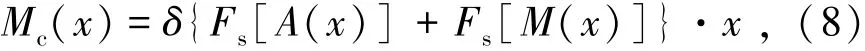
式中x为输入的特征图;A为对特征图的全局平均池化;M为对特征图的全局最大值池化;Fs为一个共享权值的多层感知器;δ为将输入限制于0至1之间的非线性激活函数Sigmoid;Mc(x)为经过通道域注意力机制后的特征图。
多层感知机(Multilayer Perceptron,MLP)设置为三层全连接层,第一层和第二层输出分别为1 204和512;第三层全连接层输出设置为模块原输入的通道数1 792,能够保证输出的权重矩阵维度和原特征图的通道数一致,使得最终得到的Channel Attention能够给予原不同通道的特征图以不同的权重,从而加强模型的表达效果,提高准确率。
CBAM中空间域注意力模块如图6所示,是原始特征图沿通道方向将1 792个数据进行全局最大池化和全局平均池化得到2张(3,3,1)的特征矩阵;矩阵沿通道域连接组合,形成一个(3,3,2)的特征图;经过一层的3×3卷积核的神经网络,将通道域维度降至1维;通过Sigmoid激活函数将变换后的权重系数矩阵权重限制在0~1之间后,将得到的权重系数矩阵(Spatial Attention)与原始输入特征图(Feature Map)点乘,赋予原本神经网络输出的特征图的每一区域不同权重。
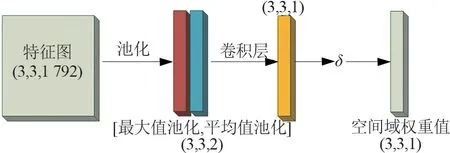
图6 空间域注意力模块结构图
空间域注意力机制的数学表达式由式(9)表示为
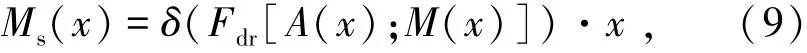
式中Fdr为降维的神经网络,将通道数降至1维;设计为1个3×3卷积核、步长为1、通道数为1的卷积层;设置填充方式为same padding,使得降维之后的权重矩阵保持和输入特征图同样的维度大小;Ms(x)为经过空间域注意力机制后的特征图。
利用权重矩阵和原特征图逐点相乘,同一张特征图的不同区域得到了不同的权重值,从而增强模型的准确率。
3 实验结果与分析
3.1 数据处理及实验条件
利用CASIA-WebFace人脸公开数据集进行实验,其是由中国科学研究院自动化研究所李子青团队在2014年收集整理完成,包含10 575个人的494 414张人脸图像。从数据集中随机选择100个对象进行实验,选择人脸对象的前10张图像作为实验数据。通过随机组合的方式选择10 000组数据样本,其中正负样本数量之比为1∶1,并且按照8∶2的数据比分割测试集和验证集。
实验的硬件配置为:中央处理器i5-8400、图形处理器英伟达1070、16G运行内存。实验平台是基于Tensorflow后端的keras框架。批大小设置为64,损失函数为对比损失函数,优化器为适应性矩估计(Adaptive moment estimation,Adm),步长为0.000 2,迭代次数设置为100。
3.2 预训练模型
采用Inception-Resnet-v1作为预训练模型,通过交叉熵损失函数和中心损失函数的联合损失函数在CASIA-WebFace上进行训练,选择模型的卷积层作为特征提取部分,连接全连接层并添加Dropout层和Relu激活函数后将输出映射至特定维度的向量空间。每次2张图像通过孪生神经网络模型运算,得到2个相同维度的特征向量,通过比较其在向量空间中的欧氏距离来判定2张人脸的相似度。为了选定维度大小,设定了最后一个Dense层的输出维度进行实验比较分析。维度选择的实验结果见表2。

表2 不同特征向量维度实验结果表
由表2可知,选择128维的特征空间输出的特征向量训练集的准确率达到了98.78%,准确率差距最小为2.34%,可以得出实验过程中没有出现过拟合现象,因此确定以128维特征向量输出的Dense层作为输出。
3.3 实验结果
为了对比在孪生神经网络中添加注意力机制的有效性,实验将添加通道域注意力机制SENet的模型命名为SE_Siamese,添加空间域注意力机制(Global Context Network,GCNet)的模型命名为GC_Siamese,添加混合域注意力机制CBAM的模型命名为CBAM_Siamese,不添加注意力机制的模型命名为Siamese。实验结果见表3。实验验证集准确率如图7所示。
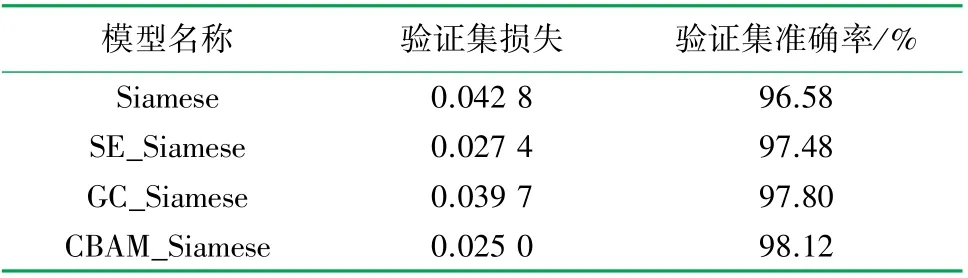
表3 注意力机制实验结果表
由图7可知,通过增加注意力机制模块的3种模型的验证集准确率都超过了不添加注意力模块的表现。比起通道的激励挤压注意力机制SENet,集合了SENet和NLNet(Non-local)的GCNet以及混合了空间域和通道的CBAM表现得更加优秀。基于模型的准确率以及训练参数的综合选择,确定了以CBAM注意力模块嵌入神经网络模型中。

图7 实验验证集准确率图
3.4 算法比较结果
为了进一步比较实验算法的准确率,在训练上述网络模型的数据集中将文章所设计CBAM_Siamese模型与PCA+SVM[3]、Facenet+SVM[6]、DeepFace[7]和ResNet-50[13]进行比较。实验结果见表4。

表4 不同方法人脸识别准确率对比表
由表4可知,由于PCA的特征选取没有进行训练,所以识别率较低。基于加性角度间隔损失函数的ResNet-50模型在准确率上没有达到本实验方法的准确率,而利用DeepFace算法的深度学习模型识别率也有待提高。利用Facenet模型提取了128维人脸特征后,通过特征进行SVM分类的方法也没有达到CBAM_Siamese模型的准确率。通过对这5种检测算法的对比实验可知,文章提出的算法对于小样本的人脸进行识别具有一定的优势性,其准确率达到了98.12%。
4 结论
通过上述研究,得到如下结论:
(1)在使用更少的训练数据情况下,文章选择了混合域注意力机制的CBAM模块作为注意力机制嵌入至孪生神经网络中,与其他单纯使用通道域和空间域注意力机制模块相比,其能够充分考虑给予不同通道的特征图以不同的权重,使得模型比传统的孪生神经网络具有更高的准确率;以训练集和验证集准确率综合考虑,输出128维的孪生神经网络模型人脸识别准确率达到96.44%,而且过拟合现象小。
(2)以实验准确率为性能指标,通过与其他4种人脸识别模型对比,文章所提出的算法对于小样本集的人脸识别达到了98.12%的准确率。
