基于多特征组合的构音障碍语音识别
2022-03-01梁正友黎雨星
梁正友,黎雨星,孙 宇,姚 强
(1.广西大学 计算机与电子信息学院,广西 南宁 530004; 2.广西大学 广西多媒体通信与网络技术重点实验室,广西 南宁 530004)
0 引 言
构音障碍是大脑性麻痹、中风等疾病患者的语言症状[1]。依托计算机进行构音障碍的自动识别研究具有十分重要的社会意义和临床应用价值,已经吸引了众多的学者进行了相关的研究。Takaya Taguchi等[2]使用多元回归分析得出声学特征中MFCC的第2阶特征是区分健康说话人和重度抑郁症患者语音的显著特征。Vyas G等[3]从语音信号中提取出基频、共振峰、振幅等传统韵律特征和MFCC进行组合用来表征构音障碍语音;李东等[4]使用语速、基频、共振峰等韵律特征和MFCC的统计值进行融合,使用融合后的特征向量进行构音障碍识别。Ali Z等[5]通过计算改进的语音轮廓(MVC)下的区域面积来度量一段语音的声音强度,并使用SVM进行识别;Spangler T等[6]使用构音障碍语音的分形特征,采用XGBoost分类算法来实现构音障碍的自动检测。Mucha J等[7]从不准确发音、言语声律障碍、语言流畅性缺失和言语质量恶化4个方面提取出了相应的声学特征,并使用随机森林分类器进行分类。Amara F等[8]使用GMM和SVM共同建立分类模型;Galaz Z等[9]使用顺序浮动特征选择算法和随机森林分类器对构音障碍进行识别。Kadi K L等[10]使用两个公开数据库来进行3个等级的构音障碍严重程度评估,为了使评估方式同样适合两个数据库,他们提出了一种改进的FDA分数计算方法,并选用GMM作为分类器。
本文提出了一种基于多特征组合的构音障碍语音识别方法,该方法总体的流程如图1所示。首先,预处理后分别从语音中按韵律、频谱、嗓音质量、人耳听觉和声道模型等5特征类型提取相应的声学特征并组成多特征组合,以保留语音的多种语音特征信息,克服韵律特征、MFCC等部分特征无法全面表征构音障碍语音所具有的特点;其次,以遗传算法搜索、SVM分类评价的特征选择策略,对多特征组合进行特征选择,选择出分类准确率最高的特征子集,降低多特征组合中噪声数据和冗余数据,以降低计算复杂度和提高分类准确度;最后用SVM分类器进行分类。在Torgo声学和发音数据库[11]进行了模拟实验,实验结果表明,本文提出的方法对Torgo数据库的3种语音刺激类型的平均准确率为97.52%,优于现有的识别方法。

图1 方法整体流程
1 多特征组合参数提取
构音障碍患者在发音时,有发音不准、鼻音过强、声音过大变化以及声音质量、可理解性下降等临床特点。要充分反应构音障碍患者语音的信息,在特征抽取时要尽可能抽象各类特征。主要的语音特征有以下几种:
(1)韵律特征:韵律特征反映了语音信号的时域分布、语调和重音的特点。构音障碍患者由于发音器官和相关肌肉的运动机能的减弱,导致声音强度和音调等韵律特征发生异样的变化。韵律特征可以较好区分构音障碍患者和健康说话人。韵律特征包括3个共振峰(F1,F2,F3)[3]、基频(F0)[3]、最大峰值(PQ)、短时能量(E)、短时平均过零率(ZCR)、偏度(ske)和峰度(kur)等9个特征,记为F={F0,F1,F2,F3,PQ,E,ZCR,ske,kur}。
(2)基于频谱的特征:基于频谱的特征主要反映了语音信号能量与频率分布的特点,在声学上反映声道形状和发声器官运动之间的关联。构音障碍患者在发声器官上的病变会导致肌肉运动的异常,某些音调无法发出导致语音断续,或无法正常控制音调导致声音起伏变化过大。基于频谱的特征包括频谱质心(SC)、频谱通量(SF)、频谱衰减点(SR)、能量熵(Ent)等4个特征,记为S={SC,SF,SR,Ent}。
(3)嗓音质量特征:嗓音质量特征是反映嗓音强弱及规律性的重要声学参数。当构音障碍患者声带出现病变时,嗓音往往也有质量上的下降。嗓音质量特征包括两个基频微扰(Jit1,Jit2)和两个振幅微扰(Shim1,Shim2)等4个特征,记为JS={Jit1,Jit2,Shim1,Shim2}。 它们共同反映了声带振动的稳定性,因此在病理语音的医学研究中,也常将这些特征作为判断嗓音病变严重程度和恢复程度的重要参数,作为基于频谱的特征和韵律特征的补充特征。
(4)基于人耳听觉的特征:梅尔频率倒谱系数(MFCC)[12]是一种基于人耳听觉特性的语音特征,广泛应用在语音自动识别上,具有识别能力和鲁棒性较强的优点[13,14]。本文提取了MFCC作为特征参数,MFCC阶数选取为12阶,记为MFCC={MF0,MF1,…,MF12}。
(5)基于声道模型的特征:声道模型参数可以准确地描述语音信号的时域和频域特性。声道模型目前有声管模型和共振峰模型两种,线性预测(linear prediction)模型的本质即探究声管模型的性质,是一种常用的声道模型参数估计方法。主要思想是使用过去若干语音采样值的线性组合来逼近一个语音的取样,确定一组唯一的预测系数。这些参数可以准确描述语音信号的时域和频域特性。线性预测模型常用于语音信号处理,不仅有预测功能,而且提供了一个好的声道模型。本文使用了基于线性预测的线谱频率(LSF)[15]、线性预测倒谱系数(LPCC)[16]等两种声道模型参数。分别提取了LSF和LPCC各10个特征参数,分别记为LSF={LS1,LS2,…,LS10},LPCC={LP1,LP2,…,LP10}。
已有研究,如文献[2-4],它们基于上述部分特征进行识别。为了获取比较全面的语音信息,本文把上述5类特征组合成多特征向量V,其中V={F,S,JS,MFCC,LSF,LPCC}, 共包含有49个特征参数,再使用遗传算法从中选择出对构音障碍语音识别有效的特征。
2 结合遗传算法搜索和SVM分类器评价的特征选择
从语音中提取到的多特征组合包含有冗余信息和噪声信息。这些冗余信息和噪声信息将直接影响构音障碍分类的准确性;因此,需要对多特征组合进行选择优化,选择出最优的特征子集。本文以遗传算法为搜索算法、SVM分类器为评价方法构造特征选择策略,从多特征组合中选择出分类准确率最高的特征子集。方法流程如图2所示。
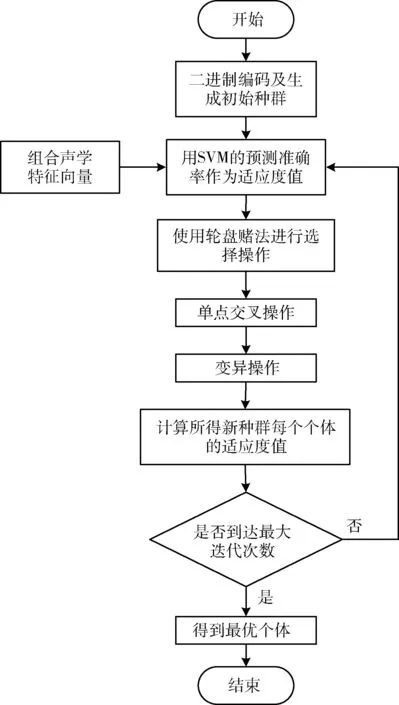
图2 结合遗传算法搜索和SVM分类器评价的 特征选择方法流程
其中,遗传算法包括了选择、交叉和变异等过程,最终产生出更适应环境的个体;而根据输入的多特征组合的特征向量对构音障碍进行分类,其分类的准确率用作遗传算法的适应度评价标准。其主要操作如下:
(1)个体编码和初始化种群。首先需要将实际问题的求解形式转换成基因组合的形式,这个过程就是编码。由于待解决的问题是离散优化问题,因此本文采用二进制编码方式。设特征向量为F={f1,f2,…,fn}, 其二进制编码表示见表1;其中,个体基因为{0,1}取值,当基因值为0时代表该位置的特征不被选择,当基因值为1时则代表该位置的特征被选择。
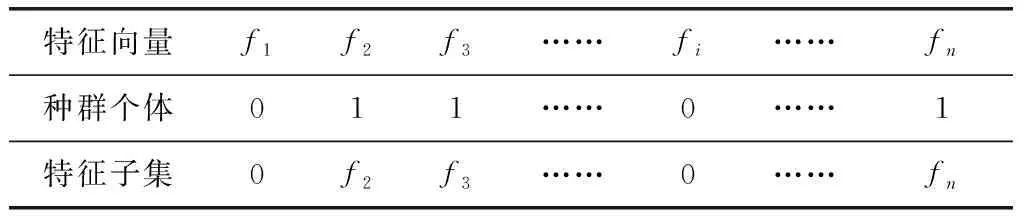
表1 Torgo数据库各类型语音数目
(2)适应度函数。适应度函数即用来考量个体在群体中的相对适应性,个体适应度的大小决定了该个体的遗传机会。本算法是以寻找最优准确率为优化目标,所以我们将由个体编码决定的特征子集所得分类器的预测准确率作为每个个体的适应度值,适应度值越高,遗传机会越大。本文使用的分类器为参数调优后的SVM分类器。
(3)遗传操作:选择操作、交叉操作和变异操作。
选择操作是由个体适应度值决定其是否存活到下一代的过程。本文选择操作的策略采用轮盘选择方法,个体存活到下一代的概率与其适应度值成正比。
交叉操作模仿自然界基因传递的过程,被选择的两个个体通过交换部分基因而重组,从而形成两个新个体。交叉操作使种群多样性得到扩展,从而有更大的可能向全局最优解收敛。二进制编码常用的交叉操作有单点交叉、多点交叉和均匀交叉,多点交叉和均匀交叉虽然有较好的基因重组能力,但是容易对好的基因模式造成破坏,因此本文采用单点交叉法进行交叉操作。
变异操作是模拟遗传过程中可能的基因突变,以非常小的概率决定当前个体是否发生突变,在二进制中突变则取反操作,即0变成1或相反。根据设定的变异概率对每个个体进行一定概率的基因突变。
(4)终止条件设定。遗传算法的迭代停止条件一般有两种设定,一种是运行到最大代数停止,一种是设置迭代误差阈值,当误差达到这个值时说明种群无法再进化了,算法停止。本文选用设置最大迭代次数作为算法终止条件。
3 实 验
实验在配置为CPU i7-7700Hq 2.80 GHZ、内存为8 G的笔记本上进行,操作系统为 Windows10,以MatlabR2016b编写程序进行实验。
3.1 实验数据库及评价指标
3.1.1 Torgo数据库
本文在公开的Torgo声学和发音数据库[11]上进行实验。该数据库的音频样本来源于8位大脑性麻痹或肌萎缩性脊髓侧索硬化症引发的构音障碍的患者,其中5位男性和3位女性。此外,还有7位年龄性别相匹配的健康对照人,包括4位男性和3位女性。并且由专业的语言病理学家对每一位构音障碍患者的语音动力功能按照标准的Frenchay Dysarthria进行了评估。Torgo构音障碍数据库基本信息见表2。

表2 Torgo构音障碍数据库的相关信息
3.1.2 数据预处理
根据已有数据库所含数据类型,为了便于实验对比分析,本文从Torgo数据库中分别选择了非词、短语和限制句3种类型作为实验数据来源。其中,Torgo数据库中的非词类型,是择取持续元音发音作为非词语音刺激类型的组成部分。在Torgo的原始数据中,有一小部分语音数据存在声音过小、环境噪音异常等问题,为避免这类数据对实验结果的影响,在进行实验前,对所有数据进行了进一步的人工筛选,最终选出的语音数目见表3。对整理后的语音数据进行预处理,使用谱减法进行去噪,目的是去除录制语音时背景中的稳定噪声成分。随后对去噪后的语音信号进行预加重、分帧加窗的预处理,本文中选取每帧长度为400个采样点,即25 ms;每帧的重叠部分为160个采样点,即10 ms;窗函数使用汉明窗。
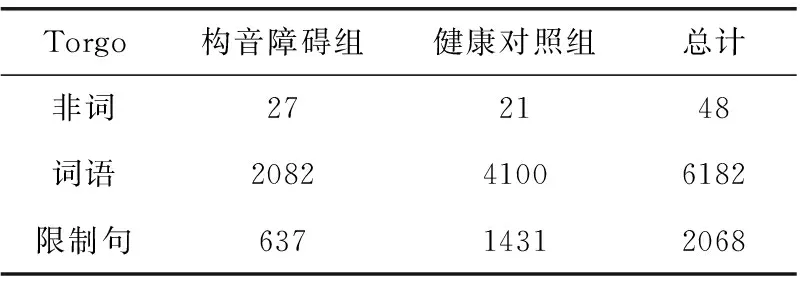
表3 Torgo数据库各类型语音数目
3.1.3 评价指标
为了客观评价算法的分类性能,本文根据混淆矩阵选用了4个评价指标,分别是准确率(Accuracy,Acc)、灵敏性(Sensitivity,Sen)、特异性(Specificity,Spe)和AUC值(Area under Curve)。从机器学习的角度看,准确率是最为常用的评价指标,但准确率在数据不平衡的情况下会非常敏感,而AUC值对于不平衡数据相对更不敏感,因此AUC值能很好描述分类模型整体性能的稳健性,并且AUC值越高代表分类器整体性能越好。从医学角度看,在疾病分类中灵敏性越高代表了漏诊率越低,特异性越高则代表误诊率越低,因此同时引入了灵敏性和特异性作为构音障碍识别的评价指标。
3.2 实验结果与分析
3.2.1 构音障碍语音识别结果的对比
为了比较本文方法的识别效果,对本文方法与文献[3]、文献[4]的方法进行对比实验,在Torgo数据库上进行构音障碍语音与正常语音的分类实验。文献[4]使用MFCC和韵律特征所提取的统计特征进行组合形成融合特征FFPM,并使用随机森林(RF)进行分类;文献[3]使用MFCC和韵律特征作为特征向量,并使用经典遗传实现了构音障碍分类。实验结果见表4,实验结果表明本文提出的识别方法在3种语音刺激类型的平均准确率、平均灵敏性、平均特异性和平均AUC值等指标上都优于文献[4]和文献[3]的方法;在单项语音刺激类型方面,本文方法只在词语刺激类型的敏感性上低于文献[4],在限制句刺激类型的灵敏度上略低于文献[4],其它指标都优于其它方法。这是由于本文方法使用了更为全面的语音特征;并用性能稳健的遗传算法进行特征优化选择,消除了冗余信息和噪声,从而具有更优越的性能。
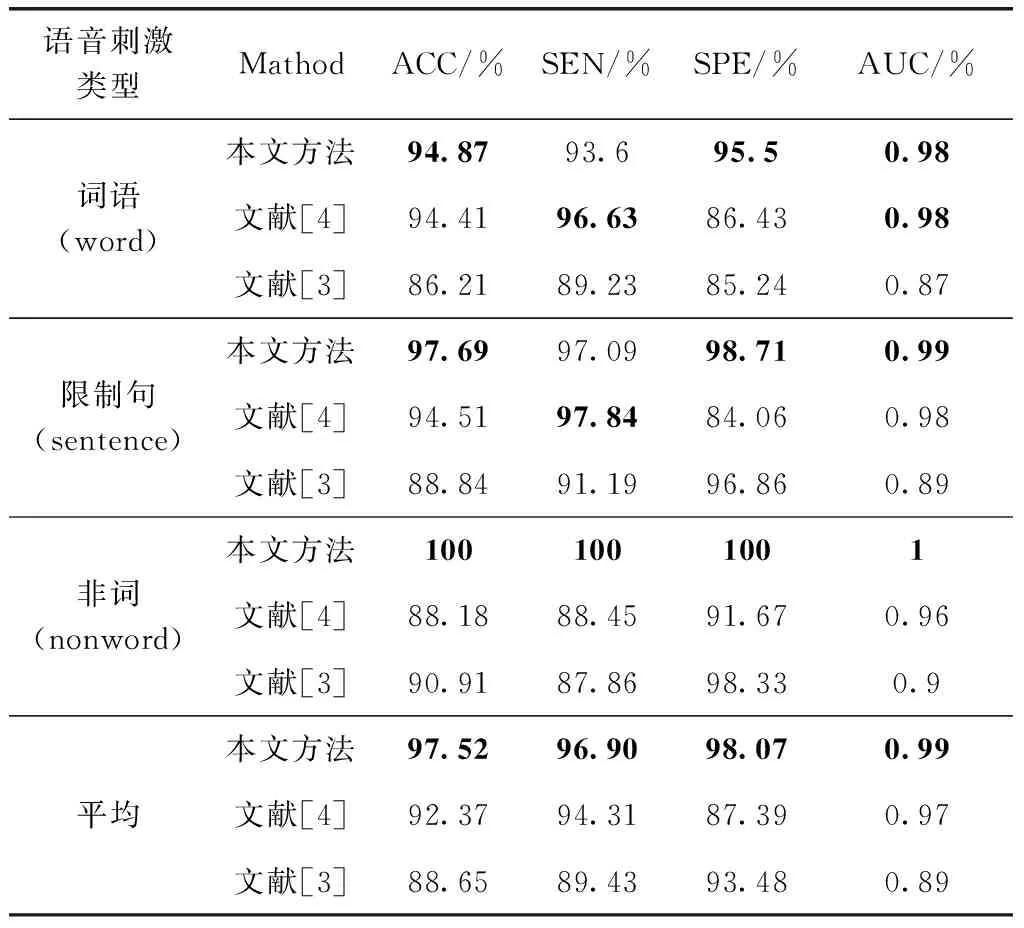
表4 与文献[4]、文献[3]的对比实验结果
3.2.2 不同语音刺激类型的实验结果与分析
为了探讨不同语音刺激类型分类的差异性,本文使用了Torgo的所有数据,按照3种语音刺激类型分别进行了3组实验。本文遗传算法的各项参数设置见表5,其中交叉概率和变异概率至今没有统一的设定标准,一般是靠经验进行调整。交叉概率一般设置范围为0.4~1.0且一般不设置为1,因为容易造成优秀基因的流失。但在本文的实验数据下进行多次实验,分别设置交叉概率为0.95~1,测试后设置1为交叉概率所得的结果最好。变异概率的设置范围一般在0.1以下,原理是允许极少数个体变异,从而跳出局部最优解的情况,在本文的实验数据下进行了0.04~0.09的测试实验,最终选择设置0.07。对每组实验数据,使用留出交叉验证法随机选择80%的数据作为训练数据,20%的数据作为测试数据,并重复10次该操作进行实验。
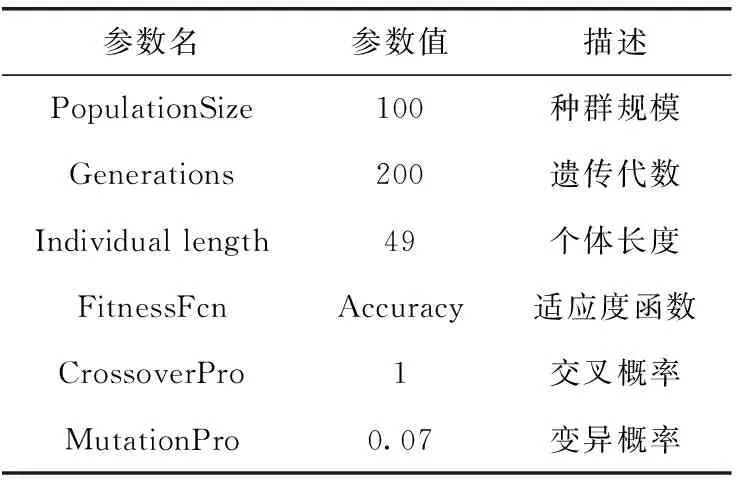
表5 遗传算法参数设置
表6为使用本文方法在Torgo数据库上的实验结果,结果显示:①本文方法对非词数据类型的识别准确率上最高,达到100%识别率; 平均准确率达到97.52%;②3种语音刺激类型的AUC值处在比较高的水平;③从敏感性和特异性看,该算法在3组实验数据上都保持了一个相对较高的值,这说明该算法对构音障碍患者和正常说话人的正确识别都有一个较高的水平,这对于构音障碍识别的实际应用中,不会出现过高的漏诊率和误诊率。
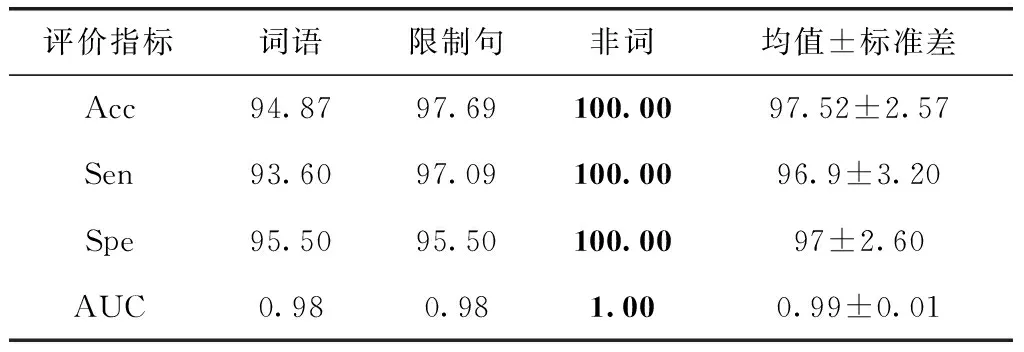
表6 不同语音刺激类型的分类结果
3.2.3 特征选择分析
本节通过实验分析本文所提出的特征选择方法是否能提高构音障碍语音的识别率。分别使用本文提取的5个种类的语音特征、全部特征以及基于统计的特征子集对构音障碍进行实验,其中基于统计的特征子集是10次重复实验选择出的特征子集统计得到的。统计方法为,对10次重复实验所选择的特征按照选取次数进行从高到低的排序,并计算10次实验选取的特征子集的平均特征数n,提取出排序后前n个特征视为被选择的特征子集。
表7展示的是在6个数据子集上使用不同特征进行的构音障碍识别实验,使用的分类器为SVM。使用的不同特征分别为:5个单方面的语音特征(韵律特征、频谱特征、人耳听觉特征、嗓音质量特征和声道模型特征)、全部特征、基于统计的特征子集。
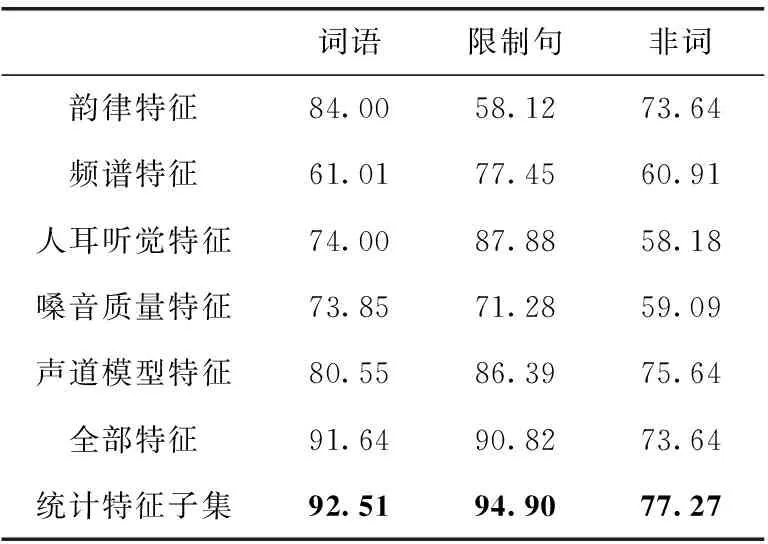
表7 使用不同特征的构音障碍识别准确率/%
根据表7展示的实验结果,我们进行如下分析:①单独使用某类特征的情况下,在多数数据子集上可以展现出其具备一定的构音障碍识别能力;②使用全部特征进行实验得到的识别率要高过单独使用某类特征的识别率,说明包含的特征种类越多,其中有用信息也越多;③使用基于统计的特征子集进行实验在多数情况可以获得比全部特征更高识别准确率,这说明通过遗传算法特征选择后,经过统计得到的特征子集可以有效提取全部特征中大部分的分类信息;同时相比于全部特征,基于统计的特征子集有较少的特征维数,减少了冗余信息和噪声信息;从而提高了识别正确率。
4 结束语
本文提出了一种多特征组合的构音障碍识别方法。首先,从构音障碍的语音特点出发,从语音信号中分别提取了5类声学特征并组合成一个多特征组合;随后使用结合遗传算法搜索和SVM分类器评价的特征选择策略进行特征选择,最后用SVM进行构音障碍识别。本文按照语音刺激类型设计了3组实验,深入研究了不同语音刺激类型给识别带来的差异性。通过分析实验结果可以得出,本文所提出的方法可以有效地识别构音障碍语音和正常语音。通过与文献[3,4]进行实验对比,实验结果表明本文提出的方法比它们具有更好的性能。另外,根据本文实验可以观察得出:不同语音刺激类型之间构音障碍识别效果也有差别。其中限制句和非词类型的数据可以更好地用于构音障碍识别问题,而词语类型的数据在识别问题上则表现出更好的稳定性,这个结论为构音障碍语音自动识别在实际临床应用和进一步的研究上提供了可靠的参考作用。
