基于堆叠沙漏网络改进的多人姿态估计
2022-03-01任文静李传秀
梁 鸿,任文静,张 千,李传秀
(中国石油大学(华东) 计算机科学与技术学院,山东 青岛 266580)
0 引 言
随着深度学习技术的发展,深度卷积神经网络开始被应用到人体姿态估计任务中。DeepPose是第一个将深度卷积神经网络应用到人体姿态估计领域的模型。Newell等[1]提出的经典网络结构——堆叠沙漏网络,可以更好地混合全局和局部信息,在姿态估计任务上具有重要的意义。Papandreou等[2]先使用Faster R-CNN[3]检测出可能包含人物的区域,然后利用全卷积残差网络(ResNet[4])预测每个人的关键点坐标,但是人体目标检测效果不理想。
多人姿态估计需要对多个人体姿态进行区分和匹配,加大了算法的复杂程度,存在以下难点:①图像中存在的人数不定。需要使用检测器遍历图像才能知道图像中的人数,这就对检测器的速度和精度提出了高要求;②检测尺度问题。图像中不同人离镜头的远近使得人与人之间相对图像的占比会有所不同,这就涉及到人体多尺度的检测;③关键点遮挡问题。包括人体自身衣物的遮挡和物体对部分关节的遮挡。
针对以上问题,本文提出了基于堆叠沙漏网络改进的多人姿态估计网络模型(channel shuffle and attention residual stacked hourglass networks,CA-SHN)。结合先进的人体目标检测模型YOLOv3[5]提高人体目标检测的准确率;通过对通道上的信息进行多尺度融合加强网络学习能力,帮助信息在特征通道间流动,有助于人体多尺度的识别;在沙漏网络的残差模块中加入注意力机制,提高了网络对小尺度关键点的关注度,更好地解决遮挡问题,继而可以提高人体姿态估计的识别效果。最后在MPII和MSCOCO数据集上的实验结果验证了本文算法的有效性和优越性。
1 网络结构
堆叠沙漏网络(stacked hourglass networks,SHN)作为MPII 2016年关键点挑战赛的冠军,取得了不错的识别效果,也是经典的人体姿态估计方法之一。它成功的关键在于使用对称式的沙漏结构,先对特征图进行自下而上的处理,得到不同尺度的特征,然后再对下采样得到的特征图执行自上而下的处理,同时把下采样之前的特征图经过卷积操作保留下来,和之后上采样到相同分辨率的特征图融合。这种自下而上、自上而下的处理重复多次,从而建立一个叠加的沙漏网络。但是,堆叠沙漏网络只专注于从图像中定位单人姿态的关键点,而且在针对小尺度关键点时的识别效果不佳,同时原始沙漏网络中使用的残差单元也存在一些问题:在特征图传递的过程中,它是将所有的特征统一权重传给后面的沙漏网络,当多个残差单元的输出被总结时,输出方差几乎翻倍,这会导致计算量加大,优化困难。因此,本文改进基于堆叠沙漏网络的单人姿态估计,使其可以更好地应用到多人姿态估计中。
本文所提出的算法的整体流程如图1所示,首先使用改进后的人体目标检测器(YOLOv3-person)将含有人体目标的区域裁剪出来,然后送入改进后的姿态估计网络(CA-SHN)进行人体关键点的检测,最后将检测后的图像重新映射回原图像中,即可完成对一张图像的多人姿态估计识别。
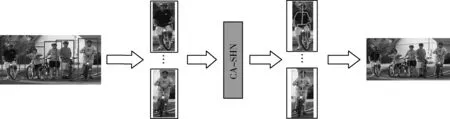
图1 整体算法流程
改进后的沙漏网络结构如图2,改进部分如虚线框所示,图2中的每个小方块表示融入注意力机制的残差模块。本文在原始沙漏网络的基础上,将下采样前的卷积特征Conv_1~Conv_4进行通道混洗之后作为新的特征加入到上采样之后的模块中,加强不同尺度多层特征之间的跨通道信息交流,并将原始网络中的残差模块改为融入注意力机制的残差单元,让网络更好地将注意力放到有用特征的学习上。
2 改进方法
2.1 多尺度特征融合
使用局部特征对于识别面部和手部等特征至关重要,但是最终的姿态估计需要对全身有整体的理解,同时人的方位、相邻关键点之间的关系等信息在图像不同尺度下可以得到不同的理解。高层低分辨率的语义特征可以用来推导看不见的关键点,而低层高分辨率的语义特征对于推导小尺度的关节点至关重要。因此将两者结合起来,既可以解决被遮挡关键点的识别,也能使尺度较小的关键点被有效检测出来。因此,人体姿态估计需要在网络中将局部信息与全局信息结合,将低层特征与高层特征结合。
多尺度特征融合作为深度学习的常规操作,可以提高网络的学习性能。原始的堆叠沙漏网络将下采样前的卷积特征Conv_1~Conv_4保留,与上采样之后得到的相同维度的卷积特征Conv_4’~Conv_1’进行像素点的相加,做到了局部信息与全局信息的结合。但是对于多人姿态估计,低层特征和高层特征之间的取舍仍然存在局限性。与此同时,很少有人关注特征图在通道信息上的多尺度融合。受ShuffleNet[6]的启发,本文对不同尺度的特征图在通道特征上采取混洗操作,进一步打乱高层特征和底层特征之间的依赖性,进而这些不同尺度的特征可以相互作为补充和强化。通过对通道上的信息进行多尺度的融合也可以加强网络学习能力,帮助信息在特征通道间流动,从而可以更好地识别出被遮挡的关键点。同时,将不同分辨率的图像采样到相同的尺度,在经过反复的融合,加上网络自身的学习能力,会使得多次融合后的结果更加接近于正确的结果表示。

图2 改进后的沙漏网络结构
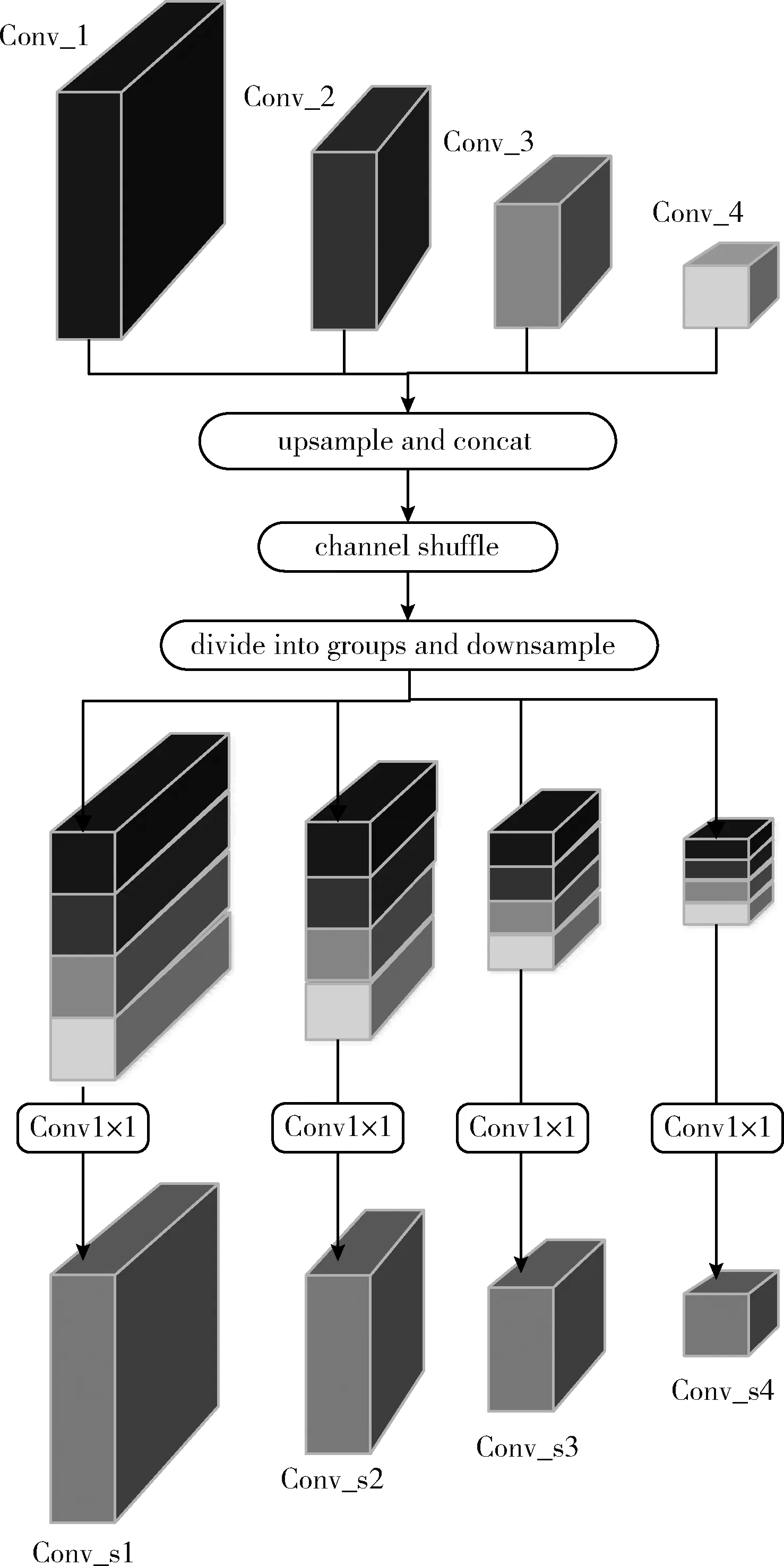
图3 通道混洗模块网络结构
通道混洗操作如图3所示,首先将沙漏模块中下采样得到的卷积特征Conv_1~Conv_4进行1×1卷积,变换到相同的通道数256;然后把中低分辨率特征Conv_2~Conv_4进行上采样得到与Conv_1相同的分辨率,接着在通道维度进行concat操作,得到1024维的长特征;再对长特征进行混洗(shuffle)操作:①把1024维的通道特征图进行数据重组操作到 (g,n), 其中g为分组,且g×n=1024; ②进行转置操作,得到规模为 (n,g) 的通道特征图;③再进行一次数据重组操作,由 (n,g) 重新拉长为1024维;通过上一步操作,得到了新的1024维的通道特征图,接着进行划分到之前的组数,下采样,最终得到了shuffle后的新特征Conv_s1~Conv_s4;最后对Conv_s1~Conv_s4分别进行1×1卷积后,与沙漏网络上采样到相同分辨率的Conv_4’~Conv_1’特征进行元素相加,从而完成了一个沙漏模块在通道特征图上的多尺度融合。
2.2 融入注意力机制的残差模块
文献[7,8]证明加深网络的深度和宽度可以在一定程度上提高网络的性能,残差模块使用卷积路和跳级路的方式既提取了较高层次的特征,又保留了原有层次的信息,不改变尺度,只改变深度。为了提高人体姿态估计网络的性能,沙漏网络就是基于残差模块设计,沙漏中的每个小模块代表了一个残差单元。
但是在特征图传递的过程中,不是所有的特征通道都对特征图的学习有用,因此,要根据特征通道的重要程度去抑制无用的特征并且提升有用的特征,从而提高小尺度关键点的识别效果。L.Shen等[9]提出的SENet,可以通过学习的方式自动获取到每个特征通道的重要程度,根据loss去学习特征权重,使得有效的特征映射权重变大,无效或者效果小的特征映射权重变小,从而达到更好的训练效果。因此,受SENet的启发,使用融入注意力机制的残差模块(attention residual module,ARM)试图在特征图的传递过程中提高有用特征图的权重,降低无用特征图的权重,从而提高小尺度关键点的检测效果。原始残差模块和融入注意力机制的残差模块结构如图4所示。
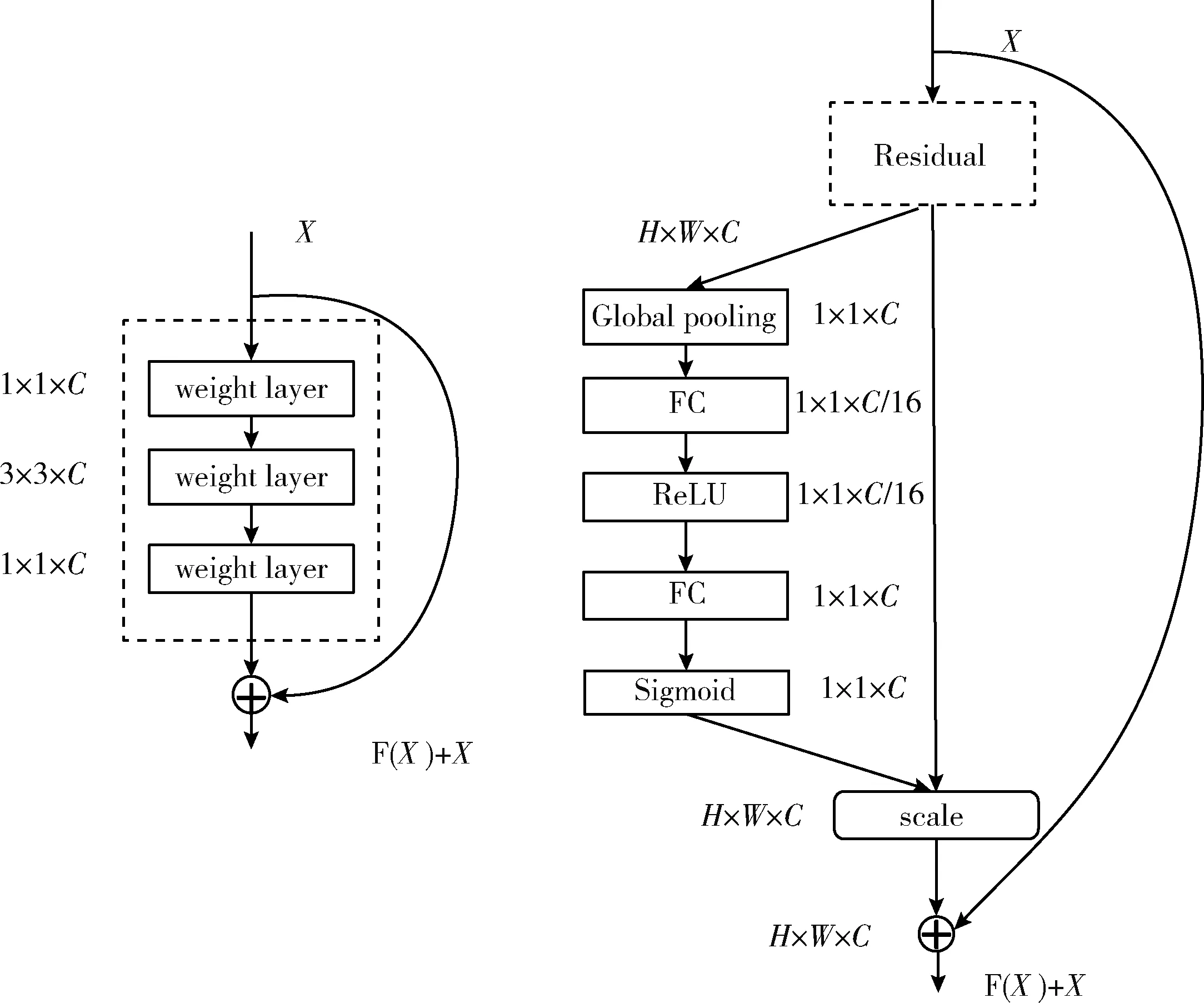
图4 原始残差模块和融入注意力机制的残差模块结构

(1)在Squeeze操作中,对输入V进行全局池化操作得到通道统计量z∈RC, 如式(1),其中uc∈RH×W, 使用式(1)将H×W×C的输入转换成1×1×C的输出,从而得到了全局描述特征
(1)
(2)在Excitation操作中,为了降低模型复杂度以及提升泛化能力,使用两个全连接层的bottleneck结构。在第一个全连接层中把通道数减少为原始通道的1/16;然后经过一个ReLU层激活;再使用一个全连接层恢复原始维度;接着经过Sigmoid函数获得0~1之间归一化的权重,得到的注意力权重s如式(2);最后通过一个缩放(scale)操作将归一化后的权重加权到每个通道的特征上,增加对关键通道的注意力,最终得到重新调节变换的输出如式(3)所示
s=Fex(z,W)=σ(g(z,W))=σ(W2(δ(W1(z))))
(2)
(3)
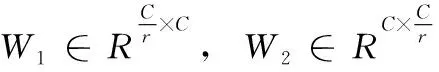
同时,融入注意力机制后的残差模块加深了整个网络,这在一定程度上会提高网络识别的准确率,其中的跳级路可以让来自深层的梯度能直接畅通无阻地去到上一层,使得浅层的网络层参数得到有效的训练,从而解决网络梯度消失的问题,更好地优化网络性能。
2.3 其它改进
基于自顶向下的姿态估计算法的检测精度同时要依赖第一步的人体目标检测的效果,在此部分,本文选用YOLOv3作为人体目标检测模型。针对人体目标检测任务,对YOLOv3算法做了如下改进,改进后的网络为YOLOv3-person。
(1)修改anchor尺寸。原始YOLOv3算法中设置的anchor的大小是为了满足通用物体检测数据集PASCAL VOC或COCO而设计的,物体的类别至少包含20类,而本文只需人物这一类,需要根据当前任务的数据集重新设定anchor尺寸。通过使用k-means算法针对人物目标检测数据集,设置表1所示的9个anchor尺寸。从表1中可以看出由k-means聚类得到的anchor尺寸的长度均大于宽度,趋向于一个长方体,这与人体目标的特征是符合的。

表1 anchor尺寸大小
(2)使用SoftNMS[10]替代NMS。NMS(non maximum suppression)算法直接将大于某个阈值的边界框的得分置零,这样会将多人重叠情况下检测到的正确的边界框错误删除,造成人体目标的大量漏检。SoftNMS将阈值较大的框中分数较小的框的置信度大幅衰减,而不是直接去除掉,保证了在多人重叠情况下有相对较高的召回率,从而提高了人体目标检测的准确率。
3 实验结果
3.1 评估数据集
本文在MPII多人姿态估计数据集和MSCOCO关键点挑战数据集上验证了CA-SHN模型的有效性。
MPII多人姿态估计数据集由3844个训练组和1758个测试组组成,标记了16个人体关键点,同时包含2万多个单人姿态估计训练样本。本文使用单人姿态估计数据集所有训练样本和多人训练数据集中80%的样本训练网络,剩下20%数据用于验证。本文使用PCKh@0.5(Percentage of Correct Keypoints)作为评价指标,以人体目标头部作为归一化标准。
MSCOCO关键点挑战数据集包括10万多人的训练样本和大约8万人的测试样本,标记了18个人体关键点,训练集包含超过100万个标记的关键点。本文使用数据集中的test-dev子集作为测试集,测试指标是基于OKS(object keypoint similarity)的平均精度值(mean average precision,mAP),本文使用OKS阈值分别设为0.5, 0.05, 0.95时,对应的3个mAP的平均值,同时以AP@0.5、AP@0.75、AP(M)和AP(L)作为参考指标。
3.2 训练中的实现细节
在实验中,YOLOv3-person使用PASCAL VOC2007和VOC2012数据集中的person类进行训练,其余19个类别都被忽略。为了保证将人体目标区域完全提取出来,将检测到的目标框沿宽高各拓展20%,同时将输出图像resize到256*256像素作为关键点检测网络的输入。所有的代码基于Pytorch1.0框架编写。
在MPII数据集中,网络使用均方根梯度下降算法优化,初始学习率为2.5e-4,批处理大小为16,在第100和150epoch时,将学习率降低5倍,共训练180epoch。
在MSCOCO数据集中,同样使用均方根梯度下降算法优化,初始学习率为5e-3,批处理大小为16,在第100和150epoch时,将学习率降低10倍,共训练200epoch。
同时,Newell等经实验验证,堆叠4个沙漏网络,每个沙漏网络中使用2个残差模块将可以使用最少的参数达到相对最优的结果。因此,在实验中采取相同结构的网络设置。
3.3 实验结果
在MPII和MSCOCO数据上验证了本文方法的有效性,实验结果见表2、表3。图5和表2分别显示了在MPII数据集上测试的PCKh曲线图和部分单个关键点的实验结果。可以看出,在MPII数据集中,本文的方法总体性能要优于之前的一些姿态估计方法和堆叠沙漏网络(stacked hourglass networks,SHN)。相比较于堆叠沙漏网络,本方法在总体PCK@0.5提升了3.2%,同时在脚踝、膝盖、手腕和手肘等小尺度关节上的检测效果都有所提升,验证通道混洗模块可以更好地识别被遮挡的关节,融入注意力机制的残差模块可以更好地关注小尺度的姿态。
从表3中看出,在MSCOCO数据集上,虽然本文的方法在mAP上略低于之前的方法,但是在AP@0.75和AP(M)上要优于之前的方法,同时本方法与堆叠沙漏网络相比,各种评价指标的精度均有提升。
CA-SHN模型将为每个关键点生成热力图,本文在COCO数据集中测试多人图像检测的热力图效果,热力图效果如图6所示,包括整体热力图和每个关键点的热力图。

表2 MPII数据集实验结果(PCK@0.5)/%
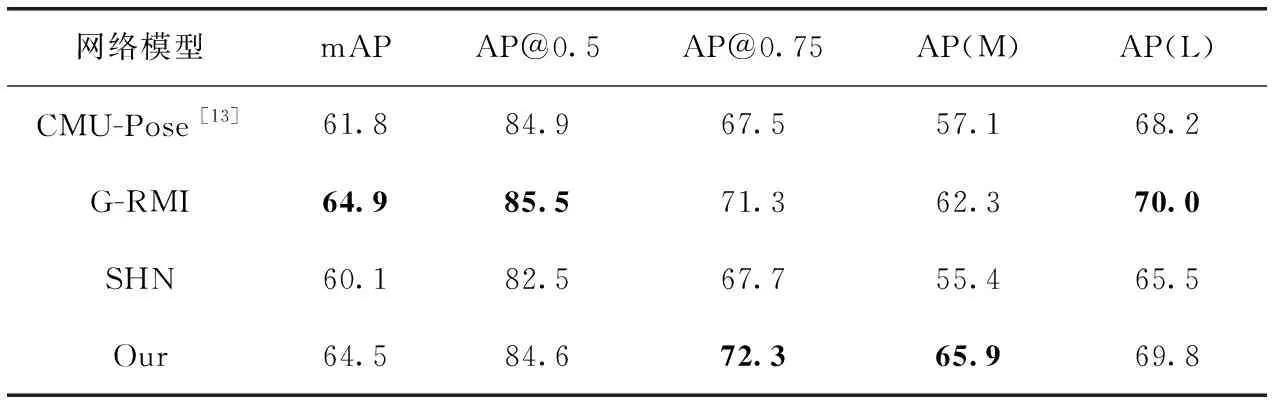
表3 MSCOCO数据集实验结果/%
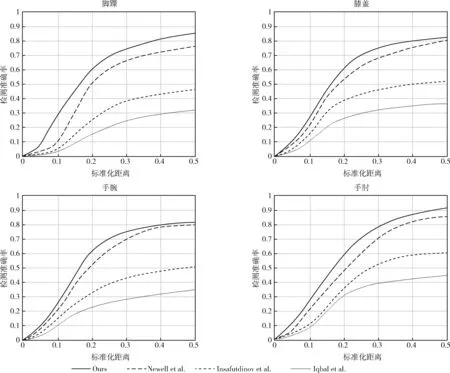
图5 MPII数据集的PCKh比较
结果表明,CA-SHN模型对耳朵、手腕、脚踝等小尺度关键点具有良好的检测效果,提高了对遮挡关键点的检测效果。
图7显示了CA-SHN模型对一些COCO数据集的姿态估计效果。如图7所示,我们的模型可以很好地处理各种姿势、遮挡和杂乱的场景。
3.4 对比实验
3.4.1 人物目标检测模型对比实验
对于人物目标检测模型,训练时将batch size设置为32,并使用前5个阶段进行预热训练,动量设置为0.9,初始学习率为1e-3,在150和250epoch时学习率迭代下降,共训练300个epoch,本文在多台配备NVIDIA 2080 GPU的机器上使用分布式训练。
将改进前的YOLOv3模型与改进后的YOLOv3-person模型同时在PASCAL VOC2007和PASCAL VOC2012数据集的person类上训练和测试,其中VOC2007含有人物目标的图像2095张,VOC2012含有人物的图像9566张,使用80%作为训练集,20%作为验证集。另外,对图像做了缩放(0.75-1.25)和旋转(-/+30度)的数据增强,实验结果见表4。
实验结果显示对于person这一类YOLOv3-person模型在VOC2007和VOC2012中达到了更好的检测效果,验证本文对YOLOv3提出的改进方法是有效的。
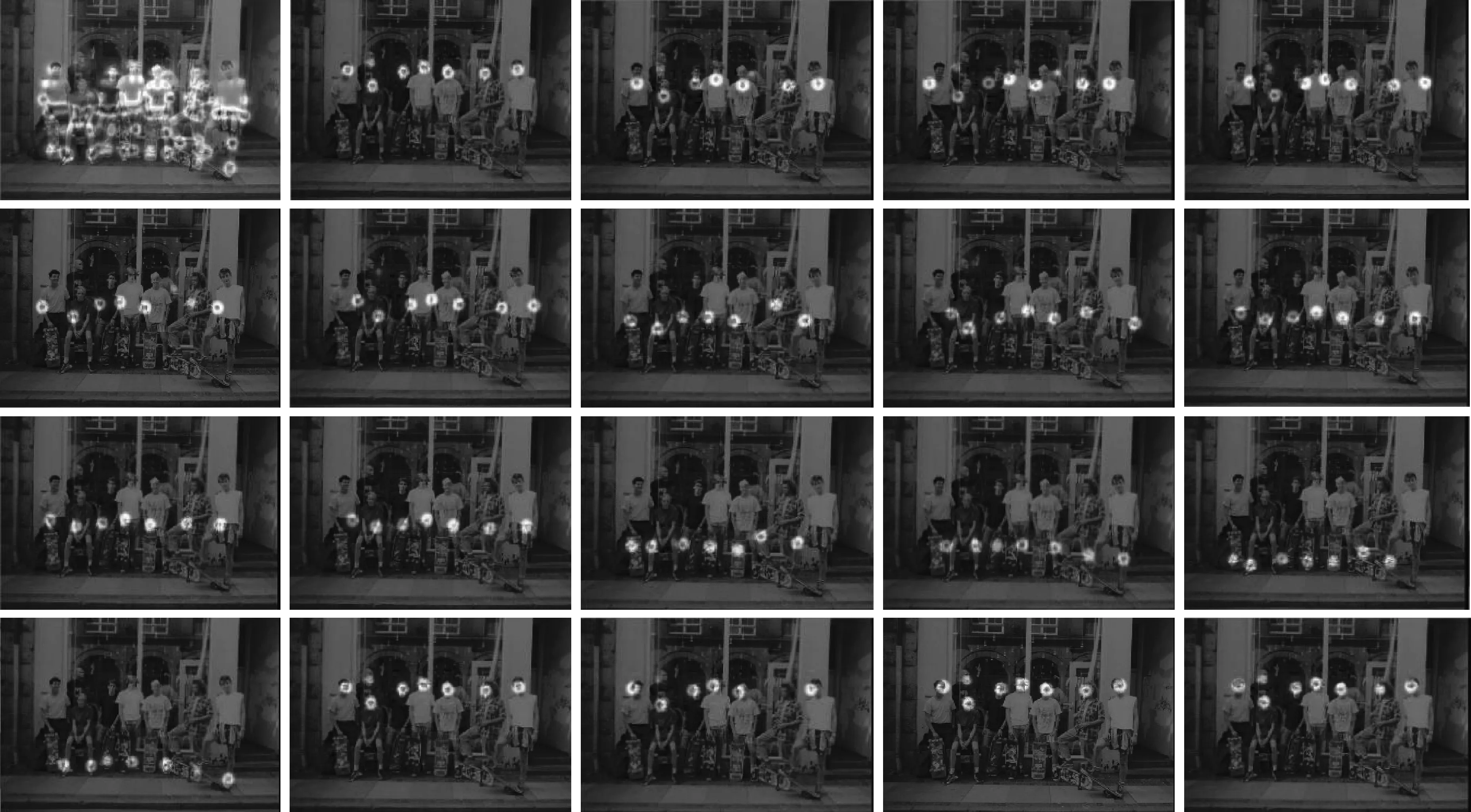
图6 多人姿态估计各关键点的热力图效果

图7 COCO数据集的姿态估计效果

表4 YOLOv3与YOLOv3-person在PASCAL VOC数据集上的实验结果/%
3.4.2 人体姿态估计方法对比实验
对于姿态估计器,本文使用两台配备NVIDIA 2080 GPU的机器上训练,批量大小为16。本文使用5e-3的固定学习率和RMSProp优化方法,共训练200epoch。
将堆叠沙漏网络、加入多尺度特征融合模块(channel shuffle module,CSM)、加入融入注意力机制的残差网络(attention residual module,ARM)和同时加入CSM,ARM的4网络结构在MSCOCO数据集上训练后进行了对比,见表5。实验结果表明,单独加入CSM模块和ARM模块都可以有效提高检测结果,同时加入时效果最佳。
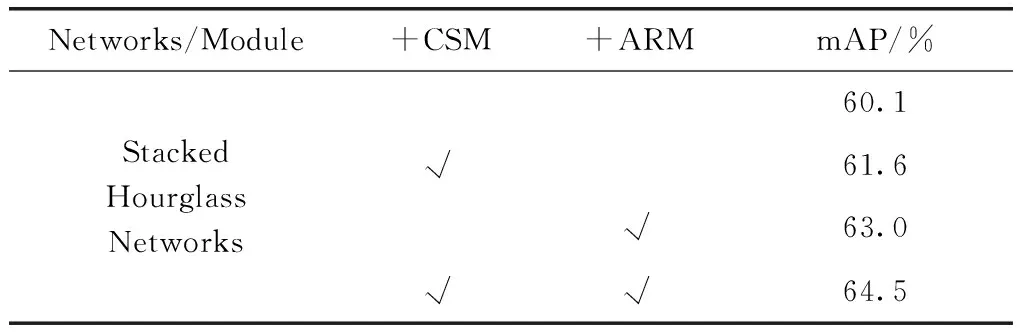
表5 在MSCOCO上的对比实验结果
4 结束语
本文提出了一种基于改进Stacked Hourglass网络的多人姿态估计方法,该方法结合基于YOLOv3改进的人物目标检测模型,设计了通道混洗模块和注意力残差模块。通道混洗模块帮助信息在特征通道间流动,注意力残差模块使模型对各个通道更具有辨别能力。通过在MPII和MSCOCO挑战数据集上的对比实验,可以看出本文的方法相比于堆叠沙漏网络,在手腕、脚踝等小尺度关键点的检测精度提高了2%左右,总体PCK@0.5提升了3.2%,同时在面对多人姿态估计时存在的关键点遮挡时的检测效果也有所提高,验证了本文提出的方法能有效提高多人姿态估计的识别率,同时为多人的姿态估计提供了一种方法。
