基于和声搜索机制的特征选择与文本聚类分析
2022-03-01王永刚王文慧曹传剑王晓燕
王永刚,李 靖,王文慧,曹传剑,王晓燕
(1.青岛黄海学院 通识教育学院,山东 青岛 266427;2.青岛黄海学院 大数据学院, 山东 青岛 266427;3.青岛黄海学院 教学工作部,山东 青岛 266427; 4.青岛黄海学院 智能制造学院,山东 青岛 266427)
0 引 言
文本聚类的目标是将巨量文本信息划分为若干文本群组的过程[1,2],常应用于文本数据挖掘领域[3]。矢量空间模型VSM是最常用的文本特征表征模型,该模型以矢量权重的形式对文本特征进行表示,文本信息中的每个词条均被描述为一维权重空间。因此,特征的高维度特性和稀疏特性,以及充斥在文本中的冗余特征成为影响文本聚类准确性的主要问题[4]。
文本特征一般由有用特征和无用特征组成。无用特征是具有噪声、不相关性和冗余的特征,需要从文本中剔除。特征选择的目标是搜索文档中的有用特征最优子集,以此获取更精确的文本聚类[5]。特征选择主要解决如何准确获取有用特征[6,7]和如何改善文本聚类性能两个问题。文本聚类的目标是将文本集合划分为若干群组,是非监督学习领域中的一种有效手段。文本聚类算法的最终目标是搜索最优解将集合进行划分,且算法基于目标函数和适应度函数标准执行进行搜索。
针对以上分析,设计了一种基于和声搜索机制的特征选择算法。算法的主要目标是借助于和声搜索的寻优机制降低文本初始特征维度,剔除无用特征,选择有用特征最优子集,以此提升文本聚类准确度。
1 相关工作
文献[8]为了改进传统K均值法随机性选择初始质心的不足,引入了样本局部密度指标,改善了聚类性能。文献[9]利用语义K均值解决了特征词条稀疏性问题,在质心选取上利用最大词频克服了初始质心敏感性。文献[10]基于后缀树思想设计了半监督自适应多密度聚类算法,利用K最近邻传播扩展簇标签,适应于多密度不平衡文本数据。文献[11]提出基于粒子群优化的特征选择算法PSOTC,通过改进惯性权重提升粒子寻优性能,数据集测试结果表明新的特征选择下的文本聚类在准确率和效率均有提升。文献[12]设计了基于遗传算法的特征选择算法GAFSTC,以此改善聚类性能。算法首先通过遗传算法生成新的特征子集,再将其输入K均值算法,通过这种两阶段的优化方式收集最优信息性特征,实验中的聚类准确率得到了有效提升。传统卡方统计法在特征选择上忽略了词频和词条分布,对此,文献[13]提出一种基于特征词频率分布函数的特征选择算法。这种过滤特征选择算法效率虽然有所提高,但特征子集求解精度低的问题依然没有得到有效解决。
2 文本预处理
(1)词语切分。词语切分的目标是将文本流进行分割,生成符号、词语、句子或其它有意义的元素(移除空格信息)。
(2)移除终止词。文本文档中的一些常规的、高频率词语,如but、and、be、in以及其它一些常用词汇,通常会具有较小的权重及较高的出现频率。该类词语会影响文本聚类效果,因此需要在预处理过程中将其移除。该类终止词总计有571个。
(3)提取词干。主要目标是移除词语的前后缀,使其拥有相同词根。如:insect、section、subsect这3个词,拥有相同词根sect,在剔除前后缀后,即可得到一个词根,可理解为词条特征。常规词干提取方式为Porter提词器。
(4)词条权重TF-IDF。文本数据挖掘领域中,词条权重策略可用于为文档中的词条分配合适的权重值以改进词条类型划分(即辨别力)。词条权重TF-IDF是一种常用的计算文档词条权重的计算与度量方法,根据词条频率TF和逆文档频率IDF计算,令di为一个文档,表示为一个词条权重矢量di=(wi,1,wi,2,…,wi,j,…,wi,t)。 以下公式用于计算词条权重值
(1)
式中:n为文档总量,tf(i,j) 为文档i中词条j的出现频率,wi,j为i中词条j的权重,idf(i,j) 为逆文档频率,df(j) 为含有特征j的文档数。
3 基于和声搜索机制的特征选择
文本特征选择的目标是寻找最优的文本特征子集,以改进文本聚类结果。整个过程如下:首先,按第2节中的方法,对文本进行预处理,即先将文本文档集合形式化为文本数据集,然后经过文本中的词语切分、终止词移除、提取词干、计算词条权重值,并通过矢量空间模型基于词条权重值将原始文本表示为标准文档模式。该过程如图1所示。

图1 预处理
其次,利用和声搜索机制过滤无用文本特征,生成最优特征子集,即特征选择优化。图2是该阶段的示例图,和声搜索机制用于搜索信息性文本特征子集,在每个文本文档上均运行和声搜索过程。最终和声搜索将结合所有搜索文本生成信息化特征集合。
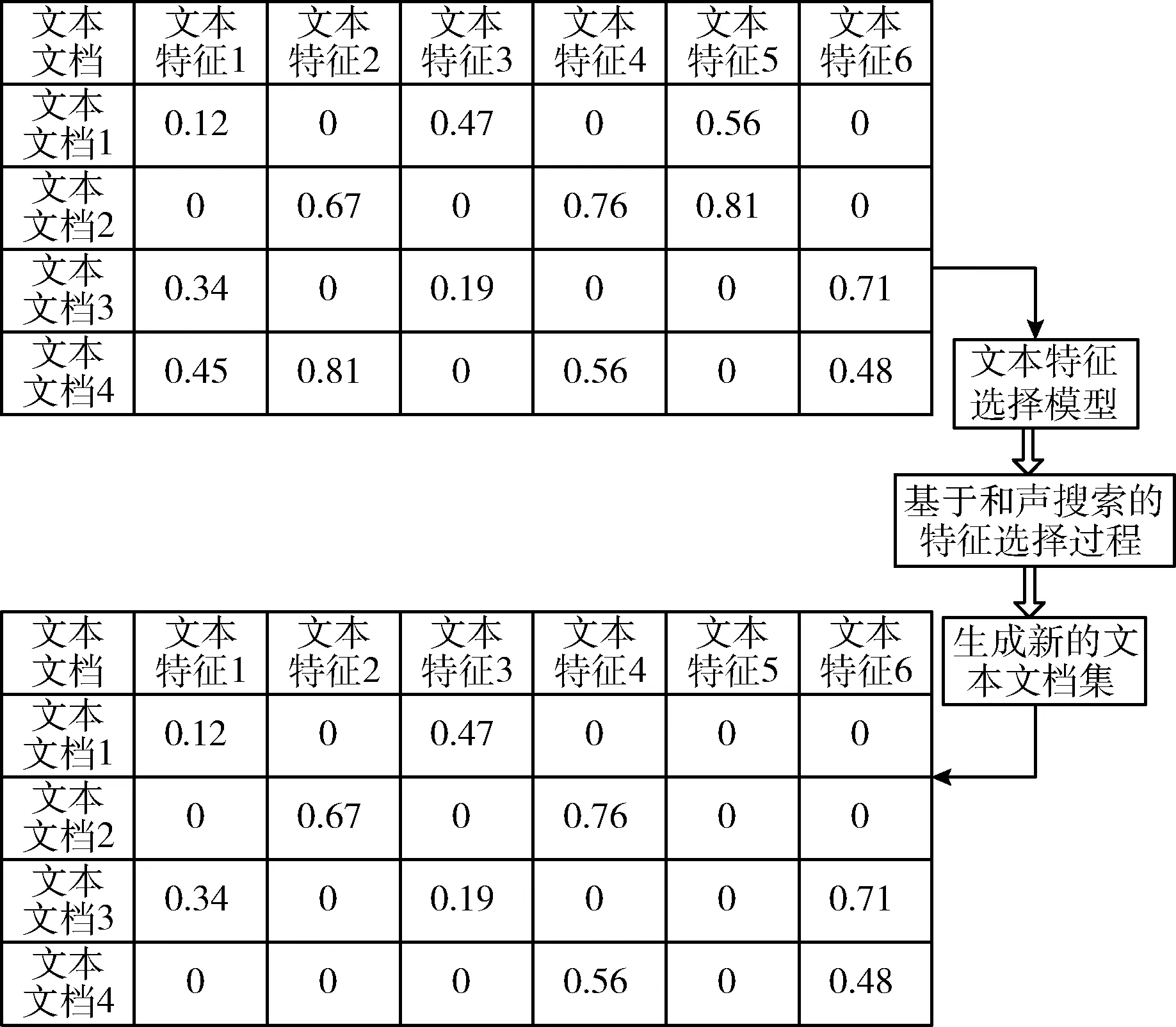
图2 特征选择
最后,利用K均值聚类方法进行聚类划分,如图3所示。
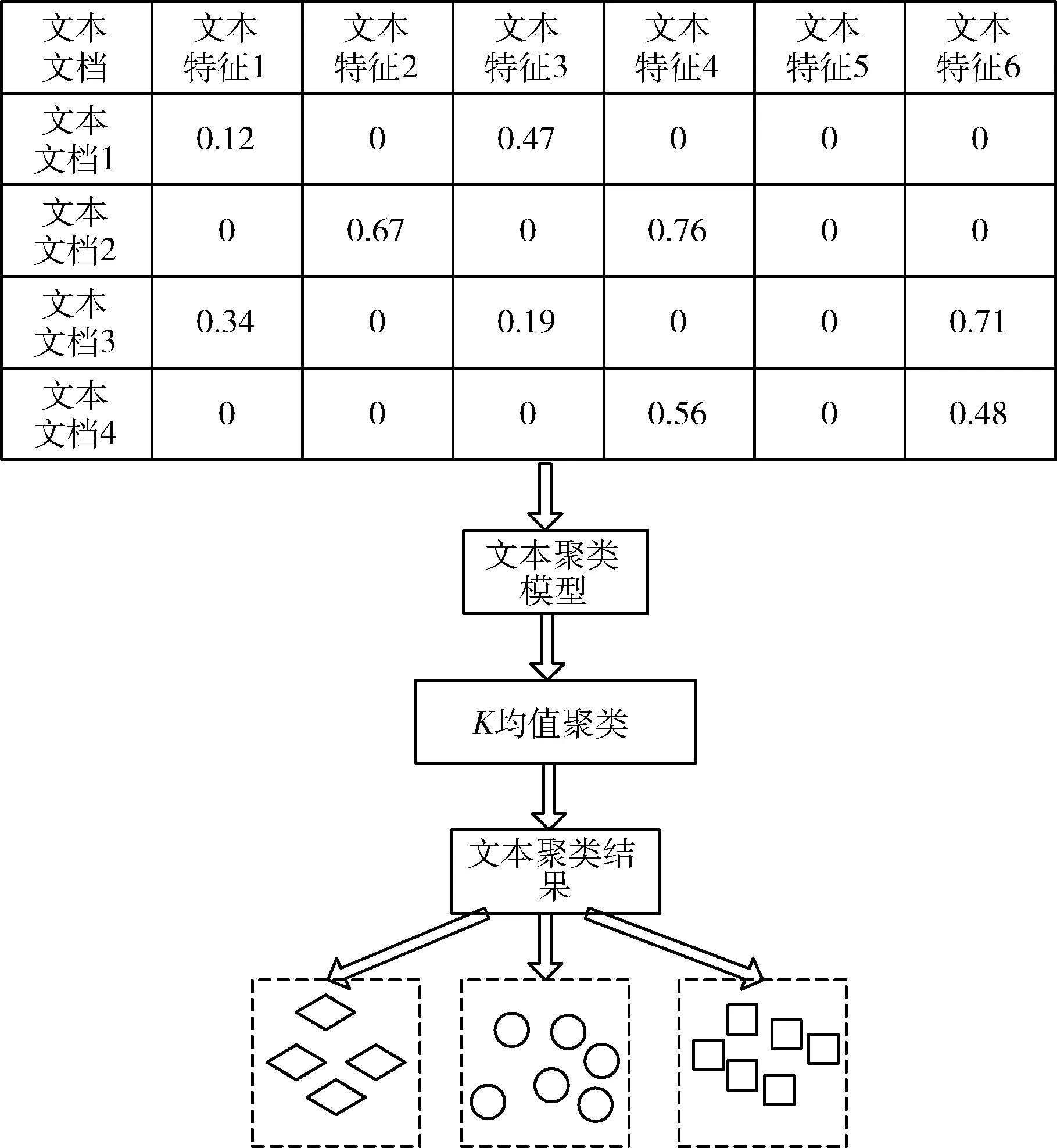
图3 聚类
3.1 特征选择模型
特征选择即生成最优特征子集的优化问题。令初始特征集合fi={fi1,fi2,…,fit}, 其中,t为唯一特征量,i为文档序号。令sfi表示新的特征子集,sfi={si1,si2,…,sij,…,sim}, 其中,m表示数据集中所有特征的新数量,如果sij=1,表明文档i选择特征j为重要特征;如果sij=0,则为非重要特征。
3.2 解的表达
利用和声搜索机制进行文本特征选择,首先需要随机生成初始解,然后以和声搜索迭代改进直到得到全局最优解。文档中每个唯一词条可理解为搜索空间中一个维度。表1为一种特征选择解。
表1所示特征选择解的具体含义是:X表示特征选择的一个解。若位置j=1,则特征j包含在特征子集中;若位置j=0,则特征j不在最优特征子集内;若位置j=-1,则特征j不是初始文档中的特征词条。
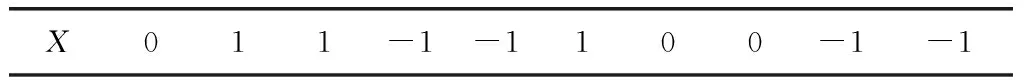
表1 特征选择的解表示
3.3 适应度函数
适应度函数用于评估和声搜索解的质量。每次迭代中需要计算和声搜索解的适应度值,拥有最高适应度值的解作为最终的特征选择最优解。利用平均绝对差MAD作为算法的适应度函数。MAD可以通过计算特征权重的均值差为特征分配权重值,然后计算xi,j的均值与中值之差,具体为
(2)
(3)
式中:xi,j为文档i中特征j的权值,根据式(1)计算,ai为文档i的所选特征量,t为特征总量,x′i为矢量i的均值。
3.4 和声搜索过程
和声搜索算法可以随机生成若干和声记忆库解,并不断改进和声记忆库以获取最优解,即最优的信息化特征子集。每一位音乐家,即可视为一个文本词条,可作为搜索空间中的一个维度。和声搜索解可以通过式(2)的适应度函数进行评估,以便得到最优和声,即全局最优解。利用和声搜索机制进行特征选择的具体过程如下所示:
步骤1 对问题进行初始化,并初始化和声搜索相关参数。文本特征选择问题可定义为一个最优化问题,并通过最大化适应度函数值f(x)得到最优解,其中,xi表示表1所示特征选择解中第i个位置上的值。基于和声搜索的特征选择的相关参数设置如下:生成的和声记忆库解的总数量HMS=50,HMCR=0.9,表示是否从记忆库或随机方式决定决策变量的选择概率,PARmin=0.45,表示音高调整率的最小值,PARmax=0.9,表示音高调整率的最大值,bwmin=0.1,表示最小带宽,bwmax=1,表示最大带宽,NI表示最大迭代次数。
步骤2 初始化和声记忆库。算法包括和声记忆库HM矩阵方式的解的存储,以随机生成和声记忆库解HMS填充,表示为
(4)

(5)
和声记忆库由式(4)所示的矩阵创建,其中,LBi表示下限值,UBi表示上限值。
步骤3 创建新解。根据以下3个规则生成新解:记忆考虑、纵向倾角调整和随机选择。具体过程如算法1所示
X′=(x′1,x′2,…,x′t)
(6)
算法1:创建新解
(1)input: Harmony memoryHMsolutions
(2)output: a new solution as vector represented in Equ.(6)
(3)for eachj∈[1,t] do
(4) ifrand(0,1)≤HMCRthen
(5)x′j=HM[i][j] wherei~U(1,2,…,HMS)
(6) ifrand(0,1)≤PARthen
(7)x′j=x′j±rand×bw,wherer~U(0,1) andbwis distance bandwidth
(8) elsex′i=LBj+rand×(UBj-LBj)
(9) end if
(10) end if
(11)end for
和声搜索解根据PAR(I)和bw(I)两个参数动态的决定收敛状态,如果[0,1]间生成的随机生成数小于或等于PAR的概率,则新的决策变量x的决策方式为
(7)
(8)
式中:PAR(I)为一个新解的纵向倾角调整率,I表示当前迭代数,Imax为最大迭代数,bwmin为最小调整率,bwmax表示最大调整率。
步骤4 更新记忆库。如果生成的新解拥有更高的适应度,将取代较差的和声解。
步骤5 检查终止条件。当和声搜索达到最大迭代次数时将终止,和声搜索中的HMCR和PAR两个参数有助于搜索全局解和局部解。
4 文本聚类
利用和声搜索机制得到特征最优子集后,进一步设计基于K-mean算法的文本聚类算法,更新聚类质心并做相似性度量。
4.1 文本聚类模型
给定一个文本文档集合D,D=(d1,d2,…,dj,…,dn), 其中,n为集合D的文档总量。聚类目标是以文档i与质心j间的余弦相似度达到最大的同时,将文本划分为若干子集。将余弦相似度定义目标函数,评估算法的可行性和效率。
4.2 计算聚类质心
利用K均值进行文本聚类过程中,每一次迭代过程中需要更新聚类质心,以实现全局搜索。令ck为聚类中心,ck=(ck1,ck2,…,ckj,…,ckK), 其中,ckj表示聚类j的质心。聚类质心更新如下
(9)
式中:akj表示聚类j的文档总量,di表示聚类质心cj的第i个文档,ri表示聚类i中的文档总量。
4.3 相似性度量
余弦相似度是文本文档聚类问题中常用的相似性度量方法,可以用于计算代表文档和聚类质心这两个矢量间的相似性。文档d1与质心d2两者间的余弦相似度为
(10)
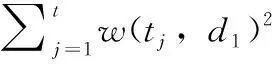
4.4 融入特征选择的K-mean文本聚类算法
K均值聚类算法的目标是将集合D=(d1,d2,…,dn) 划分为K个聚类,同时需要满足将每个文档分配至最为相似的质心,而文档与质心间的相似性则由余弦相似度式(10)进行衡量。具体地,算法利用规模为n×K的X作为初始文档聚类矩阵,n为文档总数,K为聚类量。文档以权重矢量形式表示为di=(wi1,wi2,…,wij,…,wit),t为文本特征总数,算法搜索空间为n×K。
融入特征选择的K-mean文本聚类算法过程如下:
步骤1 将每个文档表达为词条权重矢量;
步骤2 基于特征选择解X,随机初始化生成聚类质心;
步骤3 计算每个文档与所有聚类质心的相似度,将文档分配至相似度最高的聚类质心;
步骤4 根据式(9)更新聚类质心;
步骤5 重复执行多目标K-mean文本聚类过程,直到达到终止条件或最大迭代次数。
具体过程的伪代码如下:
算法2:K-mean文本聚类
输入:文本文档集合D和聚类数K
输出:集合D与聚类间的分配关系
(1)迭代终止条件
(2)随机选取K个文档作为初始的聚类质心, 表示为C=(c1,c2,…,cK)
(3)将矩阵X的所有元素初始化为0
(4)for eachdinD
(5)j=argminkbased onCos(di,ck)
(6)end for
(7)更新新的聚类质心
(8)结束
5 性能评测
利用Matlab对基于和声搜索机制的特征选择及K-mean文本聚类算法进行仿真测试。以下分别对测试数据集的特征、性能评估标准以及实验结果和分析讨论做出描述。表2是4种标准文本数据集的特征,包括数据集名称、包含的文档数量、文档中包含的词条数目以及聚类数量。文本数据集可用于分析和比较利用和声搜索机制后的K-mean文本聚类算法和未使用特征选择的文本聚类算法间的性能。

表2 数据集特征
5.1 评估指标
利用一个内在评估指标:相似性度量指标,以及两个外在评估指标:准确率AC和F度量(F-measure)进行算法性能评测。
F-measure:F-measure是一种用于文本聚类领域的常用度量指标,用于表示求解的聚类结果中与原始分类匹配的百分比。主要由聚类精确率P和聚类召回率R两个要素决定,两个因素的计算方法分别为
P(i,j)=ni,j/nj
(11)
R(i,j)=ni,j/ni
(12)
式中:ni,j为聚类j中分类i的成员数量,nj为聚类j的成员数量,ni为分类i的成员数量。对于聚类j和分类i的F-measure 为
(13)
因此,文本中的所有聚类的F-measure可计算为
(14)
准确率AC。准确率AC用于计算文档分配至相应聚类正确比例,计算方法为
(15)
式中:n对应每个聚类的文档数量,K为聚类总数。
5.2 结果对比讨论
对两种类型的K-mean文本聚类算法进行仿真测试,一种是没有利用特征选择的K-mean文本聚类算法,命名为KMTC,另一种是利用了和声搜索机制特征选择策略的K-mean文本聚类算法,即本文设计的算法,命名为FSHSTC。对于数据集DS1和DS2而言,FSHSTC算法在所有度量指标上均优于未使用特征选择策略的文本聚类算法KMTC,在DS4数据集中则FSHSTC算法在F-measure指标上有所改进。为了进行公平的比较,实验结果均是30次仿真实验得到的均值结果。和声搜索机制是一种全局搜索算法,每一次运行均需要进行500次迭代。实验中500次迭代足以使得和声搜索的全局搜索过程发生收敛。K-mean是一种局部搜索算法,因此,100次迭代也足以使该算法在文本聚类中进行局部搜索的收敛。表3对比了聚类算法的聚类质量表现。所提出的基于和声搜索机制的特征选择在4种基准的文本数据集测试下均有性能指标上有所改善。信息化特征最优子集的选择是文本聚类的关键步骤,它需要处理大量文本特征并寻找近似的最优聚类结果。所提出的FSHSTC算法在使用了特征选择后在文本聚类上明显表现更好,降低了特征数量,具体地,在DS1数据集中将特征数量从1725降低至1225,在DS2数据集中将特征数量从5773降低至351。总体来看,FSHSTC算法在DS1、DS2和DS43个数据集上均克服了K-mean算法在文本聚类上固有的不足。
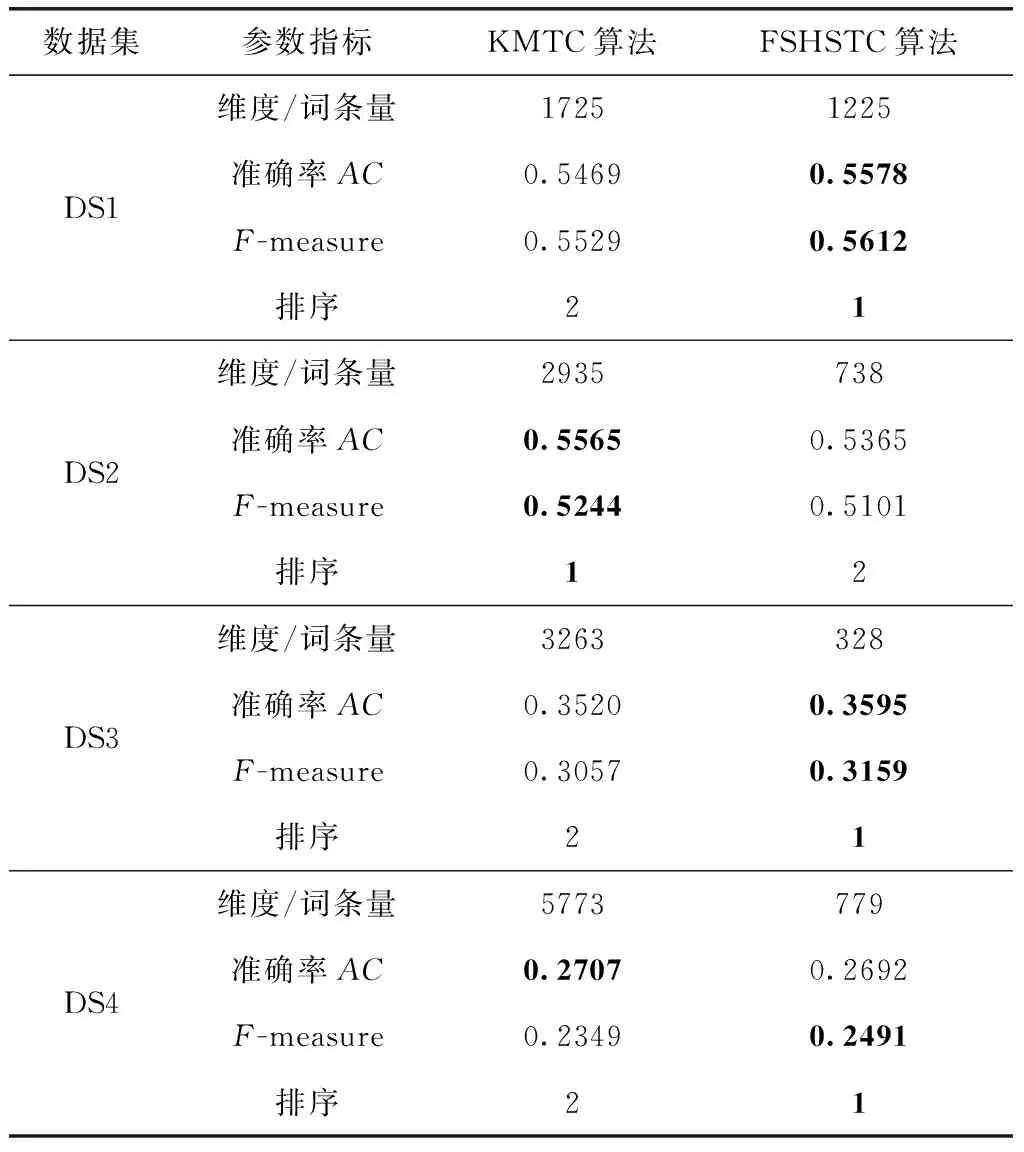
表3 聚类质量对比
图4观察采用不同的特征选择算法后,最优特征子集比较原始文本特征集合的下降百分比。除KMTC算法以外,再引入GAFSTC[13]做进一步的性能比较。从4种文本数据集的测试结果来看,本文设计的FSHSTC算法在不同数据集中的特征子集选择规模上,降维比例是最高的,说明该算法可以尽可能地减少无用非信息化特征的在最优特征子集中的出现比例,降低特征维度,建立有用特征为新的子集。以此最优特征子集作为基础的文本聚类,会生成更好的聚类结果。
图5观察在4个测试数据集中算法进行特征选择时的适应度变化,验证算法收敛性。收敛适应度即为算法得到的最优特征子集的最优适应度。从实验结果观察,本文设计的基于和声搜索机制的特征选择FSHSTC算法具备最好的收敛性能,处于收敛处的适应度值是所有算法中最高的,适应度比GAFSTC算法和KMTC算法分别高于8.65%和13.17%,验证本文设计的和声搜索优化特征选择的思路是有效可行的。
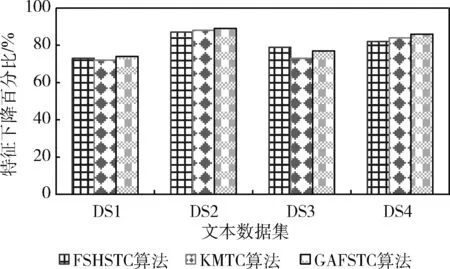
图4 特征下降率
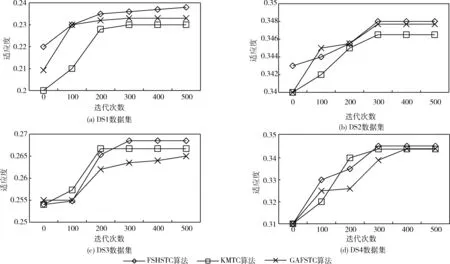
图5 4种测试文本数据集的特征选择收敛性
图6观察3种算法在所有4个测试数据集中求解特征选择解的计算时间。计算时间少,表明算法求解最优解的迭代数越少,收敛速度更快。根据图6的结果,本文的FSHSTC算法在测试数据集中都得到了最小计算时间,计算效率最高,说明基于和声搜索机制的特征选择算法比较基于遗传算法的特征选择算法GAFSTC和未使用特征选择优化的KMTC算法均是更优的。
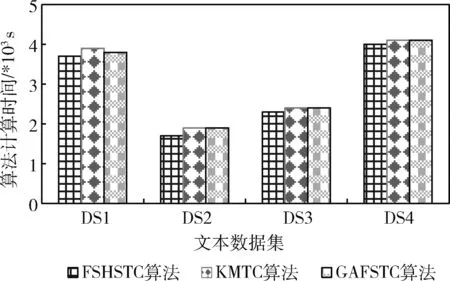
图6 特征选择计算时间
6 结束语
本文提出一种基于和声搜索机制的文本特征选择算法,算法以词频逆文本频率指数评估特征词条,然后通过和声搜索的记忆考虑、纵向倾角调整和随机选择3种特征选择新解更新规则,迭代搜索最优特征子集;最后以最优特征子集为基础,以K均值进行文本聚类。实验结果表明,算法可以有效降低特征维度,并提升聚类准确率。进一步的研究可以尝试对和声搜索过程的相关参数进行寻优,得到最优的参数取值范围,在提升和声搜索机制的性能的前提下,使特征选择求解性能得到进一步提高。
