基于改进级联R-CNN的酒瓶瑕疵检测
2022-03-01张玉蓉李升凯朱庆港姜旭辉
高 林,张玉蓉,李升凯,朱庆港,姜旭辉
(青岛科技大学 自动化与电子工程学院,山东 青岛 266100)
0 引 言
瓶装酒的生产过程中,受到原材料质量(酒瓶)以及加工工艺(灌装)等因素[1,2]的影响,产品中可能存在各类瑕疵影响产品质量。一条生产线需要有3个到5个质检环节分别检测不同类型的瑕疵[3]。由于瑕疵种类多样,有的瑕疵体积小不易察觉,瓶装酒厂家往往需要投入大量人力成本用于产品质检。但人力观察往往存在漏检、难以量化、检测速度较慢等问题。
机器视觉系统采用高分辨率摄像技术,光学照明技术配合机电控制技术以及实时图像处理技术,具有很好的实时性、准确性及稳定性的性能[5]。
近年来,基于卷积神经网络[6](CNN)的目标检测算法异军突起,相比传统目标检测算法不论是检测精度,还是速度都有较大的提升。其中比较有代表性的是Ren等[7-9]提出的R-CNN系列为代表的两阶段目标检测算法,此类方法精确度效果较好,但速度稍慢。另外一种为Redmon等[10]提出的YOLO(You only look once)系列的一阶段算法,该方法将要检测的图片划分多个网格,每个网格独立检测目标,速度较快但检测精度不高。由于酒瓶瑕疵检测任务对检测精度要求较高,所以选用两阶段的目标检测算法。
本文以实际生产中瓶装酒的瑕疵检测为研究目标,以Zhaowei Cai等[11]提出的Cascade R-CNN为基本框架,结合目标检测的最新技术,提出一种改进的Cascade R-CNN算法,在检测速度基本持平的情况下,对酒瓶的瑕疵检测精度有了明显的提升。
1 算法描述
本文提出的算法检测框架主要基于Cascade R-CNN模型的改进模型,具体的:①提出基于聚类算法[12,13]的Anchor生成策略;②使用多尺度融合检测的骨干网络[14](ResNet-FPN网络)代替原先的VGG网络;③感兴趣对齐层[15](ROI Align)代替感兴趣池化层(ROI Pooling)。
1.1 级联区域卷积神经网络(Cascade R-CNN)
经典的算法模型Faster R-CNN在区域提案网络生成区域提案的过程中,需要通过锚框(anchors)与真实框(ground truth)的交并比(intersection over union,IOU)来判定锚框为前景或背景。通常设置IOU=0.5时选出的前景框中含有较多的背景会造成很多的误检,而直接提高IOU的阈值会导致可用的前景框呈指数下降,训练正样本不足[16]。Zhaowei Cai等在Faster R-CNN基础上提出的Cascade R-CNN使得检测效果有了较大的提高,弥补了Faster R-CNN的IOU阈值设置困难的问题。
Cascade R-CNN通过级联3个回归器作为一种重采样的机制,逐阶段提高区域提案的IOU阈值,从而使得前一个阶段重新采样过的区域提案能够适应下一个有更高阈值的阶段,最终产生更高质量的区域提案,使得模型在检测速度损失较少的情况下,检测精度有了明显的提高。
1.2 基于K-means算法的Anchor生成策略

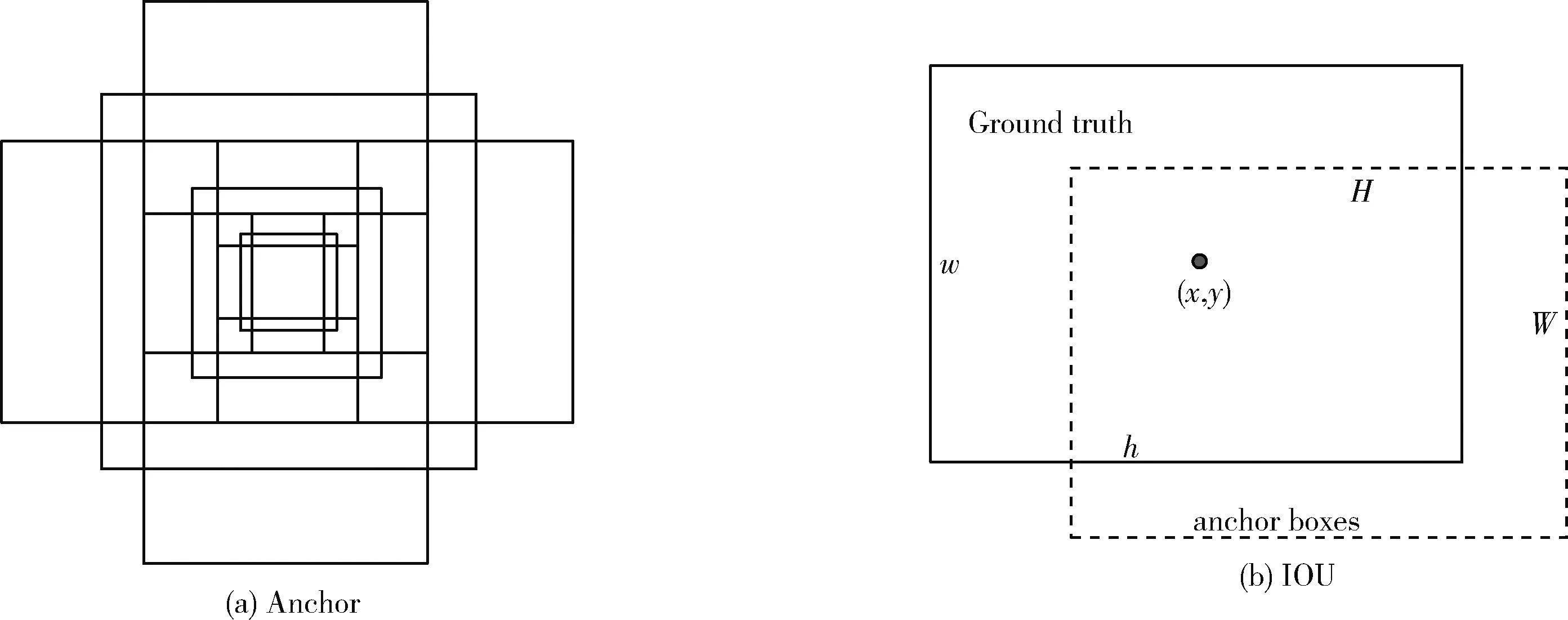
图1 Anchor与IOU
K-means算法是一种无监督的聚类算法。K-means算法通常对于给定的数据集,按照样本点之间的欧氏距离大小,将样本划分为K个簇。能够使输出的簇中类内相似度最小,类间差异尽可能大。常规K-means算法中采用的距离为欧氏距离
(1)
式中:K为聚类数,n为样本总数,xi为样本点,μj为聚类中心点。
可以看出如果使用欧氏距离大的anchor可能会产生较大的误差。本文提出使用目标检测的常用评价指标IOU来定义k-means中的距离度量如图1(b)所示
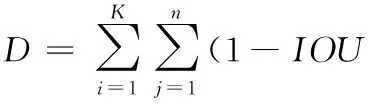
(2)
式中:K为聚类数,n为样本总数, (xj,yj,wj,hj) 为标注框的坐标值, (Wi,Hi) 为聚类中心点的坐标。所以通过聚类生成Anchor尺寸的步骤见表1。
1.3 多尺度检测网络(ResNet-FPN)
图像中存在不同尺寸的目标,而不同的目标具有不同的特征,利用浅层的特征就可以将简单的目标区分开来;利用深层的特征可以将复杂的目标区分开来。对此Tsung-Yi Lin等[14]提出的基于特征金字塔结构(FPN)目标检测网络,能够在多个不同特征图上分别提取区域提案,实现在多尺度预测。

表1 聚类生成Anchor scales流程
如图2所示,基于ResNet[14]的FPN骨干网络,将各个层级的特征进行融合,使其同时具有语义信息和强空间信息。
图2 ResNet-FPN网络结构
从图2中可以看出,ResNet-FPN骨干网络主要包括2部分:
(1)自下而上:将ResNet作为骨干网络,根据特征图的大小分为5个阶段。其中stage2、stage3、stage4、stage5每个阶段最后一层的卷积核输出分别定义为C2、C3、C4、C5,它们各自相对于原始图片的步长分别为 {4,8,16,32}。
(2)自上而下与横向连接:对C2、C3、C4、C5中的每一层经过一个1×1的卷积操作用以降低通道数,将输出通道全部设置为相同的256,将从最高层开始进行最近邻上采样,将卷积后的特征图与执行上采样后的特征图进行加和操作。在融合之后再次使用3×3的卷积核对融合后的卷积图进行处理以消除上采样的混叠效应。最终得到的特征图为 [P2,P3,P4,P5] 作为后续RPN网络的输入和R-CNN网络的输入。
1.4 感兴趣对齐层(ROI Align)
Cascade R-CNN的感兴趣池化层(ROI Pooling)就是将感兴趣的区域从特征图上划分出来,然后缩放成固定大小区域提案。但是在处理过程中会存在两次取整操作:①候选区域的位置信息 {x,y,w,h} 通常是小数,但为了方便操作会把它整数化;②整数化后的候选区域平均分割成k×k个单元,会对每一个单元的边界进行整数化。
从图3可以明显看出,经过两次整数化后可能会出现“不匹配问题(misalignment)”:候选区域与最开始回归选出来的区域会有一定的位置偏差,这个偏差会影响检测或者分割的准确度。
为了解决ROI Pooling的不匹配问题,使用He等[15]提出了ROI Align算法消除了不匹配的问题。具体的:取消整数化操作,保留浮点数坐标,并用双线性插值法[19]获得坐标为浮点数的像素点上的图像数值,然后将这些坐标点进行池化得到最终结果。ROI Align如图4所示。
可以看到ROI Align的算法步骤如下:
(1)遍历每一个候选区域,保持浮点数边界不做量化;
(2)将候选区域分割成k×k个单元,每个单元的边界也不做量化处理;
(3)在每个单元中计算固定4个坐标位置,用双线性内插值的方法计算4个位置的值,然后进行最大池化操作。

图3 ROI Pooling过程

图4 ROI Align
2 实验结果与分析
2.1 酒瓶瑕疵数据集
本次实验采用的数据来源于真实生产中采集的酒瓶瑕疵数据集,使用labelme软件将采集到的数据集进行标注,数据集共包含3个大类瑕疵:瓶盖瑕疵、贴标瑕疵、喷码瑕疵。3个大类里面又包含共10个小类:{瓶盖部分:瓶盖破损、瓶盖变形、瓶盖坏边、瓶盖打旋、瓶盖断点;标贴部分:标贴歪斜、标贴起皱、标贴气泡;喷码部分:正常喷码、异常喷码},最终划分到的训练样本图片4512张,测试样本2614张。训练集和测试集的标签数量见表2。
其中对应的各个类别瑕疵如图5所示。
2.2 聚类生成Anchor
选取所有标注的标注文件,从标注文件中提取出待检测目标的坐标值 (x,y,w,h) 将提取数的标注框的坐标值作为聚类算法的输入,通过对酒瓶标注数据坐标值的分析处理,聚类得出适合酒瓶瑕疵的anchor尺寸数据。具体的对标注数据进行如下处理:
(1)统计标注数据的长宽数据分布,使用聚类的方法选取anchor的基础边长(scales)
(3)

表2 数据集标注数量

图5 酒瓶瑕疵
(2)对标注数据的长宽比进行统计分析,选取合适的Anchor长宽比尺寸(ratios)。
其中对酒瓶数据的分析结果如图6所示。其中图6(a)中横轴为长宽比,纵轴为对应的样本数量;图6(b)中横轴为瑕疵的长,纵轴为瑕疵的宽。
Anchor ratios:在图6(a)中可以看出,标注数据的长宽比例存在十几种可能。所以在选取的过程中要保持两个原则:①Anchor ratios一般成对出现(乘积为1);②不能极端选择比例,选取过多比例会造成多余的计算。最终选择的ratios为{0.2,0.5,1,2.0,5.0}
Anchor scales:如图6(b)可以看出,通过聚类算法选出3组长宽数据,并根据公式求出3个基础边长。具体步骤见表2。最终得到3个聚类中心的坐标和基础边长分别为 {(35.68,35.19),(44.93,155.90),(145.65,355.80),35,83,227}。
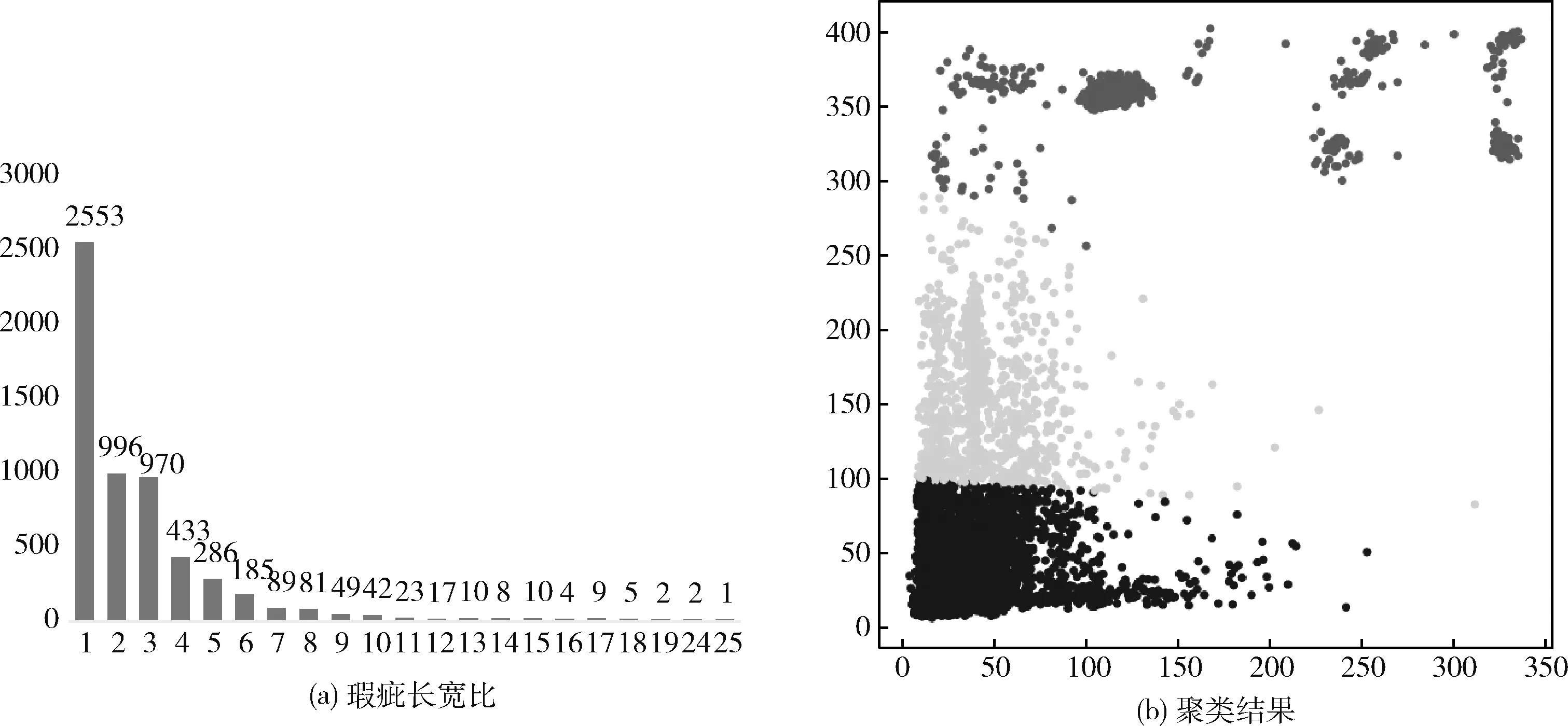
图6 酒瓶瑕疵标注分析
2.3 网络结构
为了验证本文设计算法的优越性,将本文设计的算法与几种目前最常用的基线检测器进行实验:Faster R-CNN和Cascade R-CNN检测模型。骨干网络是否使用ResNet-FPN,是否使用ROI Align取代ROI Pooling的感兴趣池化层。
Faster R-CNN:基础Faster R-CNN模型,骨干网络为VGG16[20]网络,输入图像经过骨干网络生成特征图,特征图经过区域提案网络生成感兴趣的区域,这些区域经过一个ROI池化层,得到128个ROI,后接两个全连接层,每个全连接层保留2048个单元,然后分别经过softmax分类和bbox回归网络。其中带ResNet-FPN和ROI Align的网络模型如图7所示。
Cascade R-CNN:级联R-CNN共有4个阶段,一个RPN和3个用于U={0.5,0.6,0.7} 的检测阶段,所有级联检测阶段都具有相同的架构。其中u=0.6和u=0.7分别使用了第二阶段和第三阶段的建议。带ROI Align的Cascade R-CNN结构如图8所示。

图7 Faster R-CNN+ResNet-FPN+ROI Align
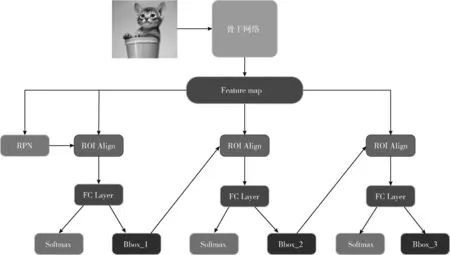
图8 Cascade R-CNN + ROI Align
3 实验结果与分析
本次实验采用所有算法模型均在同一个硬件设备上,采用相同的运行环境,以验证实验的公正性。具体的:CPU为Intel 至强 E3-1231,显卡型号为Tesla T4 16 G显存。操作系统为基于Linux的Ubuntu 18.04,Cuda-10.1,Python-3.6.9,PyTorch-1.5.1+cu101,与其对应的TorchVision-0.6.1+cu101。
3.1 不同anchor尺寸训练网络检测结果对比
如图9所示,左图为采用标准Cascade R-CNN所采用的anchor尺寸来训练模型的Loss曲线,右图为采用聚类出的anchor尺寸训练模型的Loss曲线,从图9中可以看出,未做anchor尺寸修改时,Loss下降比较平缓,训练模型收敛较慢,当训练次数到达9k代,模型还未收敛,相反的修改anchor尺寸后,Loss从2k代开始下降比较迅速,直到5k代Loss下降缓慢,到6k代以后Loss趋于稳定。由此可以得出根据k-means聚类出的anchor尺寸参数,能够有效加快模型训练的速度,加快模型收敛。其中横轴为训练迭代次数,纵轴为总的损失值。
从表3测试集上的检测效果可以看出,基于k-means算法聚类得出的anchor尺寸能够更好地适应酒瓶瑕疵检测,平均能够带来约9%平均精度的检测效果提升,具有广泛的实用价值。
3.2 消融实验
为了表明使用多尺度融合的骨干网络和ROI Align带来的检测效果的提升,将本文设计的算法与目前较为流行的基线检测器进行消融对比实验。将模型通过训练集和验证集进行训练和调试,当训练误差和在验证集上的验证精度不再发生变化时,保留出最好的训练模型。然后在测试集上进行测试,在测试集上测试性能见表4。
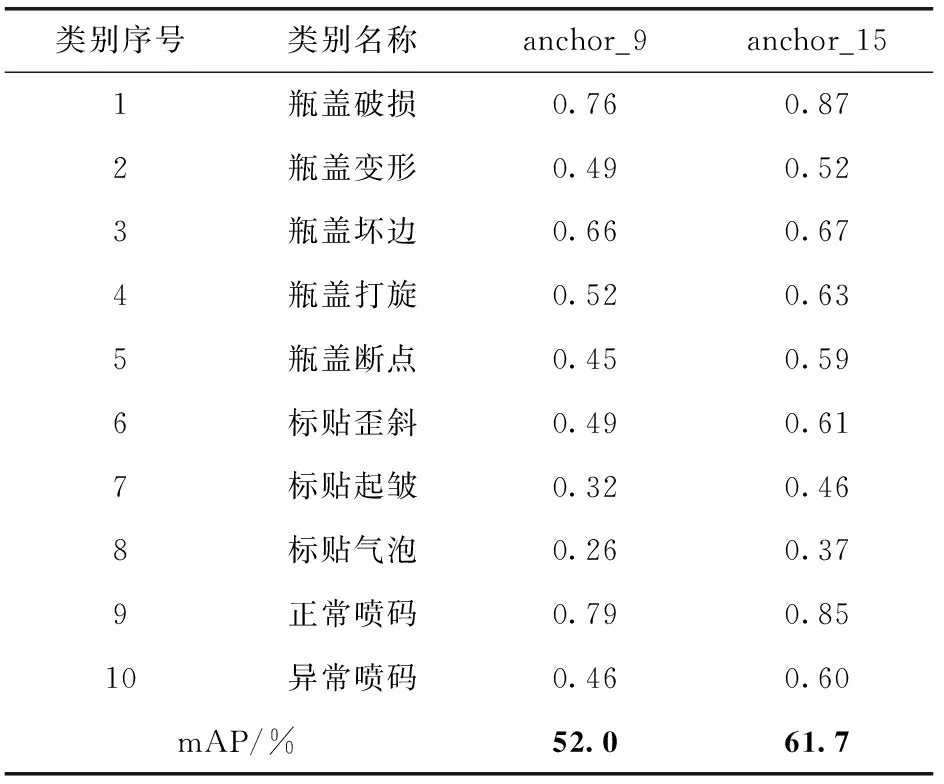
表3 anchor修改前后的测试效果对比
从表4可以看出,在自制数据集上,Faster R-CNN能够达到48.5%的平均精度,效果一般。通过ROI Align层替换ROI Pooling层能够带来大约4%的检测精度的提升,将骨干网络从VGG16网络替换为ResNet50-FPN网络,对小目标的检测具有较大的提升,能够使得模型具有更好的检测效果,大约达到60%的mAP。通过级联多个回归器的Cascade R-CNN算法模型,各个方面的精度都优于Faster R-CNN模型,mAP提升了将近13个百分点。本文改进的Cascade R-CNN网络达到了最优的检测精度,高达79.6%。检测结果如图10所示。
总的来时,通过使用多尺度融合的骨干网络和ROIAlign网络,能够有效提升检测的精度,但是在检测性能方面略有损失,从表中可以看出,ROI Align层对检测速度的影响较小,多尺度融合的特征提取网络会带来检测精度的提升,但同时会造成检测速度略有下降。可以看出,相比于Faster R-CNN检测模型,本文提出的改进Cascade R-CNN能够在检测速度损失很小的情况下大幅度提升检测精度。
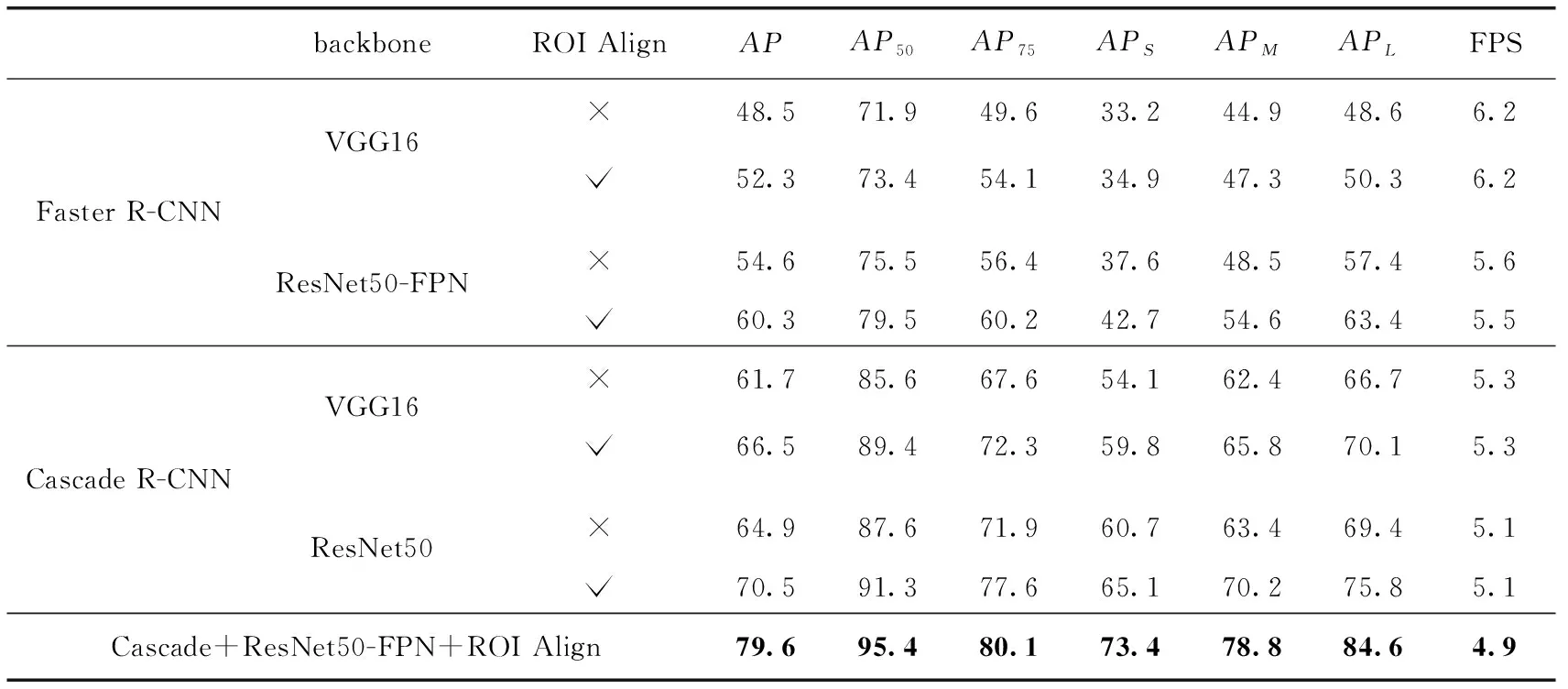
表4 各算法模型精度对比

图10 检测结果
4 结束语
本文提出的基于聚类算法的Anchor尺寸生成策略,应用于模型区域提案网络生成特定尺寸的Anchors。并结合多融合的特征提取网络(ResNet-FPN)与感兴趣对齐层(ROI Align)提出一种改进的Cascade R-CNN算法。基于聚类算法的Anchor生成策略,在训练过程中能够有效加快模型收敛,有效防止在训练过程中由于尺寸设置不合理造成的模型训练收敛困难、陷入局部最优等情况;多尺度融合的ResNet-FPN网络能够同时利用低层特征高分辨率和高层特征的高语义信息,通过融合这些不同层的特征达到预测的效果,实验结果表明在Faster R-CNN网络和Cascade R-CNN网络上面均能有3%的精度提升;ROI Align层的使用取消了原来生成区域提案时的两次取整操作,消除了特征图与原始图像的不对准问题,有效提升了缺陷定位的精准度。在未来实际生产过程中,本文提出的算法模型将会得到广泛的应用。
