基于EHDFS的海量小文件存储与检索方法
2022-03-01李文武张建锋王景林
李文武,张建锋,王景林
(西北农林科技大学 信息工程学院,陕西 杨凌 712100)
0 引 言
物联网+农业显现了TB规模量的包含文本、表格、图片等类型的KB小文件集[1]。HDFS因具备高容错、分布式、高吞吐量的特征而被广泛应用于大数据的存储[2]。但面对海量小文件,HDFS存储大文件的结构优势会被严重削弱,存储效率会大打折扣[3]。其中数据块Block(默认64 MB)作为HDFS基本存储单元,每存入一个小文件会生成一条元数据MetaData,用于记录其相关属性,并存于NameNode。而一个小文件会单独占据一个Block,且其大小远远小于Block体积,故会浪费大量DataNode空间资源,对应海量MetaData也会极大增加NameNode内存消耗[4,5]。面对来自客户端Client频繁的文件访问请求,系统依据节点内部索引会在多个DataNode之间“跨跃式”寻找并读取目标文件,导致HDFS读取文件花费的时间远少于为了读取文件所进行的RPC通信、Socket连接以及寻址等行为所花费时间,故HDFS缺少低时延访问需求,大大降低了数据读取效率[6,7]。
通过分析HDFS存取海量小文件时结构设计的不足,本文提出了一种基于可扩展分布式文件系统EHDFS的存取方案。首先,利用空间最优化的文件合并存储方式,最大化提高Block空间利用。然后,改进MapFile映射结构以建立新的文件索引模型,减少从映射文件查询MetaData的交互步骤,以降低检索文件时高频的RPC通信和多次寻址带来的时间开销。最后,调用各存储模块的接口API,保证组件间的协同工作,以达到提高海量小文件的存储效率和检索速率的目标。
1 相关工作
包括HDFS在内的分布式文件系统对于海量小文件的存取存在的缺陷包括:DataNode空间利用、NameNode负载均衡、文件读取速率问题。针对上述问题,国内外存在不少企业、机构和科研人员进行过深入研究,提出的解决方案在一定程度上缓解了小文件的存取压力。
Apache基金会提供方案有:Hadoop Archive[8]、SequenceFile[9]和CombineFileInputFormat[10]。Hadoop Archive,通过MapReduce将多个小文件打包成一个Har文件并直接存入DataNode,方法有效减少了MetaData数量,提高了NameNode内存利用率,但存在源文件需手动删除和Har文件具有特定格式且创建后无法修改的弊端[11]。SequenceFile,通过将小文件名作为key、内容作为value,以二进制形式进行合并存储。由于缺少建立文件索引而具有较大局限性,对于文件检索需要遍历整个文件集,故不适合数据的随机访问[12]。CombineFileInput-Format,通过将多个小文件打包至一个split,每个Mapper处理多个split,降低了Mapper处理的数据量与数据块大小的耦合关系。方案存在较差的小文件写的性能表现,故只适合小文件已上传至集群的分布式计算[13]。
Zhou W等针对小文件存储性能低下提出了一种利用非阻塞I/O存储方式进行小文件归并的独立引擎管理方法。该方法能够对读取次数最少的文件进行分开并分组,但在数据块批处理生成过程中会产生大量元数据的问题[14]。the New Hadoop Archive(NHAR),一种基于现存HAR归档文件上进行小文件压缩的存储方式。该方法是通过消耗大量内存进行小文件的追加工作,而且易导致压缩策略发生故障而达不到节省空间的效果[15]。Karan A等针对由海量小文件存取造成NameNode瓶颈问题提出了一种优化主节点工作方式的方法,通过将小文件与其对应生成的元数据进行共同存储进行元数据管理。由于方案缺少对大量小文件的缓存进行处理的考虑,故存储效率提升较小[16]。Anitha.R等基于HDFS增加了少数模块,提出了可扩展分布式文件系统EHDFS(extend hadoop distributed files system)。EHDFS通过合并操作减少文件数量,同时为合并文件建立有效索引机制,随后通过预取缓存模块提高数据访问速率[17]。方案有效减少了元数据数量,降低了NameNode内存消耗,缩短了文件访问时间,对文件系统的改进具有借鉴意义。
2 方案模型设计
针对HDFS存储海量小文件效率低下的问题,本文采用可扩展分布式文件系统EHDFS的结构模型,从存储与检索方面提出一种改进方案。方案整体模型架构如图1所示。存取方案核心模块包括:基于最优化策略的小文件合并存储单元、基于MapFile方法的小文件索引单元。方案是对HDFS结构形态的补充,凭借客户端、核心模块与HDFS集群间的相互作用,有助于文件的可靠交互与自由存取。
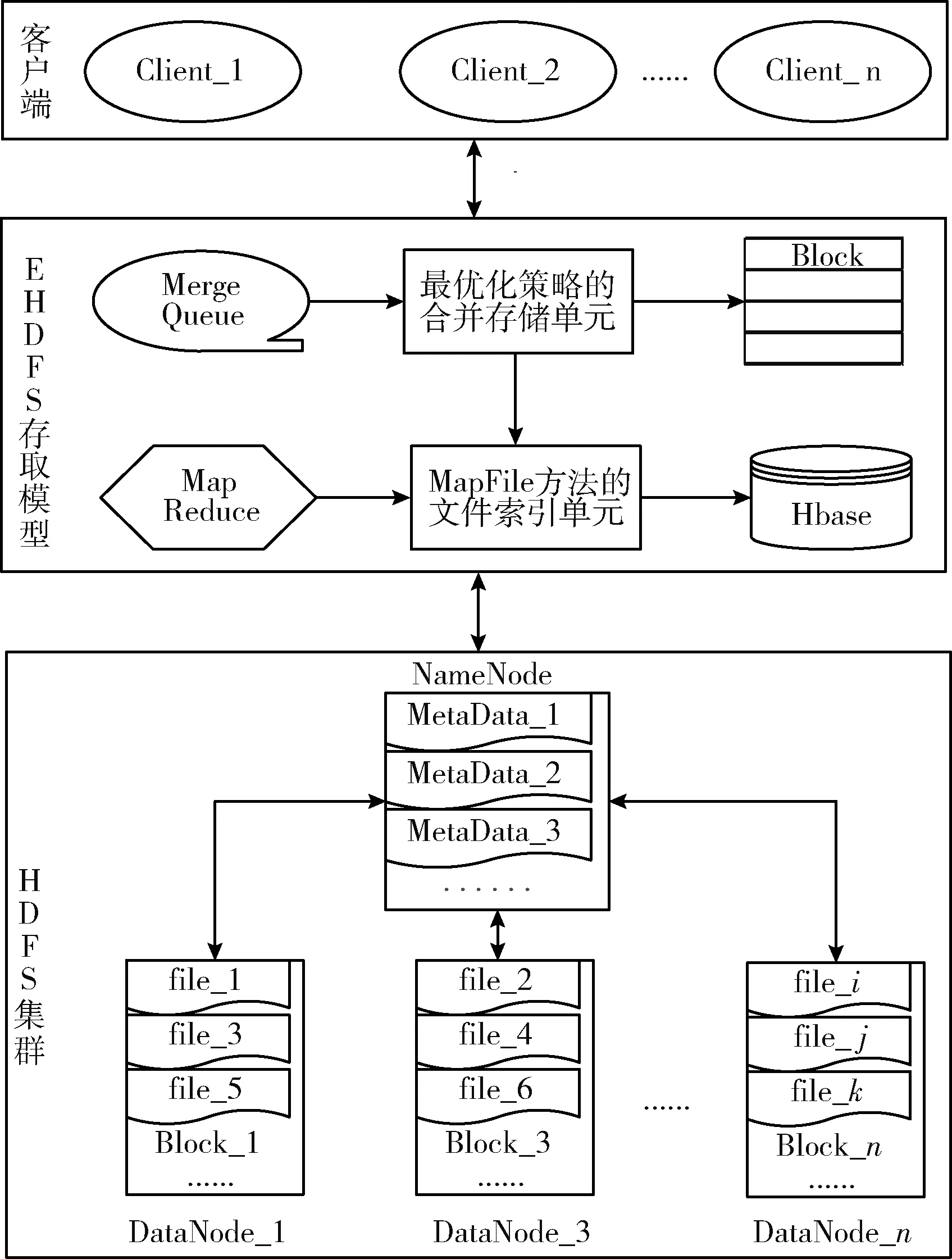
图1 方案整体模型架构
构建存储与索引模型是方案的核心成分,承担着相邻阶段的确切职责。文件存储阶段,为了充分利用DataNode空间资源,降低因海量MetaData所带来的NameNode内存压力,将使用最优化策略改进小文件的合并方式,使其尽可能地填满且均匀分布在数据块中。文件检索阶段,建立高效的映射结构和文件索引是进行快速、准确检索文件的关键,通过改进MapFile索引算法的映射关系结构、索引存储位置和组成元素以建立新的两级索引模型,从而减少在MapFile文件中查询目标文件因缺乏构建全体小文件的索引而无法满足随机访问的需求,降低分散索引与跨越式搜索目标文件所消耗的额外时长。
2.1 小文件最优化合并存储
合并是存储海量小文件的有效手段,它能减少DataNode空间浪费和NameNode内存负载。所以,关键在于如何构建有效的合并算法模型。本文做法是通过引入最优化策略[18]以构建新的合并算法,整体合并存储流程如图2所示。核心思想为:充分考虑待合并文件体积差异和分布状态对数据块Block空间占用的差异性影响,凭借阈值判别分析,让小文件均匀分布于Block中,使合并文件尽可能接近数据块阈值,做到节点空间的最大化利用。合并算法定义3种数据结构:合并队列mergeQ、备用队列backupQ和临时队列tempQ。mergeQ用于加载与合并阈值相符合的小文件;backupQ是相对于mergeQ的备用队列,两种队列可相互转化,以提供小文件多次合并的可能;tempQ用于暂时存储不符合合并条件的小文件。合并算法中,合并阈值与3种队列的初始化大小定义为Block_size。mergeQ数量a使用待上传文件总体积与Block_size比值,backupQ和tempQ数量b、c远远小于a。另外,合并算法声明:为了避免各种异常影响合并队列较长时间接收不到小文件而持续占用系统资源,合并存储的执行过程规定在合理有效的时间T内进行,时间T依据实际上传的数据规模量进行设置。
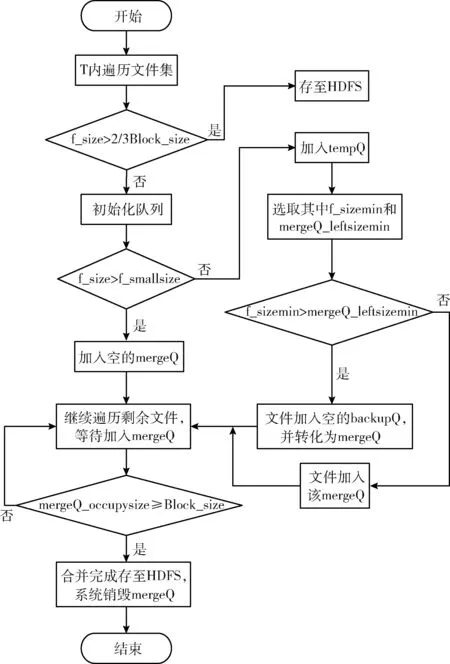
图2 最优化合并存储流程
2.1.1 最优化合并存储步骤
步骤1 时间T内依次遍历待上传存储的文件集,若当前上传文件体积f_size大于2/3倍数据块阈值Block_size,则直接存储至HDFS,继续遍历剩余文件;否则转跳至步骤2。
步骤2 依据用户准备上传的文件总体积与合并阈值,预先计算合并队列mergeQ的数量a,备用队列backupQ和临时队列tempQ的数量b和c远远小于a,依据实际取用合并队列a的1/10,不足向上取整。然后按需依次初始化对应的3种队列。
步骤3 若当前文件大小f_size大于小文件阈值f_smallsize,则将该文件添加至空的合并队列mergeQ,继续遍历剩余文件;若f_size不大于f_smallsize,则将该文件放至临时队列tempQ,然后转跳到步骤4。
步骤4 从临时队列tempQ中选取体积最小的文件f_sizemin和当前剩余空间最小的合并队列mergeQ_leftsizemin。
步骤5 比较f_sizemin与mergeQ_leftsizemin的体积大小,若f_sizemin大于mergeQ_leftsizemin,则说明当前所有合并队列都无法容纳该文件,此时将该文件添加至空的备用队列backupQ,并转换成新的合并队列mergeQ,然后继续新一轮的合并操作;若f_sizemin小于等于mergeQ_leftsizemin,则将该文件添加至该合并队列,然后转跳到步骤6。
步骤6 计算当前合并队列mergeQ的文件占用总体积,若总体积大于等于数据块阈值,则将该合并队列mergeQ中的全体文件打包存储至HDFS集群节点的数据块Block中,然后销毁该mergeQ;否则继续新一轮的合并操作。
2.1.2 合并算法执行效果对比
通用合并策略在文件遍历的进程中,因为缺乏考虑体积差异的小文件存储于同一数据块所占空间对对方和剩余空间的影响,易造成文件溢出、分割与非均衡存储,算法执行效果如图3所示。而使用改进合并策略对相同文件的执行效果如图4所示,较为改善之处在于算法能够记录每一次合并对块空间的占用情况,并动态判断与调整最适合该块合并的目标文件,因此会较大节省数据块的消耗,提高现存块空间的利用。
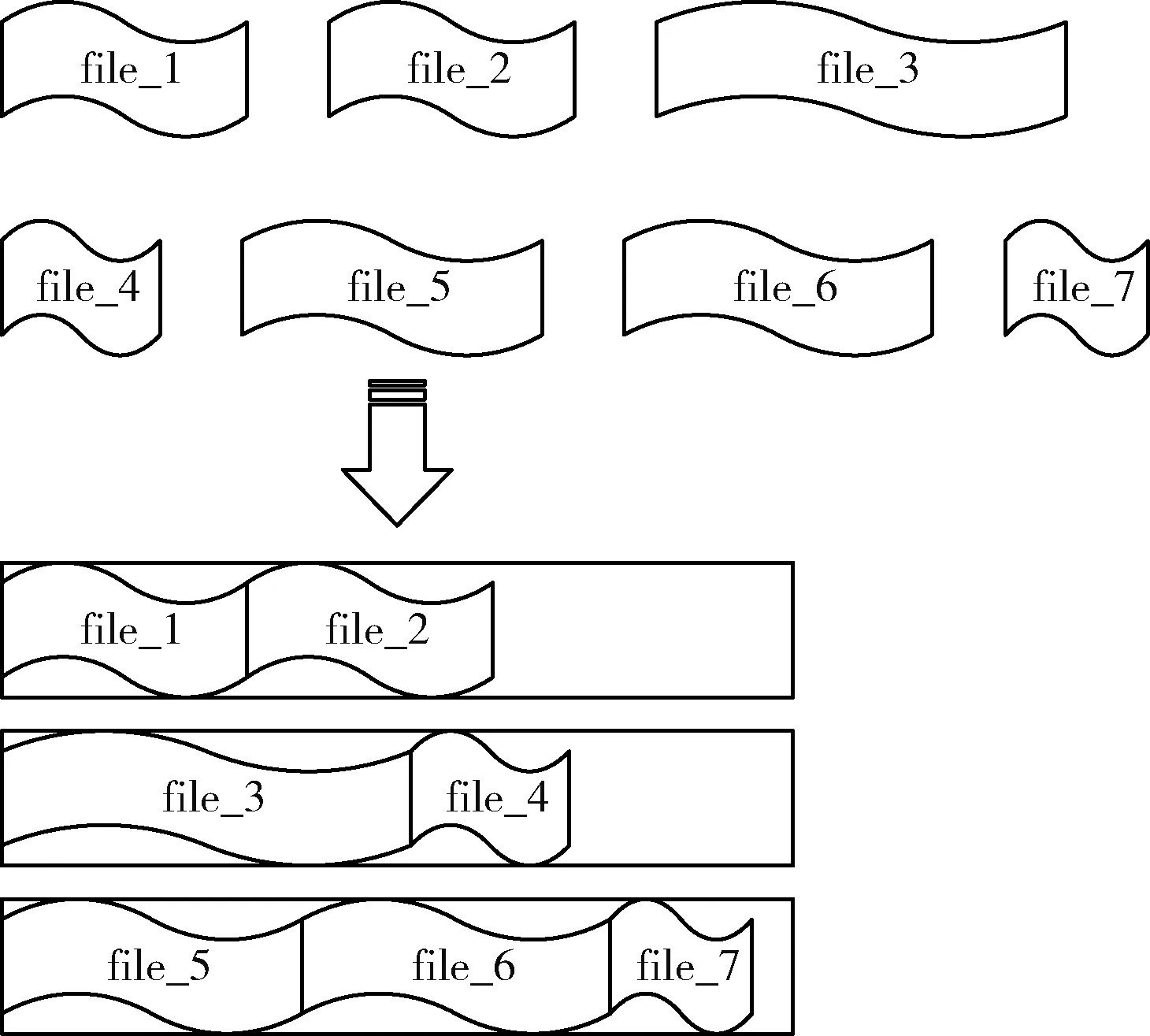
图3 通用合并算法效果
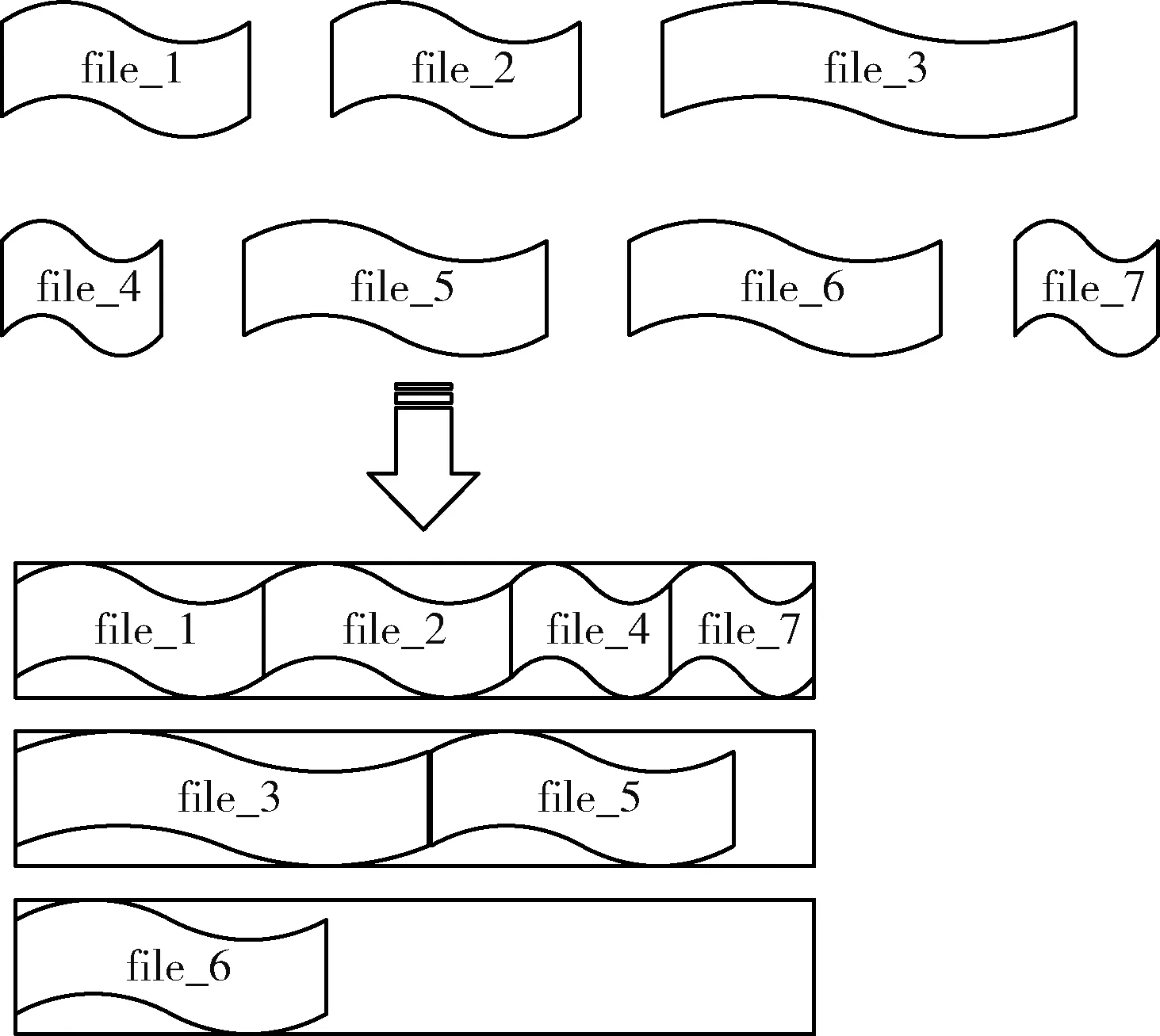
图4 最优化合并算法效果
2.1.3 最优化合并存储关键算法
Input: 农业小文件集{ A }
Output: 合并成功”Success”或者失败”Failure”
WHILE uploadTime < T
/*整个合并存储在有效时间T内进行*/
THEN Traverse uploadfiles;
/*依次遍历文件*/
IF Next file_size > 2/3Block_size
/*文件预处理,排除大文件对合并算法的干扰*/
THEN Write To HDFS;
ELSE
/*按需初始化3种结构队列,开始文件合并流程*/
Initialize mergeQ;
Initialize backupQ;
Initialize tempQ;
END IF
IF file_size > file_smallsize
/*判断当前合并文件大小,决策文件执行流程*/
THEN Add To mergeQ;
Traverse uploadfiles;
ELSE
Add To tempQ;
END IF
THEN
/*选取合适的小文件与合并队列进行组合, 实现不同大小的文件进行均匀搭配归并, 最大化填满数据块*/
Search file_sizemin In tempQ;
Search mergeQ_leftsizemin In All mergeQ;
IF file_sizemin > mergeQ_leftsizemin
THEN Add To backupQ;
Convert backupQ Into mergeQ;
/*转换队列角色, 以提供之前未满足合并条件的文件进行多次合并的可能*/
Traverse uploadfiles;
ELSE
Add To mergeQ;
END IF
IF mergeQ_occupysize > Block_size
/*合并完成条件判断, 整体归并存储节点数据块*/
THEN Write To HDFS;
System Reclaim mergeQ;
/*系统回收队列占用资源*/
ELSE
Traverse uploadfiles;
END IF
END WHILE
2.2 小文件映射与索引构建
MapFile映射文件技术[19]是对SequenceFile序列文件技术的改进方案,有效克服了序列文件缺乏文件映射关系需要遍历整个文件序列的缺陷。其中由
为了减少文件索引的交互时长,提高海量数据的检索速率,本文将对MapFile索引结构做出改进以建立新的文件索引策略。主要思想是:调整文件映射关系结构、优化索引文件组成元素以及更改索引文件存储位置。首先,应避免跨度较大的多层级映射结构,此处采用线性结构

表1 映射关系结构
最后通过解析小文件对应MetaData的属性元素,利用MapReduce并行计算引擎按映射结构建立全局小文件索引,独立保存至Hbase数据库。索引建立过程依赖于Map函数与Reduce函数,一个Map函数负责一个数据块中的合并文件,一个Reduce函数负责根据文件属性归纳每个Map函数生成的索引,进而创建全局的文件索引。其中MapReduce索引生成原理如图5所示。采用索引与文件分离存储的方式,能避免聚合存储产生的紊乱。
索引构建阶段,相比较存在低扩展性与低容错性、存储模式单一等局限的关系型数据库RDBMS,具备非结构化存储模式、高并发读写与随机查询、按列存储且同列数据的类型与特征拥有高相似度等优势的非关系型数据库HBase[21],能够更加灵活地满足海量多结构农业小文件的索引存储需求。Hbase数据结构模型由主键Row Key、列族Column Family、列限定符Column Qualifier、时间戳Time Stamp主要元素组成。其中Row Key用于唯一标识一行记录,同时作为文件检索的唯一索引标识[22]。本文存储于Hbase数据库的文件索引数据表见表2。
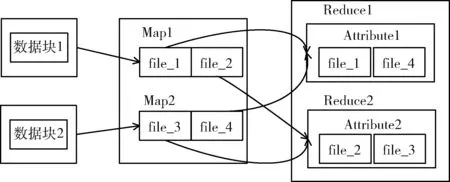
图5 MapReduce索引生成
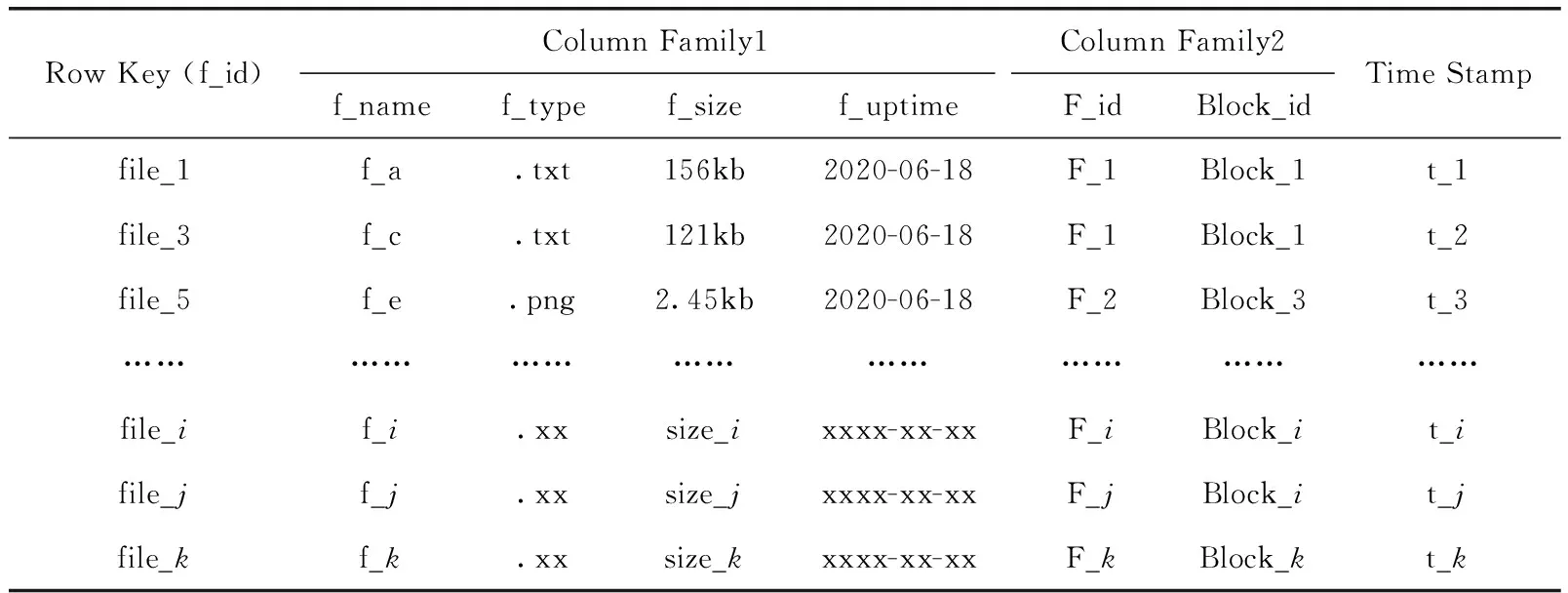
表2 Hbase文件索引数据
2.3 小文件检索
由于索引文件置于Hbase组件,位于HDFS外部,相比直接节点内部的查找步骤会稍有增加。但索引本身采用多标识的线性结构,能够避免跨越式检索而实现集中位置匹配,并且相当程度减轻了NameNode对海量元数据信息的管理压力,增强其对文件检索的控制力。当面对来自客户端的访问请求时,系统文件检索流程如图6所示。面对Client的文件读取请求,EHDFS存取模型系统的文件检索步骤具体如下:
步骤1 HDFS客户端发起文件读取的请求,包括文件基本属性。系统预判读取文件的存在性,若不存在,直接反馈给Client错误输入;否则转至步骤2。
步骤2 系统按规则预判读取文件的大小性,若为大文件,系统直接前往NameNode依据元数据信息确定文件所在Block位置,然后前往目的存储区域并将查询结果反馈至Client;否则转至步骤3。
步骤3 确定为小文件后,系统会前往Hbase数据库,依据索引数据表的映射关系,通过相关文件属性获取目标小文件存储地址,然后前往目标文件位置并将查询结果反馈至Client。
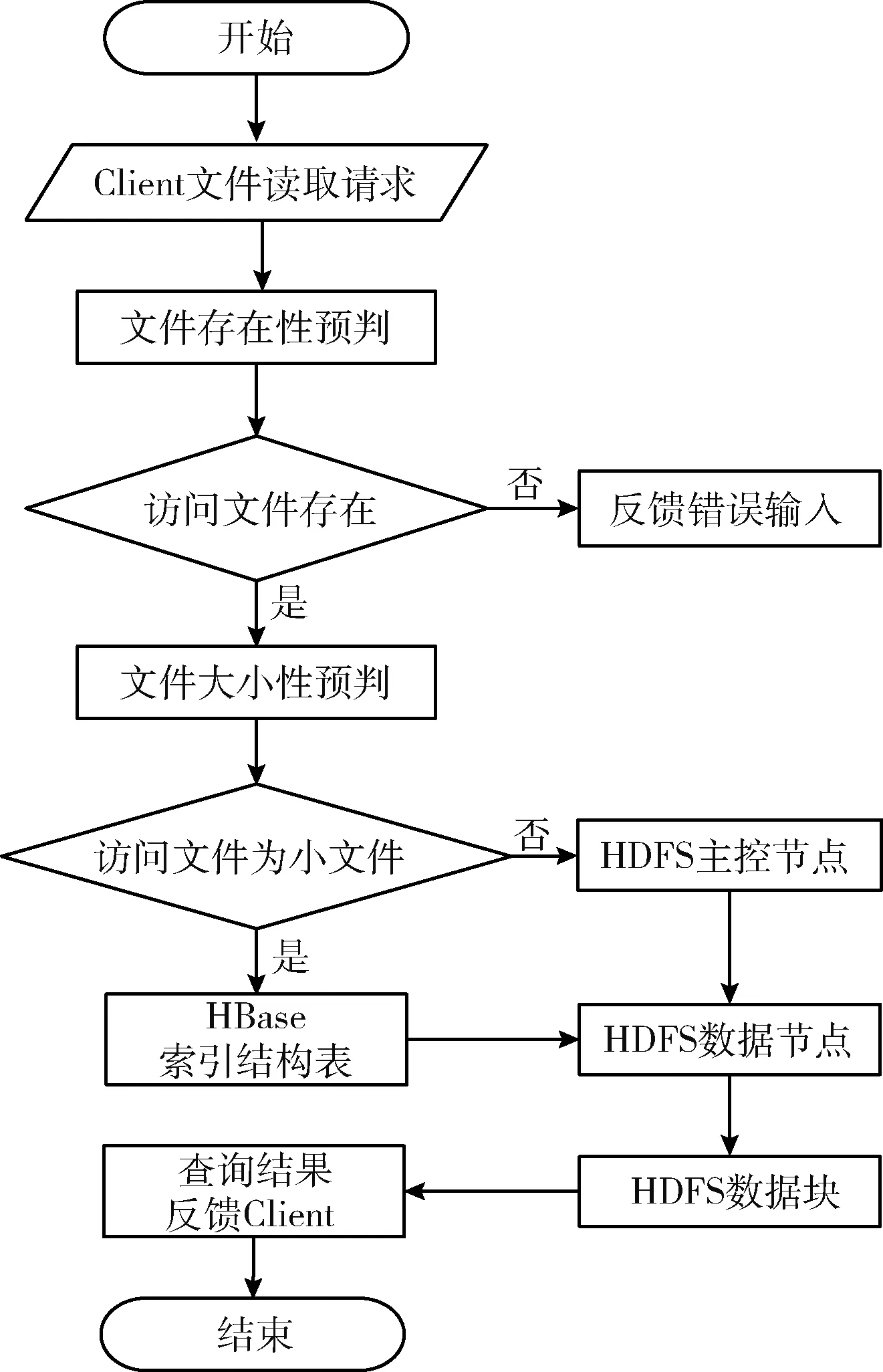
图6 文件检索结构
3 实验设计
3.1 实验环境
为了验证本文方案在数据存储与检索层面的可行性,实验将使用学校大数据实验室的4台计算机组建完全分布式的集群测试环境,其中NameNode作为主控节点使用1台计算机,DataNode作为存储节点使用3台计算机,各个节点服务器软硬件参数完全一致,以保证测试环境的高度统一,节点服务器配置信息见表3。

表3 节点服务器配置信息
依据研究内容,实验将选取NameNode内存占用、数据读取时长作为测试指标来验证方案的整体数据存取效率。NameNode内存消耗用于验证最优化合并策略的有效性,数据读取速率是对新的文件索引模型可行性的验证,通过测试在不同指标下的表现状态以确定改进方案的总体优劣情况。
实验拟使用国家农业科学数据中心平台共享的农业资源与环境科学数据进行方案验证。测试数据采用75 000条由温度、湿度、降雨量、天气值等类别组成的约15.1 GB文件集构成,具体文件的组成数量与总体占比如图7所示。图表清晰展示了数据集中不同大小文件所占数量的分布状态,其中2 M以内文件占据90%以上,该数据既能切入海量小文件对HDFS存取效率低下的研究要点,又能充分体现农业环境科学数据小的特征。为了验证系统在不同数据容量下的有效性,实验将数据划分为15 000,30 000,50 000,75 000进行分组测试。为了突出本方案与MapFile、标准HDFS的性能差异性,实验将设置对照组加以区分不同方法对数据处理的优劣状态。为了提高测试结果的精确性,实验将对每份指标进行5组重复实验,然后取其平均值作为测试结果。

图7 数据集类别组成
3.2 实验内容
3.2.1 NameNode内存占用测试
分析NameNode内存占用是验证最优化合并策略下节点空间是否充分合理化使用的直观方式。实验将采用控制变量法分别对标准HDFS、MapFile与本文方案进行数据上传存储的对照测试,每组实验在保持单一变量环境下,重复5次测试取其平均值,以确定3种方案在4组不同数据量的存储压力下NameNode内存占用率的差异化表现,实验结果如图8所示。

图8 NameNode内存占用
依据实验结果,标准HDFS因缺乏文件合并预处理,对应产生大量MetaData导致NameNode内存消耗较大,整体表现不佳。MapFile与本文方案相对表现良好,尤其体现在数据量较大状态,且本方案要稍微优于MapFile,因为通过最优化合并策略能够考虑到体积和分布状态各异的小文件对数据块占用的影响,进而提高文件合并的机率,从而减少MetaData数量以节省NameNode内存空间。
3.2.2 数据读取时长测试
数据读取时长能够直观反映文件索引结构是否有效提高文件系统的检索效率。实验将在数据分组存储的NameNode内存占用的阶段性实验基础上进行。实验分别对标准HDFS、MapFile与本文方案进行文件的随机检索。为避免多环境因素的干扰,每组测试均保持单一环境变量,利用随机函数选取各组样本的1000条文件进行检索,以测试方案在不同样本容量下的文件读取效率,然后统计5次重复实验的平均读取时长,实验结果如图9所示。
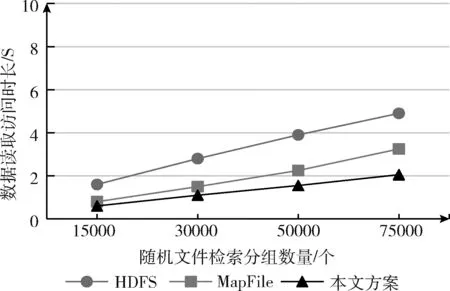
图9 随机文件平均读取时长
依据实验结果,标准HDFS因索引结构设计因素使得文件检索节点通信时间过长,导致缺少低时延的访问需求,整体表现一般。MapFile与本文方案优化了文件索引结构,整体表现较好。伴随数据量的增长,本文方案优势凸显,因为新的文件索引结构能够考虑到节点间的数据交互影响与Hbase数据表的结构优势,有效缩短交互时长以提升访问速率。
4 结束语
面对HDFS存取海量小文件低效问题,本文通过分析当前各解决方案的优劣,研究HDFS结构设计对农业小文件存取的利弊,针对DataNode空间浪费过大,NameNode内存占用过高,以及文件索引交互时长过多,从存储与检索层面构建了一种基于可扩展分布式文件系统EHDFS架构的解决方案。实验结果表明,在数据存储阶段,方案通过最优化文件合并的存储方式,有效提高了DataNode空间利用,并降低了NameNode内存占用。在数据检索阶段,通过改进文件的索引结构设计,有效节省了数据检索的节点交互时长。所以方案整体上能够满足HDFS分布式存取海量农业小文件的需要。但是与MapFile比较,本方案提升有限,仍然具有较大改进空间。
