Machine learning algorithms and techniques for landslide susceptibility investigation: A literature review
2022-03-01WengngHiqing
, , ,, Wengng,, ,, Hiqing,, ,,
(a. School of Civil Engineering; b. National Joint Engineering Research Center of Geohazards Prevention in the Reservoir Areas; c. School of Architecture & Urban Planning, Chongqing University, Chongqing 400045, P. R. China)
Abstract: There are many mountainous areas in China, with complex terrain, weak planes and geological structures and wide distribution of geohazards. Landslides are one of the most catastrophic natural hazards occurring in mountainous areas, leading to economic loss and casualties. Landslide susceptibility models are capable of quantifying the possibility of where landslides are prone to occur, which plays a significant role in formulating disaster prevention measures and mitigating future potential risk.Since expert-based models are difficult to quantify and generally depend on the subjective judgments, the accuracy and precision of landslide susceptibility models are now evolving from expert models and statistical learning toward the promising use of machine learning methods. This study presented critical reviews on current machine learning models for landslide susceptibility investigation, an extensive analysis and comparison between different machine learning techniques (MLTs) from case studies in the Three Gorges Reservoir area was presented. In combination with field survey information as well as historical data, machine learning models were used to map landslide susceptibility and help formulate landslide mitigation strategies. The advantages and limitations of several frequently employed algorithms were evaluated based on the accuracy and efficiency of landslide susceptibility forecasting models. As the result shows, the tree-based ensemble algorithms models achieved better compared with other commonly methods of papping landslide susceptibility. Furthermore, the effect of database quality and quantity is significant, and more applications of some advanced methods (i.e., deep learning algorithms) are yet to be further explored in further researches.
Keywords:landslide; machine learning; landslide susceptibility; the Three Gorges Reservoir; deep learning
1 Introduction
Landslide is a process in which the soil or rock on a slope falls, dumps, slides, spreads or flows due to the influence of various factors[1]. In recent years, landslide hazards have caused serious loss of human life and property, therefore, severely constrained economic and social development on a worldwide scale[2-5]. According to the statistics of China’s Ministry of Natural Resources (Fig.1), landslides are the most threatening geological hazards, causing incalculable damage[6-10]. To effectively reduce the damage caused by landslides, the status of landslide susceptibility identification using scientific and technical means based on existing landslide cases is the focus of current research.

Fig.1 Summary of the geological hazards in
Landslide susceptibility is considered as the potential for slides to occur in an area under the influence of local topography and ambient factors[11]such as rainfall, earthquake, reservoir water level fluctuation, human engineering activity, etc. Landslide susceptibility assessments are generally divided into qualitative and quantitative methods. Qualitative approaches are based on the existing landslide inventories and the knowledge and experience of experts, defining landslide susceptibility through descriptive terms. Quantitative methods based on databases or physical models, predict landslide occurrences according to model calculation results. By comparison, quantitative methods reduce the subjectivity of qualitative methods[12]. With recent technical advances, using Geography Information Systems (GIS), Remote Sensing (RS), Global Positioning Systems (GPS) as sources of landslide database, combined with other data integration and analysis techniques is the most prevalent measure for landslide prediction and assessment. This requires considerations of a range of environmental factors, as well as the impact of the landslides that have occurred on the terrain, and is heavily dependent on the distribution and scale of the datasets[13]. However, the development of soft computing methods provides advanced alternative quantitative methods, which possesses the characteristics of low cost and high robustness by tolerating uncertainty, imprecision and incomplete true values.
As the most promising soft computing method, machine learning (ML) has been developed since the 1950s, and has experienced two periods of declining popularity as artificial intelligence has affected the general public. In recent years, however, advances in computer technology and the rapid expansion of data and information have brought machine learning back into favor with scholars, mainly due to its ability to "learn" from large amounts of data by combining applied mathematics and computational intelligence to perform classification or regression tasks on unknown data. In the case of landslides in particular, machine learning methods are able to detect robust data structures that help model landslide susceptibility and predict landslide occurrences, despite missing values in monitoring information[14-16]. Generally, ML methods are more suitable extensive predictive modeling of landslide events, as well as classification tasks, considering that they are able to learn from complex and irregular data, establish relationships between data, and build algorithmic models without human intervention and prior assumptions. As an emerging technique in the fast development of the information age, ML is the product of statistical mathematics with artificial intelligence and other disciplines, and it is divided into supervised learning, semi-supervised learning and unsupervised learning. To the best of the authors’ knowledge, the most common in current research contents is the use of supervised learning methods for landslide susceptibility modeling, solving classification or regression problems, and predicting the potential that landslides are likely to occur in the future[17-22].
In this paper, common ML classification and regression methods are reviewed, and the performance of artificial neural network (ANN), decision trees (DT), support vector machine (SVM), multivariate adaptive regression splines (MARS), random forest (RF) and extreme gradient boosting (XGBoost) models are compared based on the researches on landslide susceptibility mapping (LSM) in the Three Gorges Reservoir area. A brief summary subsequently reviews the application of ML in landslide susceptibility prediction over the past two decades to illustrate the state of art and provide basic guidance for future research in this area.
2 Statistical analysis
2.1 Number of publications
In the period 2000-2020, publications on landslide susceptibility using "landslide", "machine learning", and "landslide susceptibility" as keywords from Web of Science were collected. A total of 614 papers in different publishing years were compiled, as shown in Fig. 2, it can be seen that there were less than ten studies per year about ML use in landslide susceptibility prediction during the first decade. After that, there was a significant increase in the number of published articles, most notably after 2016 when a sharp increase occurs, depending on the advancement of data acquisition technology and the continuous upgrading of computer hardware performance.
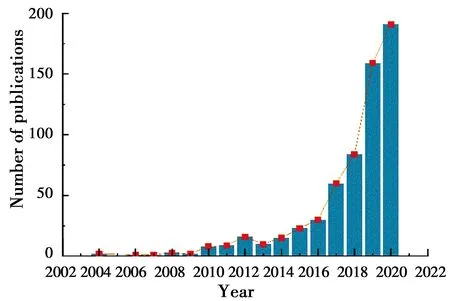
Fig.2 Total number of publications in the last 20
2.2 Keywords
The keywords of 451 studies in the Science Citation Index Expanded (SCI-E) database out of 614 retrieved literature articles were analyzed. Statistically, a total of 521 of these keywords were used. The obvious is that the number of keywords has increased substantially in the last three years, consistent with the trend in the total number of publications, as shown in Fig.3. Machine learning, GIS and landslides are the most commonly used keywords, and terms such as landslide susceptibility and remote sensing have significantly received more attention in recent years due to the rapid development of data information and computer technology. In addition, machine learning methods such as random forest, support vector machine and deep learning have been used in recent years as data acquisition methods have diversified and data sizes have increased.

2.3 Author
With 1 162 authors publishing in the area of machine learning methods for landslide susceptibility prediction, the author impact analysis was also established in the SCI-E database for the period 2000-2020. The top 15 authors with the most published articles are listed in Table 2, of which 10 authors have published more than 20 articles with a total of 1 861 citations, contributing significantly to the field of machine learning techniques (MLTs) for LSM researches. Among the publications by these authors, most focus on using logistic regression (LR)[23-24], decision trees (DT)[25-26], random forest (RF)[27-29], neural network (NNT)[30-31], and support vector machine (SVM)[32-33]methods. And from the methodological trends of these studies, it can be seen that scholars are more inclined to share research related to bagging and boosting algorithms which are representative machine learning methods.

Table 1 The most productive authors in MLTs for LSM
To date,there is no consensus on which ML models are optimal for LSM due to the influence of landslide inducing factors, database quality, and the underlying assumptions of the ML algorithms. Thus, the next section focuses on discussing the conditions of applicability, advantages and limitations of several representative ML models for critical comparison.
3 Comparison of MLTs for LSM
The Three Gorges Reservoir area refers to the area that was submerged or had migration tasks due to the Three Gorges Dam project on the Yangtze River, located in the Sichuan Basin and the middle and lower reaches of the Yangtze River plain. The excavation of the construction sites and the water storage process in the reservoir area has caused serious damage to the geological environment[34-38]. According to statistics, there were about 4 200 landslides in the whole Three Gorges Reservoir area, causing a large number of casualties and economic losses[39]. Four examples of landslides in the Three Gorges Reservoir area which are identified based on the interpretation of 1∶10 000-scale color aerial photographs are shown in Fig.4. Several published papers described landslides in the Three Gorges Reservoir area to study geological failure modes and increase slope stability by combining historical data, site investigations, satellite images, and LSM has been commonly used to identify and map historical landslides and predict future landslide occurrences. Fig.5 shows the methodology for LSM using MLTs. In this section, several methods such as artificial neural network (ANN), decision trees (DT), support vector machine (SVM), multivariate adaptive regression splines (MARS), random forest (RF) and extreme gradient boosting (XGBoost) and their applications in LSM are briefly described.

Fig.4 Landslides aerial photographs( Peng et

Fig.5 Flow chart of LSM using
3.1 Artificial neural network
ANN is an algorithmic model of “artificial neurons” inspired by the generation mechanism of resting and action points of natural neurons in the human brain, and is one of the fastest growing research fields in recent years. This method has a strong nonlinear adaptive capability[41-45]. Not only can the information itself changes in many ways, but the nonlinear dynamic system is also constantly updating itself when processing information, which can simulate the intelligence of the human brain to actively adapt to the environment for learning. In general, it is suitable for building general mathematical models for datasets with no specific rules. However, since the dependence of the output variables on the input variables is non-linear, it is not possible to visualize the effect of each input variable on the output value, so in fact, ANN is a black box model.
Depending on its advantage of handling variable relationships without relying on external rules, ANN algorithm becomes an effective tool for assessing landslide probability and predicting landslide occurrences[46-48]. In addition, Moayedi et al.[49]presented the optimization-artificial neural network (PSO-ANN) model to achieve model optimization to help establish the estimation of LSM. In general, the strong parallel processing and learning capabilities allow ANN to handle a large number of data samples, but precisely because of this, its model performance is very dependent on the quality of the landslide database and is relatively time-consuming.
3.2 Decision trees
DT is a typical supervised learning method and a predictive model that represents a mapping between object properties and object values. It uses a tree model to make decisions based on the properties of the data. The relationship between input variables and target variables can be linear or nonlinear, which allows for clear and concise explanations of variable associations or better visualization[50], unlike ANN, it is not a black box model. DT can process data measured at different scales without making assumptions about frequencies or weights based on non-linear relationship between the data, this approach helps explain complex relationship between variables and make predictions from the data[51-53].
The algorithm is actually a process of recursively selecting the optimal feature and partitioning the training data according to that feature, so that each sub-dataset has the best possible classification[54-56]. For the quantitative assessment of landslide susceptibility, there are numerous algorithms that can be used for DT method, such as iterative dichotomiser 3 (ID3), C4.5[57-58], the classification and regression tree algorithm (CART)[59]. As a single decision tree model, the DT model is computationally simple and capable of handling both data-based and conventional attributes. And unlike black-box models, the corresponding logical expressions are easily introduced based on the resulting decision trees of a given model. Tree-based models such as RF, XGBoost are based on DT algorithm.
3.3 Support vector machine
SVM is a supervised learning binomial classifier based on the risk minimization principle of structured architecture[60], originally developed by Vapnik[61]. Its basic model is a linear classifier with the largest spacing defined in the feature space, while the kernel approaches such as linear function, radial basis function and polynomial function, allow it to handle nonlinear problems[62]. Essentially, its approach seeks the best compromise between the learning accuracy of a particular training sample and the ability to correctly identify arbitrary samples based on limited sample information, in order to obtain the best generalization capability[63-66].
Among the many studies that predict landslides, SVM has been found to exhibit many unique advantages in handling small training samples, nonlinear and high-dimensional pattern recognition, and strong robustness can be obtained with very little model tuning compared with other multivariate statistical models[67-69]. The excellent generalization ability makes SVM one of the most commonly used and effective classifiers. And yet, SVM does not perform better than other algorithms in all landslide case studies. For large-scale training samples, it will waste a substantial amount of machine storage and operation time.
3.4 Multivariate adaptive regression splines
MARS is a data analysis method developed by the American statistician Friedman[70]. It is a nonparametric regression technique that combines the advantages of spline regression and recursive partitioning, and can be seen as an extension of the linear model of interaction between variables[71-79]. In MARS, no need to make assumptions about the relationship between independent and dependent variables. It divides the training set of data into different segmented line segments, which are called basis functions, and the endpoints of each segment are called nodes. It has been proved by many researches on LSM that MARS has strong adaptive capability and generalization ability when dealing with high-dimensional data[80-81]. MARS can be seen as a refinement of the effect of CART in regression problems, compared to other MLTs, it can effortlessly procure the display expressions of variables whereas model accuracy is not satisfactory.
3.5 Random forest
In 2001, Breiman combined decision trees into random forests with the idea of ensemble learning[82], so it essentially belongs to a large branch of machine learning: ensemble learning method. In RF, assuming that the problem to be solved is classification, so each decision tree is a classifier. And for an input sample, RF integrates the different voting results ofnclassifiers, and the category with the most votes is designated as the final output, which is one of the simplest bagging ideas[83-86].
The “forest” is composed of “trees”, and when constructing a decision tree, it is necessary to pay attention to the random sampling and complete splitting process, and the construction method has the following three steps:
(1) There is a put back to selectnsamples which means that each time a sample is randomly selected and then put back to continue the selection, with thesensamples training set a decision tree. And thesensets are taken as the sample at the root nodes of the decision tree;
(2) Suppose that the feature dimension of each sample isM. When the nodes of the decision tree need to be divided,mattributes are randomly selected, which need to satisfy the conditionm≪M. Then optimal one is selected as the splitting attribute from themattributes.
(3) Split each node of the decision tree to the maximum extent possible, without pruning.
Repeat steps(1)-(3) to construct a large number of decision trees, so that a random forest is formed.
RF is highly efficient and capable of processing large amounts of data with very high accuracy, and does not require dimensionality reduction in the face of input samples with high-dimensional features, so it is particularly applicable to explain the spatial relationship between landslide cases[87-89]. In addition, it can be used to evaluate the importance of individual features on the classification problems, which is very common in LSM[90-91]. In many current datasets, RF possesses a considerable advantage over other algorithms and can analyze the importance of the features. But since it presents a discontinuous output, the RF model performance in solving landslide susceptibility regression problems is not as impressive as on the classification problems.
3.6 Extreme gradient boosting
XGBoost is a tree boosting scalable machine learning system, proposed by Chen and Guestrin[92]. The learning method of this algorithm is mainly to sum the results ofK(number of trees) as the final predicted value, the forecast output of the ensemble model can be expressed as

(1)

In fact, XGBoost is known for its regularized boosting technique, the objective function is defined in order to learn the set of functions used in the model, and prevent overfitting. Generally, there are three main parameters namely, colsample_bytree (subsample ratio of columns when constructing each tree), subsample (subsample ratio of the training instance) and nrounds (max number of boosting iterations) to be selected when using the XGBoost model for landslide susceptibility assessment[93-97]. When XGBoost takes CART as the base learner, the addition of the regular term compensates for the disadvantage that the DT algorithm is prone to overfitting. The linear model can also be used as the base learner, when XGBoost is equivalent to logistic regression or linear regression with a regular term. Excepting for the disadvantage of being time-consuming, the XGBoost model is well received in landslide susceptibility evaluation researches.
3.7 Comparative summary of MLTs
There are four steps in the process of constructing a landslide susceptibility model employing the machine learning algorithms:
(1) Obtain high quality spatial data such as topography and geological conditions from remote sensing images or landslide survey maps, with the aim of determining the triggering mechanism of landslides. It should be noted that different spatial resolutions have difference influence on various models adopted.
(2) The data analysis is carried out to optimize the selection of suitable input factors. To date, there is still no universal guideline for determination of factors affecting landslides. Optimally selecting the input factors, ranking by importance, and removing factors with low contribution is a requisite. Landslide conditioning factors are required to be easily measured and estimated, and have the ability to perform functional calculations on them.
(3) The resampling method is implemented to supply the training set for training the different ML models. For some models, the performance relies not only on the quality of dataset and the assumptions of algorithm, but also on the optimization of the tuning of details.
(4) Evaluate the performance of different landslide susceptibility models, the fitting performance, prediction accuracy, and uncertainty of the results are all criteria for evaluating the model. In addition to the main measure accuracy (ACC), Receiver Operating Characteristic (ROC) curve and Cohen’s kappa Index (kappa) are adopted as metrics to further assess the overall quality of the model.
For different study regions, different MLTs exhibit different model performance as well. Zhou et al.[98]classified the landslides in the Longju area as colluvial landslides and rockfalls, used SVM, ANN and LR for mapping landslide susceptibility. They found that the machine learning models outperformed the multivariate statistical models, and the SVM approach was more applicable to this case study. For the Zigui area, Zhang et al.[99]calculated the quantitative relationship between the landslide-conditioning factors and historical landslides using a RF model and found that the RF model achieved more accurately in LSM compared with the DT model; Wu et al.[100]used object-based data mining methods to study landslide susceptibility assessment, and the results showed that the object-based SVM model has a higher accuracy than the others. Song et al.[101], Chen et al.[102]regarded the LSM problem as an imbalanced learning problem, built a more efficient prediction model using the weighted gradient boosting decision tree (weighted GBDT) method which is rarely used in previous researches. Besides, hybrid models were applied for LSM to build a more effective model and improve the adaptive capability of the model, such as the rough sets-SVM (RS-SVM) model[40], the model combined rough sets with back-propagation neural networks (BPNNs)[103], and the two steps self-organizing mapping-random forest (two steps SOM-RF) model[104].
Overall, the methods described above applied efficiently for solving many LSM problems in many individual case studies. Table 2 summarizes the applicable conditions, merits and disadvantages of the MLTs introduced in this study. Compared with the traditional ML method, the tree-based ensemble algorithms input most of the data without tedious data preprocessing process. Considering the sufficiency and accuracy of the landslide susceptibility models, the linear models classify the data in a sparse manner. By contrast, the tree-based model can better summarize the overall data structure and map the relationship between variables, and its results are less prone to overfitting problems and better handling of outliers. According to the study about the Three Gorges Reservoir area, the overall accuracy of the model was compared as a comparative index, and it was found that the accuracy of traditional linear models such as LR was in the range of 80.5%-88.3%, the accuracy of SVM model was 86.4%-93.6%, while the accuracy of RF algorithm model basically remained around 90.65%, and the accuracy of GBDT model was as high as 97.7%-99.7%. Therefore, a preliminary conclusion informed that for the Three Gorges Reservoir area, the tree-based algorithms achieve superiorly.

Table 2 Summary of the applicable conditions, merits and disadvantages for the MLTs
4 Discussion and conclusion
In the IT era, computer technology is constantly evolving, artificial intelligence is greatly improved, and machine learning has gradually covered the whole social life, which includes medical, transportation machinery, public safety, social science, disaster management and so on. This study focused on the research field of solving landslide susceptibility problems with machine learning techniques, and a systematic review of the relevant research in the past 20 years was presented. From the results of statistical analysis, it can be seen that as an emerging research method, the relevant publications are increasing year by year and rising rapidly, so it is obvious that the application of MLTs in LSM is effective.
In addition to the mentioned ANN, DT, SVM, MARS, RF, XGBoost methods, machine learning also encompasses other types of algorithms, and as research progresses, many hybrid methods have been proposed by worldwide researchers to improve the generalization ability of the models. These techniques have very powerful self-learning capability and can handle a large amount of data efficiently and accurately. They are mostly used for failure probability analysis of landslides and landslide displacement predictions, building landslide susceptibility maps to help make risk mitigation decisions. While reviewing the related research, it is important to note that this research area may face many challenges in the future as discussed below:
(1)It is difficult to conduct susceptibility analysis if the study area is large. On the one hand, data collection is a major problem, and obviously the lack of landslide information cannot build a good performance model. On the other hand, the predicted results of landslide high susceptibility areas may only account for a small portion of the total map, so that the accuracy of the susceptibility model cannot be guaranteed.
(2)Among the many cases used in literatures, there are different types of landslides with diverse geographical information and environmental conditions, so it is important to understand the types of landslides in the study area and then build an optimal model based on the assumptions and theoretical basis of different machine learning methods, which can enhance the credibility of the landslide area classification.
(3)The influence factors considered when performing landslide susceptibility modeling using machine learning techniques are not comprehensive. In current studies, most of them focus on the geotechnical properties, slope, height, etc. of landslides. But in fact, uninvolved factors often have significant effects, such as climate and environmental changes, which are difficult to observe, and destructive to landslides. In addition, the role of groundwater and weathering erosion are often ignored.
(4)Few studies consider the occurrence and interactions of multiple geologic hazards in complex environments, such as rockfalls, debris flows, ground subsidence or landslide events that have occurred with unpredictable impacts. When analyzing landslide susceptibility in the study area, the performance of susceptibility maps can be improved if other hazards are modeled and predicted simultaneously in a cross-sectional study.
Previous researches have confirmed that MLTs can accurately predict landslides to reduce damage caused by disasters, and this technique has helped to make scientific decisions on disaster management. Moreover, authors hold the view that the application of MLTs in LSM is still evolving as an emerging research direction. Especially in recent years, deep learning, a derivative of machine learning, has received much attention, but the use of deep learning methods to develop superior landslide susceptibility models has not been widely investigated and reported, it is not difficult to imagine that such applications in the future are promising.
